【云原生系统故障检测论文学习】—— Going through the Life Cycle of Faults in Clouds: Guidelines on Fault Handling

软件可靠性工程国际会议 (International Symposium on Software Reliability Engineering, ISSRE) 专注于评估、预测和改善软件产品可靠性、安全性,包括前沿理论方法与创新技术工具,是软件可靠性工程领域的旗舰国际会议,也是中国计算机学会(CCF)推荐的B类国际会议
Abstract
Faults是破坏云系统高可用性的主要原因,甚至导致停机成本高昂。随着云的规模和复杂性的增加,理解和诊断faults变得非常困难。在停机过程中,工程师以事后分析(post mortems)的形式记录faults的整个生命周期(即fault occurrence, fault detection, fault identification, and fault mitigation)的详细信息。在本文中,我们对三个流行的大规模云收集的 354 个公共死后进行了定量和定性研究,其中 97.7% 跨越 2015 年至 2021 年。通过查看和分析事后分析,我们遍历云故障生命周期并获得 10 个主要发现。基于这些发现,我们进一步达到了一系列可操作的指南,以更好地处理错误。
1 INTRODUCTION
Faults, the culprits(罪魁祸首) of failures, break down the high availability of cloud systems and lead to service performance degradation, customer drain, and even a huge economic loss.
The complex topology and propagation path further prevent fault detection and diagnosis, exacerbating the impacts of faults.
From womb to tomb, faults generally experience a life cycle involving four stages:
fault occurrenceis the birth of a fault under a specific location and environmentfault detectionis the procedure when manifestations of a fault are detected as anomalies and raise engineers’ attentionfault identificationis the procedure when engineers correlate clues and figure out the reasonsfault mitigationis the procedure when engineers adopt methods and tools to alleviate and eliminate faults.
图1是2020年7月4日微软Azure的一个事后分析示例:

先前的一些工作对云系统中的故障进行了实证研究
- What went right and what went wrong: an analysis of 155 postmortems from game development。
- Why does the cloud stop computing? lessons from hundreds of service outages
- What bugs cause production cloud incidents?
- Failures and fixes: A study of software system incident response.
- Towards intelligent incident management: why we need it and how we make it
然而,他们只关注faults的部分生命周期。在本文中,研究目标是faults的整个生命周期。
We conduct an empirical study of 354 public postmortems that occurred within 9 years from 2011 to 2021 in three large-scale cloud providers (Google Clouds, Amazon Web Services, and Microsoft Azure). We ultimately guide our research with the following research questions (RQs):
我们对三家大型云提供商(谷歌云、亚马逊网络服务和微软Azure)在2011年至2021年9年内发生的354次公开事后分析进行了实证研究。最终决定用以下研究问题(RQs)来指导我们的研究:
- RQ1: What are the root causes of faults and their distribution in clouds?
- RQ2: How do the faults happen in clouds?
- RQ3: How are the faults detected in clouds?
- RQ4: How are the faults propagated and identified in clouds?
- RQ5: How are the faults mitigated in clouds?
2 RELATED WORK
A. Failure Studies
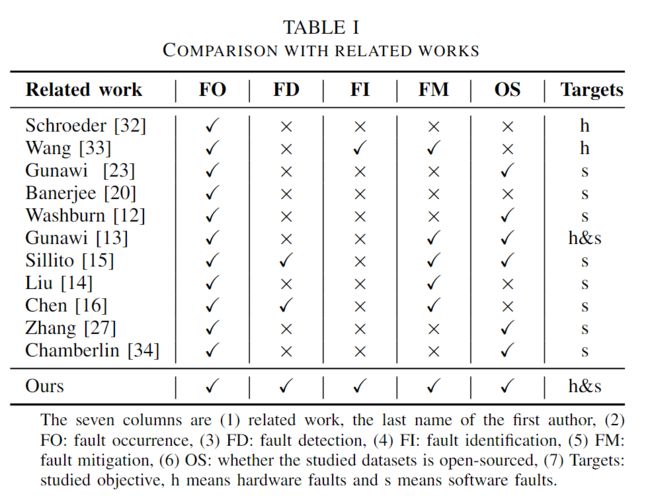
表1从多个角度对failure研究与其他重要相关工作进行了比较
B. Incident Management
Incident management plays a significant role in an online cloud service.
3 METHODOLOGY
本章讲述了讲原始未结构化的事后分析手工转换为结构化格式的方法。
A. Data Collection
在2011年至2021的10年内,我们从云服务供应商收集了354个有价值的事后分析作为原始数据集,包括14个AWS事故、242个Azure事故和98个Google Cloud事故。

B. Manual Labelling
遵循开源编码程序,编码过程是从观察(此处为事后分析)中提取定量的变量(例如,受影响的服务、故障传播路径、根本原因、解决时间、检测时间、缓解时间等)。
4 THE LIFE CYCLE OF FAULTS
A. An Overview of Time Spans Across Different Stages
不同阶段的时间跨度是评估故障重要性和处理云系统故障方法有效性的黄金标准。图2显示了云系统中故障的整个生命周期。四个阶段的 T i m e T o X ( T T X ) Time\ To\ X(TTX) Time To X(TTX) 进一步解释如下
- Time to Detect (TTD) is the time cloud systems take to detect a fault.
- Time to Identify (TTI) is the time cloud systems take to identify the root causes after detecting a fault.
- Time to Mitigate (TTM) is the time cloud systems take to mitigate faults. Sometimes, mitigating actions are applied without an accurate localization of root causes.
- Time to Resolve (TTR) is the time cloud systems take to resolve a fault. It includes the time spent on detecting a fault, identifying the root cause, and mitigating the issue.
- Time To Failures (TTF) is the time span between two failures, namely the uptime in cloud systems.

系统可用性可以被认为是正常运行时间与运行时间的相比,由如下等式定义:
A v a i l a b i l i t y = T T F T T F + T T D + T T I + T T M (1) Availability=\frac{TTF}{TTF+TTD+TTI+TTM}\tag{1} Availability=TTF+TTD+TTI+TTMTTF(1)
我们对数据集进行了Mean Time To X (MTTX)的统计研究,结果如表III所示。我们没有显示MTTF,因为跨云系统收集的数据集不是连续的。

图3显示了TTX的累积频率函数。在1分钟内检测故障,5分钟内定位故障,10分钟内减轻故障是DevOps的理想目标。及时发现故障是处理故障的关键。但只有15.7%的故障在一分钟内被检测到。定位时间距离目标也很遥远,只有14.0%达到了目标。十分钟内减轻故障只占1.9%,这意味着要达到理想的目标还有很大的进步。

B. RQ1: What are the root causes of faults and their distribution?
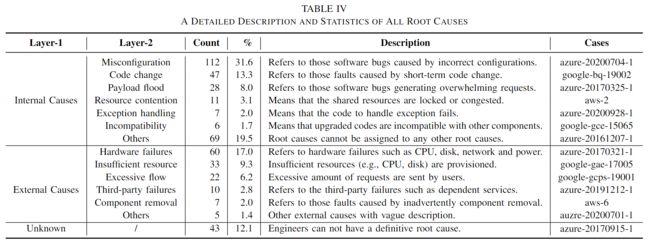
本研究从不同的角度提供了一个分层分类法。第一层是关于根本原因范围。由于我们的研究针对云系统,我们将软件中的根本原因视为internal causes,而将软件外的根本原因视为external causes。其他模糊RCA的故障被标记为unknown root causes.我们在表 IV 中展示了所有根因分类法的详细描述和统计数据。接下来,我们逐层说明根本原因的分层分类法。
请注意,本节的百分比是根据等式 P e r c e n t a g e ( % ) = # t y p e # f a u l t s Percentage(\%) = \frac{\#type}{\#faults} Percentage(%)=#faults#type 计算的。故障可能是由多个根本原因引起的,因此所有根本原因的百分比之和大于100%
1) Internal Causes (IC)
内部原因(主要是软件bugs)占故障总数的79.1%。我们将软件bugs主要分为7类:
- misconfiguration 错误配置
- code change 代码变更
- payload flood 负载洪流
- resource contention 资源竞争
- exception handling 异常处理
- incompatibility 不兼容
- others
最常见的根本原因是错误配置 (31.6%),因为配置是云系统中的重要组成部分,而最不常见的根本原因是不兼容 (1.7%)。
2) External Causes (EC)
由云软件系统外因素引起的这些故障归因于外部原因。在我们的研究中,外部原因覆盖了41.0%的故障,源于以下几方面:
- hardware failures 硬件故障
- insufficient resources 资源匮乏
- excessive flow 流量过大
- third-party failure 第三方故障
- component removal 组件移除
- others
我们可以观察到,硬件故障(17.0%)在实际环境中是最常见的外部原因。面对动态变化的工作量,资源不足(9.3%)也会导致拒绝请求,这在很大程度上影响客户。过多的流量(6.2%)可能是由异常的用户行为或固定的模式(如早高峰)生成的。其他根本原因,如第三方故障,组件移除分别只占2.8%和2.0%。
3) Unknown Causes (Un)
在某些情况下,工程师无法确定明确的根本原因 [azure-20170915-1]。这种情况被认为是未知的根本原因。
4) Multiple Root Causes
我们在表 V 中展示了根因的分布。我们找出那些由多种根因引起的案例,并总结出三种典型的形式:
- 一个根因可能不会引发
failure,但是在某些少见的情况下,多种根因的组合会产生failure,比如某些软件bug会由一些特定的配置产生[azure20180820-1]。 - 一个根因源于另一个根因,就像链式反应。
- 不正确的故障处理会产生新的故障。[google-bq-18036].

C. RQ2: How Do the Faults Happen?
除了根本原因的分布外,我们还更多地关注其他重要信息:What are the ongoing procedures when the faults occur? Are the faults related to human error? Why do these faults escape fault-tolerant mechanisms?
1) Ongoing Procedures
我们聚合了类似的正在进行的程序,最后列出了以下三个正在进行的程序簇。图 4 显示了已识别的第 1 层根本原因的正在进行的程序分布。

Upgrade and Maintenance,经常出现在开发和运维活跃的云系统,这种正在运行的程序是58.8%的故障的罪魁祸首。所以说,更新和维护会对正在运行的云系统造成扰动。
Upgrade (42.9%)。生产环境和测试环境之间的差距可能会导致系统升级过程中的故障。此外,一些案例[azure20200928-1]表明,安全部署实践(SDP)中的故障会向许多区域广播不良部署,从而加剧故障。在升级过程中,内部原因尤其是配置错误是最常见的根本原因,几乎占46.0%的故障。此外,84.8%的错误配置导致的故障发生在更新和维护期间。这表明更新时经常发生错误配置。
Maintenance (20.0%)。首先,故障会发生在日常维护期间,如硬件维护(例如,fire suppression system[azure-20170929-1]、fiber[azure20181024-1])和software maintenance(例如容量调整[azure20170518-1])。其次,缓解过程中的错误会加剧故障。[google-gcdf-16001]是一个典型的例子。
Normal Operation (NoOps):当云系统遇到故障时不会进行干预。由于外部原因造成的故障占NoOps中所有故障的56.3% (95),部分在升级和维护过程中大于故障
从图4中我们可以看到,在系统更新和维护期间,大约84.7%(238个)的故障是由内部原因造成的。在 NoOps期间,由外部原因引起的故障占所有故障的56.3%(95个),这个比例比更新和维护期间的要大。**这表明一旦成功部署了一个合格的系统版本并持续执行几天,系统很可能连续且正常地运行,而不会改变外部环境。**外部环境的变化极大地影响了云系统的内部稳定性。
2) Human Errors
根据我们的统计数据,人为错误回导致占7.6%的故障。与2003年19-36%的统计结果相比,人为错误大大减少。这表明intelligent operations的引入有助于减少人为错误。人为错误表现在两方面:
- 无意中的错误。例如,[azure-20180220-1] 中的工程师无意中回收生产规模单元上的power。
- 管理效率不高。例如 X 团队中的工程师通过电子邮件发送消息以通知其他团队,但另一个团队的工程师没有注意到它并进行冲突操作,导致服务中断。
3) Ineffective fault tolerance
什么样的故障确实逃脱了容错的机制。我们提供了三个具有代表性的场景:
- 备份可能会遇到故障。
- 潜在的故障可能隐藏在备份中。
- 性能低的问题会被掩盖,直到没有足够的可用副本才会暴露。
D. RQ3: How are the Faults Detected?
Fault detection is the primary step of fault handling that possibly affects following handling operations.
实践中的故障检测方法可以分为两部分:自动检测与人工检测。Rule-based monitoring方法是简单而有,因此在实践中被广泛使用。随着机器学习的流行,数据驱动的故障检测方法也引人注意,但它们在很大程度上仍处于研究阶段。
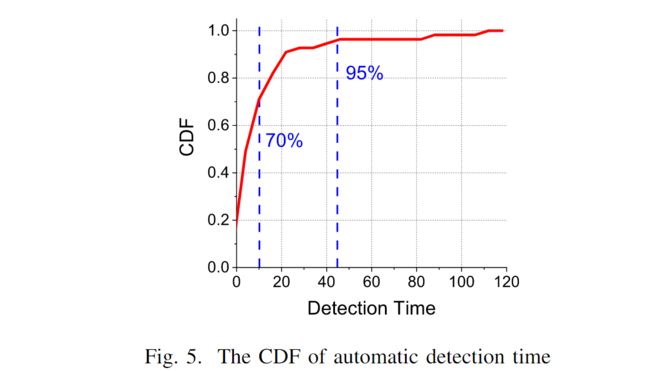
在我们的数据集中,只有 38.7% 的事后分析明确记录了工程师如何检测缺陷。根据我们的调查,大约 93.4% 的带有检测记录的案例使用了自动监控工具,例如使用健康监测和内部遥测工具来检测异常。**由此可见,基于规则和数据驱动的自动化监测方法在实践中发挥着重要作用。**图5显示了自动检测时间的CDF。约70%的故障可以在10分钟内自动检测到,95%的故障可以在47分钟内检测到。
E. RQ4: How are the Faults Propagated and Identified?
Fault identification is to first localize faulty components or metrics, and then identify the root cause of this fault.
现有的故障识别研究方法倾向于自动定位故障部件或指标,并向工程师报告。然后,工程师将手动确定根本原因。而云系统更为复杂,更难以识别故障。
了解trivial and non-trivial的传播模式有利于故障定位的研究。经过几轮讨论和验证,我们得出了一个高级别的抽象,并提供了对传播路径的更好的见解阐述。垂直方向可分为硬件、支持基础设施、操作系统、虚拟机和应用程序(服务)。支持基础架构包含扮演不同角色的服务器,如缓存服务器、作业服务器等。水平方向由前端、后端、存储、网络和中间件等云系统中的不同角色来标记。所有与网络相关的设备(如路由器、交换机、负载均衡器)以及与网络相关的组件(如DNS、VPN和网络控制平面)都分组到网络中。
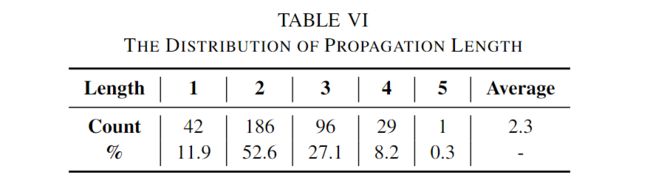
我们分析了传播长度的分布,并将结果显示在表VI中。可以观察到,大约88%的故障被传播到云系统中的其他组件。这表明有故障表现的部件可能不是根本原因部件。平均来说,在我们的研究中,故障会传播2.3个组件。
对于传播路径中的流分布,我们计算了两个抽象组件之间的边,并在表VII中给出了结果。本质上,故障是从底层传播的,比如从硬件传播到网络,从中间件传播到应用程序。因此,我们可以观察到,传播路径中的大多数目的地都是应用层。此外,传播路径中还存在环路(即表VII中的对角元素)。在APP内传播的有30例,在网络内传播的有20例。然而,也有一些反向传播的流量,如从“应用”到“网络”。
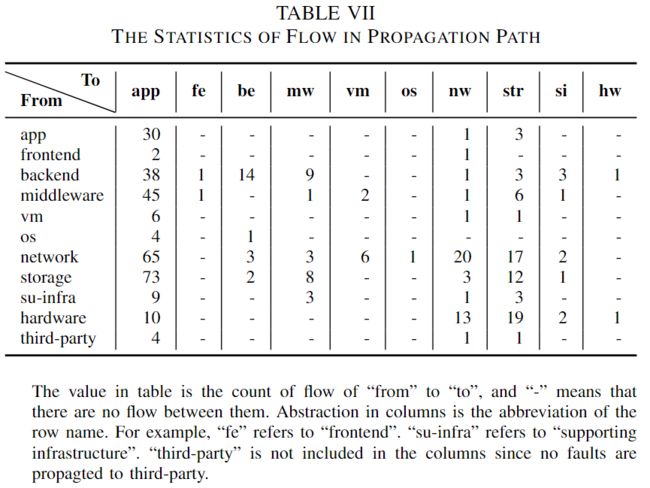
此外,我们在图6(A)和图6(B)中显示了频繁出现的前两个故障传播路径。案例1(11.0%)是从“网络”传播到“应用”。云系统中的网络负责连接面向用户的服务与底层系统之间。一旦网络中出现错误,极有可能将故障传播到应用层。案例2(9.0%)只包含一个节点APP,这意味着应用层的服务在没有传播的情况下遇到错误。我们发现,这种情况很可能是由应用层的软件错误或未知的根本原因造成的。未知的根本原因使得故障表现只能在应用层上找到。

我们给出了图6©中传播长度为5的特殊情况[#AWS-1]。
F. RQ5: How are the Faults Mitigated?
在弄清故障背后的故事和相关的检测和定位方法后,我们希望回答如何缓解故障,并揭示实践中常用的缓解措施。
1) Mitigation Actions
九种缓解措施如下:
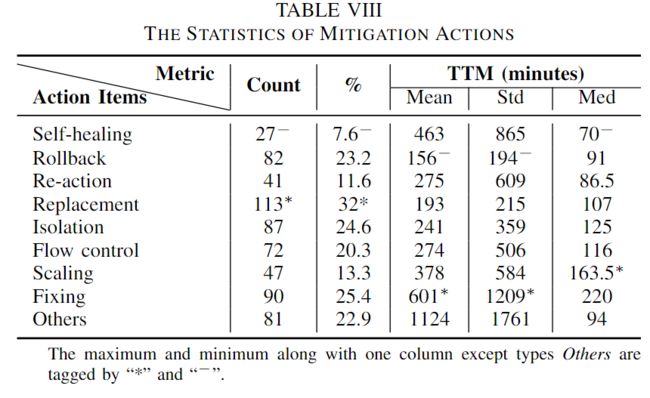
Self-healing
三种故障无需人工干预即可自愈,仅占全部故障的7.6%。首先,过载的服务在移除负载后会恢复健康。另一种情况是意外重启或重新安装,操作完成后,云系统恢复正常[google-gcnet-18019,azure20180220-1]。第三类是采用自动恢复机制,有时问题会通过自动恢复机制自行修复,而没有确定的根本原因[AZURE-20170517-1]。
Rollback
如果在发布、新功能部署、代码更改和配置更改等过程中出现故障,减少故障的简单但有效的方法是回滚[google-gce-16015]。根据我们的统计数据,回滚的缓解故障的时间最少。
Re-action
下一个缓解措施是redo process,如重新启动和重新部署组件,但有很高的风险破坏云系统的可用性[googlegcps-17001,google-bq-19003]。在分布式系统中,领导者选举模块是指定单个进程作为分布在多台计算机之间的一些任务的组织者。因此,强制领导人选举在分布式云系统中也很常见,以减轻领导人冲突的错误[google-gcnet-19020]。
Replacement
更换故障组件是缓解故障的快速措施,这是最常见的缓解措施。其中之一是更换软件组件。由于错误配置的覆盖率很高,用正确的配置替换配置是处理的快速方法[azure-20200604-1,azure-20200221-1]。清除满载组件也是一种理想的方法。另一个是更换硬件组件或故障转移[google-gae-15023]。
Isolation
当服务失败时,隔离是一种非常有效的手段。
第一种方法是使故障组件离线。一个是删除有故障的硬件组件[azure20190110-1],另一个是使服务离线,例如删除机制[google-gcic-2005]和禁用服务[google-csql-17017]。例如,[google-gcic-2005]中的高重试率和高重试量策略触发了拒绝服务(DoS)保护机制,导致了流量拥塞。删除DoS保护机制可以减轻症状。
第二种方法是取消任务,如暂停故障的发布[googlegcnet-19007]或维护[azure-20181129-1]、停止错误的迁移[google-gae-15025]和停止错误的工作流[azure-20200224-1]。
Flow control
缓解过载服务的一般缓解措施是限制速率、减少流量或重定向流量。
Scaling
扩大规模是为了缓解服务能力不足的状况。通常利用扩展和增加容量等缓解措施来缓解故障。
Fixing
在某些情况下,修补相应的bugs是常见的缓解措施。其他情况下采用roll out build以消除当前构建和之前构建的不兼容情况
others
缓解措施不清楚,无法被分类。
2) Relation between Root Causes and Mitigation Actions
通常,工程师根据SRE运行手册中的指导,根据具体的根本原因采取缓解措施。为了更好地了解实践中的缓解措施并为工程师提供指导,我们调查了根本原因和缓解措施之间是否存在详细且可解释的关系。由于收集的数据集中可能存在多种根本原因和缓解措施,我们首先使用笛卡尔乘积展开它们。
缓解措施与内部原因之间的关系如图7所示。例如,第一行中的51意味着由错误配置导致的51个故障可以通过回滚得到缓解。我们可以观察到,在大多数根本原因中,一些缓解措施非常明显,例如misconfiguration的Rollback和Replacement、code change的Rollback和Fixing。但是,对于由于根本原因导致的其他故障,如resource contention和exception handling,不同类型的缓解措施在故障缓解中被均匀应用

我们还分析了缓解措施和外部原因之间的关系,如图8所示。我们可以观察到,Replacement缓解了29个硬件故障。这是因为用健康的硬件替换有故障的硬件显然可以减轻故障。此外,不仅采取一种缓解措施来缓解故障。例如,为了减轻资源不足导致的故障,工程师首先隔离故障组件,然后扩展容量以容纳更多请求。与内部原因类似,一些外部原因(例如,component removal, third-party failures)中没有明显的缓解措施。
5 GUIDELINES ON FAULT HANDLING
接下来,我们通过总结数百例事后分析后的实证研究得出的指导方针,主动提供我们的见解。
A. Guidelines on Chaos Engineering in Clouds
**Chaos Engineering is the discipline of experimenting on a systemin order to build confidence in the system’s capabilityto withstand turbulent conditions in production.**主动模拟可能的故障使云工程师能够建立及时的识别机制和可行的缓解措施。
现有的混沌工程工具提供了延迟或丢弃API请求的方法;消耗系统资源;杀死、挂起进程或使节点崩溃;模拟网络压力等。图9可视化了当前混沌工程的能力与现实世界中的预期能力之间的差距。
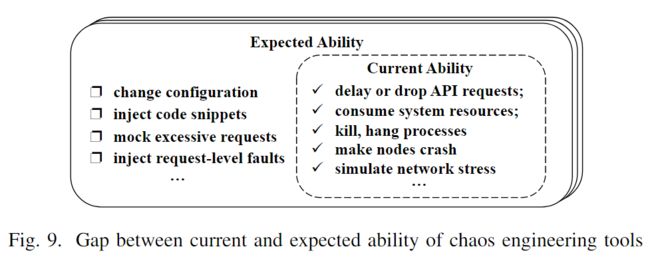
根据Finding 1,混沌工程工有望实现以下场景:
- 在运行时注入配置更改。
- 在运行时在特定位置注入代码片段。尽管
chaosblade提供了通过修改字节码在Java中注入代码片段的方法,但在GoLang和C++等其他编程语言中注入错误的进展仍处于初步阶段。这种能力可以模拟由code change,payload flood, exception handling, incompatibility引起的故障。 - 模拟对系统的过度请求。
- 注入请求级故障。
RQ2的探索揭示了一些意外的故障发生场景。根据发现3-6,混沌工程工有望在更多场景下实施:
- 测试和部署框架。破坏测试和部署框架的控制器,并验证这些机制的鲁棒性(robustness)和有效性。
- Failover机制。分解关键路由(如修改目标前缀),模拟流量未成功指向的场景。
- 备份组件。销毁软件和硬件中的备份组件,并检查它们是否能够以正确的状态执行。
- 运营框架,包括监控和缓解。破坏系统,并验证监控和缓解工具在破坏系统下是否仍然有效。
B. Guidelines on Observability in Clouds
可观测性是指根据系统的输出来理解和解释复杂系统状态的能力。云系统中可靠性的三个基础组成为:metrics, logs, and traces。为了更好的可观察性,我们根据人工理解的观察结果提供了三个指导方针:
- 建议保证可观测数据的完整性。监控数据的丢失可能导致错过警报,从而不利于进一步的故障处理。
- 建议提供组件间和组件内的分层可观察性。根据Finding 8,故障可能跨越多个组件传播。跟踪对于处理这种情况特别有效,它将一个“trace id”附加到请求,以便识别组件间和组件内部请求的整个执行路径。
- 建议按需控制观测数据采集的粒度。当前可观察数据的粒度主要集中在服务级别和实例级别。从本质上讲,细粒度的监测数据,如在请求级别,更有利于推断系统状态。考虑到开销和可观察性,按需控制可观察数据的颗粒度是云计算的一个富有前途的方向。
C. Guidelines on Intelligent Operations in Clouds
基于findings,我们提供了一些在经历故障生命周期后进行智能运维的指导方针:
- 基于Finding 3 , 当在更改过程中遇到故障时,指导工程师通过区分离线和在线在配置、执行流和数据流方面的差异来确定根本原因。它们之间的差异可能是根本原因。
- 基于Finding 4 , 鼓励工程师在升级和维护过程中关注内部原因。同样,鼓励他们重点监测正常运营期间外部环境的变化。外部环境的变化可能会为故障识别提供一些线索
- 基于Finding 8 , 建议考虑警报组件周围的两个或三个组件的上下文,以确定根本原因。
- 基于Finding 10 , 一些根本原因与缓解措施有很强的联系。对于这种根本原因,建议工程师设计自动化缓解措施推荐器,这样可以大大减少TTM。
不仅如此,现有智能运维工具的缺陷值得一定的关注。我们的研究可以指导两种可能的提升方面:
- 建议构建一个开销低的统一化智能运维流水线。从我们的研究来看,监控系统中的问题和不一致流水线[azure20180319-1, azure-20181119-1]可能会延迟故障的理解、检测和识别。
- 建议开发健壮的云系统。监控系统不完善,无法达到 100% 的准确率。按照尽可能捕获异常的原则,监控系统旨在获得比精度高的召回率。然而,错误警报可能会将系统触发自保护模式并破坏正常执行,导致意外故障。尽管收到不正确的指令,但稳健的系统会正常运行。
6 THREATS TO VALIDITY
对有效性的外部威胁在于我们收集的事后分析。我们系统地从大规模的云中收集了354个公共和有价值的事后分析。但大多数都提供脱敏信息。因此,我们的分析结果很大程度上取决于云供应商对故障信息的披露意愿。
对有效性的内部威胁在于人工标注的过程。由于云计算故障的复杂性,每个工程师在构建事后分析的过程中可能存在主观性。为了缓解这一威胁,我们的研究经历了多轮,涉及独立的结构化程序、交叉的结构化程序,以及对困难故障的进一步讨论。
7 CONCLUSION
随着云系统的规模和复杂性日益增长,需要对大规模云中的故障进行全面研究。我们从三个流行的云中收集了354个公共事后分析,并进行了定量和定性分析。在经历了故障的生命周期后,我们提供了一系列有趣的发现,并达成了一些故障处理的指导方针。我们相信我们的研究成果可以启发工业界和学术界的工程师和研究人员。
FINDINGS
Finding 1: Regarding the root cause distribution, 79.1% and 41.0% of faults are caused by internal and external causes, respectively. The most common causes in internal causes and external causes are misconfiguration and hardware failure, accounting for 31.6% and 17.0% of faults, respectively
Finding 2: 23.2% of studied faults are caused by more than one root causes, which is a non-negligible portion in practice.
Finding 3: 58.8% of faults occur during changes such as upgrades and maintenance. Faults during an upgrade may be caused by (i) the gap between production and pre-production environment in configuration, workload pattern, unusual invocation, and (ii) defects in the deployment framework. Faults during maintenance may be caused by routine maintenance and fault mitigation.
Finding 4: 84.7% of faults during system upgrades and maintenance are due to internal causes. 56.3% of faults during normal execution are due to external causes, which is larger than the one during changes.
Finding 5: Faults due to human errors take up 7.6% of all faults. The introduction of intelligent operations helps to reduce human errors.
Finding 6: The failure of fault tolerance may be caused by unsuccessful failover, faulty backups, and potential performance issues
Finding 7: Almost 93.4% recorded cases utilized automatic detection methods, 70% of which are detected in 10 minutes.
Finding 8: On average, faults passed through 2.3 components in our study. The most common path in fault propagation is from network to application.
Finding 9: The most and the least common mitigation actions are Replacement and Self-healing. Rollback spends the least time to mitigate faults while Fixing takes the most time on average.
Finding 10: Some root causes such as misconfiguration, code change, hardware failures, insufficient resource show a strong correlation with mitigation actions. But some root causes such as resource contention, exception handling, component removal, thirdparty failures are not.