文本表达:解决BERT中的各向异性方法总结
文章目录
- 文本表达:解决BERT中的各向异性方法总结
-
- 1、BERT-flow
-
- BERT表示存在的问题
- BERT-flow
- 2、BERT-whitening
-
- 向量的内积
- 标准正交基
- 方差与协方差
- Bert-Whitning算法流程总结
- 3、SimCSE
文本表达:解决BERT中的各向异性方法总结
Sentence Embeddings:即能表征句子语义的特征向量,获取这种特征向量的方法有无监督和有监督两种,在无监督学习中,我们首先会考虑利用预训练好的大型预训练模型获取[CLS]或对句子序列纬度做MeanPooling来得到一个输入句子的特征向量。在笔者之前的文章中就利用这一方法获取论文中所有句子的特征向量后传入DGCNN来抽取摘要。
但这种方法被证明了有一个致命的缺点即: Anisotropy(各向异性) ,通俗来说就是在我们熟悉的预训练模型训练过程中会导致word embeddings的各维度的特征表示不一致。导致我们获取的句子级别的特征向量也无法进行直接比较。
目前比较流行解决这一问题的方法有
- 1、线性变换(在本文的第一二点中会详细介绍):bert-flow 或 bert-whitening,无论是在bert中增加flow层还是对得到句子向量矩阵进行白化其本质都是通过一个线性变换来缓解Anisotropy。
- 2、对比学习:先对句子进行传统的文本增广,如转译、删除、插入、调换顺序等等,再将一个句子通过两次增广得到的新句子作为正样本对,取其他句子的增广作为负样本,进行对比学习,模型的目标也很简单,即拉近正样本对的embeddings,同时增加与负样本的距离。
- 3、SimCSE: Simple Contrastive Learning of Sentence Embeddings,发现利用预训练模型中自带的Dropout mask作为“增广手段”得到的Sentence Embeddings,其质量远好于传统的增管方法,其无监督和有监督方法无监督语义上达到SOTA。
1、BERT-flow
BERT表示存在的问题
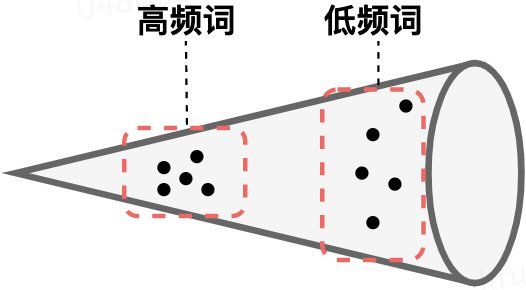
- BERT的词向量在空间中不是均匀分布,而是呈锥形。作者发现高频词都靠近原点(所有的均值),而低频词远离原点,相当于这两种词处于了空间中不同的区域,那高频词和低频词之间的相似度就不再适用了
- 低频词的分布很稀疏。低频词表示得到的训练不充分,分布稀疏,导致该区域存在语义定义不完整的地方(poorly defined),这样算出来的相似度也有问题。
BERT-flow
基于以上对相似度的深入探讨和问题研究,,作者采用一个变换,将 BERT encode 的句子表达转换到一个各向同性且分布较均匀的空间。而标准的高斯分布刚好是一个各向同性的空间,且是一个凸函数,语义分布也更平滑均匀。即BERT-flow基于流式生成模型,将BERT的表示可逆地映射到一个均匀的空间,上述的问题就迎刃而解了:

于是,变换就来了。BERT-flow 采用一种流式可逆变换,记为:
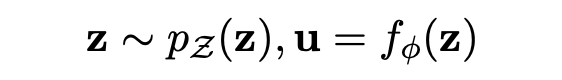
其中 u 就是 BERT 空间向量(observe space),z 即是高斯空间向量(latent space), 则是一个可逆变换,这个变换也是模型需要学出来的。
根据变元定理,观测空间的 u 的概率密度函数为:
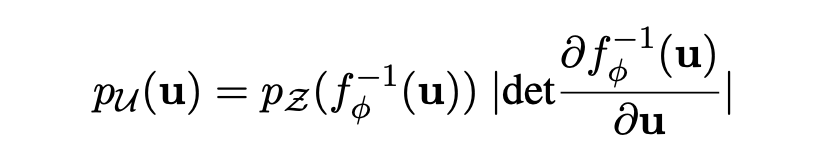
那模型优化目标的也就是最大化这个 u 的边际概率。
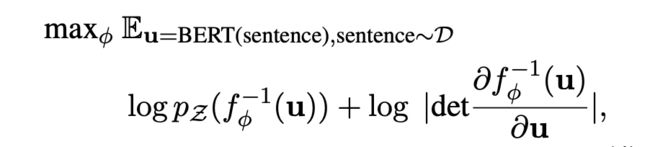
最后,通过无监督的方式 maximize 这个优化目标,得到可逆的映射变换 f,这其实就是在 Bert pre-train model 后接了一个 flow 变换的模型,让其继续 pre-train,学出 flow 变换,从而完成向量空间的 transform。
2、BERT-whitening
首先我们想一想文本相似度计算的方法,是不是先将文本表示为向量,然后计算两个句向量之间的余弦相似度,通过相似度的大小判断这两个文本是否相似。
那么这里就出现了一个问题:余弦相似度为什么就能够计算两个向量的相似性呢?想弄清楚这个问题,就需要我们对于向量的内积有一个充分的理解。
向量的内积
在线性代数中,我们知道,对于向量 A 和 B A和B A和B来说,它们的内积形式是这样的
A ⋅ B = ( a 1 , a 2 , . . . , a n ) ⋅ ( b 1 , b 2 , . . . , b n ) T = a 1 b 1 + a 2 b 2 + . . . + a n b n A·B=(a_1,a_2,...,a_n)·(b_1,b_2,...,b_n)^T=a_1b_1+a_2b_2+...+a_nb_n A⋅B=(a1,a2,...,an)⋅(b1,b2,...,bn)T=a1b1+a2b2+...+anbn
从上面的公式我们可以看出,向量内积的运算是将两个向量映射为实数。接下来,我们从几何的角度来进行分析,假设 A A A和 B B B为二维向量来进行分析,则:
A ⋅ B = ∣ A ∣ ∣ B ∣ c o s ( a ) A·B=|A||B|cos(a) A⋅B=∣A∣∣B∣cos(a)
经过变换后我们就可以得到
c o s ( a ) = A ⋅ B ∣ A ∣ ∣ B ∣ cos(a)=\frac{A·B}{|A||B|} cos(a)=∣A∣∣B∣A⋅B
其几何图为:

可以看到,向量 A A A与 B B B投影的长度乘以 B B B的模。假设 ∣ B ∣ = 1 |B|=1 ∣B∣=1,则公式变为
A ⋅ B = ∣ A ∣ c o s ( a ) A·B=|A|cos(a) A⋅B=∣A∣cos(a)
也就是说,向量 A 与 B A与B A与B的乘积可以看作 A 向 B A向B A向B所在直线投影的标量大小。我们把 A , B A,B A,B这两个向量扩展至d维,可以得到:
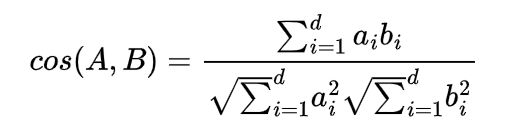
向量的模的计算公式为: ∣ A ∣ = a 1 2 + a 2 2 + . . . + a n 2 |A|=\sqrt{a_1^2+a_2^2+...+a_n^2} ∣A∣=a12+a22+...+an2
上面的 c o s ( A , B ) cos(A,B) cos(A,B)也被我们称为欧式距离,然而,别忘了一件事,上述等号旨在“标准正交基”下成立。换句话说,向量的“余弦夹角”本身是具有鲜明的集合意义的,但上公右端只是坐标的原酸,而坐标运算依赖于所选取的坐标基,基底不同,内积对应的坐标公式就不一样,从而余弦值的公式也就不一样。
标准正交基
我们知道,对于两个向量A和B来说,如果 A ⋅ B = 0 A·B=0 A⋅B=0,那么就称这两个向量正交(两向量与任何向量正交)。我们知道,在n维的欧式空间中,由n个向量组成的正交向量组称为正交基,由单位向量组成的正交基称为标准正交基。
对于一个向量 A A A来说,其中不同维度上的值表示的就是在该维上的投影,是一个标量。所以,我们可以大致得出一个结论:要准确描述限量,首先要确定一组基,然后给出在基所在的各个维度上的投影值,就可以了。
为了方便求坐标,我们希望这组基向量模长为1。因为向量的内积运算,当模长为1时,内积可以直接表示投影,然后还需要这组基是线性无关的,我们一般用正交基,非正交基也是可以的,不过正交基有较好的性质。
到这里,是不是就清楚了,BERT模型输出的[CLS]向量为什么在文本表示语义计算任务中无法取得好的效果呢?可能的一个原因是此时的句向量所属的坐标系并非标准正交基。
而且如果基的数量少于向量本身的维数,则可以达到降维的效果,但是我们还是没有回答一个最关键的问题:如何选择基才是最优的。
一种直观的看法是:希望投影后的投影值尽可能分散,因为如果重叠就会有样本消失。当然这个也可以从熵的角度进行理解,熵越大所含信息越多。
所以,这里我们希望的是投影后的数值尽可能的分散,那么,该如何让投影值分散呢?而在数学中,可以用方差来表示数值的分散程度。
方差与协方差
我们知道在一维的情况下,方差的计算如下:
V a r ( a ) = 1 m ∑ i = 1 m ( a i − μ ) 2 Var(a)=\frac{1}{m}\sum_{i=1}^m(a_i-\mu)^2 Var(a)=m1i=1∑m(ai−μ)2在多维的情况下,我们使用的协方差,计算如下:
C o v ( a , b ) = 1 m − 1 ∑ i = 1 m ( a i − μ a ) ( b i − μ b ) Cov(a,b)=\frac{1}{m-1}\sum_{i=1}^m(a_i-\mu_a)(b_i-\mu_b) Cov(a,b)=m−11i=1∑m(ai−μa)(bi−μb)这里为了方便计算,我们讲均值 μ a 和 μ b \mu_a和\mu_b μa和μb置为0,当样本数比较大的时,不必在意分母是 m 还 是 m − 1 m还是m-1 m还是m−1,这里为了方便统一取 m m m,可得:
C o v ( a , b ) = 1 m ∑ i = 1 m a i b i Cov(a,b)=\frac{1}{m}\sum_{i=1}^ma_ib_i Cov(a,b)=m1i=1∑maibi当协方差为 0 时,表示两个变量完全线性不相关。为了让协方差为 0,我们选择第二个基时只能在与第一个基正交的方向上进行选择,因此最终选择的两个方向一定是正交的。
到这里,我们就可以得到一个优化目标:将一组 N 维向量降为 K 维,其目标是选择 K 个单位正交基,使得原始数据变换到这组基上后,各变量两两间协方差为 0,而变量方差则尽可能大(在正交的约束下,取最大的 K 个方差)。
对于向量 A 和 向 量 B A和向量B A和向量B来说,我们按照行组成一个向量矩阵 X X X为:
X = { a 1 a 2 . . . a n b 1 b 2 . . . b n } X=\left\{\begin{matrix} a_1&a_2&...&a_n\\b_1&b_2&...&b_n \end{matrix} \right\} X={a1b1a2b2......anbn}然后根据协方差的计算公式,可得:
1 m X X T = { 1 m ∑ i = 1 m a i 2 1 m ∑ i = 1 m a i b i 1 m ∑ i = 1 m a i b i 1 m ∑ i = 1 m b i 2 } = { C o v ( a , a ) C o v ( a , b ) C o v ( b , a ) C o v ( b , b ) } \frac{1}{m}XX^T=\left\{\begin{matrix} \frac{1}{m}\sum_{i=1}^ma_i^2 & \frac{1}{m}\sum_{i=1}^ma_ib_i \\\frac{1}{m}\sum_{i=1}^ma_ib_i & \frac{1}{m}\sum_{i=1}^mb_i^2 \end{matrix} \right\} =\left\{\begin{matrix} Cov(a,a) & Cov(a,b) \\ Cov(b,a) & Cov(b,b) \end{matrix} \right\} m1XXT={m1∑i=1mai2m1∑i=1maibim1∑i=1maibim1∑i=1mbi2}={Cov(a,a)Cov(b,a)Cov(a,b)Cov(b,b)}我们可以看到这两个矩阵对角线上的分别是两个变量的方差,而其他元素是 a 和 b a和b a和b的协方差。两者被统一到了一个矩阵里面,所以,我们很容易将其推广到一般情况:
设我们有m个n维数据,将其排列成矩阵 X n , m X_{n,m} Xn,m,设 1 m X X T \frac{1}{m}XX^T m1XXT,则C是一个对称矩阵,其对角线分别对应各个变量的方差,而第 i 行 j 列和 j 行 i 列元素相同,表示 i 和 j 两个变量的协方差。
由此可知,我们需要将除对角线外的其它元素化为 0,并且在对角线上将元素按大小从上到下排列(变量方差尽可能大),这里就是将协方差转为一个单位矩阵,也就是矩阵的对角化。
设原始数据矩阵 X 对应的协方差矩阵为 C,而 P 是一组基按行组成的矩阵,设 Y=PX,则 Y 为 X 对 P 做基变换后的数据。设 Y 的协方差矩阵为 D,我们推导一下 D 与 C 的关系:
D = 1 m Y Y T = 1 m ( P X ) ( P X ) T = 1 m P X P T X T = P ( 1 m X X T ) P T = P C P T D=\frac{1}{m}YY^T=\frac{1}{m}(PX)(PX)^T=\frac{1}{m}PXP^TX^T=P(\frac{1}{m}XX^T)P^T=PCP^T D=m1YYT=m1(PX)(PX)T=m1PXPTXT=P(m1XXT)PT=PCPT这样我们就看清楚了,我们要找的P是能让原始协方差矩阵对角化的P。换句话说,优化目标变成了寻找一个矩阵P,满足 P C P T PCP^T PCPT是一个对角矩阵,并且对角元素按从小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
Bert-Whitning算法流程总结
先前解决BERT句向量各向异性采用的是基于flow的方法,在Bert-Whitning的论文中,作者认为机器学习中简单的白化操作也能够达到相同的效果。具体来说,就是将所有的句向量转换为 均值为0且协方差矩阵为单位矩阵的向量,之后再使用余弦相似度计算,便可以得到两句子向量的相似度。
假设有一组句子向量,也可以写为行向量 X i = 1 N {X}^N_{i=1} Xi=1N,然后对 X i = 1 N {X}^N_{i=1} Xi=1N进行如下的线性变换。
x ~ i = ( x i − μ ) W \tilde{x}_i=(x_i-\mu)W x~i=(xi−μ)W使得 x ~ i i = 1 N {\tilde{x}_i}^N_{i=1} x~ii=1N的均值为0、协方差矩阵为单位阵。为了让均值等于0,可以设置
μ = 1 N ∑ i = 1 N x i \mu=\frac{1}{N}\sum_{i=1}^Nx_i μ=N1i=1∑Nxi下面求解W,将原始数据的协方差记为:
Σ = 1 N ∑ i = 1 N ( x i − μ ) T ( x i − μ ) \Sigma=\frac{1}{N}\sum_{i=1}^N(x_i-\mu)^T(x_i-\mu) Σ=N1i=1∑N(xi−μ)T(xi−μ)根据公式,我们可以得到 Σ ~ = W T Σ W \tilde{\Sigma}=W^T\Sigma W Σ~=WTΣW,所以,我们的实际目标是: W T Σ W = I W^T\Sigma W=I WTΣW=I,然后,可得:
Σ = ( W T ) − 1 W − 1 = ( W − 1 ) T W − 1 \Sigma=(W^T)^{-1}W^{-1}=(W^{-1})^TW^{-1} Σ=(WT)−1W−1=(W−1)TW−1我们知道 Σ \Sigma Σ是一个正定对矩阵,正定对矩阵多具有如下的SVD分解:
Σ = U Λ U T \Sigma=U\Lambda U^T Σ=UΛUT其中 U U U是一个正交矩阵, Λ \Lambda Λ是一个正对角矩阵,则可以让 W − 1 = Λ U T W^{-1}=\sqrt{\Lambda}U^T W−1=ΛUT,则可以得到:
W = Λ − 1 U W=\sqrt{\Lambda^{-1}}U W=Λ−1U
3、SimCSE
SimCSE可以参看这篇博客,简单来说,SimCSE 使用(自己,自己)作为正例,(自己,别人)作为负例来训练对比学习模型。其中,(自己,自己)作为正例训练模型并不常见,不是简单地使用两个完全一样地样本来训练,这样会使得模型地泛化能力大打折扣。一般来说,我们会使用一些数据扩增的手段,让正例的两个样本有所差别。但是在NLP中如何做数据扩增本身又是一个难搞的问题,SimCSE则提出了一个极为简单的方案:直接把Dropout当作数据扩增!
