Redis cluster集群部署详细讲解
集群Redis cluster
文章目录
- 集群Redis cluster
-
- 1.集群介绍
- 2.数据分布
- 3.集群Redis cluster
-
- 3.1.集群环境
- 4.部署操作
-
- 4.1.配置文件
- 4.2.配置redis集群自动发现
- 5.redis Cluster通讯流程
- 6.Redis Cluster 手动分配槽位
-
- 6.1.分配槽位操作
- 6.2.配置主次交叉复制
- 7.redis cluster故障切换
-
- 7.1.手动恢复主服务器
1.集群介绍
Redis Cluster是redis的分布式解决方案,在3.0版本正式推出。
当遇到单机、内存、并发、流量等瓶颈时,可以采用Cluster架构方案达到负载均衡的目的。
Redis cluster之前的分布式方案有两种:
1)客户端分区方案,有点逻辑分区可控,缺点是需要自己处理数据路由,高可用和故障转移等。
2)代理方案,优点是简化客户端分布式逻辑和升级维护便利,缺点加重架构部署和性能消耗。
2.数据分布
分布式数据库首先要解决吧整个数据库集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整体数据的一个子集,需要关注的是数据分片规则,Rredis Cluster采用哈希分片规则。
3.集群Redis cluster
1.槽位分配slot
2.65534个槽位
3.每个槽都得分配到位,有一个槽没有分配,整个集群不可用。
4.序号不一定要连续,最重要的是每个节点的槽位数量要大致相同,运行2%的误差。
5.集群通讯端口为配置文件里的port加10000,比如6380,通讯端口是16380
6.集群转移切换全自动,不需要手动更改
7.集群配置文件动态更新
8.代码连接redis集群需要插件更新驱动
9.集群内的消息传递是同步的
10.集群内的所有已经发现的节点配置文件是自动更新的。
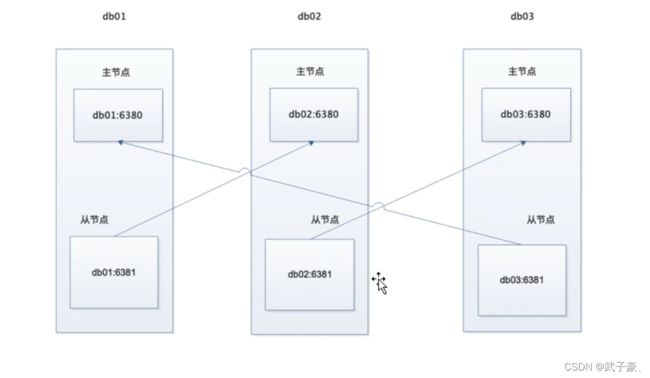
3.1.集群环境
4.部署操作
4.1.配置文件
创建一下对应的文件目录
db1、db2、db3先给这几个机器创建目录。
[root@localhost redis_cluster]# mkdir -p /opt/redis_cluster/redis_6381/{conf,pid,log}
[root@localhost redis_cluster]# mkdir -p /opt/redis_cluster/redis_6380/{conf,pid,log}
[root@localhost redis_cluster]#mkdir /data/redis_cluster/redis_6381
[root@localhost redis_cluster]#mkdir /data/redis_cluster/redis_6380
内容都是一样的只需要根据自己的情况修改一下IP就行,三台机器一样的操作
cat >/opt/redis_cluster/redis_6381/conf/redis_6381.conf<cat >/opt/redis_cluster/redis_6380/conf/redis_6380.conf<redis集群不仅需要开通redis客户端连接端口比如6380,而且需要开通集群总线端口,集群总线端口为redis客户端连接的端口+1000
4.2.配置redis集群自动发现
先启动三个节点的服务
然后我们来配置redis集群的自动发现
这样把其他几个节点的端口也进行自动发现。
192.168.40.5:6380> CLUSTER MEET 192.168.40.5 6381
192.168.40.5:6380> CLUSTER MEET 192.168.40.1 6381
192.168.40.5:6380> CLUSTER MEET 192.168.40.1 6380
192.168.40.5:6380> CLUSTER MEET 192.168.40.2 6380
192.168.40.5:6380> CLUSTER MEET 192.168.40.2 6381
使用命令查询,会发现多出来其他节点的信息
可以去其他两个节点查看一下是否同步过来了,三个节点都已经发现的了对应的信息。
192.168.40.5:6380> CLUSTER NODES
8dafec60cce26a31db7a572781a4a142cef5afc8 192.168.40.5:6381 master - 0 1654524226664 0 connected
84a879f92a71ce681fea90bfb1f0580e065665aa 192.168.40.1:6381 handshake - 1654524218830 0 0 connected
03b15eff66eec33ed10c688d96433df406ba22c6 192.168.40.5:6380 myself,master - 0 0 1 connected
8df440140f0e6726e46276d91971a7e1e41dd1c7 192.168.40.1:6380 handshake - 1654524220151 0 0 connected
88cfb82f60c2c3bad1bff680ecf46d6587860308 192.168.40.2:6380 handshake - 1654524223713 0 0 connected
068edbb27ed5c3ae6846c7871edf8aa539bfedda 192.168.40.2:6381 handshake - 1654524228290 0 0 connected
还有配置文件中的相关信息,三个节点的内容是一样的
[root@localhost redis_cluster]# cat redis_6380/nodes_6380.conf
40346157be5f5a04d8885dd8505da410cc82f0c2 192.168.40.2:6380 master - 0 1654524526563 4 connected
8dafec60cce26a31db7a572781a4a142cef5afc8 192.168.40.5:6381 master - 0 1654524525544 2 connected
ed3bf0674ec300001f0a366d2959fe5c15ad9ea7 192.168.40.2:6381 master - 0 1654524528705 0 connected
4c824b30bfb0e44aa3ee6e45818e8c6b528f969d 192.168.40.1:6381 master - 0 1654524527583 3 connected
932ae32e441ada1089d35144200315905e97997d 192.168.40.1:6380 myself,master - 0 0 5 connected
03b15eff66eec33ed10c688d96433df406ba22c6 192.168.40.5:6380 master - 0 1654524528602 1 connected
vars currentEpoch 5 lastVoteEpoch 0
5.redis Cluster通讯流程
在分布式存储中需要提供维持节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障灯状态信息,redis集群采集Gossip(流言)协议,Gossip协议工作原理就是节点彼此不断交换信息,一段时间后所有的节点都会知道集群完整的信息,这种方式类似流言出传播。
通信过程:
1.集群中的每一个节点都会单独开辟一个tcp通道,用于节点之间彼此通信,通信端口在基础端口上架10000.
2.每个节点在固定周期内通过特定规则选择结构节点发送ping消息
3.接收到ping消息的节点用pong消息作为相应。集群中每个节点通过一定规则挑选需要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只要这些节点彼此可以正常通信,最后他们会达成一致的状态,当节点出现故障,新节点加入,主从角色变化等,他能够给不断的ping/pong消息,从而达到同步目的。
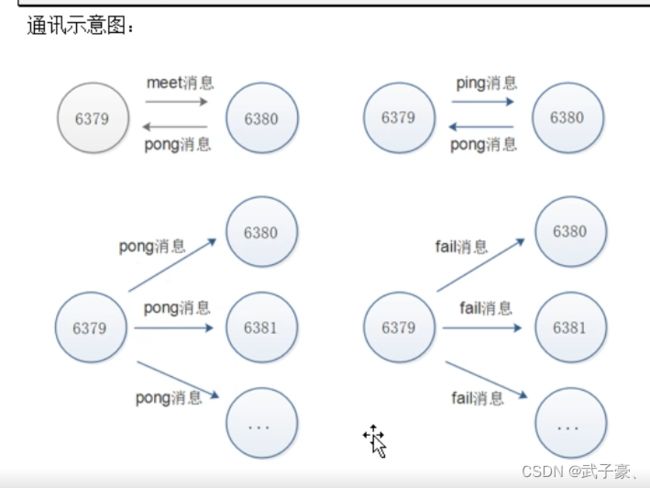
通信消息类型:
Gossip
Gossip协议职责就是信息交换,信息交换的载体就是节点彼此发送Gossip消息。
常见的Gossip消息分为:ping、pong、meet、fail等
meet
meet消息:用于通知新节点加入,消息发送者通知接受者加入当前集群,meet消息通信正常完成后,接收节点加入集群中并进行ping、pong消息交换。
通讯示意图:
6.Redis Cluster 手动分配槽位
虽然节点之间已经互相发现了,但是此时集群还是不可用的状态,因此并没有给节点分配槽位,而且必须是所有的槽位都分配完成后整个集群是可用的状态。
反之,也就是说只有一个槽位没有分配,那么整个集群就是不可用的。
目前是没有分配槽位的情况下
测试命令:
[root@localhost ~]# redis-cli -h 192.168.40.5 -p 6380
192.168.40.5:6380> set k22 v1
(error) CLUSTERDOWN Hash slot not served
#发现执行的报错的
#执行这个命令CLUSTER INFO
192.168.40.5:6380> CLUSTER INFO
cluster_state:fail #集群状态目前是失败的
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6 #集群数量是6个
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:1
cluster_stats_messages_sent:18869
cluster_stats_messages_received:18813
6.1.分配槽位操作
我们槽位一共是有16384个
db01 192.168.40.5 0-5460
db02 192.168.40.1 5461-10922
db03 192.168.40.2 10923-16384
命令:#在服务器中执行分配对应的槽位
redis-cli -h 192.168.40.5 -p 6380 cluster addslots {0..5461}
redis-cli -h 192.168.40.1 -p 6380 cluster addslots {5462..10922}
redis-cli -h 192.168.40.2 -p 6380 cluster addslots {10923..16383}
#查询槽位分配成功的情况
192.168.40.1:6380> CLUSTER NODES
9ab7887766fb733ea9ba8b9077c493a604e8eaf4 192.168.40.2:6380 master - 0 1655214041555 3 connected 10923-16383
8787c7146d996e1a9721cce8d7f0191a01a7df27 192.168.40.1:6381 master - 0 1655214037526 2 connected
a5a381d1196111efaa97519b450b150487524245 192.168.40.5:6380 master - 0 1655214042561 5 connected 0-5461
e5dad803a672ae4a78761f7e6ce58f67941b8fb1 192.168.40.2:6381 master - 0 1655214043569 0 connected
27c999eb5f011491803f4493826791b101e6b1df 192.168.40.5:6381 master - 0 1655214040548 4 connected
7094c6f0782084271a2705a2bfdd99a7780cd0d1 192.168.40.1:6380 myself,master - 0 0 1 connected 5462-10922
6.2.配置主次交叉复制
上面我们的槽位已经是分配完成了,现在我们来配置cluster集群的主从关系。
命令是CLUSTER REPLICATE
#我们进入6381的端口是需要根据他最前面的“e5dad803a672ae4a78761f7e6ce58f67941b8fb1”这个来指集群的信息,配置交叉复制。
[root@localhost redis_cluster]# redis-cli -h 192.168.40.5 -p 6381
192.168.40.5:6381> CLUSTER NODES
e5dad803a672ae4a78761f7e6ce58f67941b8fb1 192.168.40.2:6381 master - 0 1655214861385 0 connected
7094c6f0782084271a2705a2bfdd99a7780cd0d1 192.168.40.1:6380 master - 0 1655214856351 1 connected 5462-10922
9ab7887766fb733ea9ba8b9077c493a604e8eaf4 192.168.40.2:6380 master - 0 1655214859373 3 connected 10923-16383
a5a381d1196111efaa97519b450b150487524245 192.168.40.5:6380 master - 0 1655214858365 5 connected 0-5461
27c999eb5f011491803f4493826791b101e6b1df 192.168.40.5:6381 myself,master - 0 0 4 connected
8787c7146d996e1a9721cce8d7f0191a01a7df27 192.168.40.1:6381 master - 0 1655214862393 2 connected
192.168.40.5:6381>
#上面有详细的图来解释交叉复制。
db01
192.168.40.5:6381> CLUSTER REPLICATE 7094c6f0782084271a2705a2bfdd99a7780cd0d1
OK
db02
192.168.40.1:6381> CLUSTER REPLICATE 9ab7887766fb733ea9ba8b9077c493a604e8eaf4
OK
db03
192.168.40.2:6381> CLUSTER REPLICATE a5a381d1196111efaa97519b450b150487524245
OK
配置完成后再次查询发现会有三个6381的节点变成slave,这样我们的交叉复制就配置完成了
192.168.40.5:6381> CLUSTER NODES
e5dad803a672ae4a78761f7e6ce58f67941b8fb1 192.168.40.2:6381 slave a5a381d1196111efaa97519b450b150487524245 0 1655215163610 5 connected
7094c6f0782084271a2705a2bfdd99a7780cd0d1 192.168.40.1:6380 master - 0 1655215166631 1 connected 5462-10922
9ab7887766fb733ea9ba8b9077c493a604e8eaf4 192.168.40.2:6380 master - 0 1655215164618 3 connected 10923-16383
a5a381d1196111efaa97519b450b150487524245 192.168.40.5:6380 master - 0 1655215165624 5 connected 0-5461
27c999eb5f011491803f4493826791b101e6b1df 192.168.40.5:6381 myself,slave 7094c6f0782084271a2705a2bfdd99a7780cd0d1 0 0 4 connected
8787c7146d996e1a9721cce8d7f0191a01a7df27 192.168.40.1:6381 slave 9ab7887766fb733ea9ba8b9077c493a604e8eaf4 0 1655215162602 3 connected
7.redis cluster故障切换
来模拟一下故障切换的功能,目前的架构是三主三从交叉复制的结构,主服务器宕机的情况下从服务器会自动顶替,但是主服务器恢复后,之前的主服务器不会自动恢复,需要我们来手动指定。
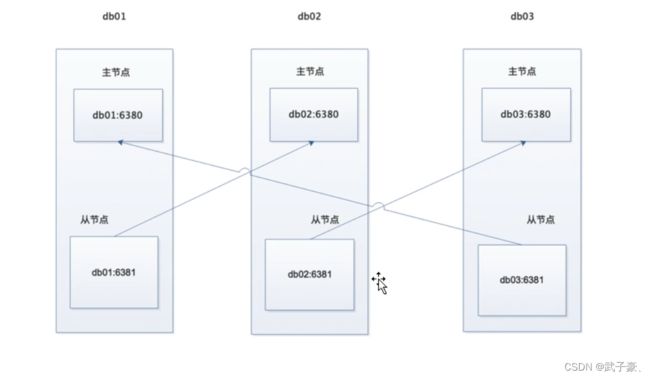
下面我们把db01的6380接口给关掉,然后db03的6381会变成主服务器。
[root@localhost ~]# ps -ef |grep redis
root 3289 1 0 20:15 ? 00:00:01 redis-server 192.168.40.5:6379
root 3297 1 0 20:16 ? 00:00:02 redis-server 192.168.40.5:6381 [cluster]
root 3696 1 0 20:32 ? 00:00:01 redis-server 192.168.40.5:6380 [cluster]
root 3700 3149 0 20:33 pts/1 00:00:00 redis-cli -h 192.168.40.5 -p 6380
root 4370 3709 0 21:03 pts/2 00:00:00 grep --color=auto redis
[root@localhost ~]# kill -9 3696
[root@localhost ~]# ps -ef |grep redis
root 3289 1 0 20:15 ? 00:00:01 redis-server 192.168.40.5:6379
root 3297 1 0 20:16 ? 00:00:02 redis-server 192.168.40.5:6381 [cluster]
root 3700 3149 0 20:33 pts/1 00:00:00 redis-cli -h 192.168.40.5 -p 6380
root 4405 3709 0 21:03 pts/2 00:00:00 grep --color=auto redis
#可以看到6380端口已经被kill掉了,我们在查询一下集群情况

我们关闭db01的6380后可以看到
db03:192.168.40.2:6381已经是变成主了
db01:192.168.40.5的6380已经变成了从服务器
然后我们来启动db01的6380端口
[root@localhost redis_cluster]# redis-server redis_6380/conf/redis_6380.conf
[root@localhost redis_cluster]# ps -ef |grep redis
root 3289 1 0 20:15 ? 00:00:02 redis-server 192.168.40.5:6379
root 3297 1 0 20:16 ? 00:00:03 redis-server 192.168.40.5:6381 [cluster]
root 3700 3149 0 20:33 pts/1 00:00:00 redis-cli -h 192.168.40.5 -p 6380
root 4620 1 0 21:12 ? 00:00:00 redis-server 192.168.40.5:6380 [cluster]
root 4624 3709 0 21:12 pts/2 00:00:00 grep --color=auto redis
7.1.手动恢复主服务器
#我们可以在db01的6380端口来执行这个命令,来把slave给升级为master
192.168.40.5:6380> CLUSTER FAILOVER
OK

可以看到我们的节点已经是恢复到db01上了。