将爬取的数据以文件的方式进行存储
1、以文本的形式存储
我们打开知乎的源代码:
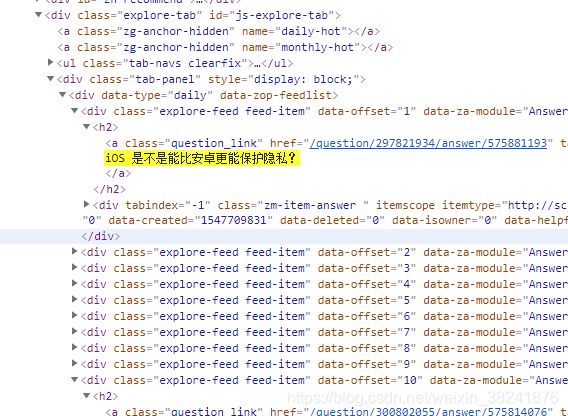
发现信息都是存储在class属性为explore-tab feed-item的div标签中:
import requests
from pyquery import PyQuery as pq
url = 'https://www.zhihu.com/explore'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'\AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
html = requests.get(url,headers=headers).text
doc = pq(html)
items = doc('.explore-tab .feed-item').items()#获取我们想要的信息的标签并生成迭代器
#对每一个符合条件的标签作遍历
for item in items:
question = item.find('h2').text()#查询h2子节点获取文本得到问题
author = item.find('.author-link-line').text()
# 因为回答是嵌入在很多p标签里面,因此我们先将其转化为html格式再转化为pyquery对象获取其中的文本
answer = pq(item.find('.content').html()).text()
with open('explore.txt','a',encoding='utf-8') as file:
#将三个组合为一个列表,然后在每一个成员插入一个换行符再写入文件
file.write('\n'.join([question,author,answer]))
file.write('\n'+'='*50+'\n')2、以json格式存储
loads()方法可以将json文本字符串转化为json对象,dumps()方法可以将json对象转化为字符串。下面来看一个将列表写入文本的例子:
import json
data = {
'姓名':'hi',
'年龄':20,
'生日':'1998-12-12'
}
with open('data.json','w',encoding='utf-8') as file:#指定以编码格式为utf-8写入,不然可能会写入乱码
file.write(json.dumps(data,indent=2,ensure_ascii=False))#indent=2表示缩进为2,ensure_ascii=False时可以输出中文3、以CSV文件进行存储
先来看一个简单的例子:
import csv
with open('data.csv','w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id','name','age'])#writerow方法将这一行数据进行写入
writer.writerow(['1001', 'Mike', 20])
writer.writerow(['1002', 'Bob', 21])
writer.writerow(['1003', 'Jone', 22])运行结果:

调用writerows()方法可同时写入多行:
import csv
with open('data.csv','w') as csvfile:
writer = csv.writer(csvfile)
writer.writerows([['id','name','age'],['1001', 'Mike', 20],['1002', 'Bob', 21],['1003', 'Jone', 22]])但一般情况下爬虫爬取下来的数据都是字典类型的,csv也有相应的应对策略:
import csv
with open('data.csv','w') as csvfile:
fieldnames = ['id','name','age']#定义三个字段
#初始化一个字典写入对象
writer = csv.DictWriter(csvfile,fieldnames=fieldnames)
writer.writeheader()#写入头信息
#写入对应的内容
writer.writerow({'id':'1001','name':'Mike','age':20})
writer.writerow({'id': '1002', 'name': 'Bob', 'age': 21})
writer.writerow({'id': '1003', 'name': 'Jone', 'age': 22})如果写入的内容中含有中文信息,那么在打开文件的时候声明编码格式即可:open('data.csv','a',encoding='utf-8')。
用csv也可以将其读出来:
import csv
with open('data.csv','r',encoding='utf-8') as f:
reader = csv.reader(f)
for row in reader:
print(row)