【MySQL自学之路】第2天——关系代数计算【理论知识】
目录
前言
基础名词
关系
候选码
关系运算
传统的集合计算(二目运算)
样例表创建【SQL】
专门的关系运算
后记
销毁已经创建的表
前言
在上一节我们提到了关系型数据库和非关系型数据库之间的关系,我们主要以MySQL关系型数据库为主展开。关系模型是建立在集合代数的基础上的,我们从集合论的角度给出关系数据结构的形式化的定义。
注:博客内标蓝色背景的是教材原话,黄色背景的是博主自己理解的加注,绿色背景的为引用。
基础名词
关系
定义:
D1xD2xD3x...xDn的子集叫做在域D1、D2、...、Dn上的关系,表示为 R(D1,D2,...,Dn)
这里R是关系的名字,n是关系的目或者度。
n目关系必有n种属性。
这里的D不是属性,只是R中的元素,属性是D的再分。
例如:R(AB,B,BC),属性是A、B、C
候选码
某一属性组的值能够唯一地标识一个元组,而其子集不能,则称该属性组为候选码。
上句话的意思是关系R里面的每一个属性或者元素都可以用候选码推出。
候选码的属性称为主属性。
不包含在候选码里面的属性称为非主属性。
关系运算
注:每一种关系运算均可以用SQL语句来实现。
传统的集合计算(二目运算)
(1)并
R ∪ S = {t | t ∈ R ∨ t ∈ S}
(2)差
R - S = {t | t ∈ R ∧ t
S}
(3)交
R ∩ S = {t | t ∈ R ∧ t ∈ S}
R ∩ S = R -(R - S)
(4)笛卡儿积
R x S = {tr ts | tr ∈ R ∧ ts ∈ S}
例如:R(a,b) S(c,d)
R x S = {(a, c),(a, d),(b, c),(b, d)}
其中(a,c)等也成为元组,该元组中a、c分别叫做该元组的分量。
样例表创建【SQL】
(1)创建数据库sqlstudy
(2)在数据库sqlstudy下面创建表students
(3)students表内有sno、sname、sage三个字段
(4)现保存两位同学的信息:('123456789','aaa',12),('111111111', 'bbb', 13)
create database sqlstudy;
use sqlstudy;
create table students(
sno char(9) primary key,
sname char(20),
sage int
);
insert
into students
values('123456789','aaa',12);
insert
into students
values('111111111', 'bbb', 13);
select * from students;注:这里的SQL不用记,只是方便演示效果,SQL语句后面会逐一讲解。
专门的关系运算
(1)选择
选择又称为限制。它是在关系R中选择满足给定条件的诸元组。
δF(R) = {t | t ∈ R ∧ F(t)='真'}
其中F表示选择条件,它是一个逻辑表达式,取逻辑值“真”或“假”。
例如:查询所有年龄大于10岁的学生。
δ sage > 10 (students)
SQL语句:
select *
from students
where sage > 10;总结 :
选择是找出满足条件的所有学生的所有信息。 是行查询操作。
(2)投影
关系R上的投影是从R中选择出若干属性列组成新的关系。投影操作是从列的角度进行的运算。
ПA(R) = {t[A] | t ∈ R}
例如:查询学生关系students中都有哪些人(姓名)。
Пsname(students)
SQL语句:
select sname
from students;
总结 :
投影操作是从列的角度进行的运算。
(3)连接
连接也称为θ连接。它是从两个关系的笛卡尔积中选取属性间满足一定条件的元组。
θ为“=”的连接运算称为等值连接。
自然连接:
两个关系中进行比较的分量必须是同名的属性组,并且在结果中把重复的属性列去掉。
自然连接是一种特殊的等值连接。
总结:
连接是建立在多张数据库表的基础上。通过连接可以将多张表的数据通过共同的字段进行拼接,且拼接后的表去掉了重复字段的称为自然连接。
SQL语句:
create table homes
(
sno char(9) primary key,
shome char(20)
);
insert
into homes
values('123456789','hahaha');
insert
into homes
values('111111111', 'xixixi');
select *
from homes, students
where homes.sno=students.sno;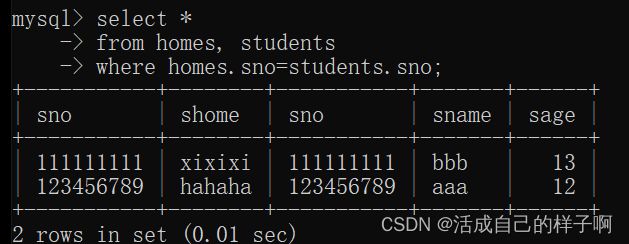
以上情况是两个表的数据正好一一对应,如果此时我再向表中再加入一个数据:
insert
into homes
values('222222222', 'lalala');
select *
from homes;此时在做连接:
select *
from homes, students
where homes.sno=students.sno;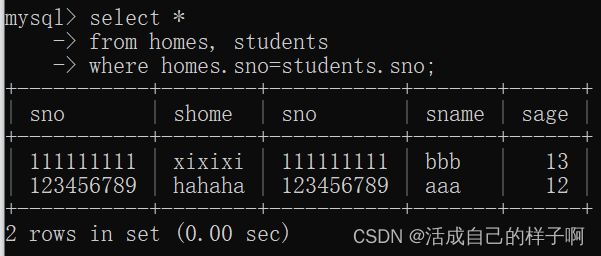
注:可以看到新加入的一行数据并没有在连接里面出现,因为students表里面并没有这个学生的信息。 我们把这个被舍弃的元组(一行数据)称为悬浮元组。
悬浮元组:
两个关系R和S在做自然连接时,选择两个关系再公共属性上值相等的元组构成新的关系。此时,关系R中某些元组有可能在S中不存在公共属性上值相等的元组,从而造成R中这些元组在操作时被舍弃了。这些被舍弃的元组称为悬浮元组。
外连接:
如果把悬浮元组也保存在结果关系中,而在其他属性上填空值(NULL),那么这种连接就叫做外连接。
左外连接:
只保留左边关系R的悬浮元组,其他地方写空值。
右外连接:
只保留右边关系S的悬浮元组,其他地方写空值。
注:SQL可以通过outer join on等关键字实现外连接来保留悬浮元组,详细内容会在之后的章节在说明。这里只做大概的说明。
(4)除运算
设关系R除以关系S的结果为关系T,则T包含所有在R但不在S中的属性以及值,且T的元组与S的元组的所有组合都在R中。
R ÷ S = {tr[X] | tr ∈ R ∧ Пy(S)
Yx}
其中Yx为x在R中的象集
注:
(1)除是同时从行和列角度进行运算的。
(2)交、连接、除均可以用并、差、笛卡尔积、选择和投影这五种基本运算来表达,通常我们在计算除法的时候都会将其转换为基本运算式。
从集合论上进行举例:
| A | B | C |
| a1 | b1 | c2 |
| a2 | b3 | c7 |
| a3 | b4 | c6 |
| a1 | b2 | c3 |
| a4 | b6 | c6 |
| a2 | b2 | c3 |
| a1 | b2 | c1 |
| B | C | D |
| b1 | c2 | d1 |
| b2 | c1 | d1 |
| b2 | c3 | d2 |
| A |
| a1 |
计算步骤:
(1)找到公共属性列(B、C)
(2)计算关系R里面不是公共属性列(A)的所有取值(a1,a2,a3,a4)。
(3)分别计算步骤(2)得到结果的象集 :
a1象集:{(b1, c2),(b2, c3),(b2, c1)}
a2象集:{(b3, c7),(b2, c3)}
a3象集:{(b4, c6)}
a4象集:{(b6, c6)}
(4)计算S在(B,C)上的投影:{(b1, c2),(b2, c1),(b2, c3)}
(5)因为a1的象集 S在(B,C)上的投影,故结果为a1。
从SQL语句上进行举例:(通过SQL语句实现除法运算会涉及部分新的知识点在后面,可以先看后面的章节,再回来学习SQL的除法运算)
R(X,Y)
S(Y,Z)
select distinct R.X from R R1
where not exists
(
select S.Y from S
where not exists
(
select * from R R2
where R2.X=R1.X and R2.Y=S.Y
)
);后记
销毁已经创建的表
drop table homes;
drop table students;注:这里销毁已经创建的表是为了之后的章节可以独立于之前的章节,避免小伙伴们找不到例题中的表。