第六课 多算法组合与模型调优
本系列是七月算法机器学习课程笔记
文章目录
- 1 前序工作流程
-
- 1.1 数据处理
- 1.2 特征工程
- 1.3 模型选择
- 1.4 交叉验证
- 1.5 寻找最佳超参数
- 2 模型优化
-
- 2.1 模型状态
- 2.2 模型优化1
- 2.3 模型优化2
- 2.4 模型优化3
- 2.5 模型优化4:模型融合
-
- 2.5.1 bagging
- 2.5.2 staking
- 2.5.3 adaboost
- 2.5.4 Gradient Boosting Tree
1 前序工作流程
1.1 数据处理
1.2 特征工程
这两部分在第五课已经说明了。
1.3 模型选择
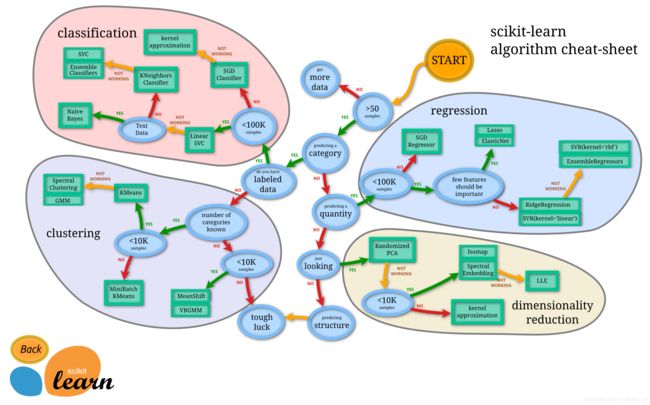
在sklearn中有关于算法选择的路径图。但也不是绝对的。
模型选择有两种含义。
第一种是:选择不同算法。
当拿到一个问题先看属于这4种类型中的哪一种:分类?回归?聚类?降维?例如搜索结果排序,看上去不是上面的任何一种。继续想为什么要排序,排序就是把用户想点的数据放在前面,那就可以将问题看做是分类问题:用户会点的数据和用户不会点的数据。当然也可以看做是回归问题:用户点击数据的概率。
此外还要看数据类型:是文本型数据还是数值型数据。例如分类问题中文本型数据推荐使用朴素贝叶斯算法。数值型可以使用K近邻或者SVM。
第二种是:选择超参数
这就类似于师哥师姐给你介绍了很多学习方法,当用在你自己的具体情况下,究竟该学习多少小时的英语,该用多少小时学习数学。这是需要考虑的。
1.4 交叉验证
交叉验证是用于评估模型超参数的一种方法。
我们将数据集分为训练集和测试集。测试集用于评估模型,只能使用一次,类比于三年只能参加一次高考。
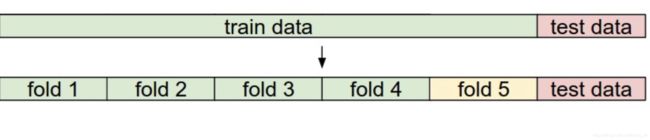
交叉验证最常采用的方法是K折交叉验证。是将训练集分为k份。每次随机选择一份数据用于验证,其余数据用于训练。
例如下图,在给定一组超参数条件下,使用其中1份数据用于评估,4份数据用于训练。做5次训练,得到5个模型的评估结果,求其平均值作为该组参数的验证结果。
1.5 寻找最佳超参数
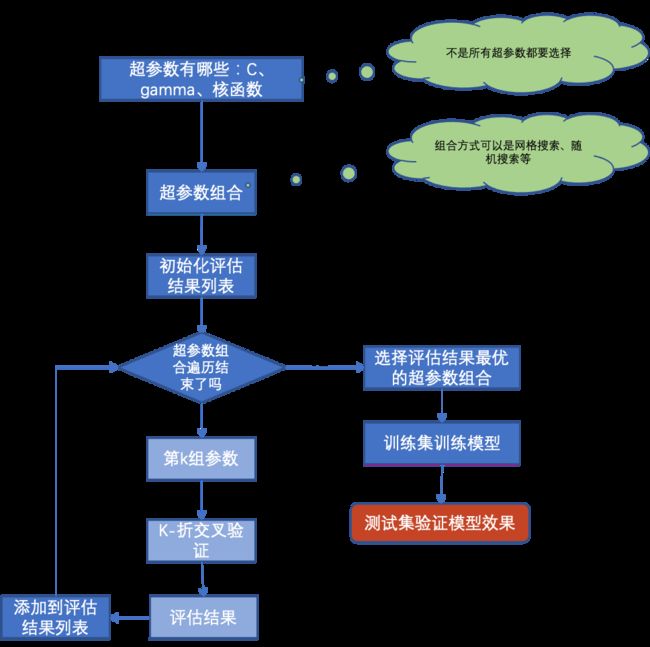
寻找最佳超参数有几种方法,常用的是网格搜索交叉验证GridSearchCV。
网格交叉验证就是任意参数要做两两组合。例如C=[1,10,100],gamma=[0.001,0.0001]。那网格交叉验证就可以得到6组超参数。每一组超参数交给交叉验证算法,评估模型效果。
最后选择模型效果最好的那一组参数作为最终模型的超参数。在训练集上训练得到模型作为最终的模型。
此外还有随机搜索交叉验证方法。他们只是组合超参数的方式不同。
2 模型优化
2.1 模型状态
模型的状态分为:过拟合、欠拟合、合适。
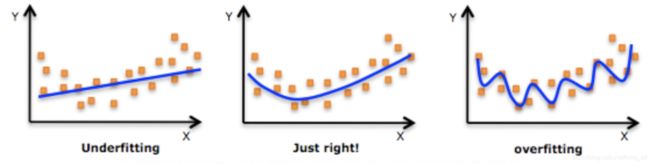
欠拟合是指模型学习能力弱,不能很好的表达数据。表现特征是在训练集准确率低,在测试集准确率低。
过拟合是指模型学习能力强,学习了噪音数据。表现特征是在训练集准确率高,在测试集准确率低。
训练集准确率随着样本量的增加而减小。原因是当样本量小的时候,模型不是学习而是记忆结果。所以随着样本量增加,训练集准确率降低。
测试集准确率随着样本量的增加而增加。原因是见到的样本多了,自然训练集数据越接近真实世界的数据,能够正确处理的数据也越来越多。
下图中的红线是一条标准线,是理想中想要找到的线。

在实际工作中,不会画这么麻烦的曲线,时间也不允许。会直接拿数据,看准确率。准确率都低,那基本就是欠拟合。训练集准确率高,测试集准确率低,过拟合。
2.2 模型优化1
如果发生过拟合:
1 采集更多的数据:增加数据会降低噪音数据的影响
2 增大正则化系数
如果发生欠拟合:
1 找更多的特征
2 减小正则化系数
2.3 模型优化2
如果是线性模型(线性回归、逻辑回归、线性SVM),可以分析特征系数。查看绝对值高的特征,看是不是可以做进一步细化,甚至可以做特征组合。
2.4 模型优化3
bad case分析
分析分错了的样本,归类错误原因。
分类问题:看是哪个特征的影响大,有没有共性
回归问题:哪些样本预测结果差距大,为什么?
2.5 模型优化4:模型融合
模型融合(model ensemble)
模型融合是一组独立的模型的组合。如果所有的模型都是同一种算法,称为base leaner。如果模型算法不同,就称为component leaner。
为什么这样是有效的呢?
从统计角度来讲,机器学习就是要找到一种从X到y的映射。这个真实的映射是什么谁都不知道。那如果有多个模型来预测学习的话,可能会更接近真实。
从计算角度来讲,很多优化函数是没有全局最优解,找到的是局部最优解。但是初始化参数不同,可能会落到不同的局部。有多个模型求平均,会接近最终想要的优化局部。
模型融合的方式有三种
1 bagging :群众的力量是伟大的,集体智慧是惊人的。
2 stacking:站在巨人的肩膀上能看得更远。
3 adboost:一万小时定律。
2.5.1 bagging
思路:很多时候模型效果不好是因为过拟合了。怎么解决?如果每次只给部分数据,多找几个模型来做一下,综合一下他们的答案。
过程:如果用同一个算法,每次取一个子集训练一个模型。如果是分类问题,将多个模型的结果做vote,如果是回归问题,将多个模型的结果做平均。如果用不同的算法,用全部数据集训练模型。如果是分类问题,将多个模型的结果做vote,如果是回归问题,将多个模型的结果做平均。
2.5.2 staking

stacking学习步骤分2步。将训练集分为两部分数据集D1和D2。D1和D2是没有交集的。
第一步,也就是level0,使用数据集D1,学习到多个模型。例如学习到LR、SVM、DT三种模型。
第二步,也就是level1,使用数据集D2和使用上一步的模型,学习到新的模型,作为最终的模型。这个模型如果是线性模型,那可以理解为是前面模型的线性组合。这个模型也可能是其他模型。
通常情况下stacking这个模型能力会非常强,所以第二层的模型一般使用线性模型,例如LR。
2.5.3 adaboost
思路:模型效果不好是因为不够努力,要重复迭代和训练。要多做之前的错题,每次分配给分错的样本更高的权重。用最简单的分类器叠加。
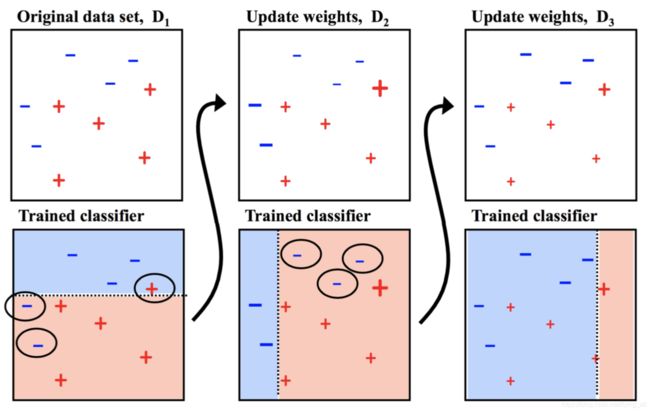

2.5.4 Gradient Boosting Tree
思路:从残差中学习
总结:模型融合有三种思路:bagging stacking boosting。
bagging的具体例子是:RandomForest
boosting的具体例子是:Adaboost,GDBT

bagging方式:VotingClassifier、BaggingClassifier、RandomForestClassifier
boosting方式:AdaBoostClassifier