推荐系统组队学习之协同过滤
1. 协同过滤算法
协同过滤(Collaborative Filtering)推荐算法是最经典、最常用的推荐算法。
所谓协同过滤, 基本思想是根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品(基于对用户历史行为数据的挖掘发现用户的喜好偏向, 并预测用户可能喜好的产品进行推荐),一般是仅仅基于用户的行为数据(评价、购买、下载等), 而不依赖于项的任何附加信息(物品自身特征)或者用户的任何附加信息(年龄, 性别等)。目前应用比较广泛的协同过滤算法是基于邻域的方法, 而这种方法主要有下面两种算法:
- 基于用户的协同过滤算法(UserCF): 给用户推荐和他兴趣相似的其他用户喜欢的产品
- 基于物品的协同过滤算法(ItemCF): 给用户推荐和他之前喜欢的物品相似的物品
不管是UserCF还是ItemCF算法, 非常重要的步骤之一就是计算用户和用户或者物品和物品之间的相似度, 所以下面先整理常用的相似性度量方法, 然后再对每个算法的具体细节进行展开。
2. 相似性度量方法
-
杰卡德(Jaccard)相似系数
这个是衡量两个集合的相似度一种指标。两个用户 u 和 v 交互商品交集的数量占这两个用户交互商品并集的数量的比例,称为两个集合的杰卡德相似系数,用符号 simuv 表示,其中 N(u),N(v) 分别表示用户 u 和用户 v 交互商品的集合。simuv=|N(u)∩N(v)||N(u)∪N(v)|
由于杰卡德相似系数一般无法反映具体用户的评分喜好信息, 所以常用来评估用户是否会对某商品进行打分, 而不是预估用户会对某商品打多少分。
-
余弦相似度
余弦相似度衡量了两个向量的夹角,夹角越小越相似。首先从集合的角度描述余弦相似度,相比于Jaccard公式来说就是分母有差异,不是两个用户交互商品的并集的数量,而是两个用户分别交互的商品数量的乘积,公式如下:simuv=|N(u)|∩|N(v)|√|N(u)|⋅|N(v)|
从向量的角度进行描述,令矩阵 A 为用户-商品交互矩阵(因为是TopN推荐并不需要用户对物品的评分,只需要知道用户对商品是否有交互就行),即矩阵的每一行表示一个用户对所有商品的交互情况,有交互的商品值为1没有交互的商品值为0,矩阵的列表示所有商品。若用户和商品数量分别为 m,n 的话,交互矩阵 A 就是一个 m 行 n 列的矩阵。此时用户的相似度可以表示为(其中 u⋅v 指的是向量点积):
simuv=cos(u,v)=u⋅v|u|⋅|v|
上述用户-商品交互矩阵在现实情况下是非常的稀疏了,为了避免存储这么大的稀疏矩阵,在计算用户相似度的时候一般会采用集合的方式进行计算。理论上向量之间的相似度计算公式都可以用来计算用户之间的相似度,但是会根据实际的情况选择不同的用户相似度度量方法。
这个在具体实现的时候, 可以使用
cosine_similarity进行实现:from sklearn.metrics.pairwise import cosine_similarity i = [1, 0, 0, 0] j = [1, 0.5, 0.5, 0] consine_similarity([i, j]) -
皮尔逊相关系数
皮尔逊相关系数的公式与余弦相似度的计算公式非常的类似,首先对于上述的余弦相似度的计算公式写成求和的形式,其中 rui,rvi 分别表示用户 u 和用户 v 对商品 i 是否有交互(或者具体的评分值):
simuv=∑irui∗rvi√∑ir2ui√∑ir2vi
如下是皮尔逊相关系数计算公式,其中 rui,rvi 分别表示用户 u 和用户 v 对商品 i 是否有交互(或者具体的评分值), ¯ru,¯rv 分别表示用户 u 和用户 v 交互的所有商品交互数量或者具体评分的平均值。
sim(u,v)=∑i∈I(rui−¯ru)(rvi−¯rv)√∑i∈I(rui−¯ru)2√∑i∈I(rvi−¯rv)2
所以相比余弦相似度,皮尔逊相关系数通过使用用户的平均分对各独立评分进行修正,减小了用户评分偏置的影响。具体实现, 我们也是可以调包, 这个计算方式很多, 下面是其中的一种:
from scipy.stats import pearsonr i = [1, 0, 0, 0] j = [1, 0.5, 0.5, 0] pearsonr(i, j)
下面是基于用户协同过滤和基于物品协同过滤的原理讲解。
3. 基于用户的协同过滤
基于用户的协同过滤(以下用UserCF表示),思想其实比较简单,当一个用户A需要个性化推荐的时候, 我们可以先找到和他有相似兴趣的其他用户, 然后把那些用户喜欢的, 而用户A没有听说过的物品推荐给A。
UserCF算法主要包括两个步骤:
- 找到和目标用户兴趣相似的集合
- 找到这个集合中的用户喜欢的, 且目标用户没有听说过的物品推荐给目标用户。
上面的两个步骤中, 第一个步骤里面, 我们会基于前面给出的相似性度量的方法找出与目标用户兴趣相似的用户, 而第二个步骤里面, 如何基于相似用户喜欢的物品来对目标用户进行推荐呢? 这个要依赖于目标用户对相似用户喜欢的物品的一个喜好程度, 那么如何衡量这个程度大小呢? 为了更好理解上面的两个步骤, 下面拿一个具体的例子把两个步骤具体化。
以下图为例,此例将会用于本文各种算法中

给用户推荐物品的过程可以形象化为一个猜测用户对商品进行打分的任务,上面表格里面是5个用户对于5件物品的一个打分情况,就可以理解为用户对物品的喜欢程度
应用UserCF算法的两个步骤:
- 首先根据前面的这些打分情况(或者说已有的用户向量)计算一下Alice和用户1, 2, 3, 4的相似程度, 找出与Alice最相似的n个用户
- 根据这n个用户对物品5的评分情况和与Alice的相似程度会猜测出Alice对物品5的评分, 如果评分比较高的话, 就把物品5推荐给用户Alice, 否则不推荐。
关于第一个步骤, 上面已经给出了计算两个用户相似性的方法, 这里不再过多赘述, 这里主要解决第二个问题, 如何产生最终结果的预测。
最终结果的预测
根据上面的几种方法, 我们可以计算出向量之间的相似程度, 也就是可以计算出Alice和其他用户的相近程度, 这时候我们就可以选出与Alice最相近的前n个用户, 基于他们对物品5的评价猜测出Alice的打分值, 那么是怎么计算的呢?
这里常用的方式之一是利用用户相似度和相似用户的评价加权平均获得用户的评价预测, 用下面式子表示:
Ru,p=∑s∈S(wu,s⋅Rs,p)∑s∈Swu,s
这个式子里面, 权重 wu,s 是用户 u 和用户 s 的相似度, Rs,p 是用户 s 对物品 p 的评分。
还有一种方式如下, 这种方式考虑的更加前面, 依然是用户相似度作为权值, 但后面不单纯的是其他用户对物品的评分, 而是该物品的评分与此用户的所有评分的差值进行加权平均, 这时候考虑到了有的用户内心的评分标准不一的情况, 即有的用户喜欢打高分, 有的用户喜欢打低分的情况。
Pi,j=¯Ri+∑nk=1(Si,k(Rk,j−¯Rk))∑nk=1Sj,k
所以这一种计算方式更为推荐。下面的计算将使用这个方式。
在获得用户 u 对不同物品的评价预测后, 最终的推荐列表根据预测评分进行排序得到。 至此,基于用户的协同过滤算法的推荐过程完成。
根据上面的问题, 下面手算一下:
Aim: 猜测Alice对物品5的得分:
-
计算Alice与其他用户的相似度(这里使用皮尔逊相关系数)

JavaCKT9KdW55iLxnNzt.png!thumbnail698×371
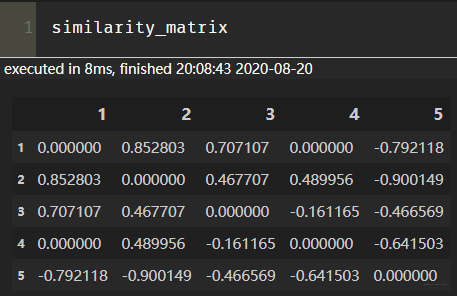
这里我们使用皮尔逊相关系数, 也就是Alice与用户1的相似度是0.85。同样的方式, 我们就可以计算与其他用户的相似度, 这里可以使用numpy的相似度函数得到用户的相似性矩阵:

图片778×441
从这里看出, Alice用户和用户2,用户3,用户4的相似度是0.7,0, -0.79。 所以如果n=2, 找到与Alice最相近的两个用户是用户1, 和Alice的相似度是0.85, 用户2, 和Alice相似度是0.7
-
根据相似度用户计算Alice对物品5的最终得分
用户1对物品5的评分是3, 用户2对物品5的打分是5, 那么根据上面的计算公式, 可以计算出Alice对物品5的最终得分是
PAlice,物品5=¯RAlice+∑2k=1(SAlice,userk(Ruserk,物品5−¯Ruserk))∑2k=1SAlice,userk=4+0.85∗(3−2.4)+0.7∗(5−3.8)0.85+0.7=4.87
- 根据用户评分对用户进行推荐
这时候, 我们就得到了Alice对物品5的得分是4.87, 根据Alice的打分对物品排个序从大到小: 物品1>物品5>物品3=物品4>物品2
这时候,如果要向Alice推荐2款产品的话, 我们就可以推荐物品1和物品5给Alice
至此, 基于用户的协同过滤算法原理介绍完毕。
4. UserCF编程实现
这里简单的通过编程实现上面的案例,为后面的大作业做一个热身, 梳理一下上面的过程其实就是三步: 计算用户相似性矩阵、得到前n个相似用户、计算最终得分。
所以我们下面的程序也是分为这三步:
- 首先, 先把数据表给建立起来
这里我采用了字典的方式, 之所以没有用pandas, 是因为上面举得这个例子其实是个个例, 在真实情况中, 我们知道, 用户对物品的打分情况并不会这么完整, 会存在大量的空值, 所以矩阵会很稀疏, 这时候用DataFrame, 会有大量的NaN。故这里用字典的形式存储。 用两个字典, 第一个字典是物品-用户的评分映射, 键是物品1-5, 用A-E来表示, 每一个值又是一个字典, 表示的是每个用户对该物品的打分。 第二个字典是用户-物品的评分映射, 键是上面的五个用户, 用1-5表示, 值是该用户对每个物品的打分。
# 定义数据集, 也就是那个表格, 注意这里我们采用字典存放数据, 因为实际情况中数据是非常稀疏的, 很少有情况是现在这样
def loadData():
items={'A': {1: 5, 2: 3, 3: 4, 4: 3, 5: 1},
'B': {1: 3, 2: 1, 3: 3, 4: 3, 5: 5},
'C': {1: 4, 2: 2, 3: 4, 4: 1, 5: 5},
'D': {1: 4, 2: 3, 3: 3, 4: 5, 5: 2},
'E': {2: 3, 3: 5, 4: 4, 5: 1}
}
users={1: {'A': 5, 'B': 3, 'C': 4, 'D': 4},
2: {'A': 3, 'B': 1, 'C': 2, 'D': 3, 'E': 3},
3: {'A': 4, 'B': 3, 'C': 4, 'D': 3, 'E': 5},
4: {'A': 3, 'B': 3, 'C': 1, 'D': 5, 'E': 4},
5: {'A': 1, 'B': 5, 'C': 5, 'D': 2, 'E': 1}
}
return items,users
items, users = loadData()
item_df = pd.DataFrame(items).T
user_df = pd.DataFrame(users).T
- 计算用户相似性矩阵
这个是一个共现矩阵, 5*5,行代表每个用户, 列代表每个用户, 值代表用户和用户的相关性,这里的思路是这样, 因为要求用户和用户两两的相关性, 所以需要用双层循环遍历用户-物品评分数据, 当不是同一个用户的时候, 我们要去遍历物品-用户评分数据, 在里面去找这两个用户同时对该物品评过分的数据放入到这两个用户向量中。 因为正常情况下会存在很多的NAN, 即可能用户并没有对某个物品进行评分过, 这样的不能当做用户向量的一部分, 没法计算相似性。 还是看代码吧, 感觉不太好描述:
"""计算用户相似性矩阵"""
similarity_matrix = pd.DataFrame(np.zeros((len(users), len(users))), index=[1, 2, 3, 4, 5], columns=[1, 2, 3, 4, 5])
# 遍历每条用户-物品评分数据
for userID in users:
for otheruserId in users:
vec_user = []
vec_otheruser = []
if userID != otheruserId:
for itemId in items: # 遍历物品-用户评分数据
itemRatings = items[itemId] # 这也是个字典 每条数据为所有用户对当前物品的评分
if userID in itemRatings and otheruserId in itemRatings: # 说明两个用户都对该物品评过分
vec_user.append(itemRatings[userID])
vec_otheruser.append(itemRatings[otheruserId])
# 这里可以获得相似性矩阵(共现矩阵)
similarity_matrix[userID][otheruserId] = np.corrcoef(np.array(vec_user), np.array(vec_otheruser))[0][1]
#similarity_matrix[userID][otheruserId] = cosine_similarity(np.array(vec_user), np.array(vec_otheruser))[0][1]
这里的similarity_matrix就是我们的用户相似性矩阵, 长下面这样:
有了相似性矩阵, 我们就可以得到与Alice最相关的前n个用户。
- 计算前n个相似的用户
"""计算前n个相似的用户"""
n = 2
similarity_users = similarity_matrix[1].sort_values(ascending=False)[:n].index.tolist() # [2, 3] 也就是用户1和用户2
- 计算最终得分
这里就是上面的那个公式了。
"""计算最终得分"""
base_score = np.mean(np.array([value for value in users[1].values()]))
weighted_scores = 0.
corr_values_sum = 0.
for user in similarity_users: # [2, 3]
corr_value = similarity_matrix[1][user] # 两个用户之间的相似性
mean_user_score = np.mean(np.array([value for value in users[user].values()])) # 每个用户的打分平均值
weighted_scores += corr_value * (users[user]['E']-mean_user_score) # 加权分数
corr_values_sum += corr_value
final_scores = base_score + weighted_scores / corr_values_sum
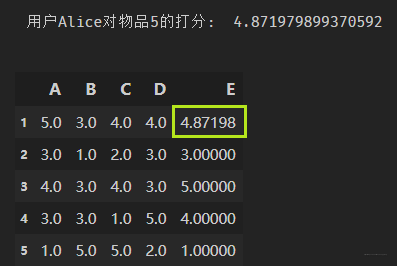
print('用户Alice对物品5的打分: ', final_scores)
user_df.loc[1]['E'] = final_scores
user_df
结果如下:
至此, 我们就用代码完成了上面的小例子, 有了这个评分, 我们其实就可以对该用户做推荐了。 这其实就是微型版的UserCF的工作过程了。
注意:基于用户协同过滤的完整代码参考源代码文件中的UserCF.py
5. UserCF优缺点
User-based算法存在两个重大问题:
-
数据稀疏性。
一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。这导致UserCF不适用于那些正反馈获取较困难的应用场景(如酒店预订, 大件商品购买等低频应用) -
算法扩展性。
基于用户的协同过滤需要维护用户相似度矩阵以便快速的找出Topn相似用户, 该矩阵的存储开销非常大,存储空间随着用户数量的增加而增加,不适合用户数据量大的情况使用。
由于UserCF技术上的两点缺陷, 导致很多电商平台并没有采用这种算法, 而是采用了ItemCF算法实现最初的推荐系统。
6. 基于物品的协同过滤
基于物品的协同过滤(ItemCF)的基本思想是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品相类似的物品推荐给用户。比如物品a和c非常相似,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A。ItemCF算法并不利用物品的内容属性计算物品之间的相似度, 主要通过分析用户的行为记录计算物品之间的相似度, 该算法认为, 物品a和物品c具有很大的相似度是因为喜欢物品a的用户大都喜欢物品c。
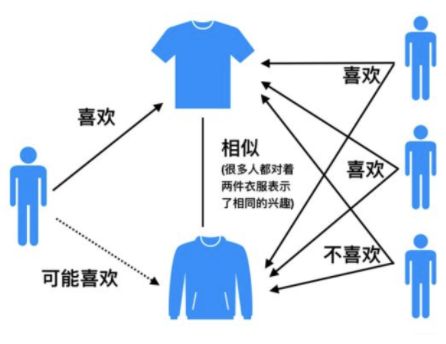
基于物品的协同过滤算法主要分为两步:
- 计算物品之间的相似度
- 根据物品的相似度和用户的历史行为给用户生成推荐列表(购买了该商品的用户也经常购买的其他商品)
基于物品的协同过滤算法和基于用户的协同过滤算法很像, 所以我们这里直接还是拿上面Alice的那个例子来看。

如果想知道Alice对物品5打多少分, 基于物品的协同过滤算法会这么做:
- 首先计算一下物品5和物品1, 2, 3, 4之间的相似性(它们也是向量的形式, 每一列的值就是它们的向量表示, 因为ItemCF认为物品a和物品c具有很大的相似度是因为喜欢物品a的用户大都喜欢物品c, 所以就可以基于每个用户对该物品的打分或者说喜欢程度来向量化物品)
- 找出与物品5最相近的n个物品
- 根据Alice对最相近的n个物品的打分去计算对物品5的打分情况
下面我们就可以具体计算一下, 首先是步骤1:

图片737×245
由于计算比较麻烦, 这里直接用python计算了:

图片781×528
根据皮尔逊相关系数, 可以找到与物品5最相似的2个物品是item1和item4(n=2), 下面基于上面的公式计算最终得分:
PAlice,物品5=¯R物品5+∑2k=1(S物品5,物品k(RAlice,物品k−¯R物品k))∑2k=1S物品k,物品5=134+0.97∗(5−3.2)+0.58∗(4−3.4)0.97+0.58=4.6
这时候依然可以向Alice推荐物品5。下面也是简单编程实现一下, 和上面的差不多:
"""计算物品的相似矩阵"""
similarity_matrix = pd.DataFrame(np.ones((len(items), len(items))), index=['A', 'B', 'C', 'D', 'E'], columns=['A', 'B', 'C', 'D', 'E'])
# 遍历每条物品-用户评分数据
for itemId in items:
for otheritemId in items:
vec_item = [] # 定义列表, 保存当前两个物品的向量值
vec_otheritem = []
#userRagingPairCount = 0 # 两件物品均评过分的用户数
if itemId != otheritemId: # 物品不同
for userId in users: # 遍历用户-物品评分数据
userRatings = users[userId] # 每条数据为该用户对所有物品的评分, 这也是个字典
if itemId in userRatings and otheritemId in userRatings: # 用户对这两个物品都评过分
#userRagingPairCount += 1
vec_item.append(userRatings[itemId])
vec_otheritem.append(userRatings[otheritemId])
# 这里可以获得相似性矩阵(共现矩阵)
similarity_matrix[itemId][otheritemId] = np.corrcoef(np.array(vec_item), np.array(vec_otheritem))[0][1]
#similarity_matrix[itemId][otheritemId] = cosine_similarity(np.array(vec_item), np.array(vec_otheritem))[0][1]
这里就是物品的相似度矩阵了, 大概长下面这个样子:
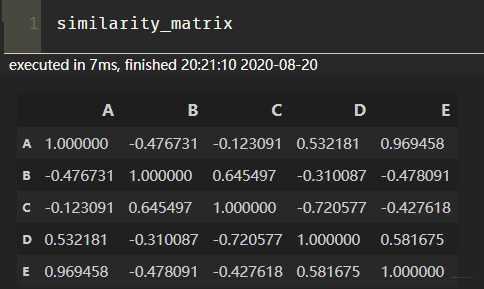
然后也是得到与物品5相似的前n个物品, 计算出最终得分来。
"""得到与物品5相似的前n个物品"""
n = 2
similarity_items = similarity_matrix['E'].sort_values(ascending=False)[:n].index.tolist() # ['A', 'D']
"""计算最终得分"""
base_score = np.mean(np.array([value for value in items['E'].values()]))
weighted_scores = 0.
corr_values_sum = 0.
for item in similarity_items: # ['A', 'D']
corr_value = similarity_matrix['E'][item] # 两个物品之间的相似性
mean_item_score = np.mean(np.array([value for value in items[item].values()])) # 每个物品的打分平均值
weighted_scores += corr_value * (users[1][item]-mean_item_score) # 加权分数
corr_values_sum += corr_value
final_scores = base_score + weighted_scores / corr_values_sum
print('用户Alice对物品5的打分: ', final_scores)
user_df.loc[1]['E'] = final_scores
user_df
结果如下:

注意:基于商品的协同过滤算法的完整代码参考源代码文件中的ItemCF.py
7. 算法评估
由于UserCF和ItemCF结果评估部分是共性知识点, 所以在这里统一标识。 这里介绍评测指标:
- 召回率
对用户u推荐N个物品记为 R(u) , 令用户u在测试集上喜欢的物品集合为 T(u) , 那么召回率定义为:
Recall=∑u|R(u)∩T(u)|∑u|T(u)|
这个意思就是说, 在用户真实购买或者看过的影片里面, 我模型真正预测出了多少, 这个考察的是模型推荐的一个全面性。
- 准确率
准确率定义为:
Precision=∑u∣R(u)∩T(u)|∑u|R(u)|
这个意思再说, 在我推荐的所有物品中, 用户真正看的有多少, 这个考察的是我模型推荐的一个准确性。
为了提高准确率, 模型需要把非常有把握的才对用户进行推荐, 所以这时候就减少了推荐的数量, 而这往往就损失了全面性, 真正预测出来的会非常少,所以实际应用中应该综合考虑两者的平衡。
- 覆盖率
覆盖率反映了推荐算法发掘长尾的能力, 覆盖率越高, 说明推荐算法越能将长尾中的物品推荐给用户。
Coverage =∣∣⋃u∈UR(u)∣∣|I|
-
该覆盖率表示最终的推荐列表中包含多大比例的物品。如果所有物品都被给推荐给至少一个用户, 那么覆盖率是100%。
-
新颖度
用推荐列表中物品的平均流行度度量推荐结果的新颖度。 如果推荐出的物品都很热门, 说明推荐的新颖度较低。 由于物品的流行度分布呈长尾分布, 所以为了流行度的平均值更加稳定, 在计算平均流行度时对每个物品的流行度取对数。
8. 协同过滤算法的权重改进

image-20200923122142218797×266 68.6 KB
- 基础算法
图1为最简单的计算物品相关度的公式, 分子为同时喜好itemi和itemj的用户数 - 对热门物品的惩罚
图1存在一个问题, 如果 item-j 是很热门的商品,导致很多喜欢 item-i 的用户都喜欢 item-j,这时 wij 就会非常大。同样,几乎所有的物品都和 item-j 的相关度非常高,这显然是不合理的。所以图2中分母通过引入 N(j) 来对 item-j 的热度进行惩罚。如果物品很热门, 那么 N(j) 就会越大, 对应的权重就会变小。 - 对热门物品的进一步惩罚
如果 item-j 极度热门,上面的算法还是不够的。举个例子,《Harry Potter》非常火,买任何一本书的人都会购买它,即使通过图2的方法对它进行了惩罚,但是《Harry Potter》仍然会获得很高的相似度。这就是推荐系统领域著名的 Harry Potter Problem。
如果需要进一步对热门物品惩罚,可以继续修改公式为如图3所示,通过调节参数 α , α 越大,惩罚力度越大,热门物品的相似度越低,整体结果的平均热门程度越低。 - 对活跃用户的惩罚
同样的,Item-based CF 也需要考虑活跃用户(即一个活跃用户(专门做刷单)可能买了非常多的物品)的影响,活跃用户对物品相似度的贡献应该小于不活跃用户。图4为集合了该权重的算法。
9. 协同过滤算法的问题分析
协同过滤算法存在的问题之一就是泛化能力弱, 即协同过滤无法将两个物品相似的信息推广到其他物品的相似性上。 导致的问题是热门物品具有很强的头部效应, 容易跟大量物品产生相似, 而尾部物品由于特征向量稀疏, 导致很少被推荐。 比如下面这个例子:

A, B, C, D是物品, 看右边的物品共现矩阵, 可以发现物品D与A、B、C的相似度比较大, 所以很有可能将D推荐给用过A、B、C的用户。 但是物品D与其他物品相似的原因是因为D是一件热门商品, 系统无法找出A、B、C之间相似性的原因是其特征太稀疏, 缺乏相似性计算的直接数据。 所以这就是协同过滤的天然缺陷:推荐系统头部效应明显, 处理稀疏向量的能力弱。
为了解决这个问题, 同时增加模型的泛化能力,2006年,矩阵分解技术(Matrix Factorization,MF)被提出, 该方法在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品, 挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。 具体细节等后面整理, 这里先铺垫一下。
10. 课后思考
1.什么时候使用UserCF,什么时候使用ItemCF?为什么?
答案:
- UserCF
由于是基于用户相似度进行推荐, 所以具备更强的社交特性, 这样的特点非常适于用户少, 物品多, 时效性较强的场合, 比如新闻推荐场景, 因为新闻本身兴趣点分散, 相比用户对不同新闻的兴趣偏好, 新闻的及时性,热点性往往更加重要, 所以正好适用于发现热点,跟踪热点的趋势。 另外还具有推荐新信息的能力, 更有可能发现惊喜, 因为看的是人与人的相似性, 推出来的结果可能更有惊喜,可以发现用户潜在但自己尚未察觉的兴趣爱好。对于用户较少, 要求时效性较强的场合, 就可以考虑UserCF。
- ItemCF
这个更适用于兴趣变化较为稳定的应用, 更接近于个性化的推荐, 适合物品少,用户多,用户兴趣固定持久, 物品更新速度不是太快的场合, 比如推荐艺术品, 音乐, 电影。
下面是UserCF和ItemCF的优缺点对比: (来自项亮推荐系统实践)
2.协同过滤在计算上有什么缺点?有什么比较好的思路可以解决(缓解)?
答案:
较差的稀疏向量处理能力
第一个问题就是泛化能力弱, 即协同过滤无法将两个物品相似的信息推广到其他物品的相似性上。 导致的问题是热门物品具有很强的头部效应, 容易跟大量物品产生相似, 而尾部物品由于特征向量稀疏, 导致很少被推荐。 比如下面这个例子:
A, B, C, D是物品, 看右边的物品共现矩阵, 可以发现物品D与A、B、C的相似度比较大, 所以很有可能将D推荐给用过A、B、C的用户。 但是物品D与其他物品相似的原因是因为D是一件热门商品, 系统无法找出A、B、C之间相似性的原因是其特征太稀疏, 缺乏相似性计算的直接数据。 所以这就是协同过滤的天然缺陷:推荐系统头部效应明显, 处理稀疏向量的能力弱。
为了解决这个问题, 同时增加模型的泛化能力,2006年,矩阵分解技术(Matrix Factorization,MF)被提出, 该方法在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品, 挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。 具体细节等后面整理, 这里先铺垫一下。
3.上面介绍的相似度计算方法有什么优劣之处?
cosine相似度还是比较常用的, 一般效果也不会太差, 但是对于评分数据不规范的时候, 也就是说, 存在有的用户喜欢打高分, 有的用户喜欢打低分情况的时候,有的用户喜欢乱打分的情况, 这时候consine相似度算出来的结果可能就不是那么准确了, 比如下面这种情况:
这时候, 如果用余弦相似度进行计算, 会发现用户d和用户f比较相似, 而实际上, 如果看这个商品喜好的一个趋势的话, 其实d和e比较相近, 只不过e比较喜欢打低分, d比较喜欢打高分。 所以对于这种用户评分偏置的情况, 余弦相似度就不是那么好了, 可以考虑使用下面的皮尔逊相关系数。
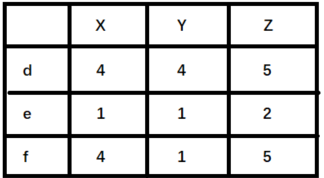
4.协同过滤还存在其他什么缺陷?有什么比较好的思路可以解决(缓解)?
答案:
协同过滤的特点就是完全没有利用到物品本身或者是用户自身的属性, 仅仅利用了用户与物品的交互信息就可以实现推荐,比较简单高效, 但这也是它的一个短板所在, 由于无法有效的引入用户年龄, 性别,商品描述,商品分类,当前时间,地点等一系列用户特征、物品特征和上下文特征, 这就造成了有效信息的遗漏,不能充分利用其它特征数据。
为了解决这个问题, 在推荐模型中引用更多的特征,推荐系统慢慢的从以协同过滤为核心到了以逻辑回归模型为核心, 提出了能够综合不同类型特征的机器学习模型。
演化图左边的时间线梳理完毕: