【自监督论文阅读笔记】Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation
掩码图像建模(MIM)学习表示 具有非常好的微调性能,盖过了以前流行的预训练方法,如图像分类、实例对比学习 和 图像-文本对齐。在本文中,证明了这些预训练方法的较差微调性能 可以通过以 特征蒸馏(FD)形式的 简单后处理 来显著改善。特征蒸馏 将旧的表示 转换成新的表示,新的表示具有一些期望的属性,就像MIM产生的那些表示一样。这些属性,我们统称为 optimization friendliness 优化友好性,通过一组 注意力和优化相关的 诊断工具来识别和分析。有了这些属性,新的表示显示出强大的微调性能。
具体来说,对比自监督学习方法 在微调方面 与 最先进的掩码图像建模(MIM)算法 一样具有竞争力。CLIP模型的微调性能也得到了显著提高,CLIP ViT-L模型在ImageNet-1K分类上达到了89.0%的 top-1准确率。在30亿参数的Swin V2-G模型上,在ADE20K语义分割和COCO目标检测上,微调精度分别提高了+1.5 mIoU / +1.1 mAP到 61.4 mIoU / 64.2 mAP,在两个基准上都创造了新纪录。更重要的是,本文的工作为未来的研究提供了一种方式,将更多的努力集中在学习表示的通用性 和 可扩展性上,而不是预先考虑优化友好性,因为它可以很容易地增强。
代码:https://github.com/SwinTransformer/Feature-Distillation
预训练和微调的范式 在计算机视觉领域深度学习方法的发展中发挥了关键作用。2006年,基于自动编码器的预训练[19]是一项开创性工作,在很大程度上引发了深度学习的爆发。此外,自2012年AlexNet[25] 在ImageNet-1K图像分类[9]方面 取得革命性的识别精度以来,使用图像分类任务的模型预训练已成为各种下游计算机视觉任务的标准实践,包括目标检测[14]和语义分割[31]。
对于计算机视觉中的表征学习,两种著名的方法已经相当成功:实例对比学习[11,18,5,15,7,3] 和 图像文本对齐方法[34,22]。前者以自监督的方式学习表示,并在图像分类方面取得了令人印象深刻的线性评估性能[18,3]。后者以CLIP方法[34]为代表,以开拓 零样本识别领域 而著称,允许 视觉识别模型 对几乎任何类别进行分类。然而,当对下游视觉任务进行微调时,它们的性能通常并不优于其他方法[43、3、26、40],因此限制了它们的广泛采用。
最近,掩码图像建模(MIM) [4,1,45,17 MAE] 在微调评估[1,45,17]中 取得了显著的性能,并引起了广泛的关注。MIM的成功引出了一个问题:为什么MIM在微调方面表现得如此出色?换句话说,是否有一些关键因素可以加入到其他预训练方法中,使它们在微调方面像MIM一样成功?
特征蒸馏:
另外一种知识蒸馏思路是特征蒸馏方法,如下图所示。它不像Logits方法那样,Student只学习Teacher的Logits这种结果知识,而是学习Teacher网络结构中的中间层特征。最早采用这种模式的工作来自于论文《FITNETS:Hints for Thin Deep Nets》,它强迫Student某些中间层的网络响应,要去逼近Teacher对应的中间层的网络响应。这种情况下,Teacher中间特征层的响应,就是传递给Student的知识。在此之后,出了各种新方法,但是大致思路还是这个思路,本质是Teacher将特征级知识迁移给Student。

本文表明,简单的特征蒸馏方法 通常可以提高各种预训练方法的微调性能,包括基于对比的自监督学习方法,如DINO[3]和EsViT[26],视觉-语言模型,如CLIP[34],图像分类方法,如DeiT[37],如表1所示。在本文的特征蒸馏方法中,已经学习的表示 被蒸馏为 从头开始训练的新特征。对于蒸馏目标,本文提倡使用 特征映射 而不是logits,这使得FD方法能够 处理 通过任意预训练方法 获得的特征,并导致更好的微调精度。
本文还提出了有益于连续微调过程的有用设计,包括 whitened distillation targets 白化蒸馏目标、共享相对位置偏差 和 不对称滴径速率。有了这种方法和精心设计,基于对比的自监督预训练方法,如 DINO 和 EsViT,在微调评估中 变得与掩码图像建模方法一样具有竞争力,甚至稍好一些。CLIP预先训练的ViT-L模型 在ImageNet-1K图像分类上 达到了89.0%的 top-1准确率,这是ViT-L的最新最先进成果。在30亿参数的SwinV2-G模型上,在ADE20K语义分割和COCO目标检测上,微调精度分别提高了+1.5 mIoU/+1.1 mAP至61.4 mIoU/64.2 mAP,从而在两个基准上创建了新记录(见表2)。
本文使用一组 与 注意力 和 优化 相关的 诊断工具来 分析特征蒸馏前后的 模型属性。本文观察到 特征蒸馏 将旧的表示 转换成 新的表示,新的表示体现了一些期望的属性,就像MIM产生的那些表示一样。这些属性,本文统称为优化友好性,通过 注意力和优化相关的诊断工具 进行识别和分析,包括 平均注意力距离[10],平均注意力映射,heads之间的注意力相似性[55] 和 归一化损失景观(normalized loss landscape)[28]。
这些工具表明,蒸馏后的模型具有更多样的注意力头(attention heads),并且更多地考虑相对位置而不是绝对位置。这些都是我们期望的属性,有助于 在微调中获得更平坦的损失分布,以及更好的最终精度。注意,通过 掩码图像建模方法 学习的表示已经具有良好的优化友好属性,因此添加额外的特征蒸馏后处理 产生很少的收益。这样的结果表明,优化友好的表示是掩码图像建模方法的优越微调性能背后的原因。
本文的工作为未来的研究提供了一种方法,使我们可以更多地关注 学习到的表示的 通用性 和 可扩展性,而不是专注于优化友好性。通用性 和 可扩展性 是至关重要的,因为它们不仅 使预训练适合广泛的可视化任务,而且允许 训练过的网络 充分利用更大的模型容量和更大的数据。在现有的研究中,通用性 和 可扩展性的目标 常常 与优化友好性的目标 纠缠在一起。特性蒸馏方法 阐明了我们 如何能够将这两个目标分离开来,并允许更多的精力投入到通用性和可扩展性的关键问题上。
一种特征蒸馏方法:
对于一个已经预训练过的模型,本文的目标是获得一种新的表示,它从已经预训练的模型中提取知识,同时更易于微调。本文通过 特征蒸馏 方法实现这一点,如图1(左)所示。在这种方法中,预训练好的模型扮演老师,而新模型扮演学生。本文考虑以下设计,以使该方法 既通用 又有效。
提取特征图以使其通用:
不同于像大多数 先前的蒸馏工作那样 蒸馏logits[20],本文采用 预训练模型的输出特征图 作为蒸馏目标。使用特征图 作为蒸馏目标 允许我们 使用任何 可能没有logit输出的 预训练模型。除了更通用之外,提取特征图 还显示出 比使用logits 或 简化的单个特征向量 更高的微调精度(见表3)。
为了使教师和学生的特征图具有可比性,本文对每个原始图像采用相同的增强视图。本文还在学生网络上应用了1 × 1卷积层,以允许教师和学生之间 不同维度的输出特征图,从而可以进一步泛化该方法。

用于蒸馏的白化(Whitening)教师特征:
不同的预训练模型 可能 具有非常不同的特征量级,这将给不同预训练方法的超参数调整带来困难。为了解决这个问题,本文通过 白化操作 来 归一化教师网络的输出特征图,该白化操作 由没有缩放和偏差的 非参数的层归一化算子 实现。
在蒸馏中,本文在学生和教师特征图之间采用平滑ℓ1损失:

其中β默认设置为2.0;s 和 t 分别是 学生和教师网络的 输出特征向量;g是1 × 1卷积层。
共享相对位置偏差RPB:
在原始ViT [10]中,相对位置偏差(RPB) 与 绝对位置编码(APE) 相比没有任何优势,因此 绝对位置编码(APE)通常用于ViT架构[10,3,7,17]。
在特征蒸馏框架中,本文重新检查了学生架构中位置编码配置的影响,包括绝对位置编码(APE)和相对位置偏差(RPB) [30]。本文还考虑了 共享RPB配置,其中 所有层 共享相同的 相对位置偏差矩阵。本文发现 共享RPB的整体性能最好,如表5所示。本文发现,共享RPB可以分散头部的注意力距离,特别是对于更深的层(见图3和7),这可能导致其略好的微调精度。本文在实验中默认使用共享RPB。

非对称丢弃路径率 Asymmetric drop path rates:
特征提取框架中的两分支方式允许本文 对教师和学生网络 使用非对称正则化。本文发现,非对称的drop path [21]率的策略有利于学习更好的表征。具体来说,在ViT-B上,对学生分支应用0.1-0.3的丢弃路径率,而对教师分支不应用丢弃路径正则化的策略效果最佳,如表6所示。
(PS:drop path :若x为输入的张量,其通道为[B,C,H,W],那么drop_path的含义为在一个Batch_size中,随机有drop_prob的样本,不经过主干,而直接由分支进行恒等映射。)
特征蒸馏前后的表示:
在本节中,通过一组 与注意力和优化相关的 诊断工具,深入研究了上一节中介绍的特征蒸馏机制,包括 每个头部的平均注意力距离[10]、头部注意力图之间的平均余弦相似性[55]、每层的平均注意力图 以及 归一化损失情况[28]。本文使用 50000张ImageNet-1K验证图像 进行这些分析,并在应用蒸馏方法之前和之后诊断模型。在特征蒸馏前后,观察到学习表征的不同性质行为。
特征蒸馏使注意力多样化:
本文研究了 头部的注意力多样性。图2显示了 分别使用 DINO、DeiT 和 CLIP 预处理的 ViT-B架构的 每个头部的平均注意距离 和 层深度。[10]中引入了 average attention distance平均注意距离,它可以 部分反映 每个注意头的感受野大小,根据注意力权重计算。可以看出:对于蒸馏前的所有预训练的表征,深层不同头部的注意力距离 塌陷到 位于很小的距离范围内。这表明,不同的头部heads 学习非常相似的视觉线索,可能会浪费模型容量。在特征蒸馏过程之后,所有表示都会变得更加多样化 或 注意力距离分布更均匀,尤其是对于较深的层。图3也反映了这一观察结果,它计算了每一层注意力头之间的平均余弦相似性。


注意力模式的变化:
图4显示了特征蒸馏之前(左) 和 之后(右)的平均注意力图。在注意力映射图中有两种明显的模式:对角线 和 列。对角线模式 对应于某些固定的 相对位置的图像块之间的关系,而 列模式 表示某些绝对位置的图像块 对所有其他位置的影响。
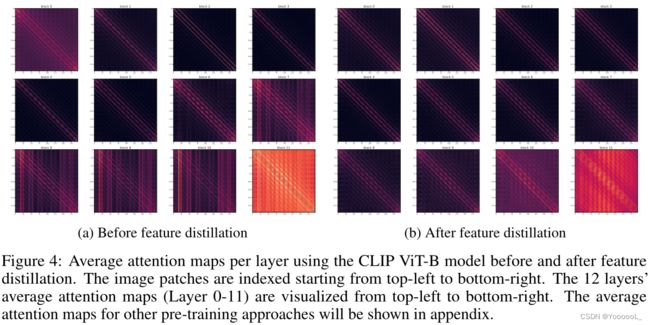
可以看出,特征蒸馏后的表示 具有更多的对角线模式,这意味着 模型 更多地依赖于 编码相对位置关系的 视觉线索。这表明模型具有更好的平移不变性,这通常是各种视觉任务的有益特性。注意到学生网络 包括 共享相对位置偏差(RPB),为了研究其影响,本文还尝试在学生架构中使用绝对位置编码(APE),其注意力分布图如图7所示。在这种配置中,特征蒸馏后的表示 也更依赖于相对位置,例如第0层和第7层,微调精度也相当高(见表5)。这表明 更多的对角线模式主要是由特征蒸馏算法本身引起的。
特征蒸馏获得更好的损失/准确性情况:
本文使用[28]中的方法来可视化不同模型的损失/精度情况。在这种可视化方法中,模型权重受到一系列不同程度的高斯噪声的干扰。根据[28],每个噪声水平被定义为归一化到每个滤波器的ℓ2范数,以考虑不同模型的不同权重幅度的影响。图5显示了不同预训练模型在特征蒸馏前后的损失/精度情况。事实证明,在特征蒸馏之后,大多数表示的损失/精度情况比蒸馏前的表示更平坦,这与它们更好的微调精度一致。

关于掩码图像建模(MIM):
图6显示了 基于MIM的方法MAE [17]在 特征蒸馏过程之前和之后的 平均注意力距离 和 损失/准确性情况。可以看出,使用MAE预训练的表示已经学习了不同的头部,并且损失/准确性曲线相对平坦。事实上,通过特征蒸馏方法将 旧的MAE表示 额外转换为新的表示 只会带来+0.2%的微小增益(83.8%对83.6%)。这些结果可能表明,特征蒸馏后处理带来的良好微调性能 与 掩码图像建模(MIM)方法在功能上有一定的重叠。

Experiments:
蒸馏实现和数据集:
对于所有的实验,本文使用1.28M ImageNet-1K训练图像进行特征蒸馏。在消融中,本文为所有的实验 蒸馏100个epochs 。在如表1所示的系统级比较中,本文采用300个周期的训练。使用了AdamW优化器[24]。学习率、重量衰减 和 批大小分别默认设置为1.2e-3、0.05和2048。对于丢弃路径率,本文选择{0.1,0.2,0.3,0.4}中的最佳值。
本文考虑了 DINO[3]、EsViT[26]、CLIP[34]、DeiT[36]和MAE[17] 的5种预训练方法,使用它们的公开checkpoints 。对于DINO, EsViT和DeiT,本文使用它们最大的可用模型,ViT-B 或 Swin-B。CLIP方法本文尝试了 ViT-B 和 ViT-L两种方法。
Evaluation settings:
本文考虑了3个评估基准:ImageNet-1K微调、ImageNet1K线性探测 和 ADE20K语义分割。
ImageNet-1K微调:
本文遵循[1]使用AdamW优化器[24]层衰减学习速率。对于ViT-B,本文将其微调100个epoch,本文的默认超参数是:批大小2048,学习率5e-3,重量衰减0.05,层衰减0.65,丢弃路径率0.3。对于ViT-L,本文对其进行了50个epoch的微调,默认的超参数是:批大小为2048,学习率为1e-3,层衰减为0.75,下降路径率为0.4。
ImageNet-1K线性探测:
本文遵循[17]使用LARS优化器[48],其基本学习率为0.1,权值衰减为0。对于ViT-B,本文训练90个周期。对于ViT-L,本文训练50个周期。
ADE20K语义分割:
本文按照[30]使用一个UPerNet框架[42]进行实验。采用AdamW[24]优化器,训练长度160K,批次大小为16,权值衰减为0.05。对于ViT-B,其他超参数设置为:学习率4e-4,层衰减0.65,丢弃路径率0.2。对于ViT-L,其他超参数设置为:学习率1e-4,层衰减0.75,丢弃路径率0.4。训练时,输入图像大小为512 × 512。在推断中,本文遵循[30]的单尺度测试。
Main Results:
表1显示了主要结果。使用特征蒸馏方法,所有列出的预训练模型在ImageNet-1K微调上提高了1.0% ~ 2.0%,在ADE20K语义分割上提高了1.0 ~ 3.3 mIoU。特别是,通过这种方法,本文改进了CLIP ViT-L模型,使其在ImageNet-1K分类上达到89.0%,这比专用于CLIP模型[40]的复杂微调方法高出1.9%。
本文还改进了30亿参数的SwinV2-G,使其在ADE20K语义分割和COCO目标检测上实现61.4 mIoU 和 64.2 mAP(使用与原始SwinV2论文[29]相同的UperNet / HTC++框架和相同的评估设置),创建了新的记录,分别比(Mask) DINO[51,27]中报道的现有技术高+0.6 mIoU和+0.9 mAP,如表2所示。
这些结果表明本文的方法具有普遍的适用性。
Ablations :
在本节中,将消融第2节中描述的设计。所有实验均在ImageNet-1K训练图像上进行,使用ViT-B和100 epoch的训练。
关于蒸馏目标:
表3消融了不同蒸馏目标的影响。在所有预训练方法中,使用全特征图的效果最好。与使用其他简化特征相比,对完整特征图的蒸馏可以 保持教师模型中涉及的更多信息,这可能会导致其更好的性能。本文还在DeiT预训练模型上用经典的logit蒸馏方法进行了实验。结果表明,与原始表示相比,logit蒸馏只有+0.1%的改进。此外,对于不依赖分类的预训练模型,logit 蒸馏方法也不适用。
教师特征归一化的效果:
表4消融了是否和如何 进行 教师特征图归一化的影响。对于CLIP、DINO和DeiT,白化教师特征映射 比 使用原始特征映射 分别带来+0.8%、+0.2%和+1.0%的改进。比较ℓ2和白化 两种归一化方法,白化方法的性能明显更好(CLIP、DINO和DeiT分别为+0.4%、+0.0%和+1.1%)。使用特征映射归一化还使超参数对预训练模型不敏感。
关于位置编码配置:
表5消融了不同的位置编码配置对学生网络的影响。共享相对位置偏差(RPB)配置总体上表现最好。图4和图7显示了共享RPB配置具有最多样化的注意头,这可能会产生最佳的准确性。还要注意,所有这些配置都执行得相当好,这表明成功的主要因素不是来自合适的位置编码配置,而是来自特征蒸馏算法本身。
关于非对称丢弃路径率:
表6消融了不同程度丢弃路径正则化的影响。适度增加学生网络的丢弃路径率是有益的,可能是由于过拟合的缓解。CLIP、DINO和DeiT的最优学生丢弃路径率分别为0.1、0.2和0.2。对于教师网络,添加丢弃路径正则化通常会降低性能,这表明一个准确的教师信号是有益的。因此,本文默认采用这种不对称的丢弃路径率策略。
Discussion in the Context of Related Works:
表示学习是计算机视觉的一个主要主题。在本节中,将讨论它的目标、评价、属性要求、现有方法,以及基于本文发现的一些思考。
表征学习的目标与评价:
表示学习的目标和常用评价包括:
• 微调目的。先前的工作[19] 发现 逐层贪婪学习的模型权值 可以为最终与所有层联合学习起到很好的初始化作用,这实际上引发了深度学习在2006年的复兴。自2012年以来,使用表示学习进行调优已经成为更实际的标准,通常使用 从ImageNet-1K图像分类任务 训练的模型权重 进行初始化是将深度学习推广到广泛的视觉任务中的关键因素[14,31]。这种用法是如此重要,因此在这个方向上的坚实改进通常可以引起显著的注意,最近的掩码图像建模方法就是如此[1,17,45]。
• 线性评估:
早期的自监督学习方法[11,33,18]通常使用该协议进行评估,该协议固定视觉骨干,在固定骨干之上学习线性分类器。该协议主要反映了学习到的特征的线性可分性。由于它不是直接针对现实场景,所以它不像过去那样受欢迎。
• Few-shot 少样本场景:
人类非常擅长少样本学习。少样本学习也有很多应用,可以帮助我们用有限的数据快速构建新功能。实例对比学习 和 视觉-文本对比学习 等自监督方法已被证明对少样本学习效果良好[41,6,34]。
• Zero-shot / prompt-aided inference 零样本/提示辅助推断:
表征学习的另一个用途是 零样本推理 或 提示辅助推理。这允许使用 预训练的模型,而无需对下游数据进行额外的训练[34,16,46]。这种表示学习的使用使得 单一模型 能够 处理 所有的任务成为可能,它现在正受到越来越多的社会关注。
本文主要研究表示学习的微调应用。本文将讨论:
什么是适合微调的好属性?
很少有研究试图研究哪些属性适合微调。在本讨论中,将把潜在的好属性分为:
• 优化友好:
预训练模型用作微调任务的初始化。良好的初始化可以帮助微调中的优化过程。给定微调中的相同优化器,更好的初始化 可能会导致 更平坦的损失情况 和 更好的准确性[28]。
• 可扩展 和 可泛化知识的编码:
预训练模型应该编码能够很好地完成预训练任务的知识。预训练模型中编码的知识通常有利于下游任务,例如,CLIP模型中编码的语义被证明对下游任务有显著帮助,如ImageNet-1K分类和ADE20K分割任务。
另一个很好的属性是 编码知识的可扩展性:当我们有更大的数据时,模型能很好地编码更丰富的知识吗? 学习任务能很好地驱动较大的模型吗? 这通常是在比例定律 scaling law[23]的背景下讨论的,这已成为最近自然语言模型取得显著成功背后的一个角落信念。本文希望这也适用于计算机视觉。
正如本文所分析的那样,本文介绍的特征蒸馏方法主要提高了优化的友好性。我们希望它为表示学习的研究提供一种方法,将更多的精力集中在第二个良好的泛化性和可扩展性上。在下文中,将对现有的表示学习方法进行一些反思,因为已经存在诸如 特征蒸馏 等通用方法来提高优化友好性。
现有的表征学习方法和本文的思考:
有四种著名的表示学习方法,包括 ImageNet-1K [9] 上的图像分类 [25]、实例对比学习 [11、18]、视觉文本对比学习 [34、22] 和 掩码图像建模 [1、45 , 17]。本文对这些方法进行了以下思考:
• 掩码图像建模(MIM):
掩码图像建模因其在微调评估方面的卓越表现而备受关注。正如本文所建议的,出色的性能可能主要来自学习到的表示的优化友好性。就其可扩展性而言,MIM 任务训练大容量模型的能力已在 [17, 45, 29] 中得到很好的证明,然而,从大数据中受益的能力目前听起来是消极的,如 [12] 所示。本文认为,如果这个问题没有得到很好的解决,可能会阻碍其进一步普及。
• 实例对比学习:
实例对比学习方法以自监督的方式进行预训练,由于它在多个下游任务上超越了监督分类方法[18],因此引起了很多关注。此外,它使用 线性和少样本评估 实现了令人印象深刻的准确性[6]。然而,当涉及到视觉 Transformer 主干 [10, 30] 时,微调性能变得不如其他 [43, 26],这可能暂时阻碍了它的吸引力。
另一个问题是它 对 模型容量 和 数据大小 的可扩展性 很少被研究,或者仅在线性评估设置中执行[35]。因此,它在可扩展性属性上的实际行为尚不清楚。本文希望本文对其微调性能的重大改进将鼓励社区重振对这种方法的研究。看到一项关于其对模型容量和数据大小的可扩展性的可靠研究将会很有趣。
• 图像分类 和 视觉文本对比学习:
自 AlexNet [25] 以来,近十年来,图像分类一直是标准的上游预训练任务。视觉文本对齐任务开辟了零样本识别领域。本文现在在一项中讨论它们,因为它们基本上可以用相同的目标来表述 [39, 47],并且它们具有一些相似的特性。
本文首先检查现有的关于其模型容量和数据大小的可扩展性的研究。事实上,这两个任务都被证明可以执行可扩展的 [50, 29, 34, 22, 34, 22]。
一般来说,视觉文本任务的数据更容易获得,因此对需要大量数据的大型模型训练更友好。此外,在本文的特征蒸馏方法的帮助下,微调性能也被证明能够显著提高,这将进一步使这项预训练任务更具吸引力。在这些考虑中,这项任务将是大规模表示学习的一个不错的选择。看看它是否可以与其他表示学习方法相结合以 提高其数据挖掘效率 也将很有趣。
还有许多其他表示学习方法,例如:灰度图像着色 [53]、拼图求解 [32]、split-brain裂脑自动编码 [54]、旋转预测 [13]、学习聚类 [2] 或 以一个或两个其他通道作为输入来预测某些通道的值 [53, 54] 和 像素级对比 [44, 38]。在本文的特征蒸馏方法的背景下,其中一些可能值得重新检查。
Conclusion:
本文介绍了一种简单的特征蒸馏方法,可以普遍提高 许多视觉预训练模型的 微调性能。它使基于对比的自监督学习方法在微调方面与最先进的掩码图像建模 (MIM) 一样具有竞争力。它还改进了 CLIP 预训练的 ViT-L 模型,使其在 ImageNet-1K 分类上的 top-1 准确率达到 89.0%。虽然本文通过一组注意力和优化相关的诊断工具进行的分析表明,本文的特征蒸馏方法主要提高了学习表示的优化友好性,但本文希望这些发现可以为未来的研究提供一种方法,将更多的精力放在学习到的表示的泛化性和可扩展性。