Self-Supervised Pre-Training for Transformer-BasedPerson Re-Identification 论文阅读与翻译
摘要
基于transformer的监督前训练在reid方面获得了很好的表现。但是,由于ImageNet与ReID数据集之间的域差异,通常需要更大的训练前的数据集(例如ImageNet-21K),因为transformer有强壮的数据拟合能力,从而提高了性能。为了应对这个挑战,本工作的目标就是从数据和模型结构的角度去减轻训练前数据集和reid数据集之间的差异。
我们第一次尝试了在未标记的人物图像数据(LUPerson 数据集)上使用vit(vision transformer)预训练的自我监督学习方法(self-supervised learening,SSL),并且经验性的发现在行人重识别任务上显著的超过了使用ImageNet监督训练前模型的表现。
为了进一步的减轻这种域差异和加速训练前的学习速度,用灾难性遗忘评分(Catastrophic Forgetting Score,CFS)来评估训练前数据和微调数据之间的差距。【注:Catastrophic Forgetting,灾难性遗忘:在一个顺序无标注的、可能随机切换的、同种任务可能长时间不复现的任务序列中,AI对当前任务B进行学习时,对先前任务A的知识会突然地丢失的现象。通常发生在对任务A很重要的神经网络的权重正好满足任务B的目标时。】
基于CFS,采样接近下游reid数据的相关数据并且依据处理前的数据集中过滤出不相关的数据 来选择出 子集。
对于这个模型结构来说,一个叫做IBN-based convolution stem 的reid-specific模块通过学习更多的不变特性来提供了一个减少域间隙。
在无监督域适应(unsupervised domain adaptation,UDA)和无监督学习(unsupervised learning,UDA)的设置下,进行了广泛的实验来微调训练前模型。
我们成功的将LUPerson数据集缩小到了50%并且没有性能的下降。
最后,我们获得了目前在Market1501和MSMT17上最先进的表现。例如我们的vit-s/16在Market1501上分别实现了supervised/UDA/USL的91.3%/89.9%/89.6%的mAP精确度。
1.介绍
基于transformer的方法受到越来越多的关注,并取得了良好的行人ReID性能。例如,与最先进的关于CNN的方法相比,纯的基于transformer方法的TransReID实现了显著的性能提升。然而,在ImageNet和personReID数据集之间还存在着比较大的域差异。原因如下:1.ImageNet和ReID数据集的图像内容非常不同。2.当personReID更加倾向于选择细颗粒度的身份信息时,在ImageNet上有监督的预训练使用类别级(category-level)监督,减少了更加丰富的视觉信息。
因此,Transformer需要在更大规模的数据集ImageNet-21K上预训练去避免训练前数据集的过拟合。为了减少训练前数据集和微调数据集的差距,更好的适应基于transformer的ReID方法,本文从数据和模型结构的的角度解决问题。

图1 ViT-S分别在Market-1501和MSMT17数据集上,使用supervised,UDA和USL ReID的表现。我们的预训练范式在很大程度上优于Baseline(有监督的预训练在ImageNet + vanilla ViT上)。
从数据视图来看,我们通过收集未标记的人物图像构建了一个名为LUPerson的大规模预训练数据集,该数据集表明,与ImageNet-1k预训练相比,基于cnn的SSL预训练在LUPerson数据集上提高了ReID的性能。
但是如果按照同样的模式,用Vision transformer (ViTs)替换骨干,由于训练CNNs和ViTs之间有巨大的差异,所以效果会很差。这促使我们首先为基于transformer的person ReID探索一种有效的SSL预训练范式。
在对几种基于transformer的自我监督方法(例如MocoV3, MoBY和DINO)与LUPerson数据集上的ViTs进行全面的比较后,我们发现DINO明显优于其他SSL方法和ImageNet上的监督前训练,因此它被用作我们的以下设置。接下来,我们需要注意的是,LUPersonn的预训练虽然性能更好,但由于训练数据量大(3X of ImageNet-1K),需要更多的计算资源。因此,我们建议采用有条件的预训练来加快训练过程,进一步减小域间隙。由于LUPerson采集自网络视频,其中一部分图像质量较低或者是与下游ReID数据集存在较大的域偏差,因此需要通过条件过滤,选择靠近下游ReID数据集(目标域)的相关子集,对LUPerson(源域)进行降尺度处理。而以往关于条件过滤的研究主要是针对密集分布任务设计的,即选择接近目标训练数据的类别标签或聚类中心的数据。如果直接应用于开放集的ReID任务,这些方法将很容易过拟合person id,而不是真正的目标域。受灾难性遗忘问题研究结论的启发,我们提出了一个名为灾难性遗忘评分(CFS)的指标来评估训练前数据和下游数据之间的差距。
对于预训练的图像,来自两个代理模型(一个在源数据集上预训练,另一个在目标数据集上微调)的特征之间的相似性可以表示源和目标域之间的相似性。这样就可以从训练前的数据中选择一个CFS分数较高的图像子集进行有效的条件前训练。初步的理论分析证明了CFS的有效性。
最近的一些研究从模型结构的角度指出,影响ViTs性能和稳定性的一个重要因素是在输入图像上采用大步p × p卷积(默认p = 16)实现的拼接干。为了解决这一问题,MocoV3冻结了patch投影来训练vit,而Xiao等和Wang等提出了由多个卷积、Batch Normalization (BN)和ReLU层叠加而成的卷积干,以增加优化稳定性,提高性能。受整合实例归一化(Instance Normalization, IN)和BN在ReID任务中学习域不变表示的成功启发,我们参考IBN-Net,将卷积干改进为基于IBN的卷积干(ICS)。
ICS继承了卷积干的稳定性,并引入了IBN来学习具有外观不变性的特征(如视点、姿态和光照不变性等)。ICS的计算复杂度与卷积干相似,但能显著提高ViTs在person ReID中的峰值性能。
结合以上两种基于DINO的改进,我们在Market1501和MSMT17上使用监督学习、UDA和USL设置进行实验。我们的训练前范式帮助vit在这些基准上达到最先进的性能。例如,如图1所示,我们的viti - s在supervised/UDA/USL ReID的Market-1501上实现了91.3%/89.9%/89.6%的mAP精度,这大大超过了ImageNet上的有监督训练前设置。通过提出的基于CFS的条件过滤,将原来的LUPerson缩减50%,LUPerson的训练前成本也降低了30%,而性能没有下降。
2.相关工作
2.1Self-supervised Learning
提出了一种自监督学习(Self-supervised learning, SSL)方法,在没有任何人工标注标签的情况下,从大规模无标记数据中学习判别特征。其中一个分支是由动量对比(MoCo)发展而来的,它将一个样本的一对增强处理为正对,而将所有其他样本处理为负对。由于负样本的数量对最终性能影响很大,MoCo系列需要大的batches或存储库。其中MoCoV3是transformer-specific的版本。Fu等已经验证了ResNet50可以通过改进的MoCoV2在person ReID上对人体图像进行很好的预训练。最近的许多研究表明,模型可以在不区分图像的情况下学习特征表示。在这个方向上,Ge等提出了一种新的范式,称为BYOL,在线网络预测目标网络在不同增强视图下对同一图像的表示。BYOL不需要大的batches因为不需要阴性样品。
许多变体以各种方式成功地改进了BYOL。其中一种是DINO,它使用动量老师输出的定心和锐化来避免模型崩溃。DINO在ImageNet分类和下游任务上使用ViT实现了最先进的性能。Xie等人将MoCo和BOYL结合起来,提出了一种特定于transformer的方法,称为MoBY。
鉴于目前有更多专门为transformer设计的SSL方法,我们将在接下来的实验中重点关注几个最先进的选项,例如MoCo系列、MoBY和DINO。
2.2. Transformer-based ReID
多年来,基于CNN的方法一直主导着ReID社区。然而,pure-transformer模型正逐渐成为一个受欢迎的选择。He等人率先成功地将ViTs应用到ReID任务中,他们提出的TransReID在人与车的ReID上都实现了最先进的性能。Auto-Aligned Transformer (AAformer)还使用附加可学习向量的ViT骨干来学习部件表示,并将部件对齐集成到自我注意中。其他作品尝试使用Transformer聚合来自CNN主干的特征或信息。例如,[27,35,48]将Transformer层集成到CNN主干中,聚合层次特征并对齐局部特征。对于视频ReID,[28,49]利用Transformer聚合外观特征、空间特征和时间特征来学习一个人轨迹的判别表示。
2.3. Conditional Transfer Learning
有一些研究[4,9,10,15,29,45]研究如何从pre-training数据集中选择相关子集,以提高传输到目标数据集时的性能。
[10]使用在JFT300M[20]上训练的特征提取器用贪心算法选择与目标类别最相似的源类别。对于来自目标域的每一幅图像,Ge等[15]从源域中搜索一定数量具有相似低级特征的图像。Shuvam等人[4]在目标数据上训练特征提取器,并分别选择目标域中靠近聚类中心的源图像。Y an等人[45]提出了一种神经数据服务器(NDS),用于在训练前数据集的许多子集上训练专家模型。用于训练目标任务表现良好的专家的源图像被赋予较高的重要度。值得注意的是,条件迁移学习的研究主要集中在图像分类、细粒度识别、目标检测等近集任务上。因此,这些方法可能不适合开放集的 ReID任务。
3. Self-supervised Pre-training
据我们所知,目前还没有研究基于transformer的ReID的SSL预训练的文献。因此,我们首先进行实证研究,以更好地理解这一问题。我们研究了两个骨干(基于CNN的ResNet50和基于transformer的ViT),四种SSL方法(MoCoV2, MoCoV3, MoBY和DINO),和两个预训练数据集(ImageNet和LUPerson)。这里使用的MoCoV2是针对[14]中ResNet50上的person ReID提出的改进版本,而其他三种方法MoCoV3、MoBy和DINO是针对ImageNet数据提出的transformer-specific方法。
3.1. Supervised Fine-tuning
我们使用的baseline是在ImageNet上预先训练的。
我们在两个ReID基准上微调预先训练的模型,包括Market-1501 (Market)和MSMT17,所有被比较模型的峰值微调性能如表1所示。为方便起见,预先训练好的模型被标记为模型+方法+数据。
例如,R50+Supervised+IMG表示以有监督的方式在ImageNet上预训练的ResNet50模型,这是以前大多数ReID方法的标准预训练范式。

表1 不同训练前模型的比较。我们在ImageNet-1K (IMG)和LUPerson (LUP)数据集上预训练ResNet50 (R50)和vits /16。MoBY不为ResNet50提供培训设置。为了与ImageNet进行公平的比较,我们从LUPerson中随机抽取了1.28M张图像,以建立LUP∗
现提出一些意见如下。1) MoCoV2在ResNet50的所有SSL方法中性能最好,而它比其他三种使用ViT的变压器特定方法差得多,这意味着有必要探索基于变压器的模型的特定方法。2) ViT对适当的预训练比ResNet50更敏感。例如,我们可以看到使用ResNet50的mAP在不同的训练前设置的MSMT17上的范围是51.9%到53.3%,而ViTS/16在MSMT17上的性能差异更大。3) LUP上的SSL方法始终比ImageNet上的SSL性能更好。即使我们将LUP的训练图像数量限制为与IMG相同,ViTS/16+DINO+LUP∗在两个基准上仍然超过了ViTS/16+DINO+ IMG,这表明利用人的图像是训练前ReID模型的更好选择。4) ViTS/16+DINO+LUP在MSMT17上实现了64.2%的mAP和83.4%的Rank1精度,超过了基准(ViTS/16+Supervised+IMG) 10.7%的mAP和8.2%的Rank-1精度。
3.2. Unsupervised Fine-tuning
由于无监督的ReID没有基于变压器的基线,所以接下来的实验选择了最先进的基于CNN的框架C-Contrast。我们在USL ReID和UDA ReID 上使用ResNet50和ViTS/16重现C-Contrast。根据表1的观察,我们在表2的这一部分中,ResNet50选择MoCoV2, vits /16选择DINO。
与使用ResNet50时的Sup相比,SSL训练前并没有提供很大的收益,更不用说在MSMT17上观察到的性能下降了。这与前述Transformer比CNN对预训练更敏感的结论是一致的。相比之下,在LUPerson上的SSL预训练大大提高了vits /16的性能。在MS2MA和MA2MS上的UDA性能也得到了类似的结论。
结论。DINO是基于变压器的ReID的候选方法中最适合的SSL方法。对于transformer来说,预训练比CNN模型更重要。与ImageNet预训练相比,在LUPerson上预训练的transformer可以显著提高性能,这表明为transformer弥合预训练和微调数据集之间的领域差距是更有益和值得做的。
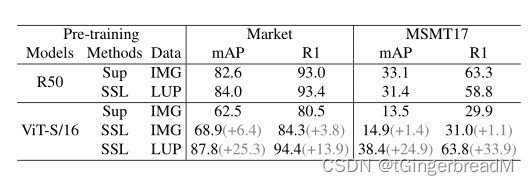
表2 在USL ReID 的模型性能。Supervised pre-training和self-supervised pre-training分别缩写为SUP和SSL。
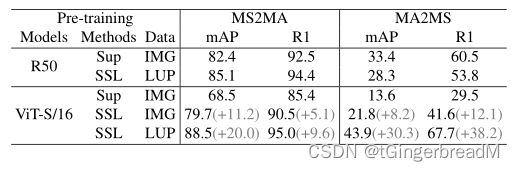
表3 在UDA ReID 的模型性能。MS2MA表示MSMT17→Market (MS2MA), MA2MS表示Market→MSMT17 (MA2MS)。
4. Conditional Pre-training
本节将介绍有效的条件预训练,在更接近目标域的子集上对模型进行预训练,以加快预训练过程,同时保持甚至提高下游微调性能。提出了灾难性遗忘评分(CFS)来评估训练前数据与目标域之间的相似性。理论分析为该方法提供了依据。
4.1. Problem Definition
给定一个目标数据集Dt = (Xt, Yt),其中Xt = {x1t, x2t, x3t,…, xMt},其ID标签为Yt。我们的目标是从大规模源/训练前数据集Ds中选择一个子集D0s,其中Xs = {x1, x2, x3,…, xn}。D0s上的图像数量为n0 < N,有效的条件预训练是在D0s上对模型进行预训练,在保持甚至提高目标数据集性能的同时减少了预训练的训练成本。之前的一些研究[4,9,29]表明,解决方法是选择接近目标域的预训练数据,我们在附录中也提供了理论分析来进一步验证这一点。由于ReID是一个开放集问题,训练集和测试集的id不同,因此关键问题是如何设计一个度量来评估训练前数据x, i∈[1,N]与目标数据集Dt(而不是Dt中的person id)之间的“相似度”。
4.2. Catastrophic Forgetting Score

我们首先在源数据集Ds上预训练一个模型θs。通过对目标数据集Dt进行微调,将θs转化为θt。
由于θs和θt只作为选择数据的代理模型,因此它们不需要达到最好的ReID性能,即它们可以是用更少的时代训练的轻量级模型。在本文中,Dt是Market-1501和MSMT17的融合,因此我们只需要选择一个共享于不同ReID数据集的子集d0。
以往的许多研究[25,34,36]都观察到神经网络在域转移过程中会发生灾难性遗忘,遗忘程度与源域和目标域之间的差距有关。为了评估预训练数据和目标域之间的域差距,提出了一个简单的度量,称为灾难性遗忘评分(CFS),它计算了预训练数据轴θs(xis)和θt(xis)之间的表示相似性: