(四)使用CNN实现文本情感分析(Pytorch)
文章目录
-
- 准备数据
- 搭建模型
- 实现细节
- 训练模型
- 用户输入
- 完整代码
在之前的笔记中,我们设法使用RNNs和 Bag of Tricks for Efficient Text Classification中的FastText模型实现了约85%的测试准确率。在这篇笔记中,我们将使用卷积神经网络(CNN)进行情感分析,实现 Convolutional Neural Networks for Sentence Classification这篇论文中的模型。
注意:本教程不是为了全面介绍和解释cnn。要获得更好更深入的解释,请点击这里和这里。
传统上,cnn是用来分析图像的,它由一个或多个卷积层和一个或多个线性层组成。卷积层使用过滤器(也称为内核或接受域)扫描一张图像,并生成一张经过处理的图像。这个处理过的图像版本可以被送入另一个卷积层或线性层。每个滤镜都有一个形状,例如,一个3x3滤镜覆盖图像的3像素宽X3像素高的区域,滤镜的每个元素都有一个权重,3x3滤镜有9个权重。在传统的图像处理中,这些权值是由工程师手工指定的,然而,神经网络中的卷积层的主要优点是这些权值是通过反向传播学习的。
学习权重背后的直觉思想是你的卷积层表现得像特征提取器,提取图像的部分是你的CNN最重要的目标,例如,如果使用一个CNN在一个图像中检测面部,CNN可能在图像中寻找鼻子,嘴巴和一双眼睛的特征。
那么,为什么要在文本上使用cnn呢?以同样的方式,一个3x3滤镜可以查看一个图像的碎片,一个1x2滤镜可以查看一段文本中的2个连续的单词,即bi-gram。在前面的教程中我们看FastText模型使用bi-grams通过显式地将它们添加到一个文本,在CNN模型中,我们将使用多个大小不同的过滤器来观察bi-grams (1 x2 filter),tri-grams (1 x3 filter)和n-grams(1 x n filter)内的文本。
这里的直觉是,在评论中出现某些 bi-grams, tri-grams 和 n-grams是最终情感的良好指示。
准备数据
与之前的笔记一样,我们将先准备数据。
与前面使用FastText模型的笔记不同,我们将不再显式地创建bi-grams并将它们附加到句子末尾。
因为卷积层希望batch维度是第一个,所以我们可以告诉TorchText使用字段(field)上的batch_first = True参数返回已经排列过的数据。
import torch
from torchtext import data
from torchtext import datasets
import random
import numpy as np
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
TEXT = data.Field(tokenize='spacy', tokenizer_language='en_core_web_sm', batch_first=True)
LABEL = data.LabelField(dtype = torch.float)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
train_data, valid_data = train_data.split(random_state = random.seed(SEED))
构建词汇表并加载预先训练的单词嵌入。
MAX_VOCAB_SIZE = 25_000
TEXT.build_vocab(train_data,
max_size = MAX_VOCAB_SIZE,
vectors = "glove.6B.100d",
unk_init = torch.Tensor.normal_)
LABEL.build_vocab(train_data)
与之前一样,我们创建迭代器。
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
搭建模型
现在来搭建我们的模型。
第一个主要障碍是如何将cnn用于文本可视化。图像通常是二维的(我们现在将忽略存在第三个“颜色”维度的事实),而文本是一维的。然而,我们知道,在我们之前的教程中(以及几乎所有的NLP管道),第一步都是将单词转换为词嵌入。这就是我们在二维空间中可视化单词的方法,每个单词沿着一个轴,向量元素沿着另一个轴。观察下面嵌入句子的二维表示:

然后我们可以使用[n x emb_dim]的过滤器。这将完全覆盖 n n n顺序单词,因为它们的宽度将是emb_dim维度。观察下面的图像,我们的单词向量是用绿色表示的。这里我们有4个5维嵌入的单词,创建一个[4x5]“图像”张量。一次覆盖两个单词的过滤器(例如bi-grams)将是[2x5]过滤器,用黄色表示,过滤器的每个元素都有一个权重与它相关联。这个过滤器的输出(用红色显示)将是一个单个实数,它是过滤器覆盖的所有元素的加权和。
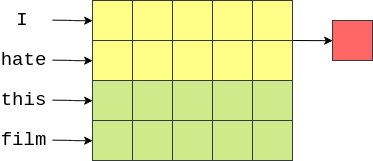
然后,过滤器将“下移”图像(或在句子中移动)以覆盖下一个bi-gram,并计算另一个输出(加权和)。
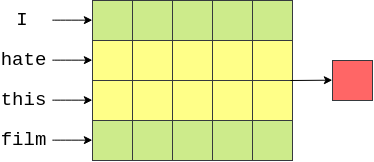
最后,过滤器再次向下移动,并计算该过滤器的最终输出。

在我们的例子中(在一般情况下,滤镜的宽度等于“图像”的宽度),我们的输出将会是一个向量的元素个数等于图像的高度(或句子中单词的个数)减去滤镜的高度再加 1,比如在上面例子中的4 - 2 + 1 = 3。
这个例子展示了如何计算一个过滤器的输出。我们的模型(以及几乎所有的cnn)会有很多这样的过滤器。其理念是,每个过滤器将学习不同的特征来提取。在上面的例子中,我们希望每个[2 x emb_dim]的过滤器将寻找不同bi-grams的出现。
在我们的模型中,我们也将有不同大小的过滤器,高度为3、4和5,每一个都有100个。直觉告诉我们,我们将寻找与分析电影评论情绪相关的不同的 tri-grams, 4-grams 和 5-grams。
我们模型中的下一步是在卷积层的输出上使用池化(特别是最大池化)。这类似于FastText模型,在该模型中,我们对每个单词向量执行平均值(由F.avg_pool2d函数实现),但在这不是对维度进行平均值,我们是取一个维度上的最大值。下面是一个从卷积层的输出中取最大值(0.9)的例子(没有显示的是应用到卷积输出的激活函数)。
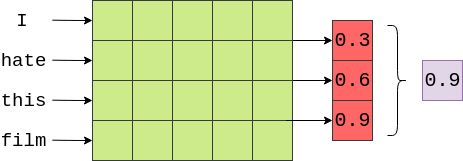
这里的想法是,最大值是决定评论情绪的“最重要”特征,对应于评论中“最重要”的n-gram。我们怎么知道“最重要的”n-gram是什么?幸运的是,我们不需要这样做!通过反向传播,过滤器的权值被改变,因此每当看到某些n-grams高度象征情绪时,过滤器的输出是一个“高”值。如果这个“高”值是输出中的最大值,那么它将通过最大池化层。
因为我们的模型有100个3种不同尺寸的过滤器,这意味着我们有300个不同的模型认为重要的n-grams。我们把这些连接在一起成为一个单一的向量,并通过一个线性层来预测情感。我们可以将这一线性层的权重看作是对每一个300个中n-grams的“加权证据”,然后做出最终决定。
实现细节
我们用nn.Conv2d来实现卷积层。in_channels参数是图像进入卷积层的“通道”的数量。在实际的图像中,这通常是3个通道(红色、蓝色和绿色通道各一个通道),然而,当使用文本时,我们只有一个通道,即文本本身。out_channels是过滤器的数量,kernel_size是过滤器的大小。每个kernel_sizes大小都是[n x emb_dim],其中 n n n是 n-grams的大小。
在PyTorch中,RNNs想要batch维度在第二位,而CNNs想要batch维度在第一位——我们不必在这里对数据进行排列,因为我们已经在文本字段中设置了batch_first = True。然后我们通过嵌入层传递句子来获得嵌入。输入到nn.Conv2d层的第二个维度必须是通道维数。由于文本在技术上没有通道维度,我们将张量unsqueeze 以创建一个通道维度。这与卷积层初始化时的in_channels=1相匹配。
然后我们将张量通过卷积层和池化层,在卷积层之后使用ReLU激活函数。池化层的另一个很好的特性是它们处理不同长度的句子。卷积层输出的大小取决于对卷积层输入的大小,不同批次包含不同长度的句子。如果没有最大池化层,线性层的输入将取决于输入句子的大小(而不是我们想要的大小)。解决这个问题的一种方法是将所有的句子修剪成相同的长度,但是对于最大池化层,我们总是知道线性层的输入将是过滤器的总数。注意:那么有一个例外,如果你的句子长度比使用的最大的过滤器短,然后你将不得不填充你的句子到最大的过滤器的长度。在IMDb数据中没有只有5个词长的评论,所以我们不需要担心,但如果你使用自己的数据,你会担心的。
最后,我们对过滤器的输出进行串联并执行dropout,然后将它们通过线性层来做出我们的预测。
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim,
dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx)
self.conv_0 = nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (filter_sizes[0], embedding_dim))
self.conv_1 = nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (filter_sizes[1], embedding_dim))
self.conv_2 = nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (filter_sizes[2], embedding_dim))
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
#text = [batch size, sent len]
embedded = self.embedding(text)
#embedded = [batch size, sent len, emb dim]
embedded = embedded.unsqueeze(1)
#embedded = [batch size, 1, sent len, emb dim]
conved_0 = F.relu(self.conv_0(embedded).squeeze(3))
conved_1 = F.relu(self.conv_1(embedded).squeeze(3))
conved_2 = F.relu(self.conv_2(embedded).squeeze(3))
#conved_n = [batch size, n_filters, sent len - filter_sizes[n] + 1]
pooled_0 = F.max_pool1d(conved_0, conved_0.shape[2]).squeeze(2)
pooled_1 = F.max_pool1d(conved_1, conved_1.shape[2]).squeeze(2)
pooled_2 = F.max_pool1d(conved_2, conved_2.shape[2]).squeeze(2)
#pooled_n = [batch size, n_filters]
cat = self.dropout(torch.cat((pooled_0, pooled_1, pooled_2), dim = 1))
#cat = [batch size, n_filters * len(filter_sizes)]
return self.fc(cat)
目前CNN模型只能使用3个不同大小的过滤器,但我们实际上可以改进我们模型的代码,使其更通用,并采取任何数量的过滤器。
我们把所有的卷积层放到一个nn.ModuleList中,nn.ModuleList是一个用来保存PyTorch 列表的函数。如果我们只是简单地使用一个标准的Python列表,列表中的模块不能被列表之外的任何模块“看到”,这会导致一些错误。
我们现在可以传递一个任意大小的过滤器大小列表,列表综合将为每个过滤器创建一个卷积层。然后,在forward方法中,我们遍历列表,应用每个卷积层来获得卷积输出的列表,在将输出连接在一起并通过dropout层和线性层之前,我们还通过列表理解中的max pooling来处理这些输出。
class CNN1(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim, dropout, pad_idx):
super(CNN1, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, pad_idx)
self.convs = nn.ModuleList([
nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(fs, embedding_dim))
for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
# text = [batch_size, sent_len]
embedded = self.embedding(text)
# embedded = [batch_size, sent_len, emb_dim]
embedded = embedded.unsqueeze(1)
# embedded = [batch_size, 1, sent_len, emb_dim]
conved = [F.relu(conv(embedded)) for conv in self.convs]
# conved_n = [batch_size, n_filters, sent_len - filter_sizes[n] + 1]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
# pooled_n = [batch_size, n_filters]
cat = self.dropout(torch.cat(pooled, dim=1))
# cat = [batch_size, n_filters * len(filter_sizes)]
return self.fc(cat)
我们也可以使用1-dimensional卷积层来实现上述模型,其中嵌入维数是过滤器的“深度”,句子中标记的数量是宽度。
我们将使用2-dimensional卷积模型在本笔记中运行测试,但将下面1-dimensional模型的实现留给感兴趣的人。
class CNN1d(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim,
dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx)
self.convs = nn.ModuleList([
nn.Conv1d(in_channels = embedding_dim,
out_channels = n_filters,
kernel_size = fs)
for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
#text = [batch size, sent len]
embedded = self.embedding(text)
#embedded = [batch size, sent len, emb dim]
embedded = embedded.permute(0, 2, 1)
#embedded = [batch size, emb dim, sent len]
conved = [F.relu(conv(embedded)) for conv in self.convs]
#conved_n = [batch size, n_filters, sent len - filter_sizes[n] + 1]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
#pooled_n = [batch size, n_filters]
cat = self.dropout(torch.cat(pooled, dim = 1))
#cat = [batch size, n_filters * len(filter_sizes)]
return self.fc(cat)
我们创建了CNN类的一个实例。
如果我们想要运行一维卷积模型,我们可以将CNN1改为CNN1d,注意这两个模型给出的结果几乎相同。
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
N_FILTERS = 100
FILTER_SIZES = [3,4,5]
OUTPUT_DIM = 1
DROPOUT = 0.5
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = CNN1(INPUT_DIM, EMBEDDING_DIM, N_FILTERS, FILTER_SIZES, OUTPUT_DIM, DROPOUT, PAD_IDX)
检查模型中的参数数量,我们可以看到它与FastText模型几乎相同。
CNN1和CNN1d模型的参数数量完全相同。
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
The model has 2,620,801 trainable parameters
接下来,我们将加载预先训练过的嵌入。
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
tensor([[-0.1117, -0.4966, 0.1631, ..., 1.2647, -0.2753, -0.1325],
[-0.8555, -0.7208, 1.3755, ..., 0.0825, -1.1314, 0.3997],
[-0.0382, -0.2449, 0.7281, ..., -0.1459, 0.8278, 0.2706],
...,
[-0.0614, -0.0516, -0.6159, ..., -0.0354, 0.0379, -0.1809],
[ 0.1885, -0.1690, 0.1530, ..., -0.2077, 0.5473, -0.4517],
[-0.1182, -0.4701, -0.0600, ..., 0.7991, -0.0194, 0.4785]])
然后将《unk》和《pad》标记的初始权值归零。
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
训练模型
训练和以前一样。我们初始化优化器,损失函数(criterion),并将模型和criterion放在GPU上(如果可用)
import torch.optim as optim
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
我们实现了计算准确率的函数…
def binary_accuracy(preds, y):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
#round predictions to the closest integer
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float() #convert into float for division
acc = correct.sum() / len(correct)
return acc
我们定义一个函数来训练我们的模型…
注意:当我们再次使用dropout时,我们必须记住使用model.train()来确保在训练时dropout是“打开的”。
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
我们定义一个函数来测试我们的模型…
注意:同样,由于我们现在使用的是dropout,我们必须记住使用model.eval()来确保在评估时dropout被“关闭”。
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
让我们定义函数来告诉我们每一个epoch需要多长时间。
import time
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
最后,我们训练我们的模型…
N_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut4-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
Epoch: 01 | Epoch Time: 0m 13s
Train Loss: 0.645 | Train Acc: 62.08%
Val. Loss: 0.488 | Val. Acc: 78.64%
Epoch: 02 | Epoch Time: 0m 11s
Train Loss: 0.418 | Train Acc: 81.14%
Val. Loss: 0.361 | Val. Acc: 84.59%
Epoch: 03 | Epoch Time: 0m 11s
Train Loss: 0.300 | Train Acc: 87.33%
Val. Loss: 0.348 | Val. Acc: 85.06%
Epoch: 04 | Epoch Time: 0m 11s
Train Loss: 0.217 | Train Acc: 91.49%
Val. Loss: 0.320 | Val. Acc: 86.71%
Epoch: 05 | Epoch Time: 0m 11s
Train Loss: 0.156 | Train Acc: 94.22%
Val. Loss: 0.334 | Val. Acc: 87.06%
我们得到的测试结果可与前2个模型相媲美!
model.load_state_dict(torch.load('tut4-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
Test Loss: 0.339 | Test Acc: 85.39%
用户输入
再一次,作为健壮性检查,我们可以检查一些输入的句子。
注意:正如在实现细节中提到的,输入句子必须至少比使用的最大的过滤器高度长。我们修改predict_sentiment函数,使其也接受最小长度参数。如果标记化的输入句子小于min_len标记,则追加填充标记(《pad》),使其成为min_len标记。
import spacy
nlp = spacy.load('en_core_web_sm')
def predict_sentiment(model, sentence, min_len = 5):
model.eval()
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]
if len(tokenized) < min_len:
tokenized += ['' ] * (min_len - len(tokenized))
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(0)
prediction = torch.sigmoid(model(tensor))
return prediction.item()
一个负面评论的例子…
res = predict_sentiment(model, "This film is terrible")
print(res)
0.11022213101387024
一个正面评论的例子…
res = predict_sentiment(model, "This film is great")
print(res)
0.9785954356193542
完整代码
import torch
from torchtext import data
from torchtext import datasets
import torch.nn as nn
import torch.nn.functional as F
import random
import numpy as np
SEED = 1234
random.seed(SEED)
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
TEXT = data.Field(tokenize='spacy', tokenizer_language='en_core_web_sm', batch_first=True)
LABEL = data.LabelField(dtype=torch.float)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
train_data, valid_data = train_data.split(random_state = random.seed(SEED))
MAX_VOCAB_SIZE = 25_000
TEXT.build_vocab(
train_data,
max_size = MAX_VOCAB_SIZE,
vectors = 'glove.6B.100d',
unk_init = torch.Tensor.normal_
)
LABEL.build_vocab(train_data)
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device
)
print(len(train_iterator))
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_size, output_dim, dropout, pad_idx):
super(CNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, pad_idx)
self.conv_0 = nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(filter_size[0], embedding_dim))
self.conv_1 = nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(filter_size[1], embedding_dim))
self.conv_2 = nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(filter_size[2], embedding_dim))
self.fc = nn.Linear(len(filter_size) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
# text = [batch_size, sent_len]
embedded = self.embedding(text)
# embedded = [batch_size, sent_len, emb_dim]
embedded = embedded.unsqueeze(1)
# embedded = [batch_size, 1, sent_len, emb_dim]
conved_0 = F.relu(self.conv_0(embedded).squeeze(3))
conved_1 = F.relu(self.conv_1(embedded).squeeze(3))
conved_2 = F.relu(self.conv_2(embedded).squeeze(3))
# conved_n = [batch_size, n_filters, sent_len - filter_size[n] + 1]
pooled_0 = F.max_pool1d(conved_0, conved_0.shape[2]).squeeze(2)
pooled_1 = F.max_pool1d(conved_1, conved_1.shape[2]).squeeze(2)
pooled_2 = F.max_pool1d(conved_2, conved_2.shape[2]).squeeze(2)
# pooled_n = [batch_size, n_filters]
cat = self.dropout(torch.cat((pooled_0, pooled_1, pooled_2), dim=1))
# cat = [batch_size, n_filters * len(filter_sizes)]
return self.fc(cat)
class CNN1(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim, dropout, pad_idx):
super(CNN1, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, pad_idx)
self.convs = nn.ModuleList([
nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(fs, embedding_dim))
for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
# text = [batch_size, sent_len]
embedded = self.embedding(text)
# embedded = [batch_size, sent_len, emb_dim]
embedded = embedded.unsqueeze(1)
# embedded = [batch_size, 1, sent_len, emb_dim]
conved = [F.relu(conv(embedded)) for conv in self.convs]
# conved_n = [batch_size, n_filters, sent_len - filter_sizes[n] + 1]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
# pooled_n = [batch_size, n_filters]
cat = self.dropout(torch.cat(pooled, dim=1))
# cat = [batch_size, n_filters * len(filter_sizes)]
return self.fc(cat)
class CNN1d(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim,
dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.convs = nn.ModuleList([
nn.Conv1d(in_channels=embedding_dim,
out_channels=n_filters,
kernel_size=fs)
for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
# text = [batch size, sent len]
embedded = self.embedding(text)
# embedded = [batch size, sent len, emb dim]
embedded = embedded.permute(0, 2, 1)
# embedded = [batch size, emb dim, sent len]
conved = [F.relu(conv(embedded)) for conv in self.convs]
# conved_n = [batch size, n_filters, sent len - filter_sizes[n] + 1]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
# pooled_n = [batch size, n_filters]
cat = self.dropout(torch.cat(pooled, dim=1))
# cat = [batch size, n_filters * len(filter_sizes)]
return self.fc(cat)
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
N_FILTERS = 100
FILTER_SIZES = [3,4,5]
OUTPUT_DIM = 1
DROPOUT = 0.5
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = CNN1(INPUT_DIM, EMBEDDING_DIM, N_FILTERS, FILTER_SIZES, OUTPUT_DIM, DROPOUT, PAD_IDX)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
import torch.optim as optim
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
def binary_accuracy(preds, y):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
#round predictions to the closest integer
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float() #convert into float for division
acc = correct.sum() / len(correct)
return acc
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
import time
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut4-model.pt')
print(f'Epoch: {epoch + 1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc * 100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc * 100:.2f}%')
model.load_state_dict(torch.load('tut4-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
import spacy
nlp = spacy.load('en_core_web_sm')
def predict_sentiment(model, sentence, min_len = 5):
model.eval()
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]
if len(tokenized) < min_len:
tokenized += ['' ] * (min_len - len(tokenized))
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(0)
prediction = torch.sigmoid(model(tensor))
return prediction.item()
res = predict_sentiment(model, "This film is terrible")
print(res)
res = predict_sentiment(model, "This film is great")
print(res)