智能优化算法:天鹰优化算法-附代码
智能优化算法:天鹰优化算法
文章目录
- 智能优化算法:天鹰优化算法
-
- 1.算法原理
-
- 1.1 初始化
- 1.2 扩大搜索($X_1$)
- 1.3 缩小搜索($X_2$)
- 1.4 扩大开发($X_3$)
- 1.5扩大开发($X_4$)
- 2.实验结果
- 3.参考文献
- 4.MATLAB代码
摘要:天鹰优化算法(Aquila Optimizer,AO)是于2021年提出的一种新型智能优化算法,该算法主要模拟天鹰在捕捉猎物过程中的自然行为,来达到寻优的目的,具有寻优能力强,收敛速度快等特点。
1.算法原理
1.1 初始化
与其他优化算法一样,种群在搜索范围内随机初始化位置。
X i j = rand × ( U B j − L B j ) + L B j , i = 1 , 2 , ⋯ , N j = 1 , 2 , ⋯ , Dim (1) X_{i j}=\operatorname{rand} \times\left(U B_{j}-L B_{j}\right)+L B_{j}, i=1,2, \cdots, N j=1,2, \cdots, \text { Dim } \tag{1} Xij=rand×(UBj−LBj)+LBj,i=1,2,⋯,Nj=1,2,⋯, Dim (1)
其中, r a n d rand rand是一个随机向量, L B j LB_j LBj表示给定问题的第 j j j个下界, U B j UB_j UBj表示给定问题的第 j j j个上界。
AO算法的优化过程用四种方法表示:通过垂直俯冲的高空飞行选择搜索空间、通过短滑翔攻击的等高线飞行在发散搜索空间内探索、通过慢速下降攻击的低空飞行在收敛搜索空间内开发、通过徒步猛扑并抓住猎物。如果 t ≤ 2 3 T t\leq\frac{2}{3}T t≤32T,则AO算法可使用不同的行为从探索步骤转移到开发步骤;否则,将很好地执行开发步骤。
1.2 扩大搜索( X 1 X_1 X1)
在第一种方法 ( X 1 ) (X_1) (X1)中,天鹰识别猎物区域,并通过垂直弯腰的高飞选择最佳狩猎区域。此时,AO让来自高空的探险者四处飞翔,以确定猎物所在的搜索空间区域。该行为的数学模型如式(2)所示:
X 1 ( t + 1 ) = X b e s t ( t ) × ( 1 − t T ) + ( X M ( t ) − X b e s t ( t ) ∗ r a n d ) (2) X_{1}(t+1)=X_{b e s t}(t) \times\left(1-\frac{t}{T}\right)+\left(X_{M}(t)-X_{b e s t}(t) * r a n d\right)\tag{2} X1(t+1)=Xbest(t)×(1−Tt)+(XM(t)−Xbest(t)∗rand)(2)
X M ( t ) = 1 N ∑ i = 1 N X i ( t ) , ∀ j = 1 , 2 , ⋯ , Dim (3) X_{M}(t)=\frac{1}{N} \sum_{i=1}^{N} X_{i}(t), \forall j=1,2, \cdots, \text { Dim } \tag{3} XM(t)=N1i=1∑NXi(t),∀j=1,2,⋯, Dim (3)
其中, X 1 ( t + 1 ) X_1(t+1) X1(t+1)是由第一种搜索方法 ( X 1 ) (X_1) (X1)生成的第 t + 1 t+1 t+1次迭代的解; X b e s t ( t ) X_{best}(t) Xbest(t)是在第 t t t次迭代之前获得的最佳解,这反映了猎物的近似位置; ( 1 − t T ) (1-\frac{t}{T}) (1−Tt)用于通过迭代次数控制扩展搜索(探索); X M ( t ) X_M(t) XM(t)表示在第 t t t次迭代时当前解的平均值,该平均值使用式(3)计算; r a n d rand rand是介于0和1之间的随机值; r r r和 T T T分别表示当前迭代和最大迭代次数。 D i m Dim Dim是问题的维度大小, N N N是候选解的数量(种群规模)。
1.3 缩小搜索( X 2 X_2 X2)
在第二种方法( X 2 X_2 X2)中,当从高空发现猎物区域时,天鹰在目标猎物上方盘旋,准备着陆陆地,然后攻击,这种方法称为短滑翔攻击的等高线飞行。在这里,AO狭窄地探索目标猎物的选定区域,为攻击做准备。该行为的数学模式如式(4)所示:
X 2 ( t + 1 ) = X best ( t ) × Levy ( D ) + X R ( t ) + ( y − x ) ∗ rand (4) X_{2}(t+1)=X_{\text {best }}(t) \times \operatorname{Levy}(D)+X_{R}(t)+(y-x) * \text { rand } \tag{4} X2(t+1)=Xbest (t)×Levy(D)+XR(t)+(y−x)∗ rand (4)
其中, X 2 ( t + 1 ) X_{2}(t+1) X2(t+1)是由第二个搜索方法( X 2 X_2 X2)生成的第 t + 1 t+1 t+1次迭代的解; D D D是维度空间大小; L e v y ( D ) Levy(D) Levy(D)是Levy飞行分布函数,使用式(5)计算; X R ( t ) X_R(t) XR(t)是在第 t t t次迭代时在 [ 1 , N ] [1,N] [1,N]范围内获得的随机解。
Levy ( D ) = s × u × σ ∣ v ∣ 1 β (5) \operatorname{Levy}(D)=s \times \frac{u \times \sigma}{|v|^{\frac{1}{\beta}}} \tag{5} Levy(D)=s×∣v∣β1u×σ(5)
其中, s = 0.01 s=0.01 s=0.01, u u u和 v v v分别为服从 N ( 0 , σ 2 ) N ( 0 , σ^2 ) N(0,σ2) 和 N ( 0 , 1 ) N(0,1) N(0,1)的高斯分布随机数, σ \sigma σ计算如式(6)所示。
σ = ( Γ ( 1 + β ) × sin ( π β 2 ) Γ ( 1 + β 2 ) × β × 2 ( β − 1 2 ) ) 1 β (6) \sigma=\left(\frac{\Gamma(1+\beta) \times \sin \left(\frac{\pi \beta}{2}\right)}{\Gamma\left(\frac{1+\beta}{2}\right) \times \beta \times 2\left(\frac{\beta-1}{2}\right)}\right)^{\frac{1}{\beta}} \tag{6} σ=⎝⎛Γ(21+β)×β×2(2β−1)Γ(1+β)×sin(2πβ)⎠⎞β1(6)
其中 β = 1.5 \beta=1.5 β=1.5。在式(4)中, y y y和 x x x用于表示搜索中的螺旋形状,计算如下:
y = r × cos ( θ ) (7) y=r \times \cos (\theta) \tag{7} y=r×cos(θ)(7)
x = r × sin ( θ ) (8) x=r \times \sin (\theta) \tag{8} x=r×sin(θ)(8)
其中:
r = r 1 + U × D 1 (9) r=r_{1}+U \times D_{1} \tag{9} r=r1+U×D1(9)
θ = − ω × D 1 + θ 1 (10) \theta=-\omega \times D_{1}+\theta_{1} \tag{10} θ=−ω×D1+θ1(10)
θ 1 = 3 × π 2 (11) \theta_{1}=\frac{3 \times \pi}{2} \tag{11} θ1=23×π(11)
r 1 r_1 r1取1到20之间的值,用于固定搜索周期数; U U U是固定为0.00565的值; D 1 D_1 D1是从1到搜索空间维数( D i m Dim Dim)的整数; ω \omega ω是固定为0.005的值。
1.4 扩大开发( X 3 X_3 X3)
在第三种方法( X 3 X_3 X3)中,当天鹰准确地指定了猎物区域,并且准备好着陆和攻击时,天鹰垂直下降并进行初步攻击,以发现猎物反应。这种方法称为低空慢降攻击。在这里,AO利用目标的选定区域接近猎物并进行攻击。这种行为在数学上如式(12)所示:
X 3 ( t + 1 ) = ( X best ( t ) − X M ( t ) ) × α − rand + ( ( U B − L B ) × rand + L B ) × δ (12) X_{3}(t+1)=\left(X_{\text {best }}(t)-X_{M}(t)\right) \times \alpha-\text { rand }+((U B-L B) \times \text { rand }+L B) \times \delta \tag{12} X3(t+1)=(Xbest (t)−XM(t))×α− rand +((UB−LB)× rand +LB)×δ(12)
其中, X 3 ( t + 1 ) X_3(t+1) X3(t+1)是由第三种搜索方法( X 3 X_3 X3)生成的第 t + 1 t+1 t+1次迭代的解; X b e s t ( t ) X_{best}(t) Xbest(t)表示第 t t t次迭代前猎物的近似位置(获得的最佳解); X M ( t ) X_M(t) XM(t)表示第 t t t次迭代时当前解的平均值,该平均值使用式(3)计算; r a n d rand rand是一个介于0和1之间的随机值; α \alpha α和 δ \delta δ是本文中固定为较小值(0.1)的开发调整参数; L B LB LB表示给定问题的下界, U B UB UB表示给定问题的上界。
1.5扩大开发( X 4 X_4 X4)
在第三种方法( X 4 X_4 X4)中,当天鹰接近猎物时,它根据其随机运动在陆地上攻击猎物。这种方法称为“行走并抓住猎物”,AO在最后一个位置攻击猎物。该行为的数学模型如式(13)所示:
X 4 ( t + 1 ) = Q F ( t ) × X b e s t ( t ) − ( G 1 × X ( t ) × rand ) − G 2 × Levy ( D ) + rand × G 1 (13) X_{4}(t+1)=Q F(t) \times X_{b e s t}(t)-\left(G_{1} \times X(t) \times \operatorname{rand}\right)-G_{2} \times \operatorname{Levy}(D)+\operatorname{rand} \times G_{1} \tag{13} X4(t+1)=QF(t)×Xbest(t)−(G1×X(t)×rand)−G2×Levy(D)+rand×G1(13)
其中, X 4 ( t + 1 ) X_4(t+1) X4(t+1)是由第四种搜索方法( X 4 X_4 X4)生成的第 t + 1 t+1 t+1次迭代的解; Q F ( t ) QF(t) QF(t)表示在第 t t t次迭代时用于平衡搜索策略的质量函数,其使用式(14)计算; G 1 G_1 G1表示在搜索猎物期间用于跟踪猎物的AO的各种运动,其使用式(15)计算; G 2 G_2 G2呈现从2到0的递减值,表示AO的飞行速率,AO用于在从第一个位置到最后一个位置的过程中跟踪猎物,使用式(16)产生; X ( t ) X(t) X(t)是第 t t t次迭代的当前解。
Q F ( t ) = t 2 × rand − 1 ( 1 − T ) 2 (14) Q F(t)=t^{\frac{2 \times \text { rand }-1}{(1-T)^{2}}} \tag{14} QF(t)=t(1−T)22× rand −1(14)
G 1 = 2 × rand − 1 (15) G_{1}=2 \times \text { rand }-1 \tag{15} G1=2× rand −1(15)
G 2 = 2 × ( 1 − t T ) (16) G_{2}=2 \times\left(1-\frac{t}{T}\right) \tag{16} G2=2×(1−Tt)(16)
其中, r a n d rand rand是介于0和1之间的随机值; t t t和 T T T分别表示当前迭代和最大迭代次数。
算法伪代码如下:
1: Initialization phase:
2: Initialize the population X of the AO.
3: Initialize the parameters of the AO (i.e., α ,δ, etc).
4: WHILE (The end condition is not met) do
5: Calculate the fitness function values.
6: X best (t)= Determine the best obtained solution according to the fitness values.
7: for (i = 1,2…,N) do
8: Update the mean value of the current solution X M (t).
9: Update the x,y,G 1 ,G 2 , Levy(D), etc.
10: if t⩽( 2
3 )∗T then
11: if rand⩽0.5 then
12: ▹ Step 1: Expanded exploration (X 1 )
13: Update the current solution using Eq. (2).
14: if Fitness(X 1 (t + 1)) < Fitness(X(t)) then
15: X(t) =(X 1 (t + 1))
16: if Fitness(X 1 (t + 1)) < Fitness(X best (t)) then
17: X best (t) =X 1 (t + 1)
18: end if
19: end if
20: else
21: {▹ Step 2: Narrowed exploration (X 2 )}
22: Update the current solution using Eq. (4).
23: if Fitness(X 2 (t + 1)) < Fitness(X(t)) then
24: X(t) =(X 2 (t + 1))
25: if Fitness(X 2 (t + 1)) < Fitness(X best (t)) then
26: X best (t) =X 2 (t + 1)
27: end if
28: end if
29: end if
30: else
31: if rand⩽0.5 then
32: {▹ Step 3: Expanded exploitation (X 3 )}
33: Update the current solution using Eq. (12).
34: if Fitness(X 3 (t + 1)) < Fitness(X(t)) then
35: X(t) =(X 3 (t + 1))
36: if Fitness(X 3 (t + 1)) < Fitness(X best (t)) then
37: X best (t) =X 3 (t + 1)
38: end if
39: end if
40: else
41: ▹ Step 4: Narrowed exploitation (X 4 )
42: Update the current solution using Eq. (13).
43: if Fitness(X 4 (t + 1)) < Fitness(X(t)) then
44: X(t) =(X 4 (t + 1))
45: ifFitness(X 4 (t + 1)) < Fitness(X best (t)) then
46: X best (t) =X 4 (t + 1)
47: end if
48: end if
49: end if
50: end if
51: end for
52: end while
53: return The best solution (X best ).
2.实验结果
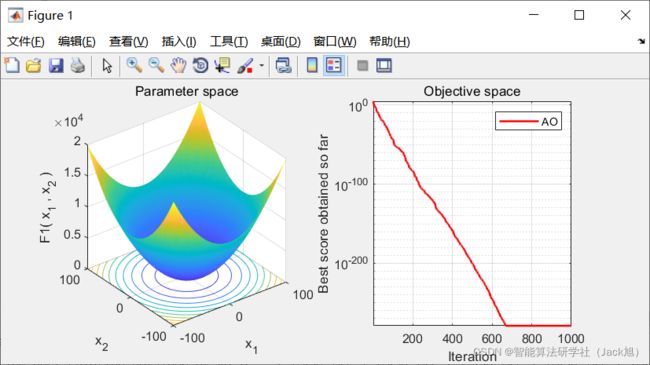
3.参考文献
[1] Abualigah L , Yousri D , Elaziz M A , et al. Matlab Code of Aquila Optimizer: A novel meta-heuristic optimization algorithm[J]. Computers & Industrial Engineering, 2021.