【多目标轨迹预测】M2I: From Factored Marginal Trajectory Prediction to Interactive Prediction(翻译+笔记)
目录
阅读总结
摘要
1 简介
2 相关工作:
2.1 交互式轨迹预测
2.2.条件轨迹预测
3 方法
3.1 问题公式
3.2 模型概括
3.3.关系预测器
3.4.边缘轨迹预测器
3.5.条件轨迹预测器
3.6.样品选择器
3.7 推理
阅读总结
关键词:多目标轨迹预测,条件概率,边缘概率,Goal, influencer-reactor
摘要
多个智能体联合预测场景兼容问题没有解决,主要是因为随着智能体数量的增加,相关函数的预测空间呈指数级增长。这项工作利用交互智能体之间的潜在关系,将联合预测问题分解为边缘预测问题。将智能体分为influencers和reactors,然后分别用边缘预测模型和条件预测模型进行预测,来自交互智能体的预测被组合并根据它们的联合可能性进行选择。
1 简介
动机:当前工作注重单目标轨迹预测,不考虑未来的交互问题,未来轨迹可能会相撞。多目标轨迹预测难点在于未来目标候选点随着智能体数量的增加呈指数级增长。
方法:生成符合场景的轨迹的一种计算效率更高的替代方法是通过修剪碰撞的边缘预测样本来后处理边缘预测样本。然而,这种临时方法未能考虑到未来潜在的智能体交互,并且可能忽略其他难以通过启发式方法修剪的冲突。交互行为很难被边缘预测器捕获,因为它不知道场景中其他智能体的未来行为。
工作: M2I利用边际和条件轨迹预测器通过将联合分布近似为边际分布和条件分布的乘积来有效地预测场景兼容的多智能体轨迹。首先,假设两种类型的智能体:influencer和reactor,后者行为受前者影响。然后,利用标准的边际预测器为influencer生成预测样本,并利用条件预测器为influencer的未来轨迹推出反应器的未来轨迹。然后根据每个influencer的预测预测reactor的反应行为。
贡献:首先,文章提出了一个简单但有效的 M2I 框架,它利用边际和条件预测器来生成准确且符合场景的多智能体轨迹。该框架不假设特定的预测器结构,允许它被广泛的主干预测模型采用。其次,我们提出了一种关系预测器,它可以推断交互代理之间的高级关系,以解耦预测空间。最后,我们使用目标条件预测模型展示我们的框架。
2 相关工作:
方法一:处理多模态问题
[5, 35] 提出了将行为预测输出为高斯混合模型 (GMM) 的模型,其中每个混合分量代表一个模态;
生成模型(例如生成对抗模型 (GAN) [16, 18, 47] 和(条件)变分自动编码器 (VAE) [26, 29, 35, 44])不是对预测分布进行参数化,而是生成轨迹样本来近似分布空间;
所存在的问题:这些生成模型存在样本效率低下的问题,并且需要许多样本来涵盖不同的驾驶场景 [18]。
方法二:先定意图,再预测轨迹
目标型 [11、13、15、29、34、46]、要遵循的车道 [21 , 37] 和机动动作 [8, 9, 19, 24]
此类模型在流行轨迹预测基准(如 Argoverse [6] 和 Waymo Open Motion Dataset [10])中为单个代理预测准确轨迹方面取得了巨大成功。
本文我们选择采用无锚的基于目标的预测器[15]。
2.1 交互式轨迹预测
问题:多智能体轨迹预测难点在于复杂的交互关系难以建模。
方法1类:早期利用手工制作的交互模型,例如社会力量 [17] 和能量函数 [43]。
方法1类问题:这些手工制作的函数需要手动调整,并且难以对高度复杂和非线性的交互进行建模。
方法2类:基于学习的方法
[2, 16] 利用社会池机制来捕捉来自邻居代理的社会影响,以预测拥挤场景中的交互式行人轨迹;
[3, 4, 31, 35] 建立一个图神经网络(GNN)来学习代理到代理的交互;
[22,27,32,33,38]利用注attention和transformer机制来学习多智能体交互行为。
方法2类问题:没说
M2I方法特点:构建一个稀疏的图神经网络,有向边代表智能体之间的依赖关系,采用influencer-reactor的关系更利于解释。M2I 通过边缘和条件预测器预测符合场景的轨迹,具有更好的计算效率。另外,M2I利用influencer智能体的未来轨迹来预测reactor的条件行为,以提高准确性。这也允许 M2I 通过改变influencer轨迹在模拟应用中用于反事实推理。
边缘预测:
传统的方法:通过利用辅助碰撞损失 [27] 或基于逆强化学习框架 [40] 的批评器,该框架不鼓励碰撞轨迹。
M2I:明确influencer-reactor的关系。参考预测场景兼容轨迹之前预测交互类型的 [23, 25] ,进一步利用解耦关系的结构和低级影响者轨迹的影响,不仅是提供高级交互标签作为轨迹预测器的输入。
2.2.条件轨迹预测
条件预测方法通过预测以另一个智能体的未来轨迹为条件的轨迹来研究未来智能体轨迹之间的相关性[20,35,39]。
方法限制:通常依赖于自动驾驶汽车或机器人的未来轨迹,其未来计划对预测者来说是已知的。
M2I超越了要预测的另一个智能体的未来轨迹。尽管条件智能体的预测错误,我们表明我们的模型优于不考虑交互相关性的边际预测器。
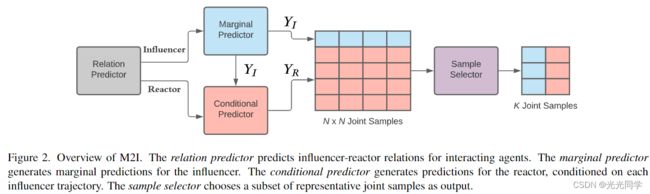
3 方法
3.1 问题公式
给定已经观察到的状态,M:地图信息;S:场景中智能体所有的状态。目标是,预测未来T步长内智能体Y的状态。M2I假设交互智能体在给定场景中预先标记,在常用数据集中可用[10.45].由于 Y 上的分布是多个智能体的联合分布,为了方便计算,降低计算复杂度,我们将其近似为边际分布和条件分布上的分解:
![]()
首先将交互智能体指定为影响者 YI 和反应者 YR,并将联合分布解耦为影响者上的边缘分布和反应者上的条件分布。在两个智能体不交互的情况下,可以分解为两个边缘分布。

智能体之间相互独立,不考虑其他智能体的情况。
涉及两个以上交互式智能体的场景,我们的方法可以通过预测所有智能体的关系并将多个边缘和条件分布链接在一起来修改,假设没有循环影响:

其中 N 是总交互智能体的数量, 是关系预测器预测的智能体 i 的影响者代理集合。我们参考附录 C 中的多智能体关系预测示例。
是关系预测器预测的智能体 i 的影响者代理集合。我们参考附录 C 中的多智能体关系预测示例。
3.2 模型概括
尽管 M2I 包括三个不同的学习模型,但它们共享相同的编码器-解码器结构并采用相同的上下文编码器来学习上下文信息,如图 3 所示。条件预测器采用包括影响器的增强场景上下文输入- 学习反应堆反应行为的真实轨迹。
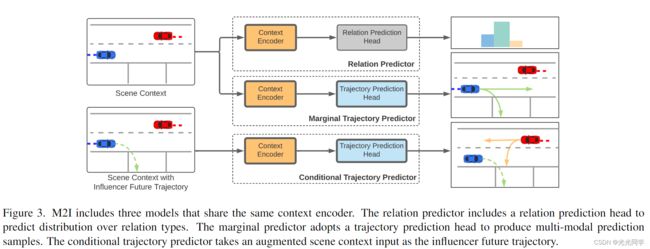
3.3.关系预测器
用关系预测器来预测两个智能体谁是influencer,谁是reactor。类似[23],假设三种类关系:PASS、YIELD 和 NONE,使用以下启发式确定关系。给定两个具有 T 步长的智能体未来轨迹 y1 和 y2,我们首先计算两个智能体之间的最近空间距离,以确定是否存在通过率关系:
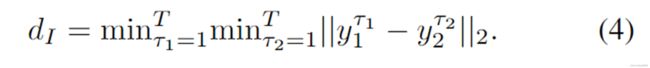
如果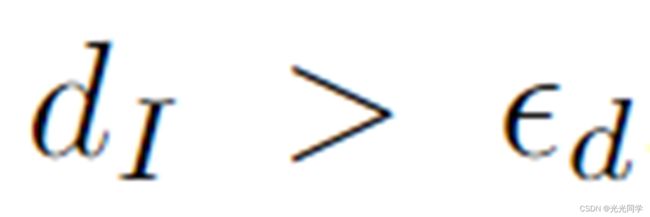 ,这是一个取决于智能体大小的动态阈值,智能体永远不会彼此靠得太近,因此我们将关系类型标记为无。否则,我们从每个智能体获得它们到达最近空间距离的时间步长,例如:
,这是一个取决于智能体大小的动态阈值,智能体永远不会彼此靠得太近,因此我们将关系类型标记为无。否则,我们从每个智能体获得它们到达最近空间距离的时间步长,例如:

当 t1 > t2 时,我们定义智能体1 屈服于智能体 2,因为智能体1 需要更长的时间才能到达交互点。否则,我们定义智能体 1 通过智能体 2。
在用三种交互类型标记训练数据后,我们提出了一个基于编码器-解码器的模型,将输入场景分类为这些类型的分布。如图 3 所示,关系预测器模型由一个上下文编码器组成,该编码器将上下文信息(包括交互代理和附近代理的观察状态和地图坐标)提取到隐藏向量中,以及一个关系预测头输出每种关系类型的概率。有大量关于从交通场景中学习上下文信息的文献,例如 [7, 12, 14, 28]。由于其模块化设计,M2I可以利用任何现有的上下文编码器,在第 4 节中对M2I的选择进行详细解释。关系预测器由一层多层感知器(MLP)组成,用于输出每个逻辑关系的概率。
训练关系预测器的损失定义为:
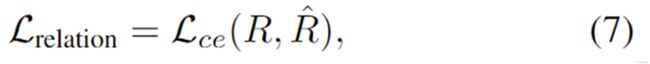
其中 Lce 是交叉熵损失,R 是预测的关系分布,^R 是真实关系。
给定预测的关系,将每个智能体分配为影响者或反应者。如果关系不存在,则两个智能体都是影响者,因此他们未来的行为彼此独立,如等式 (2)。如果关系是智能体 1 屈服于智能体 2,我们将智能体1 指定为反应者,将智能体 2 指定为影响者。如果关系是智能体 1 通过智能体 2,我们翻转影响者和反应器标签。
3.4.边缘轨迹预测器
我们提出了一种基于编码器-解码器结构的影响者边缘轨迹预测器,如图 3 所示,在轨迹预测文献中被广泛采用 [10,14,46]。预测器使用与3.3节中相同的上下文编码器。并使用轨迹预测头生成一组与置信度分数相关的预测样本。尽管我们的方法可以采用任意预测头,但我们专注于基于无锚定目标的预测头,因为它在轨迹预测基准中表现出色,并在第 4节中详细解释。
3.5.条件轨迹预测器
条件轨迹预测器类似于边缘预测器,不同之处在于它采用包括影响者未来轨迹的增强场景上下文,如图 3 所示。这允许提取和学习影响者未来轨迹的特征与其他上下文特征相同。轨迹预测头使用编码的场景特征,它与边缘预测器共享相同的模型,以产生多模态预测样本。
3.6.样品选择器
给定影响者和反应器的预测关系,我们使用边际预测器预测影响者的 N 个具有置信度分数(或概率)的样本,并且对于每个影响者样本,我们使用条件预测器预测反应器的 N 个样本。因此,联合样本的数量为  ,每个联合样本的概率是边际概率和条件概率的乘积。我们进一步将联合样本的大小减少到 K,因为评估下游任务(如风险评估)的每个预测样本可能会很昂贵 [41]。在 M2I 中,我们从个候选中选择具有最高联合似然度的 K 个样本。
,每个联合样本的概率是边际概率和条件概率的乘积。我们进一步将联合样本的大小减少到 K,因为评估下游任务(如风险评估)的每个预测样本可能会很昂贵 [41]。在 M2I 中,我们从个候选中选择具有最高联合似然度的 K 个样本。
3.7 推理
推理时,按照图 2 所示的过程生成联合预测,首先,调用关系预测器并选择概率最高的交互关系。其次,对于预测的影响者,我们使用边缘预测器生成 N 个轨迹样本。第三,对于每个影响者样本,我们使用条件预测器为预测的反应器生成 N 个样本。第四,我们使用样本选择器从 个候选者中选择 K 个具有代表性的样本。在预测关系为零的情况下,我们使用两个代理的边际预测器来获得 个轨迹对,并遵循相同的样本选择步骤。