论文模型构建的步骤_7篇ICLR论文,遍览联邦学习最新研究进展
机器之心分析师网络
作者:仵冀颖
编辑:H4O
本篇提前看重点关注 ICLR 2020 中关于联邦学习(Federated Learning)的最新研究进展。

2020 年的 ICLR 会议原计划于4 月 26 日至 4 月 30 日在埃塞俄比亚首都亚的斯亚贝巴举行,这本是首次在非洲举办的顶级人工智能国际会议,但受到疫情影响,ICLR 2020 被迫取消线下会议改为线上虚拟会议。今年的 ICLR 论文接受情况如下:共计接收 679 片文章,其中:poster-paper 共 523 篇、Spotlight-paper(焦点论文)共 107 篇、演讲 Talk 共 48 篇,另有被拒论文(reject-paper)共计 1907 篇,接受率为 26.48%。
本篇提前看重点关注 ICLR 2020 中关于联邦学习(Federated Learning)的最新研究进展。联邦学习是一种在分布式网络中实现的客户端本地存储数据并训练局部模型、中央服务器汇聚各客户端上载数据后训练构建全局模型的分布式机器学习处理框架。联邦学习能够有效解决分布式网络中两方或多方数据使用实体(客户端)在不贡献出数据的情况下的数据共同使用问题,同时保证全局模型能够获得与数据集中式存储相同的建模效果。关于联邦学习,机器之心也有过相关的进展分析报道。
在 ICLR 2020 的接受论文中,共有 7 篇文章与联邦学习相关,其中 2 篇为演讲 Talk的文章,5 篇为poster-paper。本文从中选择 3 篇进行分析,分别聚焦的是联邦学习的总体优化目标设置、全局模型构建方法以及数据特征对齐问题,具体为:
Poster Paper
Fair Resource Allocation in Federated Learning
Differentially Private Meta-Learning
DBA: Distributed Backdoor Attacks against Federated Learning
Generative Models for Effective ML on Private, Decentralized Datasets
Federated Adversarial Domain Adaptation
Talk
On the Convergence of FedAvg on Non-IID Data
Federated Learning with Matched Averaging
一、Fair Resource Allocation in Federated Learning

论文链接:https://arxiv.org/pdf/1905.10497v1.pdf
联邦学习的目标是通过最小化经验风险函数,使得模型能够拟合由若干网络设备中收集到的数据。通常情况下,联邦学习网络中的设备数量很大,从数百个到数百万个不等。这种简单直接的拟合操作可能会造成最终拟合的模型适合于一些设备,而在另外一些设备中不适用的问题。此外,不同设备中的数据存在大小不同、分布特征不同等异质性问题。这篇文章所要探讨的问题就是:是否可以设计一种优化方法来确保联邦学习模型的性能(如准确度)公平地分布在各个设备之间?
受无线网络公平资源分配工作的启发,本文提出了一种解决联邦学习中公平问题的优化目标算法 q-FFL(q-Fair Federated Learning)。q-FFL 通过引入 q 参数化的权重,实现了对不同设备损耗的重新加权计算,使得损耗较高的设备具有较高的相对权重,从而减小准确度分布方差,实现准确度更公平的分布。q-FFL 无需手工调整公平性约束,它构建的是一个灵活的框架,在该框架中可以根据所需的公平性自动调整目标。此外,本文提出了一种轻量级且可扩展的分布式 q-FFL 解决方法:q-FedAvg,该方法考虑了联邦学习架构的重要特征,例如通信效率和设备的低参与性等。
方法描述
经典联邦学习通常是最小化以下目标函数:
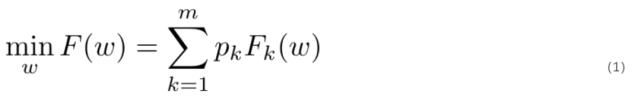
其中,m 表示设备数量,F_k 是各个客户端的局部目标函数,p_k 为客户端对应的权重。局部目标函数的优化处理过程为:
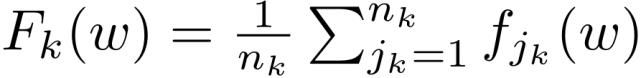
其中,n_k 为第 k 个客户端局部样本数据数量,可以令 p_k=n_k/n,n 为整个联邦学习网络的数据集中符合经验最小化目标的样本总数。传统方法通过以下方式实现全局目标最优化:每一轮选择概率与 n_k 成正比的设备子集执行这些本地更新方法通过在每个设备上本地运行可变数量的迭代的优化器(例如 SGD)来实现灵活高效的通信。经典联邦学习(FedAvg)的优化流程如下:

FedAvg 的优化过程会引入不同设备之间的不公平性。例如,所学习的模型可能偏向具有数据量大的设备,或者偏向于(通常是对设备加权)经常使用的一组设备等等。为了讨论如何解决联邦学习框架的不公平性问题,作者首先定义了什么是联邦学习中的公平性。
公平性定义:可以通过下面的方法衡量两个模型 w 和 w~的公平性,如果模型 w 在 m 个设备上的性能方差 {a_1,...,a_m} 小于模型 w~在 m 个设备上的性能方差,则认为模型 w 更公平,即
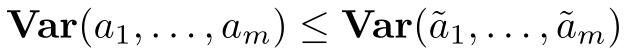
从公平性定义的角度出发,解决 FedAvg 中存在的不公平性的问题的一个很直观的办法就是重新对目标进行加权,即将较高的权重分配给性能较差的设备,以减小模型的准确度分布方差。此外,重新加权的处理必须是动态完成的,因为设备的性能取决于所训练的模型,这是无法进行先验评估的。给定非负代价函数 F_k 和参数 q>0,定义 q-FFL 目标如下:
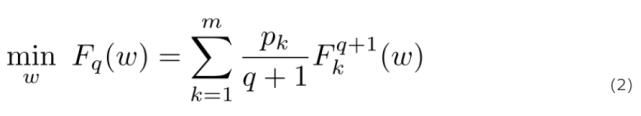
其中 (F_k).^(q+1) 表示 F_k 的 q+1 次幂,q 为调整所希望施加的公平性的权重参数。根据公平性定义,较大的 q 意味着 q-FFL 的目标强调(赋予较大权重)具有较高局部经验损失的设备 F_k(w),从而减少训练准确度分布的方差以及保证公平性。当 q 足够大时,F_q(w) 就退化为经典的 min-max 问题,此时,性能最差(最大损耗)的设备将会控制主导目标。
本文作者首先提出了一种公平但效率较低的方法 q-FedSGD,以说明在解决 q-FFL 问题时使用的主要技术,之后,通过考虑联邦学习的关键属性(例如本地更新方案),作者提供了一种更有效的解决方法 q-FedAvg。首先,q-FedSGD 是对经典的联合小批量 SGD(FedSGD)方法的扩展,其中使用动态步长替代了 FedSGD 中使用的常规固定步长。在 q-FedSGD 的每个步骤中,选择设备的一个子集,对于该子集中的每个设备 k,在当前迭代中计算其∇F_k 和 F_k 并将其传送到中央服务器,此信息用于调整权重,以收集整合来自每个设备的更新。具体算法如下:

在经典联邦学习方法中,在设备本地使用局部随机解算器(而不是批处理)能够改进本地计算与通信方面的灵活性,例如最著名的 FedAvg。然而,简单地在使用 q-FFL 目标的 q-FedSGD 中引入局部随机结算器是不成立的。这是由于当 q>0 时,不能使用局部 SGD 计算 (F_k)^(q+1)。作者提出将 q-FedSGD 步骤中的局部函数的梯度∇F_k 替换为通过在设备 k 上本地运行 SGD 获得的局部更新矢量,从而实现基于 q-FFL 目标的 FedAvg,即 q-FedAvg。作者的详细分析如下:优化 F_k 和优化 (F_k)^(q+1) 是等价的。如果通过简单的平均来组合这些更新,类似于 FedAvg,它将优化(1)而不是(2)。类似于 q-FedSGD,本文使用由下式推导得到的权重组合本地更新。如果非负函数 f 具有常数 L 的 Lipchitz 梯度,则对于任意 q≥0 和任意点 w,可得到:
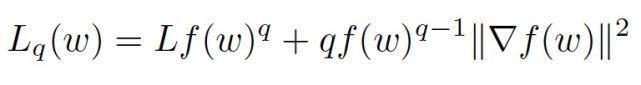
左式计算得到的权重是 w 点位置处梯度的局部 Lipchitz 常数的上界
在 q-FedAvg 的每个步骤中,选择设备的一个子集,对于该子集中的每个设备 k,在当前迭代中计算其局部更新向量并将局部更新向量传送到中央服务器,此信息用于调整权重,以收集整合来自每个设备的更新。具体算法如下:

实验分析
本文基于经典联邦学习的合成数据库和非合成数据库进行实验,实验中同时使用凸模型和非凸模型,在 TensorFlow 中实现所有代码,以一个服务器和 m 个设备模拟一个联邦学习网络。
图 1 给出了在每个数据集的 5 个随机抽取的数据中平均的两个目标(q = 0 和 q> 0 的调整值)的最终测试准确度分布。虽然平均测试准确度保持一致,但 q> 0 的目标能够产生更集中(即更公平)的测试准确度分布,且方差较小。特别的,在保持大致相同的平均准确度的同时,q-FFL 将所有设备上的准确度方差平均降低了 45%。

图 1. q-FFL 使得测试准确度分布更加公平
使用本文提出的联邦学习框架需要解决一个问题:如何在 q-FFL 目标中调整 q,从而允许框架灵活选择 q 以实现减小准确度分布方差和提高平均准确度之间的权衡。通常,可以根据可获得的数据/应用程序和所需的公平性来调整此值。特别地,在实践中,一种合理的方法是并行运行具有多个 q 的算法(详见 q-FedAvg 的算法流程),以获得多个最终全局模型,然后通过验证数据性能(例如准确度)从中进行选择。在这个过程中,联邦学习网络中的每个设备不仅可以从此过程中选择一个最佳 q,还可以根据其验证数据选择特定于设备的模型。表 1 中显示了这种针对特定设备的策略的性能改进。在表 1 中给出的实验的训练过程中,会独立维护多个全局模型(对应于不同的 q)。尽管这增加了额外的本地计算和每轮的通信负载,但使用这种特定于设备的策略同时提升了最差 10% 准确度(Worst 10%)和最佳准确度(Best 10%)的设备准确度。图 2 给出 q-FFL 与均匀采样方案的准确度比较,在测试准确性方面 q-FFL 给出了更公平的解决方案。
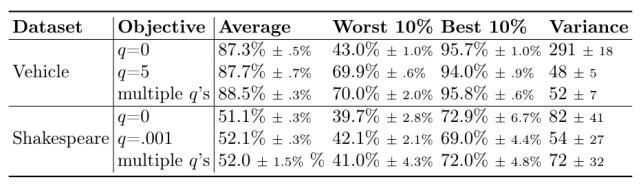
表 1. 同时运行多个 q 的 q-FFL 的效果

图 2. q-FFL(q> 0)与均匀采样的准确度比较
最后,作者对比了 q-FedSGD 和 q-FedAvg 的效率。在每个通信回合中,q-FedAvg 在每个所选设备上运行一个 epoch 的本地更新,而 q-FedSGD 则是基于本地训练数据运行梯度下降(SGD)。图 3 的结果显示,在大多数情况下使用 q-FedAvg 的本地更新方案收敛速度比 q-FedSGD 快。与 q-FedSGD 相比,在合成数据集上 q-FedAvg 收敛速度较慢,作者分析这可能是由于当存储在各个设备中的本地数据分布高度异构时,本地更新方案可能会造成本地模型与初始全局模型相距太远,进而影响收敛。

图 3. 对于固定目标(即相同的 q),q-FedAvg(Algorithm 3),q-FedSGD(Algorithm 2)和 FedSGD 的收敛性
文章小结
在无线网络中公平资源分配策略的启发下,本文提出了一种联邦学习的优化目标 q-FFL,目的是鼓励在联邦学习中实现更公平的准确度分配,此外本文还提出了一种高效且可扩展的方法 q-FedAvg,q-FedAvg 适用于使用新优化目标的联邦学习优化框架。
二、Federated Adversarial Domain Adaptation

论文链接:https://arxiv.org/abs/1911.02054
联邦学习是一种分散学习方法,它使多个客户机能够协作学习一个机器学习模型,同时将训练数据和模型参数保存在本地设备上。联邦学习提高了在分布式设备(如移动电话、物联网和可穿戴设备等)网络中进行机器学习的数据隐私性和效率。自提出联邦学习框架以来,研究人员陆续提出了很多模型/方法,包括更新机器学习模型的安全聚合方案、支持多客户端联邦学习的隐私保护协同训练模型等,但是这些方法大都忽略了以下事实:每个设备节点上的数据都是以非独立同分布(non-i.i.d)的方式收集的,因此节点之间存在域迁移的问题。例如,一台设备可能主要在室内拍摄照片,而另一台设备主要在室外拍摄照片。这种域迁移(domain shift)问题,造成使用联邦学习训练得到的模型很难推广到新设备。为了解决联邦学习中的 Non-IID 问题,一些方法引入联邦多任务学习,它为每个节点学习一个单独的模型,或者是提出隐私保护环境下的半监督联邦转移学习算法。这些算法一般采用的都是有监督/半监督的方式。
无监督域适应(Unsupervised Domain Adaptation,UDA)的目的是将从标记的源域学习到的知识迁移到未标记的目标域中。经典 UDA 方法包括:基于差异的方法(discrepancy-based methods)、基于重构的 UDA 模型、基于对抗的方法等,例如可以通过对抗性训练,在源域和目标域之间调整基于 CNN 的特征提取/分类器。在联邦学习架构中,数据存储在各个客户端本地而不能共享,这就导致经典的 UDA 方法都不适用,因为这些方法需要访问标记的源数据和未标记的目标数据。本文主要解决的问题是,在联邦学习架构下,在没有用户监督的情况下,将知识从分散节点转移到具有不同数据域的新节点的问题,作者将该问题定义为:无监督联邦域适应(Unsupervised Federated Domain Adaptation,UFDA)。
本文提出了一种解决 UFDA 问题的方法---联邦对抗域适应(Federated Adversarial Domain Adaptation,FADA)方法,该方法能够实现在不同的设备节点中学习到的表示与目标节点的数据分布相一致。FADA 是指:在联邦学习的架构中使用对抗性适应技术,通过在每个源节点上训练一个模型并通过源梯度(source gradients)的聚合来更新目标模型,同时保护数据隐私、减少域迁移。此外,本文还设计了一个动态注意力模型来应对联邦学习中不断变化的收敛速度,具体见图 1。

图 1.(a)本文针对 UFDA 问题提出了 FADA,在 FADA 中,不同域之间的数据不可共享,分别在每个源域上训练模型,并使用动态注意力机制汇总它们的梯度以更新目标模型;(b)FADA 使用对抗域对齐(红线)和特征分离器(蓝线)来提取域不变特征。
图 1(b)中提到 FADA 使用对抗域对齐和特征分离器来提取域不变特征。关于提取域不变特征的问题,主要是指深度神经网络能够在多个隐藏因素高度纠缠的情况下提取特征。学习分离表示有助于去除不相关和特定领域的特征,从而只对数据变化的相关因素建模。为此,最近的研究探索了利用生成性对抗网络(GANs)和变分自编码(VAEs)学习可解释表示以及领域不变特征。在 FADA 中引入了一种利用对抗性训练过程从领域特征中分离领域不变特征的方法。此外,通过引入最小化域不变特征和域特定特征之间的相互信息,以增强特征分离。
方法介绍
令 D_S 和 D_T 分别表示输入空间 X 上的源和目标分布,以及真实的标记函数 g:X→{0,1}。假设函数 h:X→{0,1},其误差为实地标记函数 g,h 在 D_s 上的风险记为:

两个分布 D 和 D』之间的 H-散度定义为:
其中 H 是输入空间 X 的假设类,A_H 表示 X 的子集的集合,这些子集是 H 中某些假设的支持。对称差空间 H∆H 定义为:
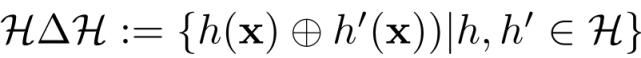
⊕表示 XOR 操作。将在源和目标上实现最小风险的最优假设表示为:
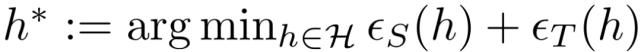
以及 h*的误差为:
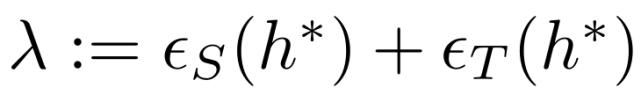
令 H 为 VC 维 d 的假设空间,D_S^和 D_T^为由 DS 和 DT 提取的大小为 m 的样本的经验分布。对于每个 h∈H,在样本选择上的概率至少为 1-δ:

定义 UFDA 中源域和目标域分别为
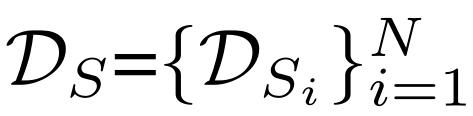


在联邦学习的域自适应系统中,D_S 分布在 N 个节点上,并且数据在训练过程中不可共享。经典的域自适应算法旨在最大程度地降低目标风险
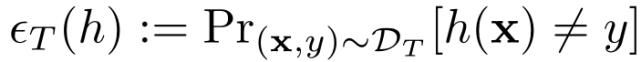
但是,在 UFDA 系统中,出于安全和隐私的原因,一个模型无法直接访问存储在不同节点上的数据。为了解决这个问题,本文提出为每个分布式源域学习单独的模型 h_S= {h_Si},目标假设 h_T 是 h_S 参数的集合。然后,可以得出以下误差范围:

其中λ_i 是 D_Si 和 T 的混合物的最优假设风险,而 S〜则是大小为 Nm 的源样本的混合物。
该误差范围证明了权重α和差异 d H∆H(D_S,D_T)在 UFDA 中的重要性,受此启发,本文提出了动态注意力模型来学习权重α和联合对抗性对齐,以最大程度地减少源域和目标域之间的差异。
1、动态注意力机制
在联邦学习的域自适应系统中,不同节点上的模型具有不同的收敛速度。此外,源域和目标域之间的域迁移是不同的,从而导致某些节点可能对目标域没有贡献甚至是负迁移。本文提出动态注意力机制,其原理是增加那些梯度对目标域有益的节点的权重,并限制那些梯度对目标域有害的节点的权重,利用差距统计数据来评估目标特征 f^t 在无监督聚类算法(K-Means)中的聚类程度,具体的,差距统计计算为:

其中,C1,C2,...,Ck 为聚类,其中 Cr 表示聚类 r 中的观测指标,而 nr = | Cr |。直观上,较小的差距统计值表示要素分布具有较小的类内方差。通过两次连续迭代之间的差距统计量增益来测量每个源域的贡献:
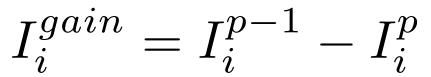
其中,p 表示训练步骤。该公式表示在建立目标模型之前和之后可以改进多少聚类。来自源域的梯度上的掩码定义为:

2、联合对抗对齐
在联邦学习框架中存在多个源域,并且数据以隐私保护的方式存储在本地,这意味着无法训练可以同时访问源域和目标域的单个模型。为了解决此问题,本文提出了联合对抗对齐,联合对抗对齐将优化分为两个独立的步骤:特定于域的局部特征提取器和全局鉴别器。(1)针对每个域,对应于 Di 训练一个本地特征提取器 Gi,以及针对 Dt 训练得到 Gt;(2)对于每个源-目标域对(Di,Dt),训练一个对抗性域标识符 DI 来以对抗性的方式对齐分布:首先训练 DI 以确定特征来自哪个域,然后训练生成器(Gi,Gt)来混淆 DI。需要注意的是,D 仅可访问 Gi 和 Gt 的输出向量,而不会违反 UFDA 设置。给定第 i 个源域数据 X^Si,目标数据 X^T,DI_s 的目标定义如下:
在第二步中,L_advD 保持不变,但是 L_advG 更新以下目标:
3、表征分离
本文采用对抗性分离(Adversarial Disentanglement)来提取域不变特征。如图 1(b)所示,分离器 Di 将提取的特征分为两个分支。首先分别基于 f_di 和 f_ds 特征训练 K 路分类器 Ci 和 K 路类别标识符 CI_i 正确地预测具有交叉熵损失的标签。目标为:
其中 f_di 和 f_ds 分别表示域不变和域特定特征。在下一步中,冻结类标识符 CI_i,仅训练特征分解器通过生成特定于域的特征 f_ds 来混淆类标识符 CI_i,如图 1 所示。这可以通过最小化预测类别分布的负熵损失来实现。目的如下:

特征分离可以通过保留 f_di、消除 f_ds 来促进知识迁移。为了增强分离,最小化域不变特征和域特定特征之间的相互信息:
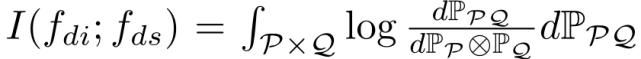
尽管互信息是跨不同分布的关键度量,但互信息仅适用于离散变量。本文采用互信息神经估计器(Mutual Information Neural Estimator,MINE)利用神经网络来估计连续变量的互信息:

为了避免计算积分,本文利用蒙特卡洛积分来计算估计值
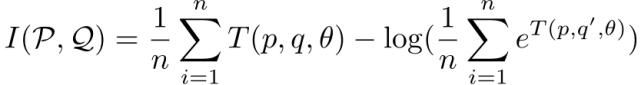
其中(p,q)从联合分布中采样,q』从边际分布中采样,T(p,q,θ)是由θ参数化的神经网络,用于估计 P 和 Q 之间的互信息。域不变和域特定的特征被转发给具有 L2 损失的重构器以重构原始特征,同时保持表征的完整性,如图 1(b)所示。可以通过调整 L2 丢失和互信息丢失的超参数来实现 L2 重建和互信息的平衡。
4、优化
本文模型以端到端的方式训练。使用随机梯度下降训练联邦对齐和表征分离组件。联合对抗性对准损失和表征分离损失与任务损失一起被最小化。详细的训练过程在算法 1 中给出:

实验分析
为了更好地探索模型中不同组成部分的有效性,本文提出了三种不同的剥离方法,包括:模型 I,具有动态关注度;模型 II,I +对抗性对齐;模型 III,II +表征分离。
本文首先基于 Digit-Five 数据库进行实验。Digit-Five 是由五个数字识别基准数据库组成的集合,这五个数据库分别是:MNIST,合成数字,MNIST-M,SVHN 和 USPS。在本文实验中,轮流将一个域(来自于其中一个数据库)设置为目标域,将其余域设置为分布式源域,从而生成五项迁移任务。本文将 FADA 与流行的域适应基准模型进行比较,包括:域对抗神经网络(DANN),深度适应网络(DAN),自动域对齐层(AutoDIAL)和自适应批归一化(AdaBN)等。具体而言,DANN 通过梯度反转层将源域和目标域之间的域差异最小化。DAN 应用多内核 MMD 损失以在「再生核希尔伯特空间」中将源域与目标域对齐。AutoDIAL 在深层模型中引入了域对齐层,以将源特征分布和目标特征分布与参考分布进行匹配。AdaBN 应用批处理规范化层来促进源域和目标域之间的知识迁移。在进行基准实验时,本文分别使用原模型的作者提供的代码并修改原始设置以适合联邦域对抗域适应设置(即每个域都有自己的模型),用 f-DAN 和 f-DANN 表示。此外,为了说明 UFDA 难以通过单一模型访问所有源数据的困难,本文还执行了相应的多源域适应实验(共享源数据)。实验结果列于表 1。从表 1 的结果可以得出以下结论:(1)模型 III 的平均准确度达到 73.6%,明显优于基线模型;(2)模型 I 和模型 II 的结果证明了动态注意力和对抗性对准的有效性;(3)联合域适应显示的结果比多源域适应弱得多。

表 1.「Digit-Five」数据库的准确度(%)
为了进一步了解 FADA 的特征表示性能,图 2 给出了不同模型得到的特征表示的 t-SNE 嵌入。与 f-DANN 和 f-DAN 相比,FADA 得到的特征嵌入具有较小的类内方差和较大的类间方差,这表明 FADA 能够生成所需的特征嵌入并能够提取跨域的不变特征。

图 2. 特征可视化:仅源特征的 t-SNE 图
表 2 中给出了在 Office-Caltech10 数据集上的实验结果,该数据集包含 Office31 和 Caltech-256 数据集共享的 10 个常见类别,以及包含四个域:Caltech(C),这是从 Caltech-256 数据集采样的;Amazon(A),这是从 amazon.com 收集的图像;Webcam(W)和 DSLR(D),这是由网络摄像头以及办公环境下的数码单反相机拍摄的图像。由表 2 可以得出以下观察结论:(1)本文提出的 FADA 模型使用 AlexNet 可以达到 86.5%的准确度,使用 ResNet 可以达到 87.1%的准确度,优于基线模型。(2)当选择 C,D,W 作为目标域时,所有模型的性能都相似,但是当选择 A 作为目标域时,各个模型的性能都较差。这可能是由较大的域差异引起的,因为 A 中的图像是从 amazon.com 收集的,并且包含白色背景。

表 2. Office-Caltech10 数据库的准确度(%)
亚马逊评论(Amazon Review)数据集是专门应用于文本跨域情感分析的测试数据库,即确定评论的情绪是正面还是负面。该数据集包含来自 amazon.com 用户的针对四个流行商品类别的评论:书籍(B),DVD(D),电子产品(E)和厨房用具(K)。本文利用 400 维词袋表示法及完全连接的深度神经网络进行实验,实验结果见表 3。从表 3 结果中可以得出两个主要观察结论:(1)FADA 模型不仅对视觉任务有效,将其应用于语言任务也表现出了较好的性能。(2)从模型 I 和 II 的结果可以观察到动态注意力和联邦对抗的对齐方式对提高性能很有帮助。
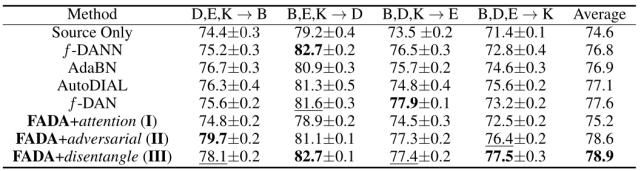
表 3.「Amazon Review」数据库的准确度(%)
最后为了证明动态注意力的有效性,本文给出了消融(ablation)研究分析。表 4 给出了 Digit-Five,Office-Caltech10 和 Amazon Review 基准测试的结果。在没有应用动态注意力模型的情况下,大多数实验的性能都会下降,因此动态注意力模块对于 FADA 是非常重要的。使用动态注意力模型能够有效应对联邦学习中不断变化的收敛速度,即不同的源域具有自己的收敛速度的问题。另外,当特定域和目标域之间的域迁移较小时,它将增加特定域的权重,相反,则降低权重。

表 4. 消融研究结果
文章小结
在本文中,作者定义了无监督联邦域适应(UFDA)问题,并给出了对 UFDA 的理论推广。此外,本文提出了一种称为-联邦对抗域适应(FADA)的联邦学习模型,通过动态注意力模式能够有效地将从分布式源域学到的知识迁移到未标记的目标域。
三、Federated Learning with Matched Averaging

论文链接:http://arxiv.org/abs/2002.06440
联邦学习允许边缘设备协作学习共享模型,同时将训练数据保留在本地设备中,从而实现将模型训练与数据存储在云中的需求分离开来。本文针对卷积神经网络(CNN)和长短期记忆网络(LSTM)等现代神经网络结构的联邦学习问题,提出了一种联邦匹配平均(Federated Matched Averaging,FedMA)算法。FedMA 通过匹配和平均具有相似特征提取特征的隐藏元素(即卷积层的通道;LSTM 的隐藏状态;完全连接层的神经元等)以层的方式构建共享全局模型。
经典联邦学习 FedAvg 的一个缺点是直接对模型参数进行加权平均,可能会对模型性能产生严重的不利影响,并显著增加通信负担,而这一问题主要是由于神经网络(NN)参数的置换不变性而导致的。比如,模型训练后的有些参数会在不同的变体中处于不同的位置,因此,直接对模型进行基于参数位置的加权平均可能使得某些参数失效。本文所提出的 FedMA 引入贝叶斯非参数方法以解决数据中的异质性问题。
方法介绍
本文首先讨论神经网络(NN)架构的置换不变性,并在 NNs 的参数空间中建立平均的概念。首先从最简单的单层隐藏层全连接 NN 开始介绍,之后针对深度架构、卷积和循环架构进行分析。
1、全连接架构的置换不变性
基本的全连接(FC)NN 可以表示为

在不失一般性的前提下,上式省略了偏差以简化表示,σ是非线性的(entry-wise)。扩展上式,得到

其中 i·和·i 分别表示第 i 行和第 i 列,L 是隐藏单元的数目。进一步,将 FC 的置换不变性写作:
置换矩阵是一个正交矩阵,当应用于左侧时,它作用于行,而应用于右侧时,则作用于列。假设 {W1,W2} 是最佳权重,那么从两个同质数据集 X_j,X_j』训练获得的权重分别为 {W_1Π_j,(Π_j)^TW_2} 和 {W_1Π_j』,(Π_j』)^TW_2}。现在可以很容易地看出为什么在参数空间中进行简单的直接平均处理是不合适的。
令 w_jl 表示数据库 j 中学习得到的第 l 个神经元(W(1)Π_j 中的第 l 列)。θi 表示全局模型中的第 i 个神经元,c(·,·) 表示一对神经元之间的相似函数。以下优化问题的解决方案是所需的置换:

给定 J 个客户端提供的权重 {W_j,1,W_j,2},计算得到联邦神经网络权重:
基于上式与最大二分匹配问题之间的关系,本文将此方法称为匹配平均(matched averaging)。如果 c(·,·)是欧式距离的平方,则可以得到类似于 k-means 聚类的目标函数,当然,该目标函数对「聚类分配」π 附加有额外的约束,以确保它们能够形成置换矩阵。
2、关键(深度、卷积、循环)架构的置换不变性
在介绍卷积和递归架构之前,首先讨论深度 FC 中的置换不变性和相应的匹配平均方法。
在 FC 置换不变性的基础上扩展,得到递归定义的深度 FC 网络
其中,n=1,...,N 表示层索引,π_0 是按照输入特征 x=x_0 排序的无歧义表征,π_N 表示输出类中对应的表征。σ(·) 为身份表征函数(或者是 softmax 函数,如果想要的是概率而不是逻辑值)。当 N=2 时,恢复得到一个与 FC 置换不变性一样的单隐藏层变量。为了对从 J 个客户机获得的深层 FCs 进行匹配平均,需要为每个客户端的每一层找到置换。然而任何连续的中间层对内的置换都是耦合的,这是一个 NP-hard 的组合优化问题。本文考虑递归(层内)匹配平均方法:假设有 {∏_(j,n-1)},将 {(∏_(j,n-1))^T W_j,n} 插入上式中,从而找到 {∏_(j,n)} 并移动到下一层。
与神经元不同,卷积 NN(CNNs)的不变性体现在通道(channel)不变性上。令 Conv(x,W)表示输入 x 的卷积运算,W 为权重。对权重的输出维度应用任何置换,以及对后续层的输入通道维度应用相同的置换,都不会改变相应的 CNN 的前向反馈。CNNs 的元素表示为:
上式允许在通道内进行池操作。为了对第 n 个 CNN 层应用匹配平均,按照公式(2)转换输入形式为:

其中 D 是 (∏_(j,n-1))^T W_j,n 的展平后的维度数。类似于 FCs,可以递归地在深度 CNNs 上执行匹配平均。
递归结构(RNN)中的置换不变性与隐藏状态的顺序有关。递归结构与 FC 结构相似,主要区别在于隐藏层到隐藏层的权重 H∈ R^(L×L) 排列不变性,其中,L 是隐藏状态的数目。隐藏状态的排列同时影响 H 的行和列。对于一个经典 RNN h_t= σ(h_t−1 H + x_t W),其中 W 是隐藏权重的输入。为了解释隐藏态的置换不变性,对于任何 t,h_t 的所有维度都应该以相同的方式进行置换,即
为了匹配 RNN,需要将欧氏距离相似的两个客户端的隐藏权重与隐藏权重对齐。本文的匹配平均 RNN 解是利用公式在输入到隐藏层的权重 {W_j} 中来找到 {∏_j},隐藏层权重输入的计算方式与之前一致,联邦隐藏层到隐藏层的权重 H 计算为

LSTMs 有多个单元格状态,每个状态都有其各自的隐藏到隐藏的和输入到隐藏的权重。在外匹配平均过程中,当计算置换矩阵时,将输入到隐藏权重的信息叠加到 S D×L 权重矩阵(S 是单元状态数,D 是输入维数,L 是隐藏状态数)中,然后如前所述平均所有权重。LSTMs 通常也有一个嵌入层,将这一层当作一个 FC 层来处理。最后,以类似于深度 FCs 的递归方式处理深度 LSTMs。
3、FedMA 的完整算法流程
首先,数据中心(中央服务器)只从客户端收集第一层的权重,并执行前面描述的单层匹配以获得联邦模型的第一层权重。然后数据中心(中央服务器)将这些权重广播给客户端,客户端继续训练其数据集上的所有连续层,同时保持已经匹配的联邦层冻结。然后,将此过程重复到最后一层,根据每个客户端数据的类比例对其进行加权平均。FedMA 方法要求通信轮数等于网络中的层数。具体流程见算法 1:

实验分析
图 1 展示了层匹配 FedMA 在更深的 VGG-9CNN 和 LSTM 上的性能。在异构环境中,FedMA 优于 FedAvg、FedProx(LeNet 和 LSTM 为 4,VGG-9 为 9)和其他基线模型(即客户端个人 CNN 及其集成)训练得到的 FedProx。

图 1. 基于 MNIST 的 LeNet;基于 CIFAR-10 数据集的 VGG-9;基于 Shakespeare 数据集的 LSTM 上有限通信量的各种联邦学习方法的比较:(a)同构数据划分(b)异构数据划分
FedMA 的优点之一是它比 FedAvg 更有效地利用了通信轮次,即 FedMA 不是直接按元素平均权重,而是识别匹配的卷积滤波器组,然后将它们平均到全局卷积滤波器中。图 2 给出了可视化的一对匹配的本地滤波器、聚合的全局滤波器和 FedAvg 方法在相同输入图像上返回的滤波器所生成的表示。匹配滤波器和用 FedMA 生成的全局滤波器能够提取输入图像的相同特征,即客户端 1 的滤波器 0 和客户端 2 的滤波器 23 提取马腿的位置,而相应的匹配全局滤波器 0 也提取马腿的位置。对于 FedAvg,全局滤波器 0 是客户端 1 的滤波器 0 和客户端 2 的滤波器 0 的平均值,这明显篡改了客户端 1 的滤波器 0 的腿部提取结果。
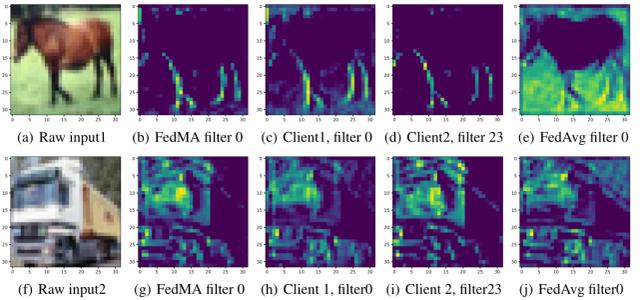
图 2. 由局部训练模型、FedMA 全局模型和 FedAvg 全局模型的第一卷积层生成的表示
最后,作者研究了 FedMA 的通信性能。通过将 FedMA 与 FedAvg、FedProx 进行比较,在数据中心(中央服务器)和客户端之间交换的总消息大小(以千兆字节为单位)和全局模型实现良好效果所需的通信轮数(完成一次 FedMA 过程需要的轮数等于本地模型中的层数)测试数据的性能。此外,还比较了集成方法(Assemble)的性能。本文在 VGG-9 本地模型的 J=16 客户端的 CIFAR-10 数据库和 1 层 LSTM 的 J=66 客户端的 Shakespeare 数据库上评估了异构联邦学习场景下的所有方法。实验确定了 FedMA、FedAvg 和 FedProx 允许的总通信轮数,即 FedMA 为 11 轮,FedAvg 和 FedProx 分别为 99/33 轮,用于 VGG-9/LSTM 实验。FedMA 在所有情况下都优于 FedAvg 和 FedProx(图 3),当在图 3(a)和图 3(c)中将收敛性作为消息大小的函数进行评估时,它的优势尤其明显。
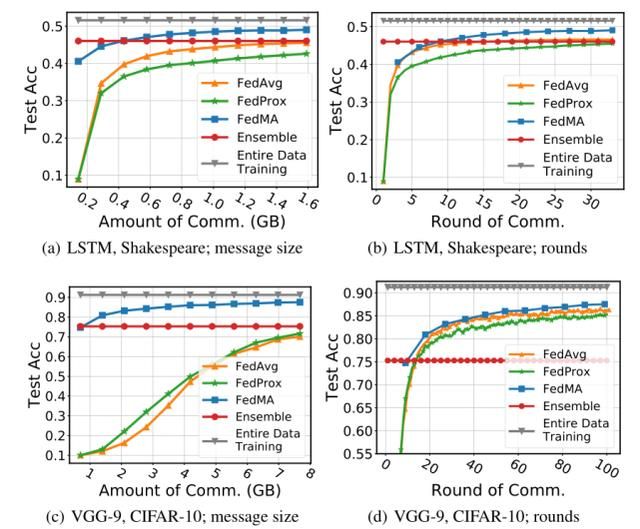
图 2. 两种联合学习场景下各种方法的收敛速度:在 CIFAR-10 上训练 VGG-9,J=16 个客户端;在 Shakespeare 上训练 LSTM,J=66 个客户端
文章小结
本文提出了 FedMA----一种为现代 CNNs 和 LSTMs 体系结构设计的分层联邦学习算法,它考虑了神经元的排列不变性,并实现了全局模型大小的自适应变化。本文证明了 FedMA 可以有效地利用训练后的局部模型,这也是联邦学习算法和架构主要考虑的问题。在后续工作中,作者考虑利用近似二次分配解(Approximate Quadratic Assignment Solutions)的方法引入额外的深度学习构建块,例如剩余连接和批处理规范化层,从而进一步改进 LSTMs 的联邦学习效果。此外,作者提出,探索 FedMA 的容错性并研究其在更大数据库上的性能非常重要,特别是针对那些即使在数据可以聚合的情况下也无法进行有效训练的数据库。
作者介绍:仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。