线性回归(Linear Regression)
Linear Regression
- 1 概述
- 2 单变量线性回归
- 3 多元线性回归
-
- 3.1 最小二乘法
- 3.2 梯度下降
- 4 多项式回归
- 5 总结
1 概述
线性回归(Linear Regression)是一种通过属性的线性组合来进行预测的线性模型,其目的是找到一条直线或者一个平面或者更高维的超平面,使得预测值与真实值之间的误差最小化。

2 单变量线性回归
在初中时,我们知道线性函数 y = k x + b y=kx+b y=kx+b
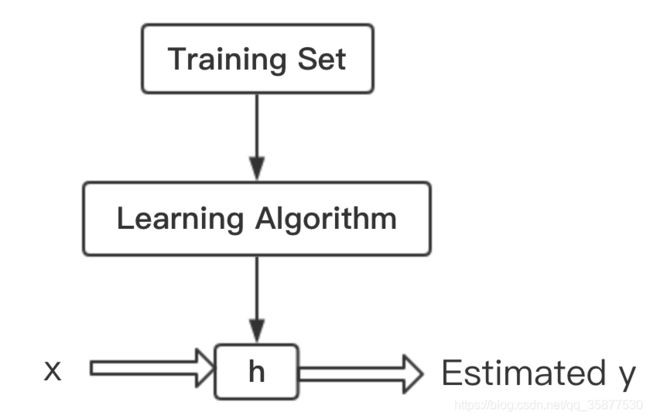
单变量线性回归模型 h θ ( x ) = θ 0 + θ 1 x h_\theta(x)=\theta_0+\theta_1x hθ(x)=θ0+θ1x, θ 0 , θ 1 \theta_0, \theta_1 θ0,θ1被称为模型参数。如果我们知道 θ 0 , θ 1 \theta_0, \theta_1 θ0,θ1,就能对任意的 x x x进行预测了。任何机器学习过程如下图所示:
代价函数:
J ( θ 0 , θ 1 ) = 1 2 m Σ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta_0, \theta_1)=\frac{1}{2m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2 J(θ0,θ1)=2m1Σi=1m(hθ(x(i))−y(i))2
目标就是最小化代价函数: m i n J ( θ 0 , θ 1 ) minJ(\theta_0, \theta_1) minJ(θ0,θ1)
下面是代价函数 J ( θ 0 , θ 1 ) J(\theta_0, \theta_1) J(θ0,θ1)与 θ 0 , θ 1 \theta_0, \theta_1 θ0,θ1之间的关系

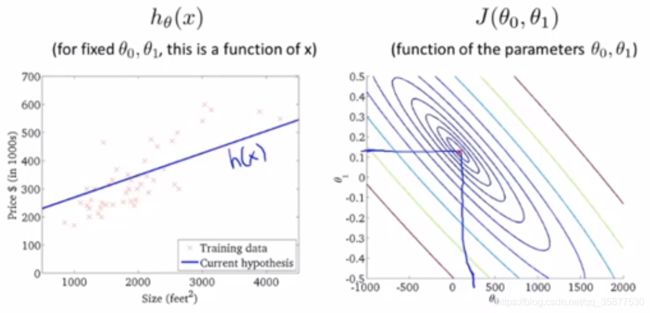
从图中可以看出,当 θ 0 , θ 1 \theta_0, \theta_1 θ0,θ1处于代价函数的最小值时,得到最优的拟合结果。
求代价函数 J ( θ 0 , θ 1 ) J(\theta_0, \theta_1) J(θ0,θ1)的最小值,可以有两种方法:
1 最小二乘法:
针对单变量线性回归,具有线性关系,为了获得代价函数 J ( θ 0 , θ 1 ) J(\theta_0, \theta_1) J(θ0,θ1)的最小值,可以利用 J ( θ 0 , θ 1 ) J(\theta_0, \theta_1) J(θ0,θ1)分别对 θ 0 , θ 1 \theta_0, \theta_1 θ0,θ1求导,令其导数为0,然后再得到 θ 0 , θ 1 \theta_0, \theta_1 θ0,θ1的值,根据导数的性质,此时得到的 θ 0 , θ 1 \theta_0, \theta_1 θ0,θ1就是模型的最优值。
{ ∂ ∂ θ 0 J ( θ 0 , θ 1 ) = 1 m Σ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) = 1 m Σ i = 1 m ( θ 0 + θ 1 x ( i ) − y ( i ) ) = 0 ∂ ∂ θ 1 J ( θ 0 , θ 1 ) = 1 m Σ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x ( i ) = 1 m Σ i = 1 m ( θ 0 + θ 1 x ( i ) − y ( i ) ) x ( i ) = 0 \{\begin{matrix} \frac{\partial}{\partial\theta_0}J(\theta_0,\theta_1)=\frac{1}{m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})=\frac{1}{m}\Sigma^m_{i=1}(\theta_0+\theta_1x^{(i)}-y^{(i)})=0 \\ \frac{\partial}{\partial\theta_1}J(\theta_0,\theta_1)=\frac{1}{m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})x^{(i)}=\frac{1}{m}\Sigma^m_{i=1}(\theta_0+\theta_1x^{(i)}-y^{(i)})x^{(i)}=0 \end{matrix} {∂θ0∂J(θ0,θ1)=m1Σi=1m(hθ(x(i))−y(i))=m1Σi=1m(θ0+θ1x(i)−y(i))=0∂θ1∂J(θ0,θ1)=m1Σi=1m(hθ(x(i))−y(i))x(i)=m1Σi=1m(θ0+θ1x(i)−y(i))x(i)=0
θ 0 = Σ i = 1 m ( x ( i ) ) 2 Σ i = 1 m y ( i ) − Σ i = 1 m x ( i ) Σ i = 1 m x ( i ) y ( i ) m Σ i = 1 m ( x ( i ) ) 2 − ( Σ i = 1 m x ( i ) ) 2 \theta_0= \frac{\Sigma^m_{i=1}(x^{(i)})^2\Sigma^m_{i=1}y^{(i)}-\Sigma^m_{i=1}x^{(i)}\Sigma^m_{i=1}x^{(i)}y^{(i)}}{m\Sigma^m_{i=1}(x^{(i)})^2-(\Sigma^m_{i=1}x^{(i)})^2} θ0=mΣi=1m(x(i))2−(Σi=1mx(i))2Σi=1m(x(i))2Σi=1my(i)−Σi=1mx(i)Σi=1mx(i)y(i)
θ 1 = m Σ i = 1 m x ( i ) y ( i ) − Σ i = 1 m x ( i ) Σ i = 1 m y ( i ) m Σ i = 1 m ( x ( i ) ) 2 − ( Σ i = 1 m x ( i ) ) 2 \theta_1= \frac{m\Sigma^m_{i=1}x^{(i)}y^{(i)}-\Sigma^m_{i=1}x^{(i)}\Sigma^m_{i=1}y^{(i)}}{m\Sigma^m_{i=1}(x^{(i)})^2-(\Sigma^m_{i=1}x^{(i)})^2} θ1=mΣi=1m(x(i))2−(Σi=1mx(i))2mΣi=1mx(i)y(i)−Σi=1mx(i)Σi=1my(i)
这就是最小二乘法的解法,就是求得损失函数的极值点。
2 梯度下降法(Gradient Descent Algorithm):
如下图所示,就好比一个人站在山上,想走到山谷的位置,每一步沿着山体梯度的方向往下走,无疑是最快的方向。

θ j : = θ j − α ∂ ∂ θ j J ( θ 0 , θ 1 ) \theta_j:=\theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\theta_0,\theta_1) θj:=θj−α∂θj∂J(θ0,θ1)(for j = 0 , 1 j=0,1 j=0,1)
∂ ∂ θ 0 J ( θ 0 , θ 1 ) = 1 m Σ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) \frac{\partial}{\partial\theta_0}J(\theta_0,\theta_1)=\frac{1}{m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)}) ∂θ0∂J(θ0,θ1)=m1Σi=1m(hθ(x(i))−y(i))
∂ ∂ θ 1 J ( θ 0 , θ 1 ) = 1 m Σ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x ( i ) \frac{\partial}{\partial\theta_1}J(\theta_0,\theta_1)=\frac{1}{m}\Sigma^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})x^{(i)} ∂θ1∂J(θ0,θ1)=m1Σi=1m(hθ(x(i))−y(i))x(i)
α \alpha α叫做学习率,当 α \alpha α较小时梯度下降的速度会很慢,训练时间更长,当 α \alpha α较大时具有较快的学习速度,但是过大时会跳过代价函数的最低点,导致永远无法获得代价函数的最小值。因此,只要我们给定 θ 0 , θ 1 \theta_0, \theta_1 θ0,θ1的初始值,让后进行逐步迭代,计算出每一步的偏导数项,最终就会走到 J ( θ 0 , θ 1 ) J(\theta_0, \theta_1) J(θ0,θ1)的低点,此时的 θ 0 , θ 1 \theta_0, \theta_1 θ0,θ1就是模型的最优参数。
3 多元线性回归
例如,房价可能与很多因素有关,如房屋面积、楼层、地段、房屋类型、房间数量等等。这样预测的模型可表示为 h θ ( x 1 , x 2 , . . . , x n ) = θ 0 + θ 1 x 1 + . . . + θ n x n h_\theta(x_1,x_2,...,x_n)=\theta_0+\theta_1x_1+...+\theta_nx_n hθ(x1,x2,...,xn)=θ0+θ1x1+...+θnxn, θ 0 , θ 1 , . . . , θ n \theta_0, \theta_1,...,\theta_n θ0,θ1,...,θn被称为模型参数。总的来说多元线性回归跟一元线性回归基本相同。
h θ ( x 1 , x 2 , . . . , x n ) h_\theta(x_1,x_2,...,x_n) hθ(x1,x2,...,xn)矩阵形式: h θ ( X ) = θ 0 + θ 1 x 1 + . . . + θ n x n = ( x 0 , x 1 , x 2 , . . . , x n ) ( θ 0 , θ 1 , θ 2 , . . . , θ n ) T = X Θ T h_\theta(X)=\theta_0+\theta_1x_1+...+\theta_nx_n=(x_0,x_1,x_2,...,x_n)(\theta_0,\theta_1,\theta_2,...,\theta_n)^T=X\Theta^T hθ(X)=θ0+θ1x1+...+θnxn=(x0,x1,x2,...,xn)(θ0,θ1,θ2,...,θn)T=XΘT J ( θ ) = 1 2 ( h θ ( X ) − Y ) T ( h θ ( X ) − Y ) = 1 2 ( X θ − Y ) T ( X θ − Y ) J(\theta)=\frac{1}{2}(h_\theta(X)-Y)^T(h_\theta(X)-Y)=\frac{1}{2}(X\theta-Y)^T(X\theta-Y) J(θ)=21(hθ(X)−Y)T(hθ(X)−Y)=21(Xθ−Y)T(Xθ−Y)
其中 x 0 = 1 , x_0=1, x0=1, Y Y Y是样本的输出向量,维度为 m × 1 m\times1 m×1, 1 / 2 1/2 1/2在这主要是为了求导后系数为1,方便计算。
3.1 最小二乘法
根据最小二乘法的原理,我们要对这个损失函数对 θ θ θ向量求导取0。结果如下式:
∂ ∂ θ J ( θ ) = X T ( X θ − Y ) = 0 \frac{\partial}{\partial\theta}J(\theta)=X^T(X\theta-Y)=0 ∂θ∂J(θ)=XT(Xθ−Y)=0
这里面用到了矩阵求导链式法则,和两个个矩阵求导的公式。
公式1: ∂ ∂ X ( X T X ) = 2 X \frac{\partial}{\partial X}(X^TX)=2X ∂X∂(XTX)=2X, X X X为向量
公式2: ∇ X f ( A X + B ) = A T ∇ Y f , Y = A X + B , f ( Y ) ∇_Xf(AX+B)=A^T∇_Yf,Y=AX+B,f(Y) ∇Xf(AX+B)=AT∇Yf,Y=AX+B,f(Y)为标量
对上述求导等式整理后可得:
X T ( X θ − Y ) = 0 X^T(X\theta-Y)=0 XT(Xθ−Y)=0 ⇒ X T X θ = X T Y ⇒X^TX\theta=X^TY ⇒XTXθ=XTY ⇒ ( X T X ) − 1 ( X T X θ ) = ( X T X ) − 1 X T Y ⇒(X^TX)^{-1}(X^TX\theta)=(X^TX)^{-1}X^TY ⇒(XTX)−1(XTXθ)=(XTX)−1XTY ⇒ θ = ( X T X ) − 1 X T Y ⇒\theta=(X^TX)^{-1}X^TY ⇒θ=(XTX)−1XTY
这里我们假设 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1是存在的,这样我们就一下子求出了模型参数 θ θ θ了,免去了代数法一个个去求导的麻烦。只要给了数据,我们就可以用 θ = ( X T X ) − 1 X T Y θ=(X^TX)^{-1}X^TY θ=(XTX)−1XTY算出 θ θ θ。
3.2 梯度下降
与一元线性回归类似,初始化所有 θ \theta θ,再求出偏导数逐步迭代,最终得到最小代价函数时 θ \theta θ的值。
∂ ∂ θ J ( θ ) = X T ( X θ − Y ) \frac{\partial}{\partial\theta}J(\theta)=X^T(X\theta-Y) ∂θ∂J(θ)=XT(Xθ−Y)
θ : = θ − α ∂ ∂ θ J ( θ ) = α X T ( X θ − Y ) \theta:=\theta-\alpha\frac{\partial}{\partial\theta}J(\theta)=\alpha X^T(X\theta-Y) θ:=θ−α∂θ∂J(θ)=αXT(Xθ−Y)
4 多项式回归
假定现在只考虑房价和房屋面积的关系,或许他们之间存在着多项式的关系,例如:
f ( x ) = θ 0 + θ 1 x + θ 2 x 2 + θ 3 x 3 + θ 4 x 4 + . . . f(x)=\theta_0+\theta_1x+\theta_2x^2+\theta_3x^3+\theta_4x^4+... f(x)=θ0+θ1x+θ2x2+θ3x3+θ4x4+...
这就是多项式回归基本模型,其中 θ 0 , θ 1 , θ 2 , . . . \theta_0,\theta_1,\theta_2,... θ0,θ1,θ2,...均为模型参数。其求解方式与多元线性回归类似,因为我们可以作如下对应关系: x 1 = x , x 2 = x 2 , x 3 = x 3 , x 4 = x 4 , . . . x_1=x,x_2=x^2,x_3=x^3,x_4=x^4,... x1=x,x2=x2,x3=x3,x4=x4,...这样 f ( x ) f(x) f(x)可表示为:
f ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 3 + θ 4 x 4 + . . . f(x)=\theta_0+\theta_1x_1+\theta_2x_2+\theta_3x_3+\theta_4x_4+... f(x)=θ0+θ1x1+θ2x2+θ3x3+θ4x4+...
可以看出,与多元线性回归完全相似,其计算方法依然可以用多元线性回归的方法。
5 总结
主要介绍了一元线性回归、多元线性回归、多项式回归的算法原理,解释了使用最小二乘法和梯度下降进行回归任务。下面对最小二乘法和梯度下降进行比较:
| 梯度下降 | 最小二乘 |
|---|---|
| 需要学习率 α \alpha α | 不需要 |
| 需要多次迭代 | 一次运算即可 |
| 当特征数量n较多时也好用 | 随着特征数量n的增多,运算付出的代价更大,中间需要计算矩阵的逆 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1,在n<10000时还可以接受 |
| 适用于各种类型的模型 | 只适用于线性模型 |
参考内容:https://blog.csdn.net/pxhdky/article/details/82388964