电信客户流失分析实战
分析目标
找到流失用户特点
预测用户是否流失
提出优化建议
源数据
数据预处理
数据清洗
import pandas as pd
f = pd.read_csv(r'D:\Data\电信用户流失'
r'\WA_Fn-UseC_-Telco-Customer-Churn - Copy.csv')
#检索数据
print(pd.isnull(f).sum(), f.info())
#按列检索数据
# for x in f.columns:
# test = f.loc[:, x].value_counts()
# print('{0} 的行数是:{1}'.format(x, test.sum()))
# print('{0} 的数据类型是:{1}'.format(x, f[x].dtypes))
# print('{0} 的内容是:\n{1}\n'.format(x, test))
#object转为float
f['TotalCharges'] = f['TotalCharges'].convert_dtypes(float)
print(f.shape)
#去空值
f.dropna(how='any', inplace=True)
#去重复
f.drop_duplicates(inplace=True)
#去' '
index = f[(f['TotalCharges'] == ' ')].index.tolist()
f.drop(index=index, inplace=True)
print(f.shape)
f.to_csv(r'D:\Data\电信用户流失'
r'\WA_Fn-UseC_-Telco-Customer-Churn - Copy1.csv', index=False)
字段分析
| 字段 | 含义 |
|---|---|
| Customer ID | 用户ID |
| Gender | 性别 |
| Senior Citizen | 是否老年人 |
| Partner | 是否结婚 |
| Dependents | 是否有亲属 |
| Tenure | 使用时长 |
| Phone Service | 是否有电话服务 |
| Multiple Lines | 是否多机号 |
| Internet Service | 是否连接宽带 |
| Online Security | 是否开通网络安全服务 |
| Online Backup | 是否有线上备份 |
| Device Protection | 是否有设备保护 |
| Tech Support | 是否有技术支持 |
| Streaming TV | 是否订购电视 |
| Streaming Movies | 是否订购电影 |
| Contract | 合同时长 |
| Paperless Billing | 是否有电子账单 |
| Payment Method | 客户支付方式 |
| Monthly Charges | 每月消费金额 |
| Total Charges | 累计消费金额 |
| Churn | 是否流失 |
目标字段:
Churn(主指标)
影响字段:
除Customer ID和Churn外都可能是影响字段
按维度划分字段
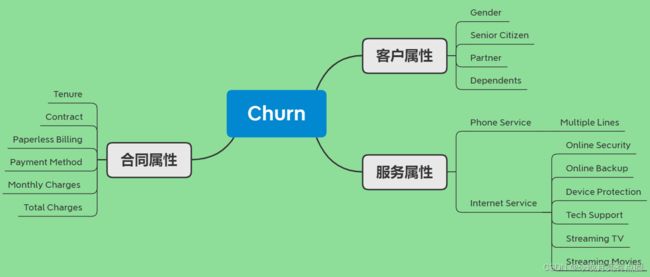
数据分析与可视化
客户属性
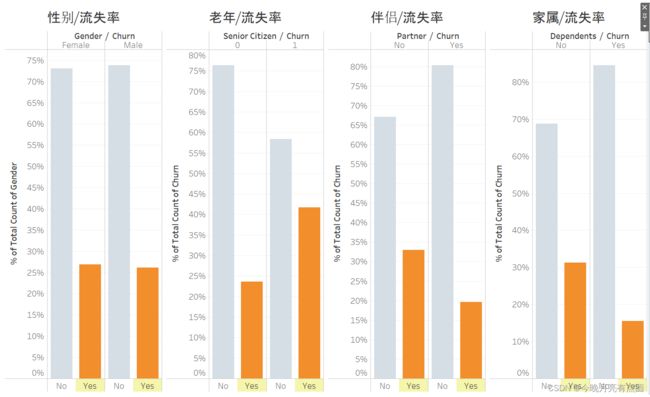
相对比率
总体比率
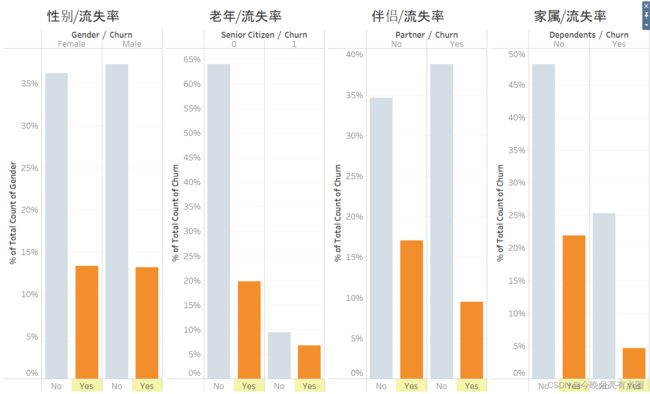
性别与流失率几乎不相关
老年用户流失率高
没有伴侣的用户流失率高
无家属的用户流失率高
服务属性
手机服务
相对比率
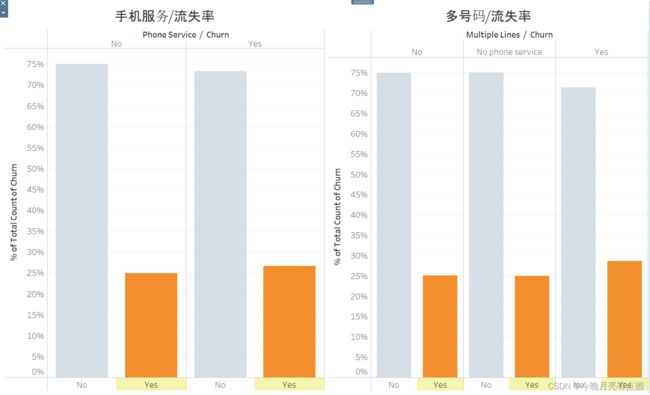
总体比率
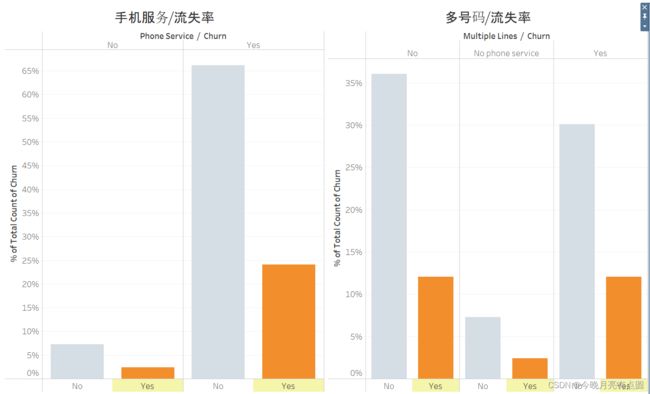
手机服务订购与否与流失率几乎不相关
是否多号码与流失率几乎不相关
网络服务
相对比率
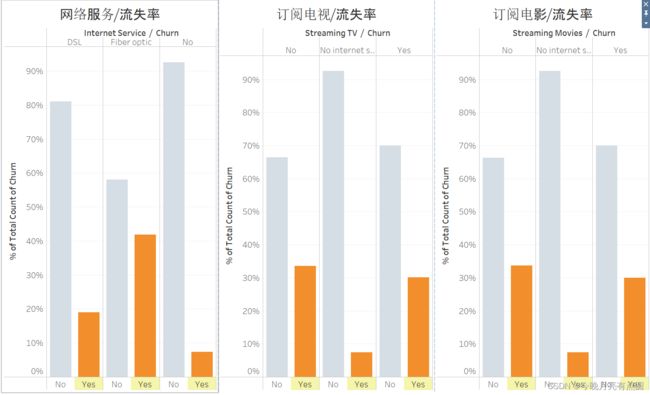
总体比率
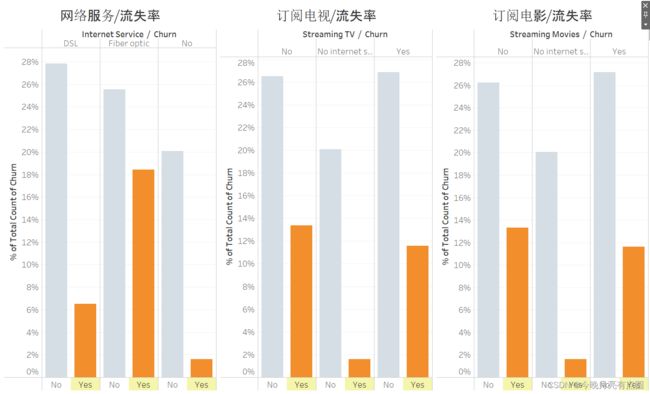
相对比率
总体比率

按网络服务订购方式,订购光纤网络的用户流失率最高
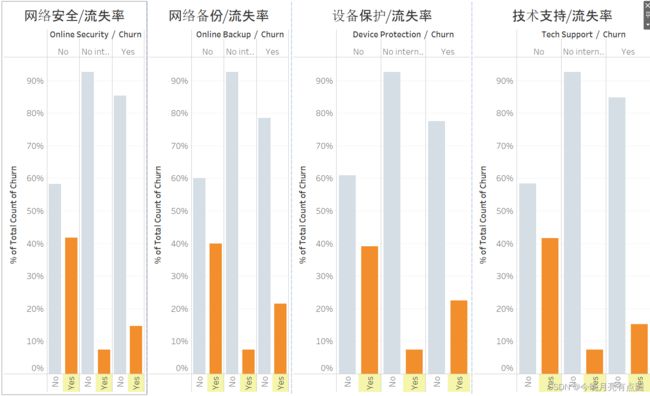
在订购了网络各项服务的用户中:
- 没有订阅电视流失率略微高
- 没有订阅电影流失率略微高
- 没有订购网络安全流失率高
- 没有订购网络备份流失率高
- 没有订购设备保护流失率高
- 没有订购技术支持流失率高
合同属性

-
随使用时长增加流失率降低
-
随付费增加流失率略微降低
-
月均付费与流失率几乎无关系
相对比率
总体比率

-
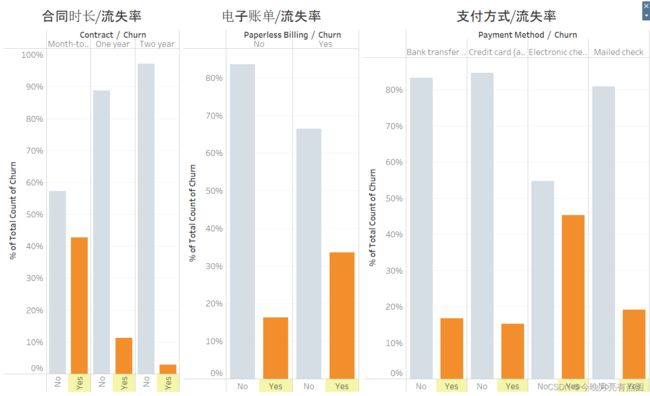
按月缴费用户流失率高
-
使用电子账单的流失率高
-
使用电子支付的流失率高
按所有属性划分(排除影响小的)
排名第一的属性

由此可以看出,拥有月度付费习惯,所有业务都不订购的用户流失率最高
总结
从总体上看,应该提高各项业务的订购率,可以通过促销等手段提高业务订购率,增加用户的粘性。
从维度上看:
- 提高无家属用户粘性
- 改善光纤服务质量
- 鼓励用户按年度付费,改善在线支付、账单系统体验
预测模型
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
# 预处理数据
f = pd.read_csv(r'D:\Data\电信用户流失'
r'\WA_Fn-UseC_-Telco-Customer-Churn - Copy1.csv', index_col=0)
x = f.iloc[:, :-1]
y = f.iloc[:, -1:]
x_train, x_test, y_train, y_test = train_test_split(x, y, stratify=y)
transfer = DictVectorizer(sparse=False)
x_train = transfer.fit_transform(x_train.to_dict(orient="records"))
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))
# 模型训练优化
model = DecisionTreeClassifier()
param = {"criterion": ['entropy', 'gini'],
"max_depth": [3, 5, 8, 12, 15]}
gc = GridSearchCV(model, param_grid=param, cv=2)
gc.fit(x_train, y_train)
# 评分和预测
print("决策树预测的准确率为:", gc.score(x_test, y_test))
print(gc.predict(x_test))
准确率:0.7861205915813424