python多线程爬虫
之前博客中介绍的爬取实战都是使用单线程的方法进行爬取。
简单的理解就是只有一个生产者和一个消费者。生产者负责生产出来之后,就由消费者进行消费。属于一对一过程,而多线程属于多个生产者同时生产,由多个消费者同时消费,属于多对多的过程,这就大大的增加了爬取效率。
我们本章主要介绍一下这个过程
设计一个关于生产者赚钱和消费者花钱的这样一个程序!具体及注释看下方代码:
import threading#导入线程的库
import random
import time
gMoney=0
gCondition=threading.Condition()
gTime=0
class Producer(threading.Thread):#定义生产者类
def run(self) -> None:
global gMoney #定义为全球变量
global gTime
while True:
gCondition.acquire()#获取线程
if gTime>=10:#如果生产者生产次数大于10
gCondition.release()#释放线程并推出循环
break
money=random.randint(0,100)#生产的钱在0,100之间随机取
gMoney+=money#赋值给生产的钱
gTime+=1#生产次数加一
print("%s生产了%d元"%(threading.current_thread().name,money))##生产者的名字和生产的钱
gCondition.notify_all()#唤醒所有等待的线程
gCondition.release()#释放掉当前线程
time.sleep(1)
#整个过程是获取线程-唤醒所有等待的其他线程-然后把当前线程释放掉(在取获取线程这样的一个过程)
class Consumer(threading.Thread):
def run(self) -> None:
global gMoney#消费者主要负责花钱,直至花完,所以不用定义次数
while True:#进入循环
gCondition.acquire()#获取次数
money=random.randint(0,100)#花钱的数量
while gMoney<money:#当剩的钱不足以支撑花的钱的时候
if gTime>=10:#消费者消费大于等于10次后
print("%s想要消费%d元,但是目前只有%d元,生产者已经不在生产!"%(threading.current_thread().name,money,gMoney))
gCondition.release()
return
print("%s想要消费%d元,但是目前只有%d元,消费失败!"%(threading.current_thread().name,money,gMoney))#不大于10次时候就不足以支持消费者花销,打印消费失败!
gCondition.wait()#消费者线程等待,等待生产者为他生产
gMoney-=money
print("%s想要消费%d元,目前剩余只有%d元"%(threading.current_thread().name,money,gMoney))
gCondition.release()
time.sleep(1)
def main():
for i in range(5):
th=Producer(name='生产者%d号'% i)
th.start()#制造5个生产者
for i in range(5):
th=Consumer(name="消费者%d号"% i)
th.start()#制造5个消费者者
if __name__=="__main__":
main()
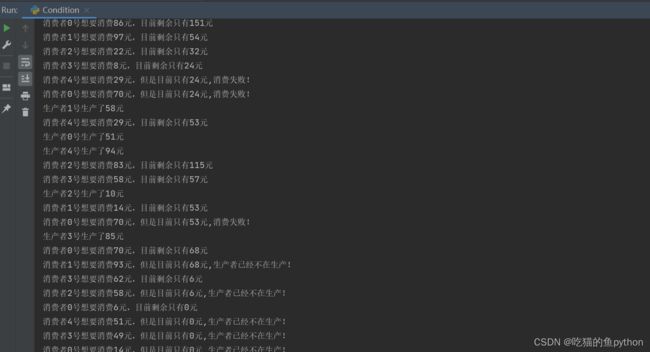
生产者进程是生产10次之后就停止生产了,消费者进程是当消费次数大于10次,把每个消费者进程释放掉然后结束程序。
整体思路框架就是:
生产者进行生产-消费者消费-如果遇到了消费金额大于目前所有的金额且生产次数不大于10次,显示消费失败。如果遇到了消费金额大于目前所有的金额且生产次数超过10次,显示生产者已经不再生产,且每次都把当前消费者线程释放掉,直到把五个消费者线程全部释放,则结束程序。
多线程对比于单线程进行爬虫工作,效率大大的提升了!!!