深度学习和tensorflow学习总结---复习自用,大家看到不对的地方多多留言,互相交流
深度学习(DeepLearing)
-
深度学习不需要人工提取特征-----模型的可解释性
-
与机器学习区别:
- 机器学习需要手动提取特征,需要大量领域专业知识。
- 深度学习,通过训练大量数据自动得出模型,不需要人工提取特征环节。
- 适合图像、语音、自然语言处理领域
-
应用场景:
- 物体识别
- 场景识别
- 人脸识别
- 人脸身份认证
- 自然语言处理
- 文本识别
- 语音识别
-
加法运算:
-
定义常量:tf.constant(常量值)
-
定义变量:tf.Variable(initial_value= ,trainable= )
-
initial_value:初始值
-
trainable:是否被训练
-
变量需要显示初始化,才能运行值
-
a = tf.Variable(tf.random_normal([2, 2], mean=0.0, stddev=1.0), name="a", trainable=True) # 添加一个初始化变量的OP init_op = tf.global_variables_initializer() with tf.Session() as sess: # 运行初始化变量的OP sess.run(init_op) print(sess.run(a))
-
-
-
定义占位符: tf.placeholder(detype=, shape=[None, 列数])
行数None表示数据的数量,列数表示特征数量。
-
加法运算:tf.add(tensor_a, tensor_b) # 张量a和张量b相加
-
-
tensorflow程序:两部分
- 构建图阶段:数据与操作的执行步骤被描述成一个图
- 执行图阶段:使用会话执行构建好的图中的操作
-
图:将计算表示为指令间依赖关系的一种表示法
- 默认图:不需要定义
- 程序中张量 、op操作、sess.graph都处在一个图里。
- 获取默认图:tf.get_default_graph()
- 自定义新图:tf.Graph()
- tf.Graph(),如果要在这张图中创建OP,典型用法是使用tf.Graph.as_default()上下文管理器
- 有一个新内存地址
- 会话中需要传入新图,如果不传,只在默认图中找。
- 默认图:不需要定义
-
会话:跨一个或者多个本地或远程设备运行数据流图的机制。
-
with tf.Session() as sess:
pass
-
-
可视化:两步
- 1 写入序列化文件
- tf.summary.FileWriter(logdir, graph=sess.graph)
- 2 启动Tensorboard
- tensorboard --logdir=’./graph_demo/’
- 直接把网址复制粘贴
- 127.0.0.1:6006 也可以打开
- 1 写入序列化文件
-
命名:定义 常量,变量,直接指定name=‘aaa’
- a = tf.constant(3.0, name=“a”)
-
占位符:
- tf.placeholder(detype=, shape=)
- 要和feed_dict() 配合使用
- 可以根据传入的数据而改变,具有变量的特性
- 占位——shape=[m,n] 传入的数据必须要匹配形状。
-
会话
- 开启会话:
- tf.Session(): 用于完整的程序中
- tf.InteractiveSession: 用于交互式上下文中的TensorFlow,例如shell。
- 这时候,使用tensor.eval() 和Opration.run()代替Session.run()
- tensor.eval() 取张量的值
- 开启会话:
-
张量
- 属性
- dtype 张量的类型
- shape 形状(阶)
- 创建随机张量
- tf.random_normal() 产生正态分布的值
- mean 平均数 stddev 标准差
- tf.truncated_normal() 产生正态分布值,截取2个标准差范围,95%
- tf.random_normal() 产生正态分布的值
- 一般张量
- tf.zeros() 所有元素为0的张量
- tf.ones() 所有元素为1的张量
- tf.constant(value, shape)
- 张量的阶
- 0阶–一个数字
- 1阶–一维向量
- 2阶–矩阵
- 张量的变化
- 类型改变
- tf.cast(tensor, detype=)
- 形状改变
- tf.set_shape() 不能跨阶,只能改变一次
- tf.reshape() 元素个数相等即可改变
- 类型改变
- 属性
-
变量OP
-
创建变量:tf.Variable(initial_value= ,trainable= )
-
initial_value:初始值
-
trainable:是否被训练
-
重点 *** 变量需要显示初始化,才能运行值
-
a = tf.Variable(tf.random_normal([2, 2], mean=0.0, stddev=1.0), name="a", trainable=True) # 添加一个初始化变量的OP init_op = tf.global_variables_initializer() # 必须写 with tf.Session() as sess: # 运行初始化变量的OP sess.run(init_op) # 必须写 print(sess.run(a))
-
-
tensor.assign() 赋值功能
- 赋值后,前面的tensor也被赋值了
-
tensor.assign_add() 加法+赋值
- 赋值后,前面的tensor也被赋值了
-
命名空间
- tf.variable_scope(‘space_name’):
- 作用:添加一个空间名,结构清晰,隔离变量,方便可视化
- 共享变量
- 添加resue=tf.AUTO_RESUE,相同名字的变量,可以共存了
- tf.variable_scope(‘space_name’):
-
-
-
辅助功能:
-
保存模型,加载模型
-
saver = tf.train.Saver()
-
保存模型(在for循环中—需要保存最新的参数,所以要在循环中)
- saver.save(sess,dir) 注:dir表示路径
-
加载模型(在会话中,for循环之前),加载模型之前判断checkpoint是否存在
-
if os.path.exists(’./xianxing_save/checkpoint’):
saver.restore(sess, ‘./xianxing_save/’)
-
-
-
可视化:
-
收集变量 :
-
tf.summary.scalar(name=’’, tensor)
- 收集 单值变量(损失函数 准确率)
- name 变量名字 tensor 值
-
tf.summary.histogram(name=’’, tensor)
- 收集高维度的变量参数
-
tf.summary.image(name=’’, tensor)
- 收集输入的图片张量 能显示图片
-
合并:tf.summary.merge_all()
-
添加—在tf.Session里面写
- FileWriter.addz_summary(logdir="./summary", graph=sess.graph)
-
在模型训练的for循环中 summary = sess.run(merge) file_writer.add_summary(summary, i)
-
-
-
线性回归
- 首先拿到数据集(一定要有标签)
- 已有的数据集
- 创造的数据集
- 确定模型的损失函数
- 平方差损失 tf.square(), tf.reduce_mean()
- 确定训练算法
- 梯度下降法
- 训练起来
- sess.run()
- 打印训练中的信息,画图
- 用到的函数:
- tf.matmul(x, w) 矩阵运算
- tf.square() 平方
- tf.reduce_mean() 均值
- tf.train.GradientDescentOptimizer(learning_rate) 梯度下降优化
- learning_rate 学习率 一般为0-0.01
- minimizer(loss) 使loss最低
- 首先拿到数据集(一定要有标签)
神经网络(NN)
-
文件读取流程
-
第一步:构造文件队列名
- tf.train.string_input_producer(sring_tensor, shuffle=True)
- sring_tensor 含有文件名+路径的1阶张量
- num_epoches 过几遍数据 默认无限数据
- return 文件队列
- tf.train.string_input_producer(sring_tensor, shuffle=True)
-
第二步:读取和解码
-
阅读器默认每次只读取一个样本:文本文件默认一次读取一行 图片文件默认一次读取一张图片 二进制文件一次读取指定字节数(最好是一个样本的字节数) TFRecords默认一次读取一个exampl
-
tf.TextLineReader() 阅读文本文件逗号分割值(scv)格式,默认按行读取
-
tf.WholeFileReader() 用于读取图片文件
-
例子
-
reader = tf.TextLineReader() key, value = reader.read(file_queue)
-
-
-
tf.FixedLengthRecordReader(record_bytes) 读取二进制文件
- record_bytes 整型,指定每次读取的字节数
-
tf.TFRecordReader() 读取TFRecords文件
-
解码
-
tf.decode_csv() 解码文本文件内容
-
tf.image.decode_jpeg(contents)
- 将JPEG编码的图像解码为uint8张量
- return: uint8张量 3d 形状 [height, width, channels]
-
tf.image.decode_png(contents)
- 将PNG编码的图像解码为uint8张量
- return: uint8张量 3d 形状 [height, width, channels]
-
tf.decode_raw() 解码二进制文件内容
- 与tf.FixedLengthRecordReader搭配使用,二进制读取为uint8类型
-
解码阶段,默认所有内容都解码为tf.uint8类型,之后可用tf.cast() 转换为其他类型
-
-
第三步:批处理
- tf.train.batch(tensors,batch_size, num_threads=1,capacity=32, name=None)
- 读取指定大小(个数)的张量
- tensors 可以是包含张量的列表 批处理的内容放到列表中
- batch_size 从队列中读取的批处理大小
- num_threads 进入队列的线程数
- capacity 整数,队列中元素的最大数量
- return: tensors
- tf.train.batch(tensors,batch_size, num_threads=1,capacity=32, name=None)
-
-
多线程运行
-
tf.train.Coordinator() 创建线程协调器
- 线程协调员,对线程进行管理和协调
- request_stop() 请求停止
- should_stop() 询问是否结束
- join(threads=None, stop_grace_period_secs=120) 回收线程
-
tf.train.start_queue_runners(sess=None, coord=None) 开启子线程读取数据
- 收集图中所有的队列线程,默认同时启动线程
- sess 所在会话
- coord 线程协调器
- return 返回所有线程
-
实例:
-
coord = tf.train.Coordinator() # 创建线程协调器 threads = tf.train_squeue_runners(sess=sess, coord=coord) # 开启子线程去读取数据 # 获取数据样本去训练 coord.request_stop() # 关闭子线程 coord.join(threads) # 回收
-
-
-
图片数据读取
-
基础知识
-
- 图片三要素:高 宽 通道数
- 张量形状
- 单张图片 [height, width, channel]
- 多张图片 [batch, height, width, channel]
- tensorflow默认的图片张量顺序是HWC,即[height, width, channel],所以图片处理时,的都要转化成这个顺序
- 改变图片特征:
- tf.image.resize_images(images,size) 注意,参数只能传2维
- images: 4-D 形状 [batch, height, width, channels] 或3-D形状的张量[height, width, channels] 的图片数据
- size: 1-D int32张量 [new_height, new_width] 图像新尺寸
- 返回4D格式 或3D格式 图片
- tf.image.resize_images(images,size) 注意,参数只能传2维
- 改变数据格式:
- tf.cast(tensor,tf.float32)
-
流程
-
构造文件名队列
file_queue = tf.train.sting_input_producer(file_list)
-
构造一个图片读取器,读取队列中的数据
reader = tf.WholeFileReader()
key, value = reader.read(file_queue)
-
解码
- image = tf.image.decode_jpeg(value)
-
调整图片大小
-
统一尺寸,size = [height, width], size 只能传2个参数,不能传channel:
re_image = tf.image.resize_images(image, [200, 200])
-
调整张量形状到tensorflow默认形状:
re_image.set_shape([200, 200, 3])
-
-
批处理
image_batch = tf.train.batch([re_image], batch_size=10, num_threads=1, capacity=32)
-
-
-
二进制文件读取(和图片读取有个对比)
-
基础知识
-
tf.FixedLengthRecodReader(length) 注意长度参数
-
解析数据:tf.decode_raw(value, tf.unit8)
-
切片:tf.slice(tensor, [start], [number])
- start:起始下标 number:切片数据的个数
-
tf.transpose(tensor, [a, b, c])
- tensor:数据 a,b,c:是待处理的下标
-
流程
-
构造文件队列名
file_queue = tf.train.string_input_producer(file_list)
-
构造读取器,读取队列数据
reader = tf.FixdLengthRecordReader(self.total_length)
key, value = reader.read(file_queue)
-
解码
decode_value = tf.decode_raw(value, tf.uint8)
-
解析数据
lable = tf.slice(decode_value, [0], [self.lable_length])
image = tf.slice(decode_value, [self.lable_length], [self.image_length])
label = tf.cast(lable, tf.int32)
-
形状转换
re_image = tf.reshape(image, [self.channel, self.height, self.width])
re_image = tf.transpose(re_image, [1, 2, 0])
-
批处理
label_batch, image_batch = tf.train.batch([lable, re_image], batch_size=20, num_threads=1, capacity=32)
-
-
-
TFRecords 文件写入与读取
-
基础知识
-
TFRecords是一种二进制文件,结构类似于字典嵌套,能更好的利用内存,不需要单独的标签文件
-
分为两部分:
构建协议(写入),协议解析(读取)
-
结构如下

-
tf.train.Example协议内存块(protocol buffer)(协议内存块包含了字段Features) -
Features包含了一个Feature字段 -
Feature中包含要写入的数据、并指明数据类型。
- 这是一个样本的结构,批数据需要循环存入这样的结构
example = tf.train.Example(features=tf.train.Features(feature={ "image": tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])), "label": tf.train.Feature(int64_list=tf.train.Int64List(value=[label])), }))
-
-
API
-
tf.train.Example(features=None)
写入tfrecords文件
features: tf.train.Features类型的特征实例
return:example格式协议块
-
tf.train.Features(Feature=None)
构建每个样本的信息键值对
feature: 字典数据,key为要保存的名字,value为tf.train.Feature实例
return:Features类型
-
tf.train.Feature(options)
options:例如
bytes_list = train.BytesList(value=[Bytes])
int64_list = tf.train.Int64List(value=[Value])
支持存入的类型如下:
tf.train.Int64List(value=[Value])
tf.train.BytesList(value=[Value])
tf.train.FloatList(value=[Value])
-
构造存储实例:
tf.python_io.TFRecordWriter(path)
写入tfrecords文件
path:TFRecords文件路径
return:写文件
方法(method)
write(record):向文件中写入一个example
close():关闭文件写入器
-
-
-
流程
-
TFRecords文件写入
-
构造tfrecords存储实例
with tf.python_io.TFRecordWriter(’./cifar.tfrecords’) as writer:
-
循环将每个样本写入到文件中
#构造tfrecords存储实例 with tf.python_io.TFRecordWriter('./cifar.tfrecords') as writer: #循环将每个样本写入到文件中 for i in range(10): # 准备特征值,特征值必须是bytes类型 调用tostring()函数 label_i = label[i].eval()[0] image_i = image[i].eval().tostring() # 构造协议块 example = tf.train.Example(features=tf.train.Features(feature={ 'image':tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_i])), 'label':tf.train.Feature(int64_list=tf.train.Int64List(value=[label_i])), })) # 写入文件中 writer.write(example.SerializerToString())
-
-
TFRecords文件读取
-
创建文件队列
file_queue = tf.train.string_input_producer([’./cifar.tfrecords’])
-
创建读取器,读取队列内容
reader = tf.TFRecordReader()
key, value = reader.read(file_queue)
-
解析协议
feature = tf.parse_single_example(value, features={
“image”: tf.FixedLenFeature([], tf.string),
“label”:tf.FixedLenFeature([], tf.int64),
})
label = feature[‘label’]
image = feature[‘image’]
-
解码
decode_image = tf.dacode_raw(image, tf.uint8)
-
调整图片大小
re_image = tf.reshape(decode_image, [self.heigth, self.width, self.channel])
-
改变数据类型
label_cast = tf.cast(label, tf.float32)
image_cast = tf.cast(re_image, tf.float32)
-
批处理
label_batch, image_batch = tf.train.batch([label_cast, image_cast], batch_size=10, num_threads=1, capacity=32)
-
-
-
-
神经网络基础
-
人工神经网络 (Artificial Neural Network)ANN 简称 神经网络(NN)
-
结构:输入层 隐藏层 输出层
-
特点:
- 每个连接都有个权值,
- 同一层神经网络之间没有连接
- 最后的输出结果对应的层称之为全连接层
-
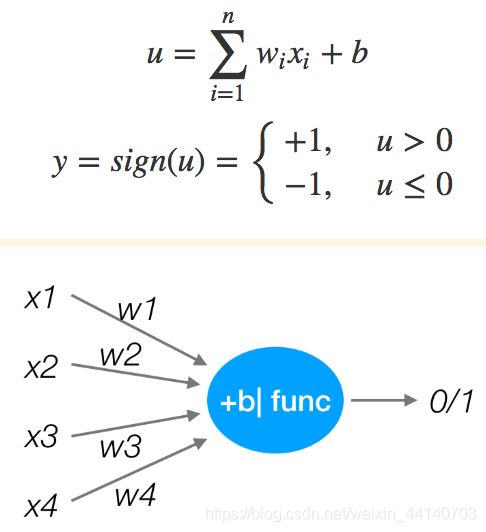
感知机:(PLA:Perceptron Learning Algprithm)
- 模拟大脑神经网络处理数据的过程。
- 最基础的分类模型,类似于逻辑回归,感知机激活函数是sign,而逻辑回归激活函数是sigmoid
-
-
softmax回归
- 作用:将神经网络输出转换成概率结果

-
交叉熵损失
- 目标值(真实值)用one-hot编码,能与概率值一一对应
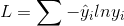
- y^是真实值,由于是one-hot编码,真实值只能是0或者1
- y 是softmax算出的值
- i是输出节点的编号
- 损失函数大小:对所有样本的损失求和,取平均值
-
softmax、交叉熵损失API
- tf.nn.softmax_cross_entropy_with_logits(labels=None,logits=None,name=None)
- 计算交叉熵损失
- labels 标签值(真实值)
- logits 样本加权之后的值
- return 返回损失值列表
- tf.nn.softmax_cross_entropy_with_logits(labels=None,logits=None,name=None)
-
tf.reduce_mean(input_tensor)
- 计算张量的平均值
-
线性神经网络的局限性
- 表达能力有限—需要添加非线性因素–激活函数
-
神经网络的黑盒性质
- 深度和神经元个数没有精确值
- 结果没有可解释性
-
改善网络的基本套路
- 更深的网络
- 更多的神经元
- 加入非线性因素添加激活函数
-
谷歌的Inception 谷歌的图像识别模型
- Inception-v2, v3, v4
- 谷歌公开的通用图像识别模型
- 继承谷歌已非常完美的网络
- Inception-v2, v3, v4
-
DNN 深度神经网络
-
tensorflow.examples.tutorials.mnist.input_data() 获取Mnist数据
-
tf.matmul(a,b,name=None) 实现全连接层计算
-
tf.train.GrandientDescentOptimizer(learning_rate).minimize(loss) 实现梯度下降优化
-
卷积神经网络(CNN)
-
区别:在原来多层网络的基础上加入了更加有效的特征学习部分,具体操作是在原来的全连接层前加入了卷积层与池化层
-
结构:
- 输入层
- 隐藏层:
- 卷积层:提取原始特征(通过平移)
- 激活层:增加非线性因素
- 池化层:减少学习参数,降低学习复杂度(最大池化和平均池化)
- 全连接层(输出层):进行损失计算并输出结果
-
卷积层的4要素
- 卷积核的个数
- 卷积核的大小 1*1 3*3 5*5
- 卷积核的步长
- 卷积核的零填充 padding
-
卷积的运算:不是矩阵运算,一对一点乘
- tf.nn.conv2d(input, filter, strides=, padding=)
- 作用:计算input数据和filter张量的卷积
- input 输入的张量,维度[batch,heigth,width,channel]
- filter:指定过滤器(卷积核)的权重数量 [filter_height, filter_width, in_channels, out_channels]
- strides:步长 [1, stride, stride, 1]
- padding:“SAME” 零填充
- tf.nn.conv2d(input, filter, strides=, padding=)
-
激活函数—添加非线性因素
- Relu: Relu = max(0,x) 小于0 取0,大于零 取原值
- 优点
- 解决梯度爆炸问题,
- 计算速度快
- API
- tf.nn.relu(features, name=None)
- features: 上一步的结果
- return: 结果
- tf.nn.relu(features, name=None)
- 优点
- Relu: Relu = max(0,x) 小于0 取0,大于零 取原值
-
池化层(Polling)—过滤不重要特征,减少参数数量。
- 一般是2*2
- 取最大值(-----常用)或平均值
- API:tf.max_pool(value,ksize=,strides=,padding=,name=None)
- value:上一层传入数据的形状 [batch, height, width, channels]
- channel:filter个数
- ksize:池化窗口大小 [1, ksize, ksize, 1] 前后的1表示对原始图片的宽、高不做处理
- strides:步长 [1,strides,strides,1] 前后的1表示对卷积核和通道数不做处理
- padding:“SAME”, “VALID”,使用的填充算法的类型,默认使用“SAME”
-
代码实现:
-
强调:y_predict 是从神经网络计算出来的
-
网络优化:
-
更好的算法:AdamOptimizer()
-
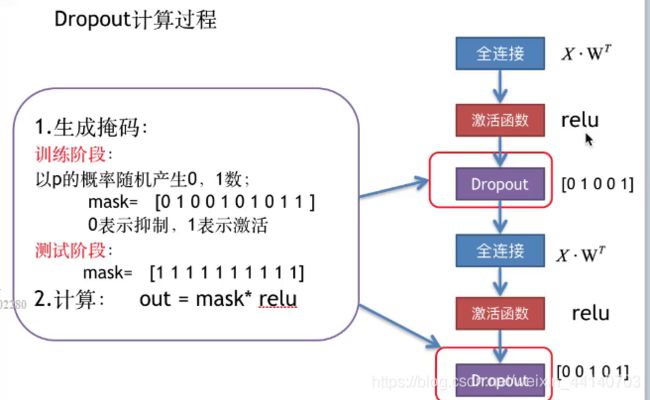
批量归一化 Batch Normalization 简称BN
使用方法:
-
导入:from tensorflow.contrib.layers.python.layers import batch_norm
-
x_bn1 = batch_norm(x_pool1,decay =0.9, updates_collections=None, is_training = True)
-
原理:
-
-
初始化参数的时候,更小的 stddev=0.001 b的初始值可以是固定值
-
应用 Dropout() keep_prob=0.5
-
每次只有0.5的概率连接权重有效
-
作用是防止或者减轻过拟合
-
train的时候才是dropout起作用的时候,train和test的时候不应该让dropout起作用
-
代码:
y_output = tf.nn.dropout(y_predict, keep_prob=0.5)
-
-
在GPU运行:
with tf.device('/gpu'): # 设置在GPU上跑,所有代码写在with下面 with tf.Session(config=tf.ConfigProto(allow_soft_placement=True)) as sess: # tf.Session()中添加config=tf.ConfigProto(allow_soft_placement=True),当运行在出现不允许在GPU运行的时候,可以切换到CPU运行 -
-
-
验证码的识别思路
- 处理标签文件
- 将字母数字化,并且one-hot
- 处理图片文件
- 流程和手写数字一样
- 构建队列文件
- 读取文件并解码 + 调整张量大小
- 批处理
- 流程和手写数字一样
- 定义一个映射函数
- 找到批处理的图片和标签的对应关系
- 网络的构建
- 定义运算图 + 开启会话 + 训练 + 测试
- tf.train.parse_single_example()
- TFRecords文件的读取,和写入example模块对应
- 处理标签文件
-
知识点
-
此处目标值有多个标签,属于多分类问题,使用sigmoid交叉熵:
- sigmoid交叉熵适合计算每个类别独立且不互相排斥的离散分类任务中的损失值,适用于多分类。
- sotfmax交叉熵适合于计算类别相互排斥的离散分类任务的损失值,每个输出对应一个类别,适用于单分类,softmaxz交叉熵损失在迭代过程中,会使概率最大的值概率更大,其他值概率减小,不适合多分类。
-
sigmoid交叉熵损失函数
-
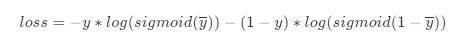
-
y为标签值,y—为输入sigmoid之前的logits值(预测值)
-
tf.nn.sigmoid_cross_entropy_with_logits(labels=None,logits=None,name=None)
labels:真实值,one-hot 编码形式,和logits一样的形状
logits:输出层的加权计算结果,即预测值
-
-
one-hot编码:
tf.one_hot(indices,depth,axis,name=None)
indices:需要编码的张量
depth:one-hot编码的深度,这个例子里是26
axis:填充的维度,默认是-1
-
提取最大值:
tf.argmax(y_predict, 2)
- 返回某个 tensor 对象在某一维上的其数据最大值所在的索引值
- 第一个参数是 张量; 第二个参数是提取的维度的下标
-
tf.reduce_all(input_tensor, axis = None, keep_dims = False,name = None, reduction_indices = None)
-
计算张量在维度上的逻辑和
-
input_tensor:要减少的布尔张量.
-
axis:要减小的维度,如果为None(默认),则减少所有维度.必须在范围[-rank(input_tensor), rank(input_tensor))内.
-
keep_dims:如果为 true,则保留长度为1的缩小维度.
-
name:操作的名称(可选).
-
reduction_indices:轴的已弃用名称.
-
例子:
x = tf.constant([[True, True], [False, False]]) tf.reduce_all(x) # False tf.reduce_all(x, 0) # [False, False] tf.reduce_all(x, 1) # [True, False] In [5]: tf.equal([1,2,3,4], [1,2,3,4]).eval() Out[5]: array([ True, True, True, True]) In [9]: tf.reduce_all([[ True, True, True, True],[True, True, True,True]], axis=1).eval() Out[9]: array([ True, True]) In [10]: tf.reduce_all([[ True, True, True, True],[True, True, True,False]], axis=1).eval() Out[10]: array([ True, False])
-
-
取ask 码:
ord(a)
-
pandas中索引的使用
定义一个pandas的DataFrame对像
import pandas as pd data = pd.DataFrame({'A':[1,2,3],'B':[4,5,6],'C':[7,8,9]},index=["a","b","c"]) data A B C a 1 4 7 b 2 5 8 c 3 6 9 # .loc[],中括号里面是先行后列,以逗号分割,行和列分别是行标签和列标签,比如我要得到数字5,那么就就是 data.loc["b","B"] # 5 data.loc["a","B"] # 4 data.loc['b':'c','B':'C'] # 5,8,6,9 选择一个区域 -
OS函数使用
# -*- coding:utf-8 -*- """ @author:lei """ import os #os.path.join() 将分离的部分合成一个整体 filename=os.path.join('/home/ubuntu/python_coding','split_func') print filename #输出为:/home/ubuntu/python_coding/split_func #os.path.splitext()将文件名和扩展名分开 fname,fename=os.path.splitext('/home/ubuntu/python_coding/split_func/split_function.py') print 'fname is:',fname print 'fename is:',fename #输出为: # fname is:/home/ubuntu/python_coding/split_func/split_function #fename is:.py #os.path.split()返回文件的路径和文件名 dirname,filename=os.path.split('/home/ubuntu/python_coding/split_func/split_function.py') print dirname print filename #输出为: # /home/ubuntu/python_coding/split_func #split_function.py #split()函数 #string.split(str="", num=string.count(str))[n] #str - - 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。 #num - - 分割次数。 #[n] - - 选取的第n个分片 string = "hello.world.python" print string.split('.')#输出为:['hello', 'world', 'python'] print(string.split('.',1))#输出为:['hello', 'world.python'] print(string.split('.',1)[0])#输出为:hello print(string.split('.',1)[1])#输出为:world.python string2="helloand
-
CNN卷积神经网络实现验证码识别代码,详细备注,供自己复习。
import tensorflow as tf
import numpy as np
import os
import pandas as pd
from tensorflow.contrib.layers.python.layers import batch_norm
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
with tf.device('/gpu'): # 设置在GPU上跑
class VerificationCode(object):
def __init__(self):
pass
def parse_label(self):
# 解析标签文件
vc_data = pd.read_csv('./Genpics/labels.csv', names=['file_num', 'char_code'], index_col ='file_num')
# pandas 自动认为第一行是列明,会自动添加一列索引,导致错位,所以,要自己给两列数据命名,自己设置索引
# print(csv_data)
vc_code = vc_data['char_code'] # 取这一列数据
letter_list =[]
for line in vc_code:
letters = []
for c in line:
diff = ord(c) - ord('A')
letters.append(diff)
letter_list.append(letters)
vc_data['verification_code'] = letter_list # 在数据中加一列-对应的ascll码 映射
return vc_data
def picture_read(self):
# 读取图片文件
filenames = os.listdir('./GenPics/')
file_list = ['./GenPics/' + name for name in filenames if name[-3:]=='jpg']
file_queue = tf.train.string_input_producer(file_list)
# 读取器
reader = tf.WholeFileReader()
key, value = reader.read(file_queue)
# 解码并调整:解码出来形状是(?,?,?) 所以需要变形
image = tf.image.decode_jpeg(value)
image.set_shape([20, 80, 3])
filename_batch, image_batch = tf.train.batch([key, image], batch_size=20, num_threads=2, capacity=32)
return filename_batch, image_batch
def file_to_label(self, filenames, label_data):
"""由图片名获取标签"""
labels = []
for name in filenames:
index, _ = os.path.splitext(os.path.basename(name))
code = label_data.loc[int(index), 'verification_code'] # 通过索引找某一列的对应数据
labels.append(code)
return np.array(labels)
def init_weights(self, shape):
return tf.Variable(initial_value=tf.random_normal(shape = shape, mean=0.0, stddev=0.001))
def cnn_model(self, x):
# [None, 20, 80, 3]
# 定义第一层卷积网络 卷积核 5*5 步长1 padding=‘SAME’ 64个
# 池化层 窗口大小 ksize 2*2 步长2 padding=‘SAME’
with tf.variable_scope('conv1'):
conv1_w = self.init_weights([5, 5, 3, 64])
conv1_b = self.init_weights([64])
x_conv1 = tf.nn.conv2d(x, conv1_w, strides=[1,1,1,1], padding='SAME') + conv1_b
# [None, 20, 80, 64]
x_bn1 = batch_norm(x_conv1, decay=0.9, updates_collections=None, is_training=True)
# 添加bn层,做批量标准化
x_relu1 = tf.nn.relu(x_bn1)
# [None, 20, 80, 64]
x_pool1 = tf.nn.max_pool(x_relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# [None, 10, 40, 64]
with tf.variable_scope('conv2'):
conv2_w = self.init_weights([3, 3, 64, 128])
conv2_b = self.init_weights([128])
x_conv2 = tf.nn.conv2d(x_pool1, conv2_w, strides = [1,1,1,1], padding='SAME') + conv2_b
# [None, 10, 40, 128]
x_bn2 = batch_norm(x_conv2, decay=0.9, updates_collections=None, is_training=True)
x_relu2 = tf.nn.relu(x_bn2)
# [None, 10, 40, 128]
x_pool2 = tf.nn.max_pool(x_relu2, ksize = [1,2,2,1], strides = [1,2,2,1], padding='SAME')
# [None, 5, 20, 128]
with tf.variable_scope('full_connection'):
# 全连接层需要矩阵运算,需要2-D张量
x_fc = tf.reshape(x_pool2, [-1, 5*20*128])
fc_w = self.init_weights([5*20*128, 4*26])
fc_b = self.init_weights([4*26])
y_predict = tf.matmul(x_fc, fc_w) + fc_b
return y_predict
def run(self):
filename_batch, image_batch = self.picture_read()
# 定义占位符
with tf.variable_scope('placeholder'):
x = tf.placeholder(dtype = tf.float32, shape = [None, 20, 80, 3])
y_true = tf.placeholder(dtype = tf.float32, shape = [None, 4*26])
y_predict = self.cnn_model(x)
with tf.variable_scope('loss'):
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels = y_true, logits = y_predict))
with tf.variable_scope('optimizer'):
train_operation = tf.train.AdamOptimizer(0.0001).minimize(loss)
with tf.variable_scope('accuracy'):
equal_list = tf.reduce_all( # tf.reduce_all --> [-1, 1] 在4 的维度比较,生成 [n个, [True]形式的数据 ]
tf.equal(tf.argmax(tf.reshape(y_true, [-1, 4, 26]), axis =2), # tf.equal --> [-1, 4] 在4 的维度比较,生成 [n个, [True, True, True, True]形式的数据]
tf.argmax(tf.reshape(y_predict, [-1, 4, 26]),axis =2)), # tf.argmax(tf.reshape(y_true, [-1, 4, 26]), axis =2) --> [-1, 4] 从26的维度提取最大值
axis=1
)
# tf.equal后,得到的是这种形式的数据 array([ True, True, True, True])
# tf.reduce_all() 计算张量在维度上的逻辑和
# In [9]: tf.reduce_all([[ True, True, True, True],[True, True, True,True]], axis=1).eval()
# Out[9]: array([ True, True])
# In [10]: tf.reduce_all([[ True, True, True, True],[True, True, True,False]], axis=1).eval( )
# Out[10]: array([ True, False])
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
saver = tf.train.Saver()
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True)) as sess:
sess.run(tf.global_variables_initializer())
if os.path.exists('./CNNyanzhengma_save/checkpoint'):
saver.restore(sess, './CNNyanzhengma_save/')
coo = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess = sess, coord = coo)
label_data = self.parse_label()
for epoch in range(1000):
filenames, images = sess.run([filename_batch, image_batch])
labels = self.file_to_label(filenames, label_data)
y_one_hot = tf.reshape(tf.one_hot(labels, 26), [-1, 4*26]).eval()
train_epoch, loss_epoch, accuracy_epoch = sess.run([train_operation, loss, accuracy], feed_dict = {
x:images, y_true:y_one_hot
})
if (epoch + 1) % 50 == 0:
print('round=%d, loss=%f, accuracy=%f' % (epoch+1, loss_epoch,accuracy_epoch))
if accuracy_epoch > 0.9:
saver.save(sess, './CNNyanzhengma_save/')
coo.request_stop()
coo.join(threads)
if __name__ == '__main__':
vc = VerificationCode()
vc.run()