AWNet: Attentive Wavelet Network for Image ISP AWNet:图像 ISP 的注意力小波网络(个人笔记,勿喷)
抽象的。
随着过去十年智能手机性能的革命性提升,手机摄影成为广大智能手机用户最普遍的做法之一。然而,由于手机上相机传感器的尺寸有限,所拍摄的图像在视觉上仍然与数码单反 (DSLR) 相机拍摄的图像不同。为了缩小这一性能差距,一种是重新设计相机图像信号处理器(ISP)以提高图像质量。由于深度学习的迅速兴起,最近的工作求助于深度卷积神经网络 (CNN) 来开发一种复杂的数据驱动 ISP,该 ISP 将手机捕获的图像直接映射到 DSLR 捕获的图像。在本文中,我们介绍了一种利用注意力机制和小波变换的新型网络,称为 AWNet,以解决这个可学习的图像 ISP 问题。通过添加小波变换,我们提出的方法使我们能够从 RAW 信息中恢复有利的图像细节并实现更大的感受野,同时在计算成本方面保持高效率。我们的方法采用全局上下文块来学习非局部颜色映射以生成吸引人的 RGB 图像。更重要的是,这个块减轻了图像错位对提供的数据集的影响。实验结果表明我们的设计在定性和定量测量方面的进步。源代码可在 https://github.com/Charlie0215/AWNet-AttentiveWavelet-Network-for-Image-ISP 获得。
1 Introduction
传统的图像 ISP 是一个关键的处理单元,它将 RAW 图像从相机传感器映射到 RGB 图像,以适应人类视觉系统 (HVS)。为此,利用一系列子处理单元来处理来自照片捕获设备的不同伪影,其中包括颜色偏移、信号噪声和莫尔效应。然而,调整每个子处理单元需要图像专家的大量努力。
如今,移动设备已经配备了高分辨率相机,以满足移动摄影日益增长的需求。然而,由于空间紧凑,硬件在光学质量和像素数方面受到限制。此外,由于手持的不稳定性,曝光时间相对较短。因此,移动特定的 ISP 也必须补偿这些限制。
最近,基于深度学习 (DL) 的方法在各种图像增强任务上取得了相当大的成功,包括图像去噪 [1,39]、图像去马赛克 [10] 和超分辨率 [15,18,22,35]。与通常需要自然图像统计先验知识的传统图像处理算法不同,数据驱动的方法可以隐式地学习这些信息。由于这个事实,基于 DL 的方法非常适合映射问题 [5,37,42]。在这里,学习图像 ISP 可以看作是一个图像到图像的转换问题,可以通过基于 DL 的方法很好地解决。在 [14] 的 ZRR 数据集中,RAW 图像可以分解为 4 个通道,分别是拜耳模式的红色(R)、绿色(G1)、蓝色(B)和绿色(G2),如图 1 所示. 备注 4 个通道中的 2 个记录来自绿色传感器的辐射信息。因此,与 RGB 图像相比,需要额外的操作,例如去马赛克和颜色校正来处理 RAW 图像。此外,由于拜耳滤波器的性质,这 4 个通道的大小被下采样了 2 倍。为了使预测和地面实况图像的大小一致,需要进行上采样操作。这可以看作是一个恢复问题,应该考虑高频信息的恢复。在我们的观察中,即使作者采用了 SIFT [21] 和 RANSAC [33] 算法来减轻这种影响,DSLR 和移动拍摄的图像对之间的错位仍然很严重。值得一提的是,输入 RAW 图像和真实 RGB 图像之间的微小偏差会导致性能显着下降。
为了解决上述问题,我们引入了一种利用注意力机制和小波变换的新型可训练管道。更具体地说,我们提出的方法的输入是 RAW 图像及其去马赛克对应物的组合作为补充,其中双分支设计旨在强调不同的训练任务,即 RAW 模型的噪声去除和细节恢复以及去马赛克模型上的颜色映射;采用离散小波变换(DWT)从原始图像中恢复精细的上下文细节,同时保留训练过程中特征的信息量;至于色彩校正和色调映射,则利用 res-dense 连接和注意力机制来鼓励网络将精力放在重点区域上。
总之,我们的主要贡献是:
1)探索小波变换和非局部注意力机制在图像 ISP 管道中的有效性。
2) 采用双分支设计来获取原始图像及其去马赛克对应物,这使我们提出的方法能够将 RAW 图像转换为 RGB 图像。
3) 轻量级且完全卷积的编码器-解码器设计,在不同的输入大小上具有时间效率和灵活性。
2 相关工作
在本节中,我们简要回顾了传统的图像 ISP 方法、一些具有代表性的 RAW 到 RGB 映射算法以及现有的可学习成像管道。
2.1 传统图像 ISP 流水线
传统的 ISP 管道包含多种图像信号操作,其中包括去噪、去马赛克、白平衡、色彩校正、伽马校正和色调映射。由于图像传感器的性质,RAW图像中存在噪点是不可避免的。因此,[1,8,39] 提出了一些操作来去除噪声并提高信噪比。去马赛克操作将具有重复马赛克图案的单通道原始图像插入到多通道彩色图像中[10]。白平衡通过改变 RGB 通道的照明来校正颜色,使图像更容易被感知 [7]。颜色校正通过校正矩阵[17,28]调整图像值。色调映射缩小图像值的直方图以增强图像细节 [26,38]。请注意,传统图像 ISP 管道中的所有子处理单元都需要人工手动调整最终结果。
2.2 低级图像修复中的 RAW 数据使用
图像恢复领域的不同工作已经探索了将 RAW 数据应用于低级视觉任务的优势。例如,[5] 使用深色 RAW 图像和亮色图像对从长时间曝光的图像中恢复深色图像。在这种情况下,原始数据保留的辐射信息有助于图像照明的恢复。 [37]利用来自未处理相机数据的丰富辐射信息来恢复高频细节并提高其在超分辨率任务上的网络性能。他们的实验表明,使用原始数据代替相机处理的数据有利于单幅图像超分辨率任务。最近,[14,29] 采用未经处理的图像数据来增强移动相机成像。由于 RAW 数据避免了 ISP 中量化引入的信息丢失,因此有利于神经网络恢复精细的图像细节。受 [14] 的启发,我们的工作利用 RAW 数据来训练我们的网络以获得可学习的 ISP 管道。我们不再只将 RAW 图像作为输入,而是采用 [14] 和 [29] 中的输入数据格式的组合来鼓励我们的网络学习图像 ISP 的不同子任务,例如去噪、颜色映射、和细节还原。
2.3 基于深度学习的图像 ISP 流水线
由于 CNN 在大量低级视觉任务 [11,15,18,30,35] 上取得了可喜的表现,因此将其用于相机 ISP 的学习是很直观的。 [29] 从三星 S7 手机收集 RAW 低照度图像,并使用神经网络从简单的 ISP 管道中提高图像亮度并去除去马赛克 RGB 图像上的噪声。 [27] 从 JPEG 生成合成 RAW 图像,并应用 RAW 到 RGB 映射来恢复原始 RGB 图像。此外,之前在 AIM 2019 RAW to RGB Mapping Challenge 中的一些作品也取得了可喜的成绩。例如,[32] 考虑使用堆叠的 U-Nets 以粗到细的方式生成管道。 [24]采用多尺度训练策略,在保持全局感知接受度的同时恢复图像细节。最近的工作 [14] 试图通过将移动 RAW 图像直接转换为 DSLR 彩色图像来缩小移动和 DSLR 彩色图像之间的视觉质量差距,其中 RAW 图像由华为 P20 手机捕获,彩色图像来自佳能 5D Mark IV .尽管如此,所有以前的可学习 ISP 方法都只关注一般映射问题,而没有提及训练数据集中的其他工件。例如,如果没有额外的操作,DSLR 和移动图像对之间的错位可能会导致估计输出的严重退化。在我们的工作中,我们将全局上下文块与学习全局颜色映射的 res-dense 块相结合,以解决未对齐的图像特征。添加的块使我们的网络能够胜过 [14] 提出的当前最先进的方法。

图 2. 所提出的 AWNet 的主要架构。顶部和底部分别是 RAW 和去马赛克模型。我们取这两个模型的两个输出的平均值以获得最终预测。
3 建议的方法
我们在本节中描述了所提出的方法和训练策略。首先,展示了整个网络架构(如图2所示)和每个网络模块的细节,然后说明了这种设计的意义。最后介绍了训练中采用的损失函数。
3.1 Network Structure
所提出的 AWNet 采用 U-Net 类似结构,并通过三个主要模块整合了架构,即全局上下文 res-dense 模块、残差小波上采样模块和残差小波下采样模块(见图 3 和图 4 )。
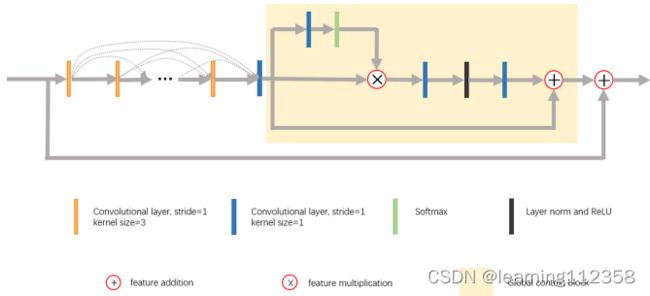
图 3. 我们的全局上下文 res-dense 模块包含一个残差密集块 (RDB) 和一个全局上下文块 (GCB)。我们观察到 RDB 可以从 RAW 图像中恢复颜色,而 GCB 鼓励网络努力学习全局颜色映射。详见章节4.4.
全局上下文 res-dense 模块由残差密集块 (RDB) 和全局上下文块 (GCB) [3] 组成。 RDB 的有效性已经过全面检查[20,41]。在这里,学习残差信息有利于颜色映射性能。 RDB 中总共使用了七个卷积层,其中前六层旨在增加特征图的数量,最后一层连接从这些层生成的所有特征图。在 RDB 的最后,提出了一个全局上下文块来鼓励网络学习全局颜色映射,因为局部颜色映射可能会由于 RAW 和 RGB 图像对之间的像素错位而导致结果退化。原因很明显,因为未对齐的存在会误导神经网络将颜色映射到不正确的像素位置。通过考虑卷积核只覆盖图像的局部信息,[34]提出了一种非局部注意机制。这项工作可以实现长距离像素之间的依赖关系,从而可以通过输入特征上所有位置的特征的加权和来计算查询点的值。然而,需要大量计算,特别是当特征图具有大尺寸时(例如,来自 ZRR 数据集的全分辨率输入图像)。通过实验,[3] 声称从不同查询点获得的注意力图有细微的差异。因此,他们提出了一种轻量级的全局上下文块(GCB),它简化了非本地模块,并结合了全局上下文框架和 SE 块 [12]。 GCB 鼓励网络在空间和通道方面学习关键信息,同时有效降低计算复杂度。这些特征正是我们在这个 RAW 到 RGB 映射问题中寻找的。
对于上采样和下采样,我们借鉴了离散小波变换(DWT)的思想,因为 DWT 的本质是将输入特征图分解为高频和低频分量,其中低频分量可以作为平均池的结果(进一步的讨论可以在第 3.3 节中找到)。如图 4 所示,我们使用低频分量作为下采样特征图的一部分,并将高频部分连接到上采样块以进行图像恢复(即逆 DWT)。然而,频域操作产生的特征图可能缺乏空间相关性。因此,采用了一个额外的空间卷积层来对带有学习内核的特征图进行下采样。类似地,像素混洗操作与空间卷积层一起用于上采样作为 IDWT 的补充。频域和空间域操作的结合有助于在上采样和下采样块中学习丰富的特征。在所提出的方法结束时,我们使用金字塔池块 [6] 来进一步扩大感受野。
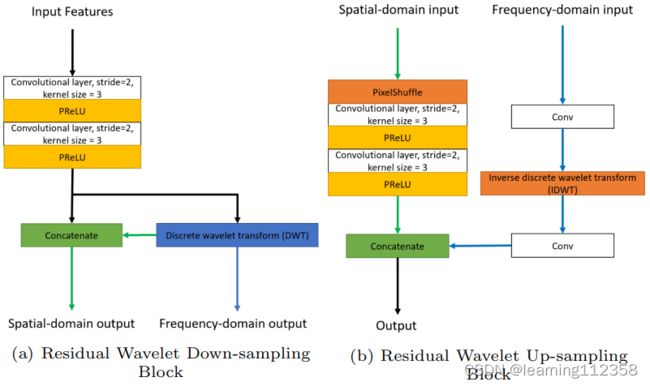
图 4 图 2 中我们的上采样和下采样模块的说明。残差设计使我们的模型能够在频域和空间域中运行,这有助于在上采样和下采样中学习丰富的特征采样块。
3.2 Two-Branch Network
通过将编码器-解码器结构与前面提到的模块相结合,我们的网络在对 RAW 图像进行训练时能够超越最先进的技术。然而,使用多个神经网络来训练不同的低级视觉任务是学习图像 ISP 的更有效方法。原因之一是向不同的网络分支提供不同的数据可以在训练期间提供丰富的信息。最近,双流设计已成功应用于各种计算机视觉任务,尤其是在视频领域。请注意,融合来自不同输入格式(例如,光流和图像帧)的信息可以显着提高网络性能。受 [4,9] 的启发,我们基于双分支架构的思想构建了 AWNet,以通过利用不同的输入来促进不同低级成像任务的网络性能。我们的双分支设计包含两个编码器-解码器模型,即 RAW 模型和去马赛克模型。在这里,RAW 模型在 224 × 224 × 4 RAW 图像上进行训练,去马赛克分支以 448 × 448 × 3 去马赛克图像作为输入。对于 RAW 模型,需要使预测大小和 ground truth 大小保持一致。因此,这个分支更加注重高频细节的恢复。对于它的对应部分,去马赛克分支不需要放大输出大小以保持一致性。相反,这个分支更多地关注去马赛克图像和 RGB 彩色图像之间的颜色映射。我们分别训练这两个网络,并在测试时平均它们的预测。正如预期的那样,通过应用这种架构可以观察到极大的性能提升(参见第 4.3 节中的详细信息)。
3.3 Discrete Wavelet Transform
为了阐述我们设计意见中选择 DWT 的原因,我们介绍了 DWT 与传统池化操作之间的联系。在二维离散小波变换中,有四个滤波器,即 fLL、fLH、fHL 和 fHH,可用于分解图像 [23]。通过与每个滤波器进行卷积,全尺寸图像 x 被分成 4 个子带,即 xLL、xLH、xHL 和 xHH。由于 DWT 的性质,我们可以将 xLL 表示为 (fLL * x) ↓2(xLH、xHL 和 xHH 的表达式类似),其中表示卷积运算,↓2 表示按比例因子 2 进行下采样。根据双正交性质,原图像 x 可以通过 IDWT 恢复,即 x = IDWT(xLL, xLH, xHL, xHH)。因此,DWT的下采样和上采样操作可以认为是无损的。此外,受 [19] 的启发,小波变换可以用来代替通常会导致信息丢失的传统池化操作。我们定义了数学格式来进一步阐述 DWT 和池化操作之间的联系。例如,在 Haar DWT 中,![]() 。因此,2D Haar 小波变换后 xLL 的第 (m, n) 个值可以定义为:
。因此,2D Haar 小波变换后 xLL 的第 (m, n) 个值可以定义为:
![]()
此外,通过将 xp 定义为 p 级平均池化后的特征图,xp 的第 (m, n) 值可以表示为:
![]()
正如我们所看到的方程(2) 与方程 (1)高度相关。通过考虑四个子带,池化操作丢弃了所有的高频分量,只利用了低频部分。因此,传统池化操作中的信息丢失严重。为了缓解这个问题,我们设计了上采样和下采样模块,同时使用小波变换和卷积运算来管理缩放。通过这样做,我们的网络可以从空间和频率信息中学习。我们的实验揭示了这种设计的优越性能(详见第 4.4 节)。
3.4 Loss Function
在本节中,我们将介绍我们的三个损失函数和多尺度损失策略。我们将 I 表示为目标 RGB 图像,将 I~ 表示为我们方法的预测结果。
像素损失。我们采用 Charbonnier [2,40] 损失作为损失函数的近似 L1 项,以更好地处理异常值并提高性能。从之前的实验中,我们意识到 Charbonnier 损失可以有效地提高重建图像的信噪比性能。此外,Charbonnier 损失已应用于多个图像重建任务,并且优于传统的 L2 惩罚 [40]。 Charbonnier 惩罚函数定义为:
![]()
其中我们![]() 设置为 1e - 3。请注意,仅在 RAW 到 RGB 映射上使用像素损失会导致图像模糊,如 [32] 中所述。因此,我们通过添加其他特征损失函数来弥补这个问题。
设置为 1e - 3。请注意,仅在 RAW 到 RGB 映射上使用像素损失会导致图像模糊,如 [32] 中所述。因此,我们通过添加其他特征损失函数来弥补这个问题。
感知损失。为了处理 ZRR 数据集的像素错位问题,我们还采用了感知损失。损失函数定义为:
![]()
其中 F 表示预训练的 VGG-19 网络,I~ 和 I 分别表示预测图像和地面实况。由于未对齐的图像由预训练的 VGG 网络处理,因此得到的下采样特征图在未对齐方面具有较少的变体。因此,在此类特征图上添加 L2 项有利于网络识别全局信息并最小化重建图像与地面实况图像之间的感知差异。
SSIM Loss
我们还采用结构相似性(SSIM)损失 LSSIM [36],旨在通过增强结构相似性指数来重建 RGB 图像。结果图像比没有应用 SSIM 损失的预测更容易被感知。请注意,损失函数可以定义为:
![]()
其中 F 表示计算结构相似度指数的函数。
多尺度损失函数
受 [25] 的启发,我们对来自不同解码器层的输出进行监督,以细化不同大小的重建图像。对于每个尺度级别,我们关注不同的恢复方面,因此应用了不同的损失组合。在我们的 RAW 模型中,有 5 次上采样操作,形成 6 个不同尺度的特征图,从小到大分别命名为 1-6 尺度。同样,去马赛克模型中有 5 种不同的尺度,我们将它们命名为尺度 1-5。
- Scale 1-2 过程特征图被缩小了 16 和 32 倍。与 ground truth 相比,这个比例的特征图包含更少的上下文信息。因此,我们主要关注全局颜色和色调映射。这些层仅由 Charbonnier 损失监督,可以写成:
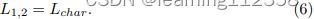
- 尺度 3-4 是在具有 4 和 8 的缩小因子的特征图上计算的;由于这些特征与地面实况的大小相比更小,但包含的信息比尺度 1-2 更丰富,因此我们应用结合了感知损失和 Charbonnier 损失的损失组合来执行全局映射,同时保持感知接受度。这些层的损失函数定义为:
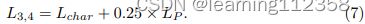
3)在尺度5-6中,特征图的大小接近或等于原始图的大小,因此除了颜色映射之外,我们能够更多地关注图像上下文的恢复。我们在这个级别选择了一个更全面的损失组合,可以表示为: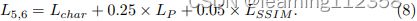
请注意,我们手动选择不同损失项的系数。总损失函数可以表示为:

其中,对于去马赛克模型和 RAW 模型,k 分别等于 5 和 6。
4个实验
我们进行了全面的实验,以证明所提出的方法在 ZRR 数据集的定量和定性比较方面优于基线模型 [14]。
4.1 数据集 为了增强智能手机图像,来自 AIM 2020 Learned Smartphone ISP Challenge [14] 的苏黎世数据集提供了 48043 个 RAW-RGB 图像对(尺寸分别为 448×448×1 和 448×448×3)。训练数据分为 46,839 个图像对用于训练和 1,204 个图像对用于测试。此外,168 个全分辨率图像对用于感知验证。对于数据预处理和增强,我们对输入数据进行归一化并执行垂直和水平翻转。
未完待续
References
- Abdelhamed, A., Afifi, M., Timofte, R., Brown, M.S.: NTIRE 2020 challenge on
real image denoising: dataset, methods and results. In: Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition Workshops, pp. 496–497
(2020) - Bruhn, A., Weickert, J., Schn¨orr, C.: Lucas/Kanade meets Horn/Schunck: combining local and global optic flow methods. Int. J. Comput. Vision 61(3), 211–231
(2005). https://doi.org/10.1023/B:VISI.0000045324.43199.43 - Cao, Y., Xu, J., Lin, S., Wei, F., Hu, H.: GCNet: non-local networks meet squeezeexcitation networks and beyond. In: Proceedings of the IEEE International Conference on Computer Vision Workshops (2019)
- Carreira, J., Zisserman, A.: Quo vadis, action recognition? A new model and the
kinetics dataset. In: Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition, pp. 6299–6308 (2017) - Chen, C., Chen, Q., Xu, J., Koltun, V.: Learning to see in the dark. In: Proceedings
of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3291–
3300 (2018) - Chen, L.C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder-decoder with
atrous separable convolution for semantic image segmentation. In: Proceedings of
the IEEE European Conference on Computer Vision, pp. 801–818 (2018) - Cheng, D., Price, B., Cohen, S., Brown, M.S.: Beyond white: ground truth colors for
color constancy correction. In: Proceedings of the IEEE International Conference
on Computer Vision, pp. 298–306 (2015) - Dabov, K., Foi, A., Katkovnik, V., Egiazarian, K.: Image denoising by sparse 3-
D transform-domain collaborative filtering. IEEE Trans. Image Process. 16(8),
2080–2095 (2007) - Feichtenhofer, C., Pinz, A., Zisserman, A.: Convolutional two-stream network
fusion for video action recognition. In: Proceedings of the IEEE European Conference on Computer Vision, pp. 1933–1941 (2016) - Gharbi, M., Chaurasia, G., Paris, S., Durand, F.: Deep joint demosaicking and
denoising. ACM Trans. Graph. (TOG) 35(6), 1–12 (2016) - He, B., Wang, C., Shi, B., Duan, L.Y.: Mop moire patterns using MopNet. In:
Proceedings of the IEEE International Conference on Computer Vision, pp. 2424–
2432 (2019) - Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the
IEEE Conference on Computer Vision and Pattern Recognition, pp. 7132–7141
(2018) - Ignatov, A., Timofte, R., et al.: AIM 2020 challenge on learned image signal processing pipeline. In: Bartoli, A., Fusiello, A. (eds.) ECCV 2020. LNCS, vol. 12537,
pp. 152–170. Springer, Cham (2020) - Ignatov, A., Van Gool, L., Timofte, R.: Replacing mobile camera ISP with a single
deep learning model. In: Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition Workshops, pp. 536–537 (2020) - Kim, J., Kwon Lee, J., Mu Lee, K.: Accurate image super-resolution using very
deep convolutional networks. In: Proceedings of the IEEE Conference on Computer
Vision and Pattern Recognition, pp. 1646–1654 (2016) - Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint
arXiv:1412.6980 (2014) - Kwok, N.M., Shi, H., Ha, Q.P., Fang, G., Chen, S., Jia, X.: Simultaneous image
color correction and enhancement using particle swarm optimization. Eng. Appl.
Artif. Intell. 26(10), 2356–2371 (2013) - Ledig, C., et al.: Photo-realistic single image super-resolution using a generative
adversarial network. In: Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition, pp. 4681–4690 (2017) - Liu, P., Zhang, H., Zhang, K., Lin, L., Zuo, W.: Multi-level wavelet-CNN for image
restoration. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 773–782 (2018) - Liu, X., Ma, Y., Shi, Z., Chen, J.: GridDehazeNet: attention-based multi-scale
network for image dehazing. In: Proceedings of the IEEE International Conference
on Computer Vision, pp. 7314–7323 (2019) - Lowe, D.G.: Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 60(2), 91–110 (2004). https://doi.org/10.1023/B:VISI.0000029664.99615.
94 - Lugmayr, A., Danelljan, M., Timofte, R.: NTIRE 2020 challenge on real-world
image super-resolution: methods and results. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 494–495 (2020) - Mallat, S.G.: A theory for multiresolution signal decomposition: the wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell. 11(7), 674–693 (1989)
- Mei, K., Li, J., Zhang, J., Wu, H., Li, J., Huang, R.: Higher-resolution network
for image demosaicing and enhancing. In: Proceedings of the IEEE International
Conference on Computer Vision Workshops, pp. 3441–3448. IEEE (2019) - Qian, R., Tan, R.T., Yang, W., Su, J., Liu, J.: Attentive generative adversarial
network for raindrop removal from a single image. In: Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition, pp. 2482–2491 (2018) - Rana, A., Singh, P., Valenzise, G., Dufaux, F., Komodakis, N., Smolic, A.: Deep
tone mapping operator for high dynamic range images. IEEE Trans. Image Process.
29, 1285–1298 (2019) - Ratnasingam, S.: Deep camera: a fully convolutional neural network for image signal processing. In: Proceedings of the IEEE International Conference on Computer
Vision Workshops (2019) - Rizzi, A., Gatta, C., Marini, D.: A new algorithm for unsupervised global and local
color correction. Pattern Recogn. Lett. 24(11), 1663–1677 (2003) - Schwartz, E., Giryes, R., Bronstein, A.M.: DeepISP: toward learning an end-to-end
image processing pipeline. IEEE Trans. Image Process. 28(2), 912–923 (2018) - Tao, X., Gao, H., Shen, X., Wang, J., Jia, J.: Scale-recurrent network for deep
image deblurring. In: Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition, pp. 8174–8182 (2018) - Timofte, R., Rothe, R., Van Gool, L.: Seven ways to improve example-based single
image super resolution. In: Proceedings of the IEEE Conference on Computer
Vision and Pattern Recognition, pp. 1865–1873 (2016) - Uhm, K.H., Kim, S.W., Ji, S.W., Cho, S.J., Hong, J.P., Ko, S.J.: W-Net: twostage U-Net with misaligned data for raw-to-RGB mapping. In: Proceedings of the
IEEE International Conference on Computer Vision Workshop, pp. 3636–3642.
IEEE (2019) - Vedaldi, A., Fulkerson, B.: VLFeat: an open and portable library of computer
vision algorithms. In: Proceedings of the 18th ACM International Conference on
Multimedia, pp. 1469–1472 (2010) - Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,
pp. 7794–7803 (2018) - Wang, X., Chan, K.C., Yu, K., Dong, C., Change Loy, C.: EDVR: video restoration
with enhanced deformable convolutional networks. In: Proceedings of the IEEE
Conference on Computer Vision and Pattern Recognition Workshops (2019) - Wang, Z., Simoncelli, E.P., Bovik, A.C.: Multiscale structural similarity for image
quality assessment. In: The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, vol. 2, pp. 1398–1402. IEEE (2003) - Xu, X., Ma, Y., Sun, W.: Towards real scene super-resolution with raw images. In:
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,
pp. 1723–1731 (2019) - Yuan, L., Sun, J.: Automatic exposure correction of consumer photographs. In:
Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012.
LNCS, vol. 7575, pp. 771–785. Springer, Heidelberg (2012). https://doi.org/10.
1007/978-3-642-33765-9 55 - Zhang, K., Zuo, W., Chen, Y., Meng, D., Zhang, L.: Beyond a Gaussian denoiser:
residual learning of deep CNN for image denoising. IEEE Trans. Image Process.
26(7), 3142–3155 (2017) - Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., Fu, Y.: Image super-resolution
using very deep residual channel attention networks. In: Proceedings of the IEEE
European Conference on Computer Vision. pp. 286–301 (2018) - Zhang, Y., Tian, Y., Kong, Y., Zhong, B., Fu, Y.: Residual dense network for image
super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and
Pattern Recognition, pp. 2472–2481 (2018) - Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation
using cycle-consistent adversarial networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2223–2232 (2017)