论文研究12:DUAL-PATH RNN for audio separation
论文研究12:DUAL-PATH RNN: EFFICIENT LONG SEQUENCE MODELING FOR TIME-DOMAIN SINGLE-CHANNEL SPEECH SEPARATION
abstract
基于深度学习的语音分离的最新研究证明了时域方法优于传统的基于时频的方法。与时频域方法不同,时域分离系统通常会接收包含大量时间步长的输入序列,这给建模超长序列带来了挑战。传统的递归神经网络(RNN)由于优化困难而无法有效地建模如此长的序列,而一维卷积神经网络(1-D CNN)的接收场小于序列长度时则无法执行话语级序列建模。在本文中,我们提出了双路径递归神经网络(DPRNN),这是一种在深层结构中组织RNN层以对极长序列进行建模的简单有效的方法。 DPRNN将长序列输入分成较小的块,并迭代应用块内和块间操作,其中输入长度可以与每个操作中原始序列长度的平方根成比例。实验表明,通过用DPRNN代替一维CNN并在时域音频分离网络(TasNet)中应用样本级别的建模,可以在WSJ0-2mix上获得最新的性能,而体积要比以前的最佳系统小20倍。
1. INTRODUCTION
基于深度学习的语音分离的最新进展激发了研究界对时域方法的兴趣[1-6]。 与标准时频域方法相比,时域方法旨在共同对幅度和相位信息进行建模,并允许针对时域和频域可区分标准进行直接优化[7-9]。
当前的时域分离系统主要可分为自适应前端和直接回归方法。 自适应前端方法旨在用可微变换代替短时傅立叶变换(STFT),以构建可以与分离网络一起学习的前端。 像传统的时频域方法一样,将分离过程应用于前端输出,将分离过程应用于频谱图输入[3-5]。 与传统的时频分析范式无关,这些系统能够在窗口大小和前端基本功能的数量方面灵活得多。 另一方面,直接回归方法通常通过使用某种形式的一维卷积神经网络(1-D CNN)来学习从输入混合信号到基本干净信号的回归函数,而没有明确的前端[2, 7、10]。
这两个类别之间的共同点是它们都依赖于对超长输入序列的有效建模。 直接回归方法在波形样本级别执行分离,而样本数量通常可以是数万个,有时甚至更多。 自适应前端方法的性能还取决于窗口大小的选择,其中较小的窗口以明显更长的前端表示为代价提高了分离性能[4,11]。 由于传统的顺序建模网络(包括RNN和1-D CNN)很难学习这种长期的时间依赖性,因此这带来了另外的挑战[12]。 此外,与具有动态感受野的RNN不同,具有固定感受野且长度小于序列长度的一维CNN不能充分利用序列级依赖性[13]。
在本文中,我们提出了一种简单的网络体系结构,我们将其称为双路径RNN(DPRNN),该体系结构可组织任何种类的RNN层,从而以一种非常简单的方式对长序列输入进行建模。 直觉是将输入序列分成较短的块,并交织两个RNN,分别是块内RNN和块间RNN,分别用于局部和全局建模。 在DPRNN块中,块内RNN首先独立处理本地块,然后块间RNN聚合来自所有块的信息以执行发话级处理。 对于长度为L的顺序输入,具有块大小K和块跃点大小P的DPRNN包含S个块,其中K和S分别对应于块间RNN和块内RNN的输入长度。 当K≈S时,两个RNN具有次线性输入长度(O(√L)),而不是原始输入长度(O(L)),这大大降低了L极大时出现的优化难度。
与其他用于布置本地和全局RNN层的方法(或更一般地说,是在多个时间尺度上执行序列建模的分层RNN)相比,堆叠的DPRNN迭代地执行块内和块内操作,从而可以视为本地和全局输入之间的交错处理。此外,大多数分层RNN中的第一RNN层仍接收整个输入序列,而在堆叠DPRNN中,每个块内或块间RNN在所有块上接收相同的亚线性输入大小。与基于CNN的架构(如时间卷积网络(TCN))由于固定的接收场而仅执行局部建模[4、5、20]相比,DPRNN能够通过块间RNN充分利用全局信息,并实现卓越甚至更小的模型尺寸。在第4节中,我们将显示通过在先前提出的时域分离系统中简单地用DPRNN代替TCN [4],该模型相对于尺度不变的信噪比,能够实现0.7 dB(4.6%)的相对改进。 WSJ0-2mix上的比率(SI-SNR)[8],模型尺寸小49%。通过在波形样本级别进行分离,即以2个样本的窗口大小和1个样本的跳数进行分离,使用比以前最好的系统小20倍的模型实现了最新的性能。
2. DUAL-PATH RECURRENT NEURAL NETWORK
2.1. Model design
双路径RNN(DPRNN)包含三个阶段:分段,块处理和重叠相加。 分割阶段将顺序输入分割为重叠的块,并将所有块连接为3-D张量。 然后将张量传递到堆叠的DPRNN块,以交替方式迭代应用局部(块内)和全局(块间)建模。 最后一层的输出通过重叠相加法转换回顺序输出。 图1显示了该模型的流程图。
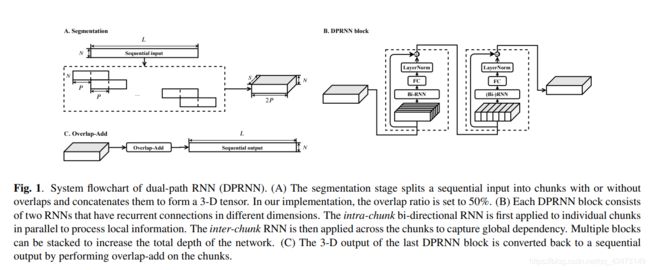
2.1.1. Segmentation
对于顺序输入W∈RN×L,其中N为特征维,L为时间步数,分段阶段将W分为长度为K且跳数为P的块。第一个和最后一个块用零填充,因此 W中的每个样本都出现并且仅出现在K / P个块中,生成S个相等大小的块Ds∈RN×K,s = 1……s 然后,将所有块连接在一起以形成3-D张量T = [D1,… ,DS]∈RN×K×S
2.1.2. Block processing
然后将分段输出T传递到B个DPRNN块的堆栈中。 每个块将输入的3-D张量转换为具有相同形状的另一个张量。 我们表示块的输入张量b = 1… ,B为Tb∈RN×K×S,其中T1 =T。每个块包含两个分别对应于块内和块间处理的子模块。 块内RNN始终是双向的,并应用于Tb的第二维,即在每个S块内:
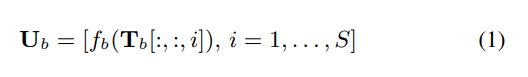
其中Ub∈RH×K×S是RNN的输出,fb(·)是RNN定义的映射函数,而Tb [:,:,i]∈RN×K是块i定义的序列。 然后应用线性完全连接(FC)层将Ub的特征维转换回Tb的维
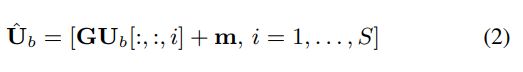
其中Uˆ∈RN×K×S是变换后的特征,G∈RN×H和m∈RN×1分别是FC层的权重和偏差,而Ub [:,:,i]∈RH×K表示 Ub中的大块i。 然后将层归一化(LN)[21]应用于Uˆ,根据经验我们发现U found对于模型具有良好的泛化能力很重要:
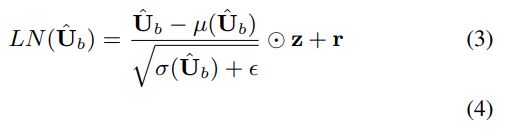
其中z,r∈RN×1是重缩放因子,对于数值稳定性来说是一个小的正数,并且表示Hadamard积。 μ(·)和σ(·)是定义为的3D张量的均值和方差
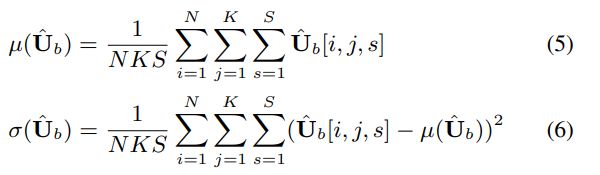
然后在LN操作的输出和输入Tb之间添加一个残余连接:

然后将Tˆ b用作块间RNN子模块的输入,其中将RNN应用于最后一个维度,即每个S块中对齐的K个时间步长:

其中Vb∈RH×K×S是RNN的输出,hb(·)是RNN定义的映射函数,Tˆ b [:, i,:]∈RN×S是第i个定义的序列 所有S块中的时间步长。 由于块内RNN是双向的,因此Tˆ b中的每个时间步都包含其所属的块的全部信息,从而允许块间RNN执行完整的序列级建模。 与块内RNN一样,线性FC层和LN操作应用于Vb的顶部。 在输出和Tˆ b之间还添加了残余连接,以形成DPRNN块b的输出。 对于b
2.1.3. Overlap-Add
将最后一个DPRNN块的输出表示为TB+1∈RN×K×S,为了将其转换回序列,对S块应用了重叠加法以形成输出Q∈RN×L。
2.2. Discussion
考虑单个块内和块内RNN的输入序列长度之和,用K+S表示,其中跳数设置为50%(即P = K / 2),如图1所示。 很容易看到S = [2L / K] +1,其中[·]是上限函数。 为了获得最小的总输入长度K + S = K + [2L / K]+ 1,应该选择K使得K≈√2L,然后S还满足S≈√(2L)≈K。这使我们得到亚线性输入长度(O(√L)),而不是原始的线性输入长度(O(L))。
对于需要在线处理的任务,可以将块之间的RNN设为单向,从第一个块到当前块进行扫描。 后面的块仍然可以利用所有先前块的信息,因此最小的系统延迟由块大小K定义。这与基于标准CNN的模型不同,该模型由于固定的接收场或常规RNN而只能执行本地处理 基于模型的模型,它们执行框架级而不是块级建模。 但是,联机和脱机设置之间的性能差异超出了本文的范围。
3. EXPERIMENTAL PROCEDURES
3.1. Model configurations
尽管DPRNN可以应用于需要长期顺序建模的任何系统,但我们研究了其在时域音频分离网络(TasNet)[1,4,22]中的应用,这是一种自适应前端方法,可以在基准测试中实现较高的语音分离性能数据集。 TasNet包含三个部分:(1)线性1-D卷积编码器,将输入混合波形封装为自适应2-D前端表示形式;(2)分隔符,用于估计C个目标源的C掩码矩阵;以及(3 )线性一维转置卷积解码器,可将屏蔽的二维表示转换回波形。当滤波器的数量设置为64时,我们使用与[4]中相同的编码器和解码器设计。对于分隔符,我们将建议的深度DPRNN与[4]中所述的最佳配置的TCN进行比较。我们使用BLSTM [23]将6个DPRNN块用作块内和块间RNN,每个方向具有128个隐藏单元。 DPRNN的块大小K是根据前端表示的长度凭经验定义的,使得训练集中的K≈√2L如2.2节所述。
3.2. Dataset
我们评估了针对两个讲话者的语音分离和识别任务的方法。仅分离实验是在广泛使用的WSJ0-2mix数据集上进行的[24]。 WSJ0-2mix包含30个小时的8k Hz训练数据,这些数据是从《华尔街日报》(WSJ0)网站集生成的。它还分别使用si dt 05和si et 05集生成了10个小时的验证数据和5个小时的测试数据。通过从相应的集合中随机选择不同的说话者并以-5至5 dB之间的随机相对信噪比(SNR)进行混合,可以人工生成每种混合物。对于语音分离和识别实验,我们分别从Librispeech数据集[25]中创建了200小时和10小时的人工混合的有噪声混响混合物,用于训练和验证。 16 kHz信号与通过图像方法生成的房间脉冲响应进行卷积[26]。房间的长度和宽度在2至10米之间随机抽样,而高度在2至5米之间随机抽样。混响时间(T60)在0.1至0.5秒之间随机采样。说话者以及单个麦克风的位置都是随机采样的。将两个混响的信号重新缩放到-5到5 dB之间的随机SNR,然后进一步移动,以使两个说话者之间的重叠率平均为50%。最终的混合物会进一步受到随机的各向同性噪声的破坏,该噪声在10到20 dB之间的随机SNR处[27]。为了进行评估,我们以Microsoft内部性别平衡的干净语音集合(由44位演讲者组成)中采样的相同方式生成混合音。分离的目标是两个说话者的混响清晰语音。
3.3. Experiment configurations
我们在4秒的长段上训练了100个时期的所有模型。 学习速率被初始化为1e -3,并且每两个时期衰减0.98。 如果在连续10个时间段的验证集中找不到最佳模型,则应用提前停止。 Adam [28]被用作优化器。 所有实验均采用最大L2范数为5的梯度裁剪。 所有模型都通过发话级置换不变训练(uPIT)进行训练[29],以最大化尺度不变SNR(SI-SNR)[8]。
从信号保真度和语音识别准确性两方面评估了系统的有效性。 信号保真度的改善程度是通过信号失真比改善(SDRi)[30]和SI-SNR改善(SISNRi)来衡量的。 语音识别精度由两个分离的说话者上的单词错误率(WER)来衡量。
4. RESULTS AND DISCUSSIONS
4.1. Results on WSJ0-2mix
我们首先在WSJ0-2mix数据集上报告结果。 表1比较了具有不同分隔符网络的基于TasNet的系统。 我们可以看到,简单地将DCN替换为DPRNN可以将分离性能提高4.6%,模型尺寸缩小49%。 这表明了所提出的局部全局建模方法优于以前的基于CNN的局部局部建模方法。 此外,可以通过进一步减小编码器和解码器中的滤波器长度(以及跳数大小)来持续改善性能。 当滤波器长度为2个样本且编码器输出超过30000帧时,可获得最佳性能。 对于标准RNN或CNN而言,这可能非常困难,甚至无法实现,而使用建议的DPRNN时,可以使用这种短滤波器并获得最佳性能。
表2将DPRNN-TasNet与WSJ0-2mix上的其他先前系统进行了比较。 我们可以看到,DPRNN-TasNet的模型比以前的最新系统FurcaNeXt [5]小20倍,从而在SI-SNRi上创下了新记录。 DPRNN-TasNet的小模型尺寸和出色的性能表明,无需使用庞大或复杂的模型即可解决WSJ0-2mix数据集上的语音分离,这表明在未来的研究中需要使用更具挑战性和现实性的数据集。

4.2. Speech separation and recognition results
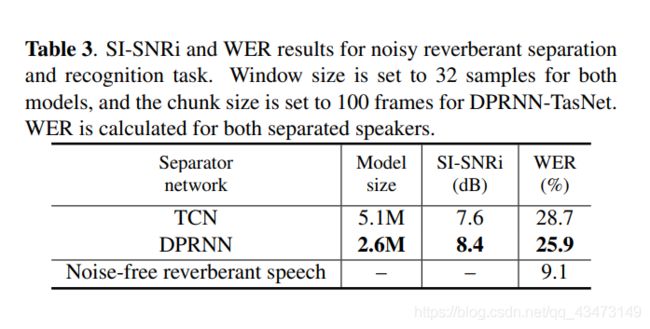
我们使用常规的混合系统进行语音识别。 我们的识别系统在从各种来源收集的大规模单扬声器嘈杂混响语音上进行了训练[35]。 表3比较了具有2毫秒窗口(32个样本和16 kHz采样率)的基于TCN和DPRNN的TasNet模型。 我们可以观察到,在SISNRi和WER中DPRNN-TasNet的性能明显优于TCN-TasNet,这表明即使在具有挑战性的嘈杂和混响条件下,DPRNN的特质也是如此。 这进一步表明DPRNN可以在一系列任务和方案中替代常规的顺序建模模块。
5. CONCLUSION
在本文中,我们提出了双路径递归神经网络(DPRNN),这是一种组织任何类型的RNN层以对超长序列进行建模的简单而有效的方法。 DPRNN将顺序输入分成重叠的块,并交替和迭代地对两个RNN执行块内(本地)和块间(全局)处理。这种设计允许每个RNN输入的长度与原始输入长度的平方根成比例,从而实现亚线性处理并减轻了优化挑战。我们还描述了使用时域音频分离网络(TasNet)进行单通道时域语音分离的应用。通过用深DPRNN代替一维CNN模块并在TasNet框架中执行样品级分离,在WSJ0-2mix上获得了最新技术,其模型比以前报道的最佳系统小20倍。还报道了嘈杂的混响语音分离和识别的实验结果,证明了DPRNN在挑战性的声学条件下的有效性。这些结果证明了所提出的方法在各种情况和任务中的优越性。