利用 Transformer 网络建立预测模型
引言
我最近读了一篇非常有趣的论文:Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case。我认为这可能是一个有趣的项目,从零开始实施类似的东西,以了解更多关于时间序列预测。
预测任务:
在时间序列预测中,目标是根据时间序列的历史价值预测其未来价值。时间序列预测任务的一些例子如下:
-
预测流感流行个案:Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Cas****e
-
能源产量预测:Energy consumption forecasting using a stacked non-parametric Bayesian approach
-
天气预报:MetNet: A Neural Weather Model for Precipitation Forecasting
例如,我们可以将一个城市的能源消耗量数据存储几个月,然后训练一个模型,该模型将能够预测该城市未来的能源消耗。这可以用来估计能源需求,因此能源公司可以使用这个模型来估计在任何特定时间需要生产的能源的最佳价值。
时间序列预测实例
模型
我们将使用的模型是一个编解码 Transformer,其中编码器部分作为输入的历史时间序列,而解码器部分以自回归的方式预测未来的价值。
解码器使用注意机制与编码器连接。通过这种方式,解码器可以学会在进行预测之前“关注”时间序列中最有用的部分历史值。
解码器使用 masked self-attention,使网络不能在训练运行过程中通过预测未来值来预测过去值来作弊。
编码器子网络:
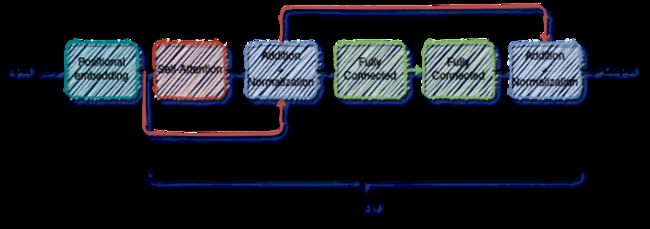
编码器
解码器子网络:
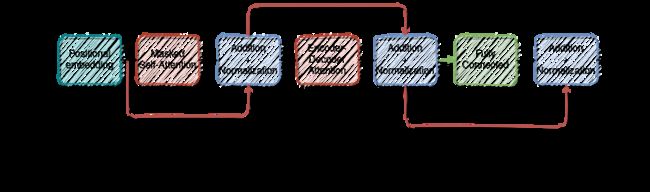
解码器
完整模型:

自回归编/解码 Transformer
这个体系结构可以使用 PyTorch 构建,方法如下:
encoder_layer = nn.TransformerEncoderLayer(
d_model=channels,
nhead=8,
dropout=self.dropout,
dim_feedforward=4 * channels,
)
decoder_layer = nn.TransformerDecoderLayer(
d_model=channels,
nhead=8,
dropout=self.dropout,
dim_feedforward=4 * channels,
)
self.encoder = torch.nn.TransformerEncoder(encoder_layer, num_layers=8)
self.decoder = torch.nn.TransformerDecoder(decoder_layer, num_layers=8)
数据
每次我实现一种新的方法时,我都喜欢首先在合成数据上进行尝试,以便更容易理解和调试。这降低了数据的复杂性,并且更加关注于实现/算法。
我编写了一个小脚本,可以生成具有不同周期、偏移量和模式的非平凡时间序列。
def generate_time_series(dataframe):
clip_val = random.uniform(0.3, 1)
period = random.choice(periods)
phase = random.randint(-1000, 1000)
dataframe["views"] = dataframe.apply(
lambda x: np.clip(
np.cos(x["index"] * 2 * np.pi / period + phase), -clip_val, clip_val
)
* x["amplitude"]
+ x["offset"],
axis=1,
) + np.random.normal(
0, dataframe["amplitude"].abs().max() / 10, size=(dataframe.shape[0],)
)
return dataframe
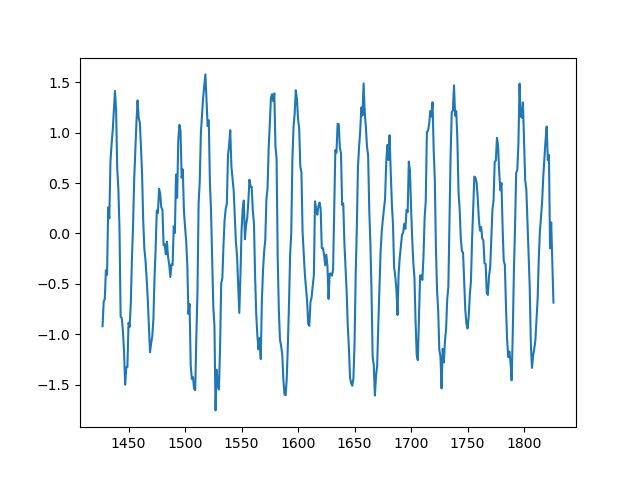
生成的时间序列示例
然后,该模型同时对所有这些时间序列进行训练:
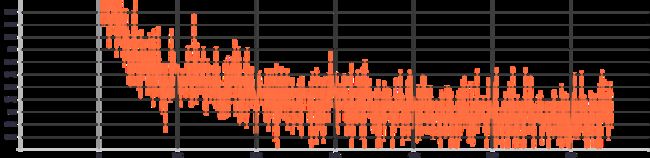
训练损失
结果
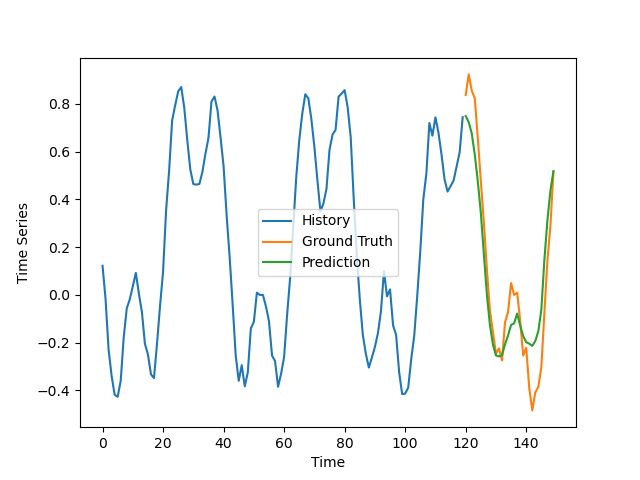
我们现在使用这个模型来预测这些时间序列的未来价值,结果有点喜忧参半:
错误的
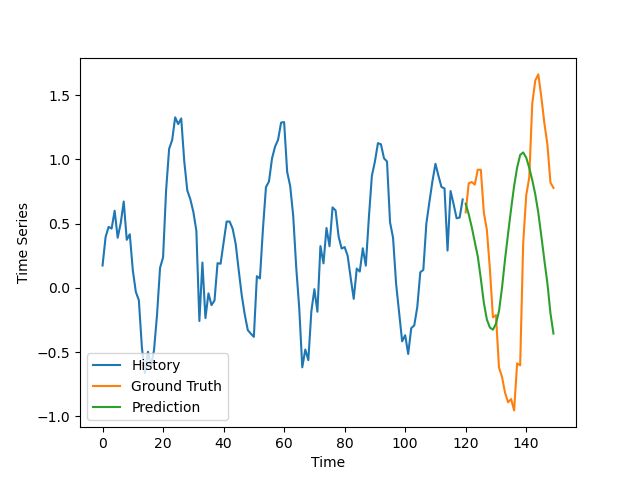
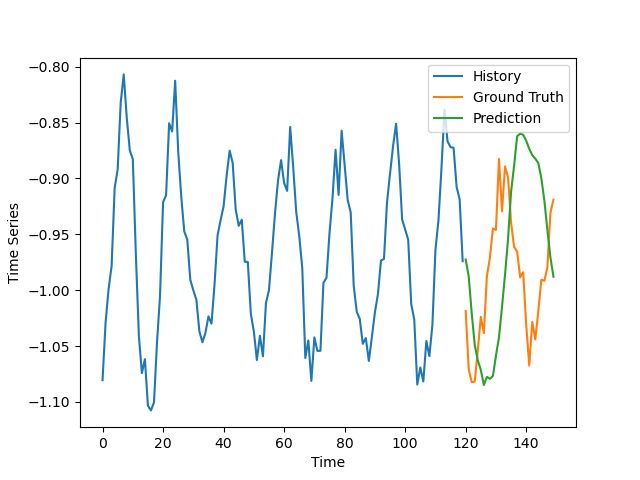
错误预测的例子
正确的
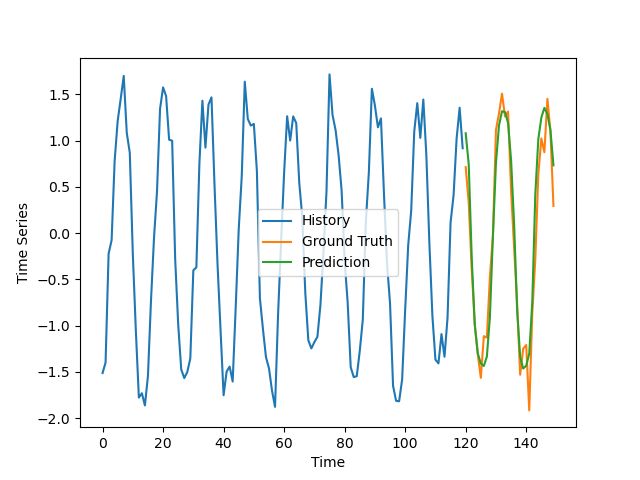
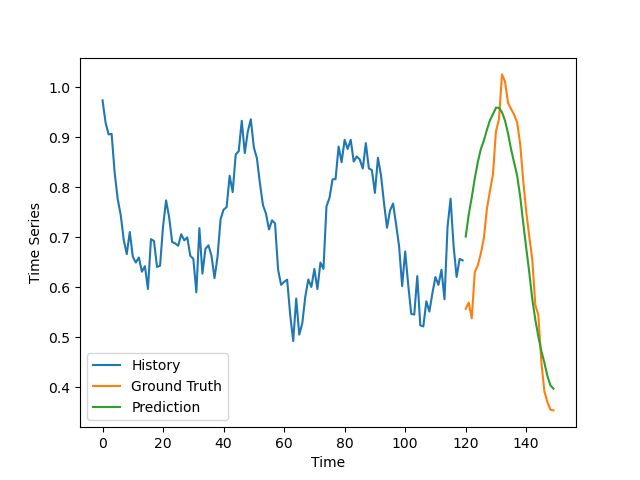
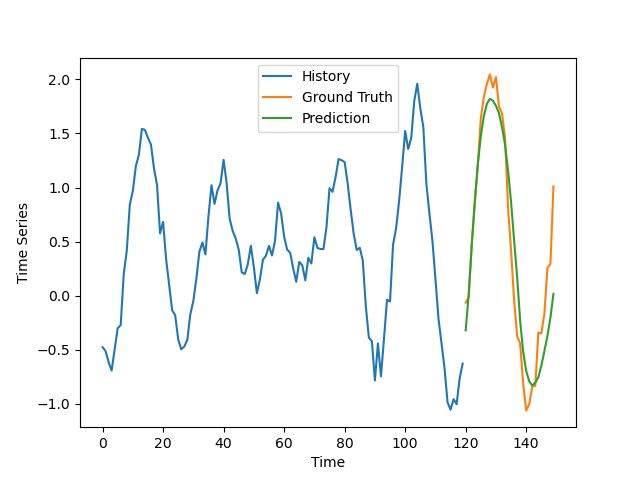
正确预测的例子
结果并不像我预期的那么好,特别是考虑到通常很容易对合成数据做出好的预测,但是他们仍然是让人有所期待的。
该模型的预测有点不同步与轻微的振幅高估了一些不良的例子。在好的例子中,除去噪音,这个预测非常符合实际情况。
我可能需要调试我的代码多一点,并在优化超参数之前,我可以期望得到更好的结果。
结论
Transformers 是目前非常流行的模型,在许多机器学习的应用,所以这是很自然的,他们将用于时间序列预测。
Transformers 可能不是你处理时间序列的第一选择,因为它们可能沉重而且需要大量数据,但是它们很适合你的机器学习工具包,因为它们的多功能性和广泛的应用范围,从它们第一次在 NLP 中应用到音频处理,计算机视觉和时间序列。