YOLO系列论文精度 & YOLOv1
You Only Look Once:Unified, Real-Time Object Detection
目录
一、摘要
二、结论
三、介绍YOLO
四、Unified Detection(统一检测)
五、Network Design
六、训练和推断
(1)训练
(2)推断
七、YOLO的局限性
八、文章中的一些表格和图像
一、摘要
我们提出了YOLO,一种新的目标检测方法。先前的目标检测工作使用分类器来执行检测。相反,我们将目标检测框定为空间分离的边界框和相关类概率的回归问题。单个神经网络在一次评估中直接从完整图像预测边界框和类概率。由于整个检测管道是一个单一的网络,因此可以直接对检测性能进行端到端的优化。
我们的统一架构速度极快。我们的 base YOLO 模型以每秒45帧的速度实时处理图像。该网络的一个较小的版本,Fast YOLO,每秒处理惊人的155帧,同时仍然实现了其他实时探测器的两倍的mAP。与最先进的检测系统相比,YOLO 会产生更多的定位误差,但在背景中预测错误的可能性较小。最后,YOLO 学习对象的非常一般的表示。当从自然图像推广到 artwork 等其他领域时,它优于其他检测方法,包括 DPM 和 R - CNN。
二、结论
我们引入YOLO,一个目标检测的统一模型。我们的模型构造简单,可以直接在完整图像上训练。与基于分类器的方法不同,YOLO是在一个直接对应于检测性能的损失函数上训练的,整个模型是联合训练的。
Fast YOLO是文献中速度最快的通用目标检测器,YOLO推动了最先进的实时目标检测。YOLO还很好地概括了新的领域,使其非常适合依赖快速、可靠的目标检测的应用程序。
三、介绍YOLO

图1 The YOLO Detection System(3.非极大值抑制)
(1)最近的方法如 R - CNN《Rich feature hierarchies for accurate object detection and semanticsegmentation》使用区域建议方法:
- 首先在图像中生成潜在的边界框;
- 然后在这些边界框上运行分类器;
- 分类后,后处理用于细化边界框,消除重复检测,并基于场景中的其他对象对框进行重评分。
R - CNN 局限:这些复杂的管道是缓慢和难以优化的,因为每个单独的组件必须单独训练。
(2)我们将目标检测重构为一个单一的回归问题,直接从图像像素到边界框坐标和类概率。使用我们的系统,您只需查看一张图像( YOLO ),就可以预测图像中存在哪些物体以及它们在哪里。
这种统一的模型与传统的目标检测方法相比有很多优点。
- 首先,YOLO速度极快。因为我们将检测框定为一个回归问题,所以我们不需要复杂的管道。我们只是在测试时在一个新的图像上运行我们的神经网络来预测检测。我们的基础网络以每秒45帧的速度运行,在Titan XGPU上没有批处理,快速版本(Fast YOLO)的运行速度超过150 fps。这意味着我们可以以小于25毫秒的延迟来实时处理 stream video(视频流)。此外,YOLO达到了其他实时系统平均精度的两倍以上。
- 第二,YOLO在进行预测时,在全局范围内对图像进行解释。与滑动窗口和基于区域建议的技术不同,YOLO在训练和测试期间看到的是整个图像,因此它隐式地编码了关于类及其外观的上下文信息。Fast R-CNN 是一种顶级检测方法《Fast R-CNN》,它会将图像中的背景 patch误判为对象,因为它看不到较大的上下文。与 Fast R - CNN 相比,YOLO的背景错误数量不到一半。
- 第三,YOLO学习对象的通用表示。当在自然图像上进行训练并在 artwork 上进行测试时,YOLO 比 DPM 和 R - CNN 等顶级检测方法有更大的优势。由于YOLO是高度可泛化的,所以当应用于新领域或非预期输入时,YOLO不太可能崩溃。
YOLO局限:YOLO在准确性方面仍然落后于最先进的检测系统。虽然它可以快速地识别图像中的物体,但它难以精确地定位一些物体,特别是小物体。我们在实验中进一步检查这些权衡。
四、Unified Detection(统一检测)
我们将目标检测的各个组成部分统一到单个神经网络中。我们的网络使用来自整个图像的特征来预测每个边界框。它同时预测图像中所有类别的所有边界框。这意味着我们的网络对整个图像和图像中的所有对象进行全局推理。YOLO设计可实现端到端训练和实时速度,同时保持高平均精度。
每个网格单元预测 B 个边界框以及这些框的置信度。这些置信度分数反映了模型是多么自信,盒子包含一个对象,以及它认为它预测的盒子是多么准确。
每个包围盒(预测框)由5个预测组成:x、y、w、h和置信度。( x , y) 坐标表示盒子中心相对于网格单元边界的位置。宽度和高度(w 和 h)是相对于整个图像预测的。最后,置信度预测表示预测框与任一真值框之间的 IOU。

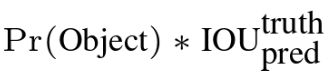 :置信度==预测框和真实值之间的交并比( IOU )。
:置信度==预测框和真实值之间的交并比( IOU )。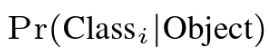 :每个网格预测的 C 个类别概率,我这些概率是在包含一个对象的网格单元上设定的。们只预测每个网格单元的一组类别概率,不考虑盒子B的个数。
:每个网格预测的 C 个类别概率,我这些概率是在包含一个对象的网格单元上设定的。们只预测每个网格单元的一组类别概率,不考虑盒子B的个数。
这给了我们每个 box 特定类的信心分数(置信度)。这些分数既编码了该类在框中出现的概率,也编码了预测框与对象的拟合程度。

图2 我们的系统将检测建模为一个回归问题。它将图像划分为一个 S × S 的网格,每个网格单元预测 B 个边界框、这些框的置信度和 C 类概率。这些预测被编码为一个 S × S × ( B * 5 + C) 张量。其中,5 代表x、y、w、h和置信度。
为了在PASCAL VOC上评估YOLO,我们使用S = 7,B = 2。PASCAL VOC有20个标记类,因此C = 20。我们最终的预测是一个7 × 7 × (2 × 5 + 20) == 7 × 7 × 30的张量。
五、Network Design
我们将此模型实现为一个卷积神经网络,并在PASCAL VOC检测数据集上进行评估《The pascal visual ob-ject classes challenge: A retrospective》。网络的初始卷积层从图像中提取特征,而全连接层则预测输出概率和坐标。
我们的网络架构受到用于图像分类的 GoogLeNet model 的启发。我们的网络有24个卷积层和2个全连接层。与《Network in network》类似,我们不再使用 GoogLeNet 使用的 inception 模块,而是简单地使用 1 × 1 的缩减层和 3 × 3 的卷积层。完整的网络如图 3 所示。

图3 The Architecture。我们的检测网络有 24 个卷积层和 2 个全连接层。交替的1 × 1卷积层减少了前一层的特征空间。我们在ImageNet分类任务上以一半的分辨率预训练卷积层(224 × 224 input image),然后将分辨率加倍进行检测。
24层卷积层:1+1+4+(4*2+2)+(2*2+2)+2=24.
我们还训练了一个快速版本的YOLO,旨在推动快速目标检测的边界。Fast YOLO使用的神经网络具有更少的卷积层( 9 而不是 24 )和这些层中更少的过滤器。除了网络的大小之外,YOLO和Fast YOLO之间的所有训练和测试参数都相同。
我们网络的最终输出是7 × 7 × 30的预测张量。
六、训练和推断
(1)训练
预训练:我们在ImageNet1000 - class竞赛数据集上预训练卷积层。对于预训练,我们使用图 3 中的前20个卷积层,然后是一个平均池化层和一个全连接层。
我们对该网络进行了每周一次的训练,在ImageNet 2012验证集上取得了88 %的最高准确率,与Caffe ' s Model Zoo中的GoogLeNet模型相当。我们使用Darknet框架进行所有的训练和推理。
然后我们转换模型来执行检测。《Object detection networks on convolutional feature maps》研究表明,在预训练网络中同时加入卷积层和连接层可以提高性能。根据他们的例子,我们添加了4个卷积层和2个随机初始化权重的全连接层。检测通常需要细粒度的视觉信息,因此我们将网络的输入分辨率从224 × 224提高到448 × 448。
我们的最后一层同时预测类概率和边界框坐标。我们通过图像的宽度和高度对边界框的宽度和高度进行归一化,使其落在0到1之间。我们将边界框x和y坐标参数化为特定网格单元位置的偏移量,因此它们也在0和1之间有界。
我们对最后一层使用线性激活函数,所有其他层使用 leaky rectified linear acti-vation:

问题:我们对模型输出中的平方和误差(sum-squared errror)进行了优化。 我们使用平方和误差,因为它很容易优化,但它并不完全符合我们追求最大化平均精度的目标。它将定位误差与分类误差等量加权,分类误差可能并不理想。同时,在每幅图像中,许多网格单元不包含任何对象。这会将这些细胞的"置信度"分数推向零,通常会压倒包含物体的细胞的梯度。这可能导致模型不稳定,导致早期的训练发散。
为了解决这个问题,我们增加了边界框坐标预测的损失,减少了不包含对象的框的置信度预测的损失。我们使用两个参数,λcoord 和 λnoobj 来实现这一点,设置 λcoord = 5 和 λnoobj = 0.5。
问题:平方和误差在 large boxes and small boxes 中也同样加权误差。我们的误差度量应该反映 large boxes 中的小偏差比 small boxes 中的小偏差更重要。
为了部分解决这个问题,我们预测了包围盒宽度和高度的平方根,而不是直接预测宽度和高度。
补充:平方损失函数,借鉴链接:平方损失函数
YOLO为每个网格单元预测多个包围盒。在训练时,我们只希望一个边界框预测器负责每个对象。我们分配一个预测器来"负责"预测一个对象,基于该对象的预测具有与真实值最高的当前IOU。这将导致边界框预测器之间的专门化。每个预测器都能更好地预测特定大小、纵横比或对象类别,从而提高整体召回率。
在训练过程中我们优化了以下,多部分(multi-part)损失函数:
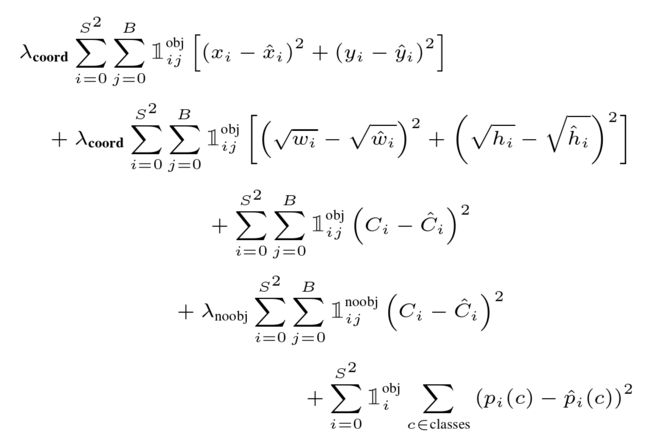
其中,
- 括号里面的变量是预测值和真实值,
- S * S:一张图像被划分后的网格数,
- B:一个网格中的预测框的数量,
- λcoord = 5 和 λnoobj = 0.5,
- C:预测的种类数量,
- p:预测的种类的概率,
 表示对象是否出现在单元 i 中,
表示对象是否出现在单元 i 中, 表示单元格 i 中的第 j 个边界框预测器“负责”该预测。
表示单元格 i 中的第 j 个边界框预测器“负责”该预测。
注意,损失函数只惩罚该网格单元(因此前面讨论的条件类概率)中存在物体时的分类错误。如果预测器对基本真值框(即在该网格单元中具有任意预测器的最高IOU) "负责",它也只对边界框坐标错误进行预测。
我们在PASCAL VOC 2007和2012的训练和验证数据集上训练了大约135个历元的网络。在2012年的测试中,我们还加入了VOC 2007的测试数据进行训练。在整个训练过程中,我们使用batch_size=64,momentum(动量)=0.9,decay(衰减)=0.0005。
我们的学习速率安排如下:对于第一阶段,如果我们以较高的学习速率开始,我们的模型往往会由于不稳定的梯度而发散,故我们将学习速率从  慢慢提高到
慢慢提高到 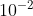 。第二阶段,我们继续以 训练75个epochs,然后以 训练 30 个epochs,最后以
。第二阶段,我们继续以 训练75个epochs,然后以 训练 30 个epochs,最后以  训练30个epochs。
训练30个epochs。
为了避免过拟合,我们使用 dropout 和广泛的数据增强。第一个连接层之后的 rate = 0.5 的 dropout 层可以防止层与层之间的协同适应《Improving neural networks by pre-venting co-adaptation of feature detectors》。对于数据增强,我们引入了高达原始图像尺寸 20% 的随机缩放和平移。在HSV颜色空间中随机调整图像的曝光度和饱和度,最高为1.5倍。
(2)推断
就像在训练中一样,预测测试图像的检测只需要一个网络评估。在PASCAL VOC上,该网络为每幅图像预测98个边界框,并为每个框预测类概率。与基于分类器的方法不同,YOLO 在测试时速度极快,因为它只需要单个网络评估。
网格设计在边界框预测中强制实现空间多样性。通常很清楚一个对象属于哪个网格单元,并且网络只为每个对象预测一个框。然而,一些较大的物体或靠近多个细胞边界的物体可以被多个细胞很好地定位。非极大值抑制(non-maximal suppression)可以用来修复这些多重检测,虽然对 R - CNN 或 DPM 的性能并不重要,但非极大值抑制使得 mAP 增加了 2 - 3 %。
七、YOLO的局限性
1. YOLO对包围盒预测施加了很强的空间约束,因为每个网格单元只预测两个盒子,且只能有一个类。这种空间约束限制了我们的模型可以预测的附近对象的数量。我们的模型与出现在群体中的小物体进行斗争,例如鸟群。
2. 由于我们的模型学习从数据中预测边界框,因此它很难泛化到新的或不寻常的纵横比或配置的对象。因为我们的架构从输入图像有多个下采样层,所以我们的模型还使用了相对粗糙的特征来预测边界框。
3. 最后,当我们训练一个接近检测性能的损失函数时,我们的损失函数在小边界框和大边界框中对待错误是一样的。
- 大盒子中的小误差一般是良性的;
- 但小盒子中的小误差对 IOU 的影响要大得多;
- 我们的主要误差来源是不正确的定位。
八、文章中的一些表格和图像
(1)如表1 所示,比较快速检测器的性能和速度。Fast YOLO是PASCAL VOC检测史上最快的检测器,其精度仍是任何其他实时检测器的两倍。YOLO比快速版本精确10 m A P,但速度仍远高于实时。
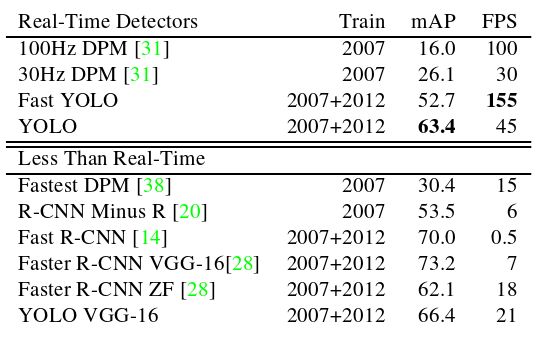
表1 Real-Time Systems on PASCAL VOC 2007.
(2)为了进一步研究YOLO和最先进的检测器之间的差异,我们查看了VOC 2007的详细结果。我们将YOLO与Fast R-CNN进行比较,因为Fast R-CNN是PASCAL上性能最高的检测器之一,它的检测是公开可用的。图4 显示了所有20个类中平均的每个错误类型的细分。
我们使用《Diagnosing error in object detectors.》的方法和工具,对于每个类别在测试时我们查看该类别的前 N 个预测。每个预测要么是正确的,要么根据错误的类型进行分类:
- Correct: correct class and IOU > .5
- Localization: correct class, .1 < IOU < .5(YOLO努力正确地定位对象)
- Similar: class is similar, IOU > .1
- Other: class is wrong, IOU > .1
- Background: IOU < .1 for any object
《Diagnosing error in object detectors.》(目标检测器中的错误诊断)论文浅析链接:
https://www.cnblogs.com/ronghuohuo/articles/6105320.html

图4 Error Analysis: Fast R-CNN vs. YOLO 。
YOLO努力正确地定位对象。定位误差比所有其他来源的误差加起来占YOLO的误差更多。快速R - CNN定位误差小得多,背景误差大得多。13.6 %的顶级检测是不包含任何对象的假阳性。Fast R - CNN 比 YOLO 预测背景检测的概率提高了近 3 倍。
(3)泛化性(可推广性):艺术品中的人物检测
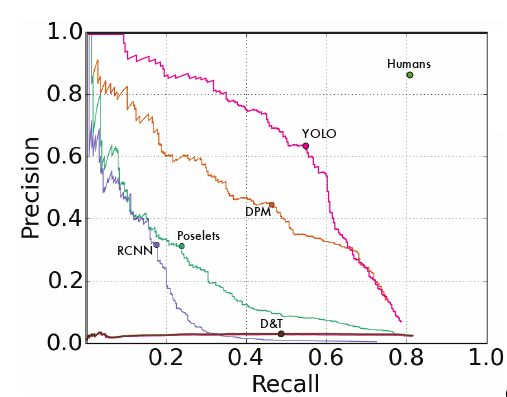
图5(a) 毕加索数据集的 精度-召回率 曲线
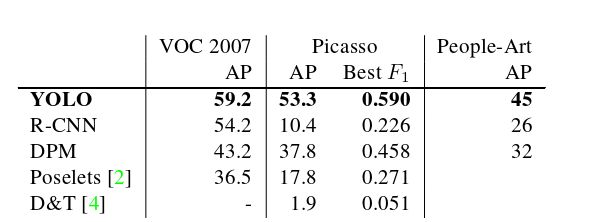
图5(b) YOLO和其他网络在毕加索数据集上的 AP 和 Best F1 的比较
补充:F1-Score又称为平衡F分数(balanced F Score),他被定义为精准率和召回率的调和平均数。F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。


图5(c) Qualitative Results.
YOLO运行在来自互联网的样本艺术品和自然图像上。它大多是准确的,虽然它认为一个人是一架飞机。
YOLO在VOC 2007上具有良好的性能,并且在应用于艺术品时,其AP退化程度低于其他方法。YOLO建模对象的大小和形状,以及对象之间的关系和对象通常出现的位置,与DPM一样。艺术品和自然图像在像素级别上非常不同,但它们在物体的大小和形状方面是相似的,因此YOLO仍然可以预测良好的边界框和检测。
>>>如有疑问,欢迎评论区一起探讨。