tensorflow学习笔记(十一):DCGAN生成手写体数字(MNIST)
文章目录
- 一、DCGAN简介
- 二、主要函数
- 三、项目实战
一、DCGAN简介
DCGAN是将CNN与GAN的一种结合,这是第一次在GAN中使用卷积神经网络并取得了非常好的结果,弥合CNNs在监督学习和无监督学习之间的差距,其将卷积网络引入到生成式模型当中来做无监督的训练,利用卷积网络强大的特征提取能力来提高生成网络的学习效果。
结构如下:
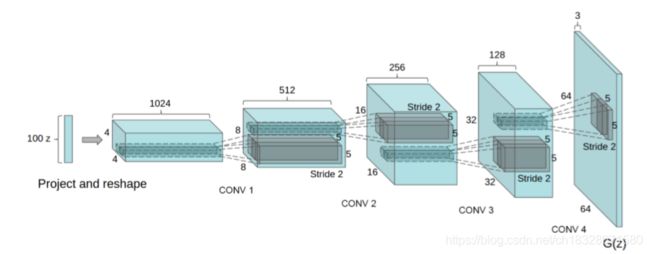
具体理论知识参考:GAN的系列经典模型讲解。
二、主要函数
1、tf.layers.dense():
相当于添加一个全连接层,即初学的add_layer()函数,定义如下:
tf.layers.dense(
inputs,
units,
activation=None,
use_bias=True,
kernel_initializer=None, ##卷积核的初始化器
bias_initializer=tf.zeros_initializer(), ##偏置项的初始化器,默认初始化为0
kernel_regularizer=None, ##卷积核的正则化,可选
bias_regularizer=None, ##偏置项的正则化,可选
activity_regularizer=None, ##输出的正则化函数
kernel_constraint=None,
bias_constraint=None,
trainable=True,
name=None, ##层的名字
reuse=None ##是否重复使用参数
)
参数:
- nputs:该层的输入。
- units: 输出的大小(维数),整数或long。
- activation: 使用什么激活函数(神经网络的非线性层),默认为None,不使用激活函数。
- use_bias: 使用bias为True(默认使用),不用bias改成False即可。
- kernel_initializer:权重矩阵的初始化函数。 如果为None(默认值),则使用tf.get_variable使用的默认初始化程序初始化权重。
- bias_initializer:bias的初始化函数。
- kernel_regularizer:权重矩阵的正则函数。
- bias_regularizer:bias的的正则函数。
- activity_regularizer:输出的的正则函数。
- kernel_constraint:由优化器更新后应用于内核的可选投影函数(例如,用于实现层权重的范数约束或值约束)。 该函数必须将未投影的变量作为输入,并且必须返回投影变量(必须具有相同的形状)。 在进行异步分布式培训时,使用约束是不安全的。
- bias_constraint:由优化器更新后应用于偏差的可选投影函数。
- trainable:Boolean,如果为True,还将变量添加到图集collectionGraphKeys.TRAINABLE_VARIABLES(参见tf.Variable)。
- name:名字
- reuse:Boolean,是否以同一名称重用前一层的权重。
程序示例:
import tensorflow as tf
batch_size = 5
ones = tf.ones([batch_size,8,20])
logits = tf.layers.dense(ones,10)
print(logits.get_shape())
#输出
(5, 8, 10)
2、tf.layers.conv2d_transpose():
用于反卷积(转置卷积),对转置卷积的需要一般来自希望使用与正常卷积相反方向的变换,即从具有某种卷积输出形状的某物到具有其输入形状的物体,同时保持与所述卷积兼容的连接模式。定义如下:
tf.layers.conv2d_transpose(
inputs,
filters,
kernel_size,
strides=(1, 1),
padding='valid',
data_format='channels_last',
activation=None,
use_bias=True,
kernel_initializer=None,
bias_initializer=tf.zeros_initializer(),
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
trainable=True,
name=None,
reuse=None
)
参数(标黄的是比较关注的参数):
- inputs:输入张量.
- filters:整数,输出空间的维数(即卷积中的滤波器数).
- kernel_size:一个元组或2个正整数的列表,指定过滤器的空间维度;可以是单个整数,以指定所有空间维度的相同值.
- strides:一个元组或2个正整数的列表,指定卷积的步幅;可以是单个整数,以指定所有空间维度的相同值.
- padding:一个"valid"或"same"(不区分大小写).
- data_format:一个字符串,一个channels_last(默认)或channels_first;输入中维度的排序channels_last对应于具有形状(batch, height, width, channels)的输入侧,而channels_first对应于具有形状(batch, channels, height, width)的输入侧.
- activation:激活功能,将其设置None为保持线性激活.
- use_bias:布尔值,表示该层是否使用偏差.
- kernel_initializer:卷积内核的初始化程序.
- bias_initializer:偏置向量的初始化器;如果为None,将使用默认初始值设定项.
- kernel_regularizer:卷积内核的可选正则化程序.
- bias_regularizer:偏置矢量的可选正则化程序.
- activity_regularizer:输出的可选正则化函数.
- kernel_constraint:由一个Optimizer更新后应用于内核的可选投影函数(例如,用于实现层权重的范数约束或值约束),该函数必须将未投影的变量作为输入,并且必须返回投影变量(必须具有相同的形状).在进行异步分布式培训时,使用约束是不安全的.
- bias_constraint:由一个Optimizer更新后应用于偏差的可选投影函数.
- trainable:布尔值,如果为True,还将变量添加到图产品集合GraphKeys.TRAINABLE_VARIABLES中.
- name:字符串,图层的名称.
- reuse:布尔值,是否以同一名称重用前一层的权重.
返回值:特定大小的张量
程序示例:
import numpy as py
import tensorflow as tf
a = np.array([[1,1],[2,2]], dtype=np.float32)
# tf.layers.conv2d_transpose 要求输入是4维的
a = np.reshape(a, [1,2,2,1])
# 定义输入
x = tf.constant(a,dtype=tf.float32)
# 进行tf.layers.conv2d_transpose
upsample_x = tf.layers.conv2d_transpose(x, 1, 3, strides=2, padding='same', kernel_initializer=tf.ones_initializer())
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(upsample_x))
#输出
[[[[1],[1],[2],[1]],
[[1],[1],[2],[1]],
[[3],[3],[6],[3]],
[[2],[2],[4],[2]]]]
3、tf.layers.conv2d():
2D 卷积层的函数接口 这个层创建了一个卷积核,将输入进行卷积来输出一个 tensor。如果 use_bias 是 True(且提供了 bias_initializer),则一个偏差向量会被加到输出中。最后,如果 activation 不是 None,激活函数也会被应用到输出中。定义如下;
tf.layers.conv2d(inputs, filters, kernel_size,
strides=(1, 1),
padding='valid',
data_format='channels_last',
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer=None,
bias_initializer=,
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
trainable=True,
name=None,
reuse=None)
参数:
- inputs:Tensor 输入
- filters:整数,表示输出空间的维数(即卷积过滤器的数量)
- kernel_size:一个整数,或者包含了两个整数的元组/队列,表示卷积窗的高和宽。如果是一个整数,则宽高相等。
- strides:一个整数,或者包含了两个整数的元组/队列,表示卷积的纵向和横向的步长。如果是一个整数,则横纵步长相等。另外, strides 不等于1 和 dilation_rate 不等于1 这两种情况不能同时存在。
- padding:“valid” 或者 “same”(不区分大小写)。“valid” 表示不够卷积核大小的块就丢弃,"same"表示不够卷积核大小的块就补0。
- data_format:channels_last 或者 channels_first,表示输入维度的排序。
- dilation_rate:一个整数,或者包含了两个整数的元组/队列,表示使用扩张卷积时的扩张率。如果是一个整数,则所有方向的扩张率相等。另外, strides 不等于1 和 dilation_rate 不等于1 这两种情况不能同时存在。
- activation:激活函数。如果是None则为线性函数。
- use_bias:Boolean类型,表示是否使用偏差向量。
- kernel_initializer:卷积核的初始化。
- bias_initializer:偏差向量的初始化。如果是None,则使用默认的初始值。
- kernel_regularizer:卷积核的正则项
- bias_regularizer:偏差向量的正则项
- activity_regularizer:输出的正则函数
- kernel_constraint:映射函数,当核被Optimizer更新后应用到核上。Optimizer 用来实现对权重矩阵的范数约束或者值约束。映射函数必须将未被影射的变量作为输入,且一定输出映射后的变量(有相同的大小)。做异步的分布式训练时,使用约束可能是不安全的。
- bias_constraint:映射函数,当偏差向量被Optimizer更新后应用到偏差向量上。
- trainable:Boolean类型。
- name:字符串,层的名字。
- reuse:Boolean类型,表示是否可以重复使用具有相同名字的前一层的权重。
返回值:特定大小的输出 Tensor
程序示例:
res = tf.layers.conv2d(x,filters=32,kernel_size=[3,3],strides=1,padding='SAME')
#用32个3*3的卷积核对x进行卷积操作
注意:
TensorFlow定义的二维卷积有三种,分别是tf.nn.conv2d、tf.layers.conv2d、tf.contrib.layers.conv2d。
与tf.nn.conv2d不同的是,tf.nn.conv2d不仅需要对权重初始化,还需要定义卷积核的维度。
4、tf.layers.average_pooling2d():
2D输入的平均池层(例如图像)。定义如下:
tf.layers.average_pooling2d(
inputs,
pool_size,
strides,
padding='valid',
data_format='channels_last',
name=None
)
参数:
- inputs:要在池上的张量,它的秩必须为4.
- pool_size:2个整数的整数或元组/列表:(pool_height,pool_width),指定池窗口的大小;可以是单个整数,以指定所有空间维度的相同值.
- strides:2个整数的整数或元组/列表,指定池操作的步幅;可以是单个整数,以指定所有空间维度的相同值.
- padding:字符串,一个填充方法,可以是“valid”或“same”,不区分大小写.
- data_format:一个字符串,输入中维度的排序,支持channels_last(默认)和channels_first;channels_last对应于具有形状(batch, height, width, channels)的输入,而channels_first对应于具有形状(batch, channels, height, width)的输入.
- name:字符串,图层的名称.
程序示例:
x = tf.layers.average_pooling2d(x, 2, 2)
5、tf.contrib.layers.flatten() :
tf.contrib.layers.flatten§函数使得P保留第一个维度,把第一个维度包含的每一子张量展开成一个行向量,返回张量是一个二维的,返回的shape为[第一维度,子张量乘积)。一般用于卷积神经网络全连接层前的预处理,因为全连接层需要将输入数据变为一个向量,向量大小为[batch_size, ……]
fla = tf.contrib.layers.flatten(pool)
上边里,pool是全连接层的输入,则需要将其转换为一个向量。假设pool是一个1007764的矩阵,则通过转换后,得到一个[100,3136]的矩阵,这里100位卷积神经网络的batch_size,3136则是77*64的乘积。
6、tf.concat():
用于连接两个矩阵。定义:、
tf.concat([tensor1, tensor2, tensor3,...], axis)
参数:
- tensor1, tensor2, tensor3,…:是需要拼接的张量。
- axis:表示维度信息,axis=0,代表在第0个维度拼接;axis=1 ,代表在第1个维度拼接 。
程序示例:
t1 = [[1, 2, 3], [4, 5, 6]]
t2 = [[7, 8, 9], [10, 11, 12]]
tf.concat([t1, t2], 0) # [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
tf.concat([t1, t2], 1) # [[1, 2, 3, 7, 8, 9], [4, 5, 6, 10, 11, 12]]
# tensor t3 with shape [2, 3]
# tensor t4 with shape [2, 3]
tf.shape(tf.concat([t3, t4], 0)) # [4, 3]
tf.shape(tf.concat([t3, t4], 1)) # [2, 6]
三、项目实战
DCGAN生成手写体数字程序展示:
from __future__ import division, print_function, absolute_import
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
# 导入MNIST数据集
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
# 训练参数
num_steps = 2000
batch_size = 32
# 网络参数
image_dim = 784 # 28*28 pixels * 1 channel
gen_hidden_dim = 256
disc_hidden_dim = 256
noise_dim = 200 # 噪声数据
# 定义生成网络
# 输入:噪声;输出:图片
def generator(x, reuse=False):
with tf.variable_scope('Generator', reuse=reuse):
x = tf.layers.dense(x, units=6 * 6 * 128)
x = tf.nn.tanh(x)
# 将图片变换为4维张量: (batch, height, width, channels)
# 新的形状: (batch, 6, 6, 128)
x = tf.reshape(x, shape=[-1, 6, 6, 128])
# 反卷积, 图片的形状: (batch, 14, 14, 64)
x = tf.layers.conv2d_transpose(x, 64, 4, strides=2)
# 反卷积, 图片的形状: (batch, 28, 28, 1)
x = tf.layers.conv2d_transpose(x, 1, 2, strides=2)
# 使用sigmoid激活函数激活
x = tf.nn.sigmoid(x)
return x
# 定义判别网络
# 输入:图片, 输出: 预测的真假图片
def discriminator(x, reuse=False):
with tf.variable_scope('Discriminator', reuse=reuse):
# 用经典的CNN去分类
x = tf.layers.conv2d(x, 64, 5)
x = tf.nn.tanh(x)
x = tf.layers.average_pooling2d(x, 2, 2)
x = tf.layers.conv2d(x, 128, 5)
x = tf.nn.tanh(x)
x = tf.layers.average_pooling2d(x, 2, 2)
x = tf.contrib.layers.flatten(x)
x = tf.layers.dense(x, 1024)
x = tf.nn.tanh(x)
# 输出为2类,真假图片
x = tf.layers.dense(x, 2)
return x
# 创建GAN网络
# 网络输入
noise_input = tf.placeholder(tf.float32, shape=[None, noise_dim])
real_image_input = tf.placeholder(tf.float32, shape=[None, 28, 28, 1])
#### 创建生成网络
gen_sample = generator(noise_input)
# 创建两个判别网络,一个用于真实图片,一个用于生成样本
disc_real = discriminator(real_image_input)
disc_fake = discriminator(gen_sample, reuse=True)
disc_concat = tf.concat([disc_real, disc_fake], axis=0)
stacked_gan = discriminator(gen_sample, reuse=True)
# 创建目标
disc_target = tf.placeholder(tf.int32, shape=[None])
gen_target = tf.placeholder(tf.int32, shape=[None])
# 定义损失函数
disc_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=disc_concat, labels=disc_target))
gen_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=stacked_gan, labels=gen_target))
# 采用AdamOptimizer优化
optimizer_gen = tf.train.AdamOptimizer(learning_rate=0.001)
optimizer_disc = tf.train.AdamOptimizer(learning_rate=0.001)
# 网络变量
gen_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Generator')
disc_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='Discriminator')
# 最小化损失函数
train_gen = optimizer_gen.minimize(gen_loss, var_list=gen_vars)
train_disc = optimizer_disc.minimize(disc_loss, var_list=disc_vars)
# 初始化变量
init = tf.global_variables_initializer()
# 开始训练
with tf.Session() as sess:
sess.run(init)
for i in range(1, num_steps+1):
batch_x, _ = mnist.train.next_batch(batch_size)
batch_x = np.reshape(batch_x, newshape=[-1, 28, 28, 1])
z = np.random.uniform(-1., 1., size=[batch_size, noise_dim])
# 准备目标 (真图片: 1, 假图片: 0)
# 前半部分数据为真图片,后半部分数据为假图片
batch_disc_y = np.concatenate(
[np.ones([batch_size]), np.zeros([batch_size])], axis=0)
# 生成器尝试去欺骗判别器, 因此目标是1.
batch_gen_y = np.ones([batch_size])
# 训练
feed_dict = {real_image_input: batch_x, noise_input: z,
disc_target: batch_disc_y, gen_target: batch_gen_y}
_, _, gl, dl = sess.run([train_gen, train_disc, gen_loss, disc_loss],
feed_dict=feed_dict)
if i % 100 == 0 or i == 1:
print('Step %i: Generator Loss: %f, Discriminator Loss: %f' % (i, gl, dl))
# 用生成器生成的网络来自噪声
f, a = plt.subplots(4, 10, figsize=(10, 4))
for i in range(10):
# 噪声输入
z = np.random.uniform(-1., 1., size=[4, noise_dim])
g = sess.run(gen_sample, feed_dict={noise_input: z})
for j in range(4):
# 将噪声生成的图片拓展成三通道用于展示.
img = np.reshape(np.repeat(g[j][:, :, np.newaxis], 3, axis=2),
newshape=(28, 28, 3))
a[j][i].imshow(img)
f.show()
plt.draw()
plt.waitforbuttonpress()
产生的图片:

最后得到的结果并不是很好,还有很大的优化空间。