论文解读 VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding
一. 摘要
在本文中,作者提出了VideoCLIP,这是一种不需要下游任务的任何标签,用于预训练零样本视频和文本理解模型的对比学习方法。VideoCLIP通过对比时间重叠的正视频文本对 和最近邻检索的负样本对 ,训练视频和文本的Transformer。在本文中,作者对一系列下游任务(包括序列级文本视频检索、VideoQA、token级动作定位和动作分割)进行了实验,实验结果表明本文提出的VideoCLIP可以达到SOTA的性能,在某些情况下甚至优于监督方法。
VideoCLIP:针对零样本迁移的视频文本预训练,提出了一个对比学习方法,训练了一个统一的Transformer模型,能够迁移到多个下游任务中。
该论文对于对比学习中的正负样本对采集分别提出了改进的方法:使用时序上重叠的视频文本正样本对和检索出来更难的视频负样本对。
论文地址
代码地址
二. 介绍
近几年,“预训练+微调”的训练范式对NLP和CV领域进行了革新。尽管以这种方式训练的模型可以获得不错的性能,但它们仍然需要特定于任务的标注数据,并需要基于每个下游任务进行微调。基于这样的问题,最近也有一些工作致力于研究无需微调的零样本迁移到下游任务的预训练,比如NLP领域中GPT,CV领域中的CLIP。
在本文中,作者主要研究零样本迁移到视频文本理解任务的预训练。本文的方法使用成对的视频本文 clip,基于对比学习的目标函数,对Transformer结构进行预训练。本文的VideoCLIP基于一个公开的预训练数据集HowTo100M来使模型能够获得视频理解的能力。实验表明,所得到的预训练模型可以直接应用于或通过微调应用于一系列视频文本任务。
作者发现,简单直接的目标函数会导致较差的结果,并认为学习视频和文本之间的细粒度关联对于零样本迁移到下游任务至关重要,因为下游任务可能需要不同粒度的视频文本交互。以前的工作是在随机batch中对短时间的、对齐的视频和文本片段进行采样,但没有学习视频帧和单词token之间的细粒度关联。
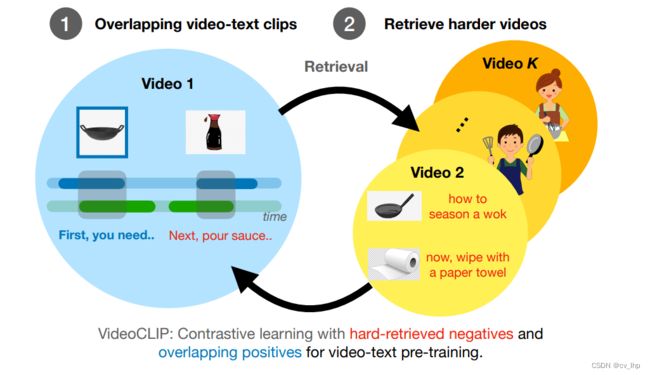
在本文中,作者提出了VideoCLIP,使用了两种关键技术(如下图所示)来计算训练目标,通过对比学习来预训练统一的视频文本表示。首先,作者的目标是改善视频和文本与不同序列长度的关联。尽管大多数视频和文本没有语义对齐,但当前的视频文本模型是通过精确的时间对齐进行训练的。因此,多个或更长的文本clip能与视频clip很好地对齐,但是许多视频clip并可能没有任何相应的文本。
为了解决这些问题,作者使用在时间上重叠的视频和文本clip对进行预训练(如下图所示),从而大大提高视频文本对齐的质量和数量 。其次,作者隐式了收集更难的负样本对,从对比损失函数中学习细粒度视频文本相似度。现有的工作通过从同一视频中采样多个视频片段来对比视频内的文本片段,但作者发现从其他视频中挖掘片段可以提供更具挑战性的负样本对。因此,作者提出了一种检索增强预训练方法来检索每个训练batch中相似的视频 。
在预训练之后,模型能够进行零样本的迁移学习,而不需要在具有标签的目标数据集上进行微调。作者在5个数据集、4个任务上进行了实验,包括文本-视频检索(用于文本-视频相似性)、视频QA(用于视频-文本相似性)、动作定位(用于视频帧-文本标签相似性)和分割(视频token-文本标签相似性),都达到不错的效果。
三. 方法
在零样本迁移的多模态视频文本预训练范式中,关键的挑战是学习视频和文本之间的细粒度关联,以满足下游任务的不同需求。在本节中,作者首先介绍视频和文本模型的主干网络和对比损失;然后,提出重叠的视频和文本clip,以提高正样本对的关联性;最后,介绍了检索增强的预训练,以改进负样本对的挖掘。
3.1 Video and Text Encoding
Video and Text Transformers

注意:使用S3D卷积对视频clip进行信息提取,生成tokens
使用均值池化而不是[CLS]标记来鼓励文本transformer和视频transformer学习标记级别的表征,可能对动作定位和动作分段有益。在实验中,作者发现共享两个transformer的参数只比不共享的效果差了一点。
值得注意的是,使用冻结的S3D权重参数能够建模长期的视觉文本一致性(大约32s),而典型的video CNNs只能捕获大约3s的时间窗口。
3.2 Contrastive Loss

3.3 Overlapped Video-Text Clips
首先,现有的很多预训练方法关注时序上精确对齐的视频文本对,它们的起止时间完全一致。大多数视频和文本并没有语义对齐,但现在的模型以精确的时序对齐来进行训练。比如一个人在说话,内容是“我去给你展示如何做炒饭”,这个片段和这个内容描述在语义上并不对齐,而随后一个米饭在锅中的片段可能与这个内容描述具有较高的相关性。因为人类很少同时说话和进行对应的动作。所以采取时间对齐可能导致多个或者较长的文本与一个视频具有更好的一致性,但是许多视频可能没有对应的字幕描述。因为在短片段中,时间上对齐的视频文本对在语义上也接近的可能性很小。该论文按照以下方法建立重叠的正样本对:
1)采样一个文本段(先采样一个视频可能没有邻近的相应文本)
2)在文本段的时间边界内取样一个时间戳作为视频片段的中心;
3)从这个中心时间戳开始,裁剪出一个具有随机持续时间的视频片段(最长32s)
该方法提高了视频和文本的相关性,并鼓励细粒度的关联。
3.4 Retrieval Augmented Training
通过使用对比预训练目标中更困难的负样例,可以学习建立更细粒度的视频文本相似性模型。因此作者在训练batch中使用难负例样本 ,它们在语义上与正例的样本对相关,这些难负例是通过检索采样得到的。
本文的方法旨在通过视频聚类来构建一个batch的训练样本,因此作者将其建模成了在视频潜在空间中进行检索的任务。整个训练过程可以看成是一个二阶段的方法,在每个迭代过程中交替执行检索和训练任务,如下图所示:

Retrieval Augmented Training 使用更困难的负样本对来建模视频和文本之间的细粒度关联。使用基于检索的采样,获取与正样本对语义上类似的负样本对,来构建训练批次。负样本并不只来自于同一视频中,还从其他不同的视频中挖掘。训练过程可以归结为一个两阶段的方法:检索和训练,如上图所示。检索的方法如下:
1)上面line2通过平均一个视频的所有视频和文本的向量表示,来计算一个视频的全局特征。通过消融试验证明了这样获得的视频特征比只取视频的开始片段来推断视频的表示效果更好。
2)上面line3为所有在训练中用到的视频构建了一个密度索引。
3)上面line4首先找到个随机的视频(对应训练集中的批次数量),其中每个视频会生成一个视频簇。我们从K个最邻近的视频中采样K个视频,而不是直接取样K个最邻近的视频。这是因为我们想要一个簇中的视频互相接近,而不是全部靠近。这样从一个视频中采样的所有视频/文本片段可以作为从另一个视频中采样的片段的负例。
3.4 对比损失
使用InfoNCE来学习视频文本的一致性,对比损失函数如下图所示,其中T是一个temperature超参数。

四. 试验
4.1. Main Results
4.1.1 Text-video Retrieval

上表展示了 Youcook2和MSR-VTT数据集上,本文的方法在监督和零样本学习设置上和其他方法的比较,可以看出,VideoClip在性能上具有一定的优越性。
4.1.2 DiDeMo
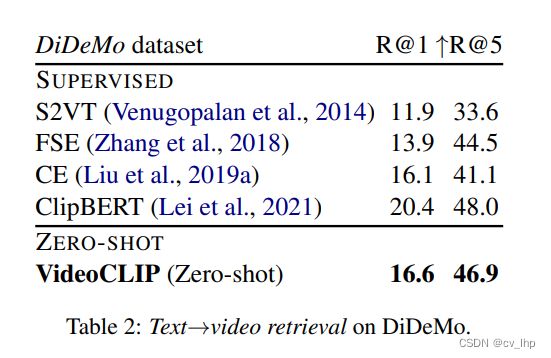
上表展示了本文方法在DiDeMo数据集上和其他监督学习方法的对比结果,可以看出 ,本文方法的零样本效果甚至优于许多监督学习的方法。
4.1.3 Video Question Answering

上表展示了Video Question Answering任务上,本文方法和其他方法的对比结果,可以看出,无论是监督学习,还是零样本学习,本文的方法都具备性能上的优越性。
4.1.4 Action segmentation on COIN
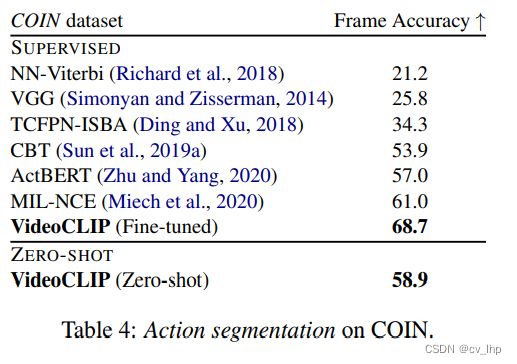
上表展示了动作分割任务上,本文方法和其他方法的性能对比。
4.1.5 Action step localization on CrossTask

上表展示了 CrossTask数据集上基于Action step localization任务,本文方法和其他方法的性能对比,可以看出,无论是监督学习,还是零样本学习,本文的方法都具备性能上的优越性。
4.2. Ablation Study

上表展示了Youcook2数据集上text→video retrieval任务,本文模型的消融实验结果。消融试验有:是否使用检索增强训练方法,是否使用视频和文本在时间重叠方法(不使用检索增强训练和视频和文本在时间重叠方法总共会使最后的精度降低百分之50),是否使用MIL-NCE方法,是否需要使视频和文本两者共享同一个transformer(视频transformer使用6层block,文本transformer使用12层block)(结论:使用共享transformer影响最后的精度不大,但效率高),是否使用K个最近邻视频检索增强训练方法,是否使用每个视频前32秒作为一个检索,是否使用Cls_token还是使用transformer最后得到的结果进行平均池化层得到结果。
五. 总结
在本文中,作者提出VideoCLIP ,这是一种预训练视频文本模型的方法,可以零样本的迁移到需要视频和语言之间细粒度关联的下游任务。为了提高训练效率和性能,作者提出了两种训练策略,即Overlapped Video-Text Clips 和Retrieval Augmented Training 。
实验表明,在下游数据集没有任何监督时,VideoCLIP在各种任务上优于以前的模型,在某些情况下,VideoCLIP甚至优于以前使用监督标签的模型;此外,下游数据的微调能够带来进一步的性能提升。
(类似clip,只使用对比学习预训练视频和文本的双塔模型,并可以zero-shot迁移到下游视频文本任务。下游包括检索、videoQA、action localization、action segment。
文章动机说nlp和图像领域中都有可以zero-shot迁移到下游的模型(GPT、clip),视频领域还没有。所以总体感觉创新性也不多,就是类似clip的训练方式,只是对于正负样本的选取,设计了两种方式:只要视频片段和文本的时间段有重叠,就算做正样本,而不需要时间严格对齐;负样本使用一种基于检索的采样技术(大概是会检索到一个视频cluster,内部彼此相似,使用它们的视频片段作为负样本,这么做的目的是找到harder examples)。所以流程会分为两步,先检索得到cluster,然后这个cluster作为训练的一个batch。
模型结构上就是transformer处理序列了。
实验上,预训练使用HowTo100M,下游比如对于videoQA MC,分别结合视频和文本答案,计算相似度,找到rank分数最高的答案。)
六. 参考链接
1.《VideoCLIP》-Facebook&CMU开源视频文本理解的对比学习预训练,性能SOTA!适用于零样本学习!
2. 论文阅读笔记 VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding
3. 论文地址
4. 代码地址