Disp R-CNN Stereo 3D Object Detection via Shape Prior Guided
论文链接:https://arxiv.org/abs/2004.03572
代码链接:https://github.com/zju3dv/disprcnn

提出的系统估计一个实例视差图,即仅在前景对象上的像素级视差,用于立体 3D 对象检测。这种设计可以获得更好的视差估计精度和更快的运行速度。
前文
Disp R-CNN 网络相较于一般的 3D 目标检测模型,不同点主要在:
- 该网络仅估计感兴趣目标的视差;
- 学习特定类别形状先验以获得更精确的视差估计;
- 可以不使用 LiDAR 提供的点云,而使用统计形状模型生成稠密视差伪 GT;
观点
由于视差估计网络是为一般的立体匹配而设计的,而不是用于三维目标检测任务,这些整体流程有两个主要的缺点:(1)视差估计过程是在全图像上进行的,在低纹理或非朗伯面(从任何角度观察反射面,其反射亮度是一个常数,这种反射面称朗伯面。)上,比如车辆表面,往往不能产生准确的视差,而这些区域正是成功进行三维边界盒估计所需要的区域。(2)由于前景感兴趣的目标在图像中所占的空间通常比背景小得多,视差估计网络和3D检测器在目标检测不需要的区域上花费了大量的计算,导致运行速度慢。
目的
视差图是为整个图像计算的,代价较高,没有利用分类特定的先验。相比之下,本文设计了一个实例视差估计网络(iDispNet),该网络仅对感兴趣的物体上的像素预测视差,并事先学习一个特定类别的形状,以获得更准确的视差估计。
贡献
- 一种新的基于实例级视差估计的立体三维物体检测框架,在精度和运行速度方面都优于最先进的基线。
- 伪GT生成过程,为实例视差估计网络提供监督,引导其提前学习有利于三维物体检测的物体形状。
网络结构
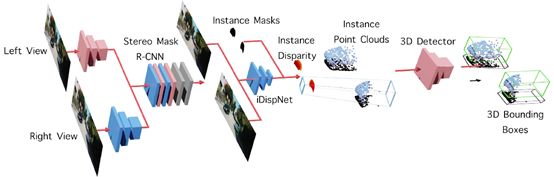
Disp R-CNN Architecture。分三个阶段:首先,输入的图像通过一个立体变体的Mask R-CNN 检测二维边界盒和实例分割掩模。然后,实例视差估计网络 (iDispNet) 以裁剪后的 RoI 图像为输入,估计一个实例视差图。最后,将实例视差图转换为实例点云,并送入三维检测器进行三维边界盒回归。
简单来说,首先检测每个对象的 2D 边界盒和实例掩模,然后仅对属于对象的像素进行差异估计,最后使用 3D 检测器从实例点云预测 3D 边界盒。
简单知识
- [1] 利用点云必须位于物体表面的约束,利用立体差异生成的点云和利用 PCA 从三维形状库中学习到的物体形状先验模型,联合优化物体的姿态和形状。
[1] Francis Engelmann, J¨org St¨uckler, and Bastian Leibe. Joint object pose estimation and shape reconstruction in urban street scenes using 3d shape priors. In German Conference on PatternRecognition, pages 219–230. Springer, 2016.
- 按照 [2] 中的设置,使用 PSMNet 作为 iDispNet 的架构。后面使用了 PointRCNN 作为 3D 对象检测器。为了提高伪GT生成过程的稳定性,仅对位于 GT 三维边界盒内的点进行优化。对于小于 10 点的物体,不需要进一步优化,直接使用平均形状。
[2] Yan Wang, Wei-Lun Chao, Divyansh Garg, Bharath Hariharan,Mark Campbell, and Kilian Q Weinberger. Pseudo-lidarfrom visual depth estimation: Bridging the gap in 3d objectdetection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8445–8453, 2019.
- 在并发作品中,OC-Stereo 和 ZoomNet 与本文的观点相似。 OC-Stereo 结束后使用 LiDAR 点作为监督,ZoomNet 引入了细粒度的注释来生成 GT ,而本文的伪 GT 是根据优化的对象形状进行渲染的,比OC-Stereo更精确,比 ZoomNet 更高效,因此可以提高 KITTI 测试仪的性能。
- 当伪 GT 为 GT 时,iDispNet 的视差和深度误差比全帧 PSMNet 小很多。在稀疏激光雷达点作为 GT 的情况下,iDispNet 仍然比全帧法 PSMNet 和最先进的深立体视觉方法 GA-Net 具有更好的性能,特别是对于目标深度RMSE 误差。全帧 PSMNet 无法捕捉到车辆光滑的表面和锐利的边缘,因此 导致以下 3D 检测器很难从不准确的点云中预测出正确的边界盒。相比之下,iDispNet 在实例视差估计和视差伪 GT 的监督下,给出了更准确和稳定的预测。
详解
1. Stereo Mask RCNN
扩展 Stereo R-CNN 框架来预测左图的实例分割掩模。Stereo Mask RCNN 由两个阶段组成。第一阶段是区域提议网络(RPN)的变体,其中左图像和右图像的对象提议是从同一组锚点生成的,以确保左区域和右区域之间的感兴趣区域正确对应(RoIs)。第二阶段使用 RoI Align 从特征图中提取对象特征,然后是两个预测头,它们产生 2D 边界框,分类分数和实例分割掩码。
2. Instance Disparity Estimation Network

视差估计模块负责立体三维物体检测中三维数据的恢复,其精度直接影响三维检测的性能。iDispNet 只将目标 RoI 图像作为输入,只对前景像素进行监督,从而捕获特定类别的形状先验,从而产生更准确的视差预测。
通常:定义像素 p 的全帧视差为: ![]()
RoIs 对齐后,实例视差为:
![]()
左右两幅图像的 RoI 都被调整为一个共同的大小 H×W。对于实例分割掩码给出的属于一个对象实例 O 的所有像素 p,其实例差异的损失函数定义为:

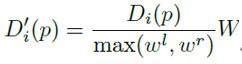
三维坐标 (X,Y,Z) 的推导如下: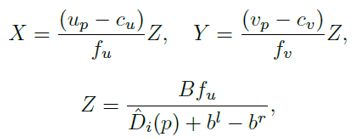
3. Pseudo Groundtruth Generation
利用目前只需要前景监督的 iDispNet 的设计,提出了一种不需要激光雷达点就能生成大量稠密视差伪 GT 的方法。生成过程是通过一个特定类别的形状先验模型实现的,根据该模型可以重建物体的形状,然后将其渲染到图像平面上,获得密集的视差 GT。这里使用体积截断带符号的距离函数(TSDF)作为形状表示。
作者提出无需LiDAR点即可生成大量的密集视差伪GT的方法如下:
(1)通过特定类别的形状先验模型来重建对象形状,然后将其绘制到图像平面以获得密集的GT视差。
(2)使用体积截断符号距离函数(TSDF)作为形状表示。对于车辆这种形状变化较小的物体,可通过低维子空间来近似,子空间的基础表示为V,它是从训练形状的前导主分量获得的,平均形状表示为μ。
(3)通过给定的3D边界框GT和实例点云,以最小化代价函数的方式来重建实例的形状系数z:只有z在优化过程中被更新。这个代价函数最小化了由TSDF的零点交叉定义的从点云到物体表面的距离。点云可以来自视差估计模块或任意的LiDAR。
由于上述代价函数不限制物体形状的3D尺寸,因此提出尺寸正则化项来减少3D边界框的溢出。
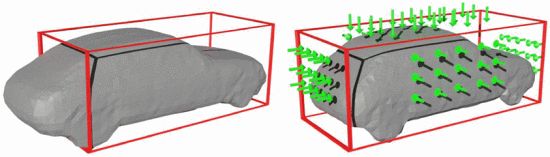
伪 GT 生成过程中,如果体素在 3D box 之外,则 TSDF 值为负值,并在维度正则化过程中对其进行惩罚,从而使形状表面停留在三维包围盒内。左右分别表示没有和有正规化尺寸的物体形状。
4. 设计与选择
a) Choices on network design
iDispNet设计有两种选择,第二种实验结果更好:
i. 仅使用iDispNet的解码器部分作为预测头,类似于掩模R-CNN中的掩模头。将从主干中提取的感兴趣区域特征用于视差估计,并将视差头与网络其余部分进行端到端训练。
ii. 从原始图像中裁剪出感兴趣图像,然后将裁剪后的图像送入iDispNet的编解码器网络中。
原因分析: 与实例细分和视差估计任务之间的不同要求有关。视差估计需要更细粒度的显著特征表示,以使像素上的代价量处理更准确,而监督实例分割,对每个属于对象的像素预测相同的类概率。通过联合训练网络的端到端版本,骨干必须在这两种不同的任务之间进行平衡,从而导致次优结果。
b) Choices on the point cloud for Pseudo-GT generation
i. 利用可选的深度补全步骤来提高数据集中的稀疏激光雷达点云密度
ii. 在其他数据集上训练的现成视差估计网络的预测(例如在 KITTI Stereo 上训练的 PSMNet)。
(i) 可能会给出更准确的点云。但是其中没有使用 LiDAR 点作为优化目标的数据集或应用场景;(ii) 在不使用激光雷达点云的情况下表现良好。