Python dataframe绘制饼图_数据可视化之实践篇——python
一.10个可视化例子
import 1.散点图
plt: plt.scatter(x, y, marker=None) 函数。x、y 是坐标,marker 代表了标记的符号。比如“x”、“>”或者“o”。选择不同的 marker,呈现出来的符号样式也会不同。
sns: sns.jointplot(x, y, data=None, kind=‘scatter’) 函数。其中 x、y 是 data 中的下标。data 就是我们要传入的数据,一般是 DataFrame 类型。kind 这类我们取 scatter,代表散点的意思。当然 kind 还可以取其他值,这个我在后面的视图中会讲到,不同的 kind 代表不同的视图绘制方式。
matplotlib绘制的视图为矩形,seaborn为方形,且还额外显示x,y的直方图分布
# 随机1000个点,模拟绘制


#?plt.scatter

2.折线图
表示数据随时间变化趋势
在 Matplotlib 中,我们可以直接使用 plt.plot() 函数,当然需要提前把数据按照 x 轴的大小进行排序,要不画出来的折线图就无法按照 x 轴递增的顺序展示。
在 Seaborn 中,我们使用 sns.lineplot (x, y, data=None) 函数。其中 x、y 是 data 中的下标。data 就是我们要传入的数据,一般是 DataFrame 类型。
这里我们设置了 x、y 的数组。x 数组代表时间(年),y 数组我们随便设置几个取值
两个库绘制出来结果一致。
# data

# use seaborn

3. 直方图
直方图用以查看变量的数值分布。
在 Matplotlib 中,我们使用 plt.hist(x, bins=10) 函数,其中参数 x 是一维数组,bins 代表直方图中的箱子数量,默认是 10。
在 Seaborn 中,我们使用 sns.distplot(x, bins=10, kde=True) 函数。其中参数 x 是一维数组,bins 代表直方图中的箱子数量,kde 代表显示核密度估计,默认是 True,我们也可以把 kde 设置为 False,不进行显示。
核密度估计是通过核函数帮我们来估计概率密度的方法。
# data

# use seaborn

4.条形图
条形图查看类别特征。
在条形图中,长条形的长度表示类别的频数,宽度表示类别。
在 Matplotlib 中,我们使用 plt.bar(x, height) 函数,其中参数 x 代表 x 轴的位置序列,height 是 y 轴的数值序列,也就是柱子的高度。
在 Seaborn 中,我们使用 sns.barplot(x=None, y=None, data=None) 函数。其中参数 data 为 DataFrame 类型,x、y 是 data 中的变量。
# data

# use seaborn

5. 箱线图
箱线图,又称盒式图,它是在 1977 年提出的,由五个数值点组成:最大值 (max)、最小值 (min)、中位数 (median) 和上下四分位数 (Q3, Q1)。
它可以帮我们分析出数据的差异性、离散程度和异常值等。
在 Matplotlib 中,我们使用 plt.boxplot(x, labels=None) 函数,其中参数 x 代表要绘制箱线图的数据,labels 是缺省值,可以为箱线图添加标签。
在 Seaborn 中,我们使用 sns.boxplot(x=None, y=None, data=None) 函数。其中参数 data 为 DataFrame 类型,x、y 是 data 中的变量。
# data:10*4维度
# use seaborn

6.饼图
饼图是常用的统计学模块,可以显示每个部分大小与总和之间的比例。
在 Python 数据可视化中,它用的不算多。
我们主要采用 Matplotlib 的 pie 函数实现它。在 Matplotlib 中,我们使用 plt.pie(x, labels=None) 函数,其中参数 x 代表要绘制饼图的数据,labels 是缺省值,可以为饼图添加标签。
# data
7.热力图
热力图,英文叫 heat map,是一种矩阵表示方法,其中矩阵中的元素值用颜色来代表,不同的颜色代表不同大小的值。
通过颜色就能直观地知道某个位置上数值的大小。另外你也可以将这个位置上的颜色,与数据集中的其他位置颜色进行比较。
热力图是一种非常直观的多元变量分析方法。
我们一般使用 Seaborn 中的 sns.heatmap(data) 函数,其中 data 代表需要绘制的热力图数据。
# data
# use seaborn
8.蜘蛛图/雷达图
蜘蛛图是一种显示一对多关系的方法。在蜘蛛图中,一个变量相对于另一个变量的显著性是清晰可见的。
假设我们想要给王者荣耀的玩家做一个战力图,指标一共包括推进、KDA、生存、团战、发育和输出。那该如何做呢?
这里我们需要使用 Matplotlib 来进行画图,首先设置两个数组:labels 和 stats。
他们分别保存了这些属性的名称和属性值。
因为蜘蛛图是一个圆形,你需要计算每个坐标的角度,然后对这些数值进行设置。
当画完最后一个点后,需要与第一个点进行连线。
因为需要计算角度,所以我们要准备 angles 数组;又因为需要设定统计结果的数值,所以我们要设定 stats 数组。并且需要在原有 angles 和 stats 数组上增加一位,也就是添加数组的第一个元素。
from 
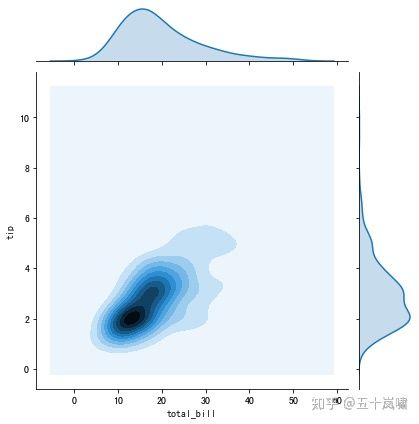
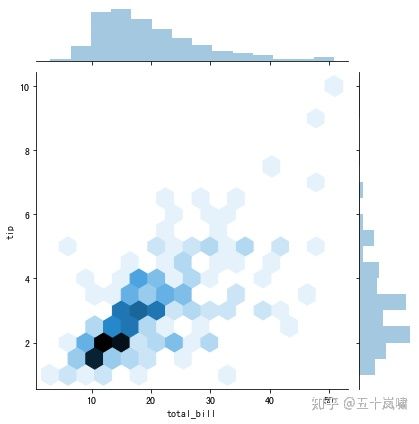
9.二元变量分布
如果我们想要看两个变量之间的关系,就需要用到二元变量分布。
当然二元变量分布有多种呈现方式,开头给你介绍的散点图就是一种二元变量分布。
在 Seaborn 里,使用二元变量分布是非常方便的,直接使用 sns.jointplot(x, y, data=None, kind) 函数即可。
其中用 kind 表示不同的视图类型:“kind=‘scatter’”代表散点图,“kind=‘kde’”代表核密度图,“kind=‘hex’ ”代表 Hexbin 图,它代表的是直方图的二维模拟。
这里我们使用 Seaborn 中自带的数据集 tips,这个数据集记录了不同顾客在餐厅的消费账单及小费情况。
代码中 total_bill 保存了客户的账单金额,tip 是该客户给出的小费金额。
我们可以用 Seaborn 中的 jointplot 来探索这两个变量之间的关系。
# data
# 用Seaborn画二元变量分布图(散点图,核密度图,Hexbin图)

10.成对关系
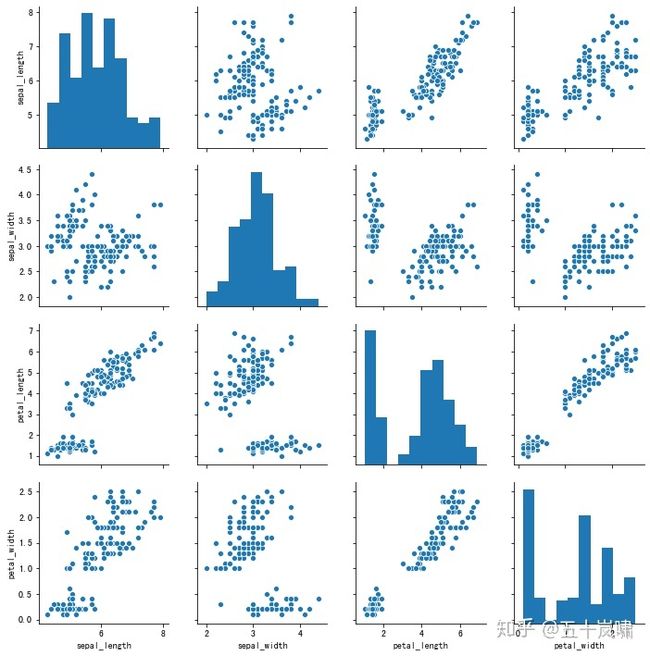
如果想要探索数据集中的多个成对双变量的分布,可以直接采用 sns.pairplot() 函数。
它会同时展示出 DataFrame 中每对变量的关系,另外在对角线上,你能看到每个变量自身作为单变量的分布情况。
它可以说是探索性分析中的常用函数,可以很快帮我们理解变量对之间的关系。
pairplot 函数的使用,就像在 DataFrame 中使用 describe() 函数一样方便,是数据探索中的常用函数。
# data
# use seaborn
二.可视化库一览
1.seaborn
官网:http://seaborn.pydata.org/
github:https://github.com/mwaskom/seaborn
Seaborn是基于matplotlib的Python数据可视化库。它提供了一个高级界面,用于绘制引人入胜且内容丰富的统计图形。
类似于:pandas比之numpy。
案例:
http://seaborn.pydata.org/examples/index.html
以下是相关绘制的api。
- 关系:API | 讲解
- 分类:API | 讲解
- 分布:API | 讲解
- 回归:API | 讲解
- 倍数:API | 讲解
- 样式:API | 讲解
- 颜色:API | 讲解
2.matplot
官网:https://matplotlib.org/
3.scipy
官网:https://www.scipy.org/
4.plotly
官网:https://plotly.com/
python-doc:https://github.com/plotly/plotly.py/tree/doc-prod/doc