NLP领域的ELECTRA在符号预测上的应用
基于ELECTRA的标点符号预测
1. 资源
-
更多CV和NLP中的transformer模型(BERT、ERNIE、ViT、DeiT、Swin Transformer等)、深度学习资料,请参考:awesome-DeepLearning
-
更多NLP模型(BERT系列),请参考:PaddleNLP
2、原理解读
2.1 介绍
掩码语言模型(masked langauge model, MLM),类似BERT通过预训练方法使用[MASK]来替换文本中一些字符,破坏了文本的原始输入,然后训练模型来重建原始文本。尽管它们在下游NLP任务中产生了良好的结果,但是它们通常需要大量计算才有效。作为替代方案,作者提出了一种更有效的预训练任务,称为Replaced Token Detection(RTD),字符替换探测。RTD方法不是掩盖输入,而是通过使用生成网络来生成一些合理替换字符来达到破坏输入的目的。然后,我们训练一个判别器模型,该模型可以预测当前字符是否被语言模型替换过。实验结果表明,这种新的预训练任务比MLM更有效,因为该任务是定义在所有文本输入上,而不是仅仅被掩盖的一小部分,在模型大小,数据和计算力相同的情况下,RTD方法所学习的上下文表示远远优于BERT所学习的上下文表示。
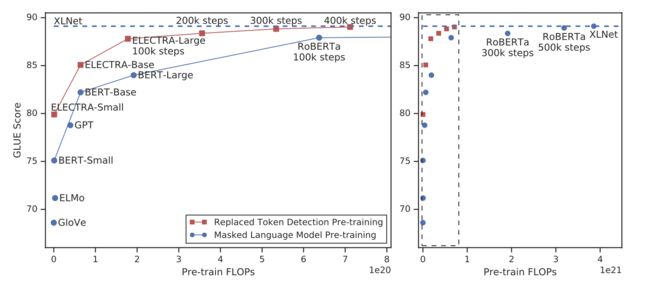
上图中,左边的图是右边的放大版,纵轴是dev GLUE分数,横轴是FLOPs(floating point operations),Tensorflow中提供的浮点数计算量统计。从上图可以看到,同量级的ELECTRA是一直碾压BERT,而且在训练更长的步长步数,达到了当时的SOTA模型RoBERTa的效果。从左边的曲线图上可以看到,ELECTRA效果还有继续上升的空间。
2.2 模型结构
ELECTRA最大的贡献是提出了新的预训练任务和框架,在上述简介中也提到了。将生成式的MLM预训练任务改成了判别式的RTD任务,再判断当前token是否被替换过。那么问题来了,假设,我随机替换一些输入中的字词,再让BERT去预测是否替换过,这样可行吗?有一些人做过实验,但效果并不太好,因为随机替换太简单了。
作者使用一个MLM的G-BERT来对输入句子进行改造,然后丢给D-BERT去判断哪个字被修改过,如下:

在下游任务中一般使用判别器(Discriminator)部分来做fine-tune。
接下来的章节,我们详细介绍一下ELECTRA每个部分的原理和代码实现,ELECTRA包括Embedding,ELECTRAModel,Generator,Discriminator,其中Embedding是整个模型的词嵌入模块
2.2.1 ELECTRA model
from paddlenlp.transformers import PretrainedModel
from paddlenlp.transformers import ElectraPretrainedModel
import paddle
import paddle.nn as nn
import paddle.tensor as tensor
import paddle.nn.functional as F
在实现ELECTRA模块之前,我们需要实现一下Embedding模块,Embedding模块包括Input Embedding,segment Embedding,position Embedding
class ElectraEmbeddings(nn.Layer):
"""Construct the embeddings from word, position and token_type embeddings."""
def __init__(self, vocab_size, embedding_size, hidden_dropout_prob,
max_position_embeddings, type_vocab_size):
super(ElectraEmbeddings, self).__init__()
self.word_embeddings = nn.Embedding(vocab_size, embedding_size)
self.position_embeddings = nn.Embedding(max_position_embeddings,
embedding_size)
self.token_type_embeddings = nn.Embedding(type_vocab_size,
embedding_size)
self.layer_norm = nn.LayerNorm(embedding_size, epsilon=1e-12)
self.dropout = nn.Dropout(hidden_dropout_prob)
def forward(self, input_ids, token_type_ids=None, position_ids=None):
if position_ids is None:
ones = paddle.ones_like(input_ids, dtype="int64")
seq_length = paddle.cumsum(ones, axis=-1)
position_ids = seq_length - ones
position_ids.stop_gradient = True
if token_type_ids is None:
token_type_ids = paddle.zeros_like(input_ids, dtype="int64")
# input embedding
input_embeddings = self.word_embeddings(input_ids)
# position embedding
position_embeddings = self.position_embeddings(position_ids)
# segment embedding
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = input_embeddings + position_embeddings + token_type_embeddings
embeddings = self.layer_norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
接下来是实现ELECTRA模型,本质上还是一个Transformer Encoder,跟BERT的结构无异
class ElectraModel(ElectraPretrainedModel):
def __init__(self, vocab_size, embedding_size, hidden_size,
num_hidden_layers, num_attention_heads, intermediate_size,
hidden_act, hidden_dropout_prob, attention_probs_dropout_prob,
max_position_embeddings, type_vocab_size, initializer_range,
pad_token_id):
super(ElectraModel, self).__init__()
self.pad_token_id = pad_token_id
self.initializer_range = initializer_range
self.embeddings = ElectraEmbeddings(
vocab_size, embedding_size, hidden_dropout_prob,
max_position_embeddings, type_vocab_size)
if embedding_size != hidden_size:
self.embeddings_project = nn.Linear(embedding_size, hidden_size)
encoder_layer = nn.TransformerEncoderLayer(
hidden_size,
num_attention_heads,
intermediate_size,
dropout=hidden_dropout_prob,
activation=hidden_act,
attn_dropout=attention_probs_dropout_prob,
act_dropout=0)
self.encoder = nn.TransformerEncoder(encoder_layer, num_hidden_layers)
self.init_weights()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def forward(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
if attention_mask is None:
attention_mask = paddle.unsqueeze(
(input_ids == self.pad_token_id
).astype(paddle.get_default_dtype()) * -1e9,
axis=[1, 2])
# Embedding
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids)
if hasattr(self, "embeddings_project"):
embedding_output = self.embeddings_project(embedding_output)
# Transformer Encoder
encoder_outputs = self.encoder(embedding_output, attention_mask)
return encoder_outputs
2.2.2 Generator
接下来是ELECTra的Generator部分,需要加载前面实现的electra,然后后面接入一个全连接层。
class ElectraGeneratorPredictions(nn.Layer):
"""Prediction layer for the generator, made up of two dense layers."""
def __init__(self, embedding_size, hidden_size, hidden_act):
super(ElectraGeneratorPredictions, self).__init__()
self.layer_norm = nn.LayerNorm(embedding_size)
self.dense = nn.Linear(hidden_size, embedding_size)
self.act = get_activation(hidden_act)
def forward(self, generator_hidden_states):
hidden_states = self.dense(generator_hidden_states)
hidden_states = self.act(hidden_states)
hidden_states = self.layer_norm(hidden_states)
return hidden_states
class ElectraGenerator(ElectraPretrainedModel):
def __init__(self, electra):
super(ElectraGenerator, self).__init__()
self.electra = electra
self.generator_predictions = ElectraGeneratorPredictions(
self.electra.config["embedding_size"],
self.electra.config["hidden_size"],
self.electra.config["hidden_act"])
if not self.tie_word_embeddings:
self.generator_lm_head = nn.Linear(
self.electra.config["embedding_size"],
self.electra.config["vocab_size"])
else:
self.generator_lm_head_bias = paddle.fluid.layers.create_parameter(
shape=[self.electra.config["vocab_size"]],
dtype=paddle.get_default_dtype(),
is_bias=True)
self.init_weights()
def get_input_embeddings(self):
return self.electra.embeddings.word_embeddings
def forward(self,
input_ids=None,
token_type_ids=None,
position_ids=None,
attention_mask=None):
generator_sequence_output = self.electra(input_ids, token_type_ids,
position_ids, attention_mask)
prediction_scores = self.generator_predictions(
generator_sequence_output)
if not self.tie_word_embeddings:
prediction_scores = self.generator_lm_head(prediction_scores)
else:
prediction_scores = paddle.add(paddle.matmul(
prediction_scores,
self.get_input_embeddings().weight,
transpose_y=True),
self.generator_lm_head_bias)
return prediction_scores
2.2.3 Discriminator
接下来就是判别器的实现,判别器的实现也是ELECTRA后面接入了一个全连接层。
class ElectraDiscriminatorPredictions(nn.Layer):
"""Prediction layer for the discriminator, made up of two dense layers."""
def __init__(self, hidden_size, hidden_act):
super(ElectraDiscriminatorPredictions, self).__init__()
self.dense = nn.Linear(hidden_size, hidden_size)
self.dense_prediction = nn.Linear(hidden_size, 1)
self.act = get_activation(hidden_act)
def forward(self, discriminator_hidden_states):
hidden_states = self.dense(discriminator_hidden_states)
hidden_states = self.act(hidden_states)
logits = self.dense_prediction(hidden_states).squeeze()
return logits
class ElectraDiscriminator(ElectraPretrainedModel):
def __init__(self, electra):
super(ElectraDiscriminator, self).__init__()
self.electra = electra
self.discriminator_predictions = ElectraDiscriminatorPredictions(
self.electra.config["hidden_size"],
self.electra.config["hidden_act"])
self.init_weights()
def forward(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
discriminator_sequence_output = self.electra(
input_ids, token_type_ids, position_ids, attention_mask)
logits = self.discriminator_predictions(discriminator_sequence_output)
return logits
2.2.4 预训练损失函数
最后是训练ELECTRA的损失函数,损失函数包括genrator的损失和discriminator的损失两部分
class ElectraPretrainingCriterion(nn.Layer):
def __init__(self, vocab_size, gen_weight, disc_weight):
super(ElectraPretrainingCriterion, self).__init__()
self.vocab_size = vocab_size
self.gen_weight = gen_weight
self.disc_weight = disc_weight
self.gen_loss_fct = nn.CrossEntropyLoss(reduction='none')
self.disc_loss_fct = nn.BCEWithLogitsLoss(reduction='none')
def forward(self, generator_prediction_scores,
discriminator_prediction_scores, generator_labels,
discriminator_labels, attention_mask):
# generator loss
gen_loss = self.gen_loss_fct(
paddle.reshape(generator_prediction_scores, [-1, self.vocab_size]),
paddle.reshape(generator_labels, [-1]))
# todo: we can remove 4 lines after when CrossEntropyLoss(reduction='mean') improved
umask_positions = paddle.zeros_like(generator_labels).astype(
paddle.get_default_dtype())
mask_positions = paddle.ones_like(generator_labels).astype(
paddle.get_default_dtype())
mask_positions = paddle.where(generator_labels == -100, umask_positions,
mask_positions)
if mask_positions.sum() == 0:
gen_loss = paddle.to_tensor([0.0])
else:
gen_loss = gen_loss.sum() / mask_positions.sum()
# discriminator loss
seq_length = discriminator_labels.shape[1]
disc_loss = self.disc_loss_fct(
paddle.reshape(discriminator_prediction_scores, [-1, seq_length]),
discriminator_labels.astype(paddle.get_default_dtype()))
if attention_mask is not None:
umask_positions = paddle.ones_like(discriminator_labels).astype(
paddle.get_default_dtype())
mask_positions = paddle.zeros_like(discriminator_labels).astype(
paddle.get_default_dtype())
use_disc_loss = paddle.where(attention_mask, disc_loss,
mask_positions)
umask_positions = paddle.where(attention_mask, umask_positions,
mask_positions)
disc_loss = use_disc_loss.sum() / umask_positions.sum()
else:
total_positions = paddle.ones_like(discriminator_labels).astype(
paddle.get_default_dtype())
disc_loss = disc_loss.sum() / total_positions.sum()
return self.gen_weight * gen_loss + self.disc_weight * disc_loss
2.3 标点符号预测任务
以前这个研究方向叫“sentence boundary detection”,现在叫predict punctuation或者punctuation restoration。使用深度学习做标点符号预测主要可以分为三类:
- 基于声学特征的方法。这类方法根据人在说话时的停顿进行标点符号预测,但在真实的ASR系统中,如果出现不自然的停顿,其预测能力会下降。
- 基于文本特征的方法。文本数据间往往类型不同,比如,在人民日报数据集上训练出的模型在一些闲聊的数据集上难以奏效。
- 结合文本与声学特征的方法。这类方法效果好,但是要求数据集同时有语音数据以及ASR转录本,数据难以获取。
本实验采用的是Discriminator来做标点符号预测任务,标点符号预测本质上是一种序列标注任务。本实验预测的标点符号有逗号,句号,问号3种。如果读者有兴趣也可以把其他类型的标点符号加进去。
3、代码实践
3.1 导入库包
import os
import xml.etree.ElementTree as ET
import codecs
from collections import Counter
import re
import ujson
import pandas as pd
import random
import time
import math
from functools import partial
import inspect
from tqdm import tqdm
import collections
import numpy as np
import paddle
from paddle.io import DataLoader
from paddle.dataset.common import md5file
import paddlenlp as ppnlp
from paddlenlp.transformers import LinearDecayWithWarmup
from paddlenlp.transformers import ElectraForTokenClassification, ElectraTokenizer
from paddlenlp.data import Stack, Tuple, Pad, Dict
from paddlenlp.datasets import DatasetBuilder
from paddlenlp.utils.env import DATA_HOME
from sklearn import metrics # https://scikit-learn.org/stable/modules/classes.html#module-sklearn.metrics
from sklearn.metrics import classification_report
3.2 数据预处理
由于数据集解压之后是xml格式的,所以需要提取出来,然后进行切分,构造成数据集。
本次用到的数据集是IWSLT12,来源于http://hltc.cs.ust.hk/iwslt/index.html 。我们也能在Aistudio公开数据集找到它。
!unzip -o IWSLT12.zip -d IWSLT12
data_path = "IWSLT12/"
file_path = data_path + "IWSLT12.TALK.dev2010.en-fr.en.xml"
xmlp = ET.XMLParser(encoding="utf-8")
tree = ET.parse(file_path, parser=xmlp)
root = tree.getroot()
docs = []
for doc_id in range(len(root[0])):
doc_segs = []
doc = root[0][doc_id]
for seg in doc.iter('seg'):
doc_segs.append(seg.text)
docs.extend(doc_segs)
dev_texts = [re.sub(r'\s+', ' ', ''.join(d)).strip() for d in docs]
with open(data_path + 'dev_texts.txt', 'w', encoding='utf-8') as f:
for text in dev_texts:
f.write(text + '\n')
file_path = data_path + "IWSLT12.TED.MT.tst2012.en-fr.en.xml"
xmlp = ET.XMLParser(encoding="utf-8")
tree = ET.parse(file_path, parser=xmlp)
root = tree.getroot()
docs = []
for doc_id in range(len(root[0])):
doc_segs = []
doc = root[0][doc_id]
for seg in doc.iter('seg'):
doc_segs.append(seg.text)
docs.extend(doc_segs)
test_texts_2012 = [re.sub(r'\s+', ' ', ''.join(d)).strip() for d in docs]
with open(data_path + 'test_texts_2012.txt', 'w', encoding='utf-8') as f:
for text in test_texts_2012:
f.write(text + '\n')
file_path = data_path + "train.tags.en-fr.en.xml"
with open(file_path) as f:
xml = f.read()
tree = ET.fromstring("" + xml + "")
docs = []
for doc in tree.iter('transcript'):
text_arr=doc.text.split('\n')
text_arr=[item.strip() for item in text_arr if(len(item.strip())>2)]
# print(text_arr)
docs.extend(text_arr)
# break
train_texts=docs
with open(data_path + 'train_texts.txt', 'w', encoding='utf-8') as f:
for text in train_texts:
f.write(text + '\n')
# 数据读取
with open(data_path + 'train_texts.txt', 'r', encoding='utf-8') as f:
train_text = f.readlines()
with open(data_path + 'dev_texts.txt', 'r', encoding='utf-8') as f:
valid_text = f.readlines()
with open(data_path + 'test_texts_2012.txt', 'r', encoding='utf-8') as f:
test_text = f.readlines()
train_text[0]
datasets = train_text, valid_text, test_text
def clean_text(text):
'''
文本处理:将符号替换为’‘,’.‘,','以及‘?’之一
'''
text = text.replace('!', '.')
text = text.replace(':', ',')
text = text.replace('--', ',')
reg = "(?<=[a-zA-Z])-(?=[a-zA-Z]{2,})"
r = re.compile(reg, re.DOTALL)
text = r.sub(' ', text)
text = re.sub(r'\s-\s', ' , ', text)
# text = text.replace('-', ',')
text = text.replace(';', '.')
text = text.replace(' ,', ',')
text = text.replace('♫', '')
text = text.replace('...', '')
text = text.replace('.\"', ',')
text = text.replace('"', ',')
text = re.sub(r'--\s?--', '', text)
text = re.sub(r'\s+', ' ', text)
text = re.sub(r',\s?,', ',', text)
text = re.sub(r',\s?\.', '.', text)
text = re.sub(r'\?\s?\.', '?', text)
text = re.sub(r'\s+', ' ', text)
text = re.sub(r'\s+\?', '?', text)
text = re.sub(r'\s+,', ',', text)
text = re.sub(r'\.[\s+\.]+', '. ', text)
text = re.sub(r'\s+\.', '.', text)
return text.strip().lower()
datasets = [[clean_text(text) for text in ds] for ds in datasets]
- 利用electra的分词工具进行分词,然后构造数据集
model_name_or_path='electra-base'
tokenizer = ElectraTokenizer.from_pretrained(model_name_or_path)
punctuation_enc = {
'O': '0',
',': '1',
'.': '2',
'?': '3',
}
# 以一个文本序列为例,构建模型需要的数据集
example_sentence="all the projections [ say that ] this one [ billion ] will [ only ] grow with one to two or three percent"
print('Use the example sentence to create the dataset:', example_sentence)
example_text=tokenizer.tokenize(example_sentence)
print(example_text)
label=[]
cur_text=[]
for item in example_text:
if(item in punctuation_enc):
print(item)
label.pop()
label.append(punctuation_enc[item])
else:
cur_text.append(item)
label.append(punctuation_enc['O'])
# label=[item for item in text]
print(label)
print(cur_text)
print(len(label))
print(len(cur_text))
# 依照上述的构建流程封装成 format_data
def format_data(train_text):
'''
依据文本中出现的符号,分别生成文本tokens以及对应标签
return:
texts:文本tokens列表,每一个item是一个文本样本对应的tokens列表
labels:标点符号标签列表,每一个item是一个标点符号标签列表,代表token的下一个位置的标点符号
'''
labels=[]
texts=[]
for line in tqdm(train_text):
line=line.strip()
if(len(line)==2):
print(line)
continue
text=tokenizer.tokenize(line)
label=[]
cur_text=[]
flag=True
for item in text:
if(item in punctuation_enc):
# print(item)
if(len(label)>0):
label.pop()
label.append(punctuation_enc[item])
else:
print(text)
falg=False
break
else:
cur_text.append(item)
label.append(punctuation_enc['O'])
if(flag):
labels.append(label)
texts.append(cur_text)
return texts,labels
# 构建训练集
train_texts,labels=format_data(train_text)
print(len(train_texts))
print(train_texts[0])
print(labels[0])
def output_to_tsv(texts,labels,file_name):
data=[]
for text,label in zip(texts,labels):
if(len(text)!=len(label)):
print(text)
print(label)
continue
data.append([' '.join(text),' '.join(label)])
df=pd.DataFrame(data,columns=['text_a','label'])
df.to_csv(file_name,index=False,sep='\t')
def output_to_train_tsv(texts,labels,file_name):
data=[]
for text,label in zip(texts,labels):
if(len(text)!=len(label)):
print(text)
print(label)
continue
if(len(text)==0):
continue
data.append([' '.join(text),' '.join(label)])
# data=data[65000:70000]
df=pd.DataFrame(data,columns=['text_a','label'])
df.to_csv(file_name,index=False,sep='\t')
output_to_train_tsv(train_texts,labels,'train.tsv')
test_texts,labels=format_data(test_text)
output_to_tsv(test_texts,labels,'test.tsv')
print(len(test_texts))
print(test_texts[0])
print(labels[0])
valid_texts,labels=format_data(valid_text)
output_to_tsv(valid_texts,labels,'dev.tsv')
print(len(valid_texts))
print(valid_texts[0])
print(labels[0])
raw_path='.'
train_file = os.path.join(raw_path, "train.tsv")
dev_file = os.path.join(raw_path, "dev.tsv")
train_data=pd.read_csv(train_file,sep='\t')
train_data.head()
# 数据清洗后的测试集样本数量
len(train_data)
def write_json(filename, dataset):
print('write to'+filename)
with codecs.open(filename, mode="w", encoding="utf-8") as f:
ujson.dump(dataset, f)
3.3 构建Dataset
class TEDTalk(DatasetBuilder):
SPLITS = {
'train': 'train.tsv',
'dev':'dev.tsv',
'test': 'test.tsv'
}
def _get_data(self, mode, **kwargs):
default_root='.'
self.mode=mode
filename = self.SPLITS[mode]
fullname = os.path.join(default_root, filename)
return fullname
def _read(self, filename, *args):
df=pd.read_csv(filename,sep='\t')
for idx,row in df.iterrows():
text=row['text_a']
if(type(text)==float):
print(text)
continue
tokens=row['text_a'].split()
tags=row['label'].split()
yield {"tokens": tokens, "labels": tags}
def get_labels(self):
return ["0", "1", "2", "3"]
def load_dataset(path_or_read_func,
name=None,
data_files=None,
splits=None,
lazy=None,
**kwargs):
reader_cls = TEDTalk
print(reader_cls)
if not name:
reader_instance = reader_cls(lazy=lazy, **kwargs)
else:
reader_instance = reader_cls(lazy=lazy, name=name, **kwargs)
datasets = reader_instance.read_datasets(data_files=data_files, splits=splits)
return datasets
def tokenize_and_align_labels(example, tokenizer, no_entity_id,
max_seq_len=512):
labels = example['labels']
example = example['tokens']
# print(labels)
tokenized_input = tokenizer(
example,
return_length=True,
is_split_into_words=True,
max_seq_len=max_seq_len)
# -2 for [CLS] and [SEP]
if len(tokenized_input['input_ids']) - 2 < len(labels):
labels = labels[:len(tokenized_input['input_ids']) - 2]
tokenized_input['labels'] = [no_entity_id] + labels + [no_entity_id]
tokenized_input['labels'] += [no_entity_id] * (
len(tokenized_input['input_ids']) - len(tokenized_input['labels']))
# print(tokenized_input)
return tokenized_input
加载dataset
# Create dataset, tokenizer and dataloader.
train_ds, test_ds = load_dataset('TEDTalk', splits=('train', 'test'), lazy=False)
label_list = train_ds.label_list
label_num = len(label_list)
# no_entity_id = label_num - 1
no_entity_id=0
print(label_list)
3.4 组装Batch和Padding
batch_size=128
ignore_label = -100
max_seq_length=128
trans_func = partial(
tokenize_and_align_labels,
tokenizer=tokenizer,
no_entity_id=no_entity_id,
max_seq_len=max_seq_length)
batchify_fn = lambda samples, fn=Dict({
'input_ids': Pad(axis=0, pad_val=tokenizer.pad_token_id, dtype='int32'), # input
'token_type_ids': Pad(axis=0, pad_val=tokenizer.pad_token_type_id, dtype='int32'), # segment
'seq_len': Stack(dtype='int64'), # seq_len
'labels': Pad(axis=0, pad_val=ignore_label, dtype='int64') # label
}): fn(samples)
train_batch_sampler = paddle.io.DistributedBatchSampler(
train_ds, batch_size=batch_size, shuffle=True, drop_last=True)
train_ds = train_ds.map(trans_func)
train_data_loader = DataLoader(
dataset=train_ds,
collate_fn=batchify_fn,
num_workers=0,
batch_sampler=train_batch_sampler,
return_list=True)
test_ds = test_ds.map(trans_func)
test_data_loader = DataLoader(
dataset=test_ds,
collate_fn=batchify_fn,
num_workers=0,
batch_size=batch_size,
return_list=True)
for index,data in enumerate(train_data_loader):
# print(len(data))
print(index)
print(data)
break
3.5 模型配置
device='gpu'
num_train_epochs=1
warmup_steps=0
model_name_or_path='electra-base'
max_steps=-1
learning_rate=5e-5
adam_epsilon=1e-8
weight_decay=0.0
paddle.set_device(device)
global_step = 0
logging_steps=200 # 日志的保存周期
last_step = num_train_epochs * len(train_data_loader)
tic_train = time.time()
save_steps=200 # 模型保存周期
output_dir='checkpoints/' # 模型保存目录
3.6 模型构建
# Define the model netword and its loss
model = ElectraForTokenClassification.from_pretrained(model_name_or_path, num_classes=label_num)
3.6.1 设置AdamW优化器
num_training_steps = max_steps if max_steps > 0 else len(
train_data_loader) * num_train_epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps,
warmup_steps)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
epsilon=adam_epsilon,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
3.6.2 设置CrossEntropy损失函数
loss_fct = paddle.nn.loss.CrossEntropyLoss(ignore_index=ignore_label)
3.6.3 设置评估方式
metric = paddle.metric.Accuracy()
def compute_metrics(labels, decodes, lens):
decodes = [x for batch in decodes for x in batch]
lens = [x for batch in lens for x in batch]
labels=[x for batch in labels for x in batch]
outputs = []
nb_correct=0
nb_true=0
val_f1s=[]
label_vals=[0,1,2,3]
y_trues=[]
y_preds=[]
for idx, end in enumerate(lens):
y_true = labels[idx][:end].tolist()
y_pred = [x for x in decodes[idx][:end]]
nb_correct += sum(y_t == y_p for y_t, y_p in zip(y_true, y_pred))
nb_true+=len(y_true)
y_trues.extend(y_true)
y_preds.extend(y_pred)
score = nb_correct / nb_true
# val_f1 = metrics.f1_score(y_trues, y_preds, average='micro', labels=label_vals)
result=classification_report(y_trues, y_preds)
# print(val_f1)
return score,result
3.7 模型训练
def evaluate(model, loss_fct, data_loader, label_num):
model.eval()
pred_list = []
len_list = []
labels_list=[]
for batch in data_loader:
input_ids, token_type_ids, length, labels = batch
logits = model(input_ids, token_type_ids)
loss = loss_fct(logits, labels)
avg_loss = paddle.mean(loss)
pred = paddle.argmax(logits, axis=-1)
pred_list.append(pred.numpy())
len_list.append(length.numpy())
labels_list.append(labels.numpy())
accuracy,result=compute_metrics(labels_list, pred_list, len_list)
print("eval loss: %f, accuracy: %f" % (avg_loss, accuracy))
print(result)
model.train()
# evaluate(model, loss_fct, metric, test_data_loader,label_num)
for epoch in range(num_train_epochs):
for step, batch in enumerate(train_data_loader):
global_step += 1
input_ids, token_type_ids, _, labels = batch
logits = model(input_ids, token_type_ids)
loss = loss_fct(logits, labels)
avg_loss = paddle.mean(loss)
if global_step % logging_steps == 0:
print("global step %d, epoch: %d, batch: %d, loss: %f, speed: %.2f step/s"
% (global_step, epoch, step, avg_loss,
logging_steps / (time.time() - tic_train)))
tic_train = time.time()
avg_loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
if global_step % save_steps == 0 or global_step == last_step:
if paddle.distributed.get_rank() == 0:
evaluate(model, loss_fct, test_data_loader,
label_num)
paddle.save(model.state_dict(),os.path.join(output_dir,
"model_%d.pdparams" % global_step))
3.8 模型保存
paddle.save(model.state_dict(),os.path.join(output_dir,
"model_final.pdparams"))
3.9 模型预测
3.9.1 加载训练好的模型
init_checkpoint_path=os.path.join(output_dir,'model_final.pdparams')
model_dict = paddle.load(init_checkpoint_path)
model.set_dict(model_dict)
punctuation_dec = {
'0': 'O',
'1': ',',
'2': '.',
'3': '?',
}
3.9.2 预测输出
def parse_decodes(input_words, id2label, decodes, lens):
decodes = [x for batch in decodes for x in batch]
lens = [x for batch in lens for x in batch]
outputs = []
for idx, end in enumerate(lens):
sent = input_words[idx]['tokens']
tags = [id2label[x] for x in decodes[idx][1:end]]
sent_out = []
tags_out = []
for s, t in zip(sent, tags):
if(t=='0'):
sent_out.append(s)
else:
# sent_out.append(s)
sent_out.append(s+punctuation_dec[t])
sent=' '.join(sent_out)
sent=sent.replace(' ##','')
outputs.append(sent)
return outputs
id2label = dict(enumerate(test_ds.label_list))
raw_data = test_ds.data
model.eval()
pred_list = []
len_list = []
for step, batch in enumerate(test_data_loader):
input_ids, token_type_ids, length, labels = batch
logits = model(input_ids, token_type_ids)
pred = paddle.argmax(logits, axis=-1)
pred_list.append(pred.numpy())
len_list.append(length.numpy())
preds = parse_decodes(raw_data, id2label, pred_list, len_list)
3.9.3 写入到文件
file_path = "results.txt"
with open(file_path, "w", encoding="utf8") as fout:
fout.write("\n".join(preds))
# Print some examples
print("The results have been saved in the file: %s, some examples are shown below: " % file_path)
print("\n".join(preds[:5]))
【实践】NLP领域的ELECTRA在符号预测上的应用