手把手教你:个人信贷违约预测模型
系列文章
- 第八章、手把手教你:基于LSTM的股票预测系统
- 第七章、手把手教你:基于深度残差网络(ResNet)的水果分类识别系统
- 第六章、手把手教你:人脸识别的视频打码
目录
- 系列文章
- 一、项目简介
- 二、数据集介绍
- 三、环境安装
- 四、代码介绍
-
- 1.数据预处理
- 2.数据可视化探索
-
- 2.1 各特征可视化
- 2.2 贷款金额的情况
- 2.3 贷款金额与分期付款关系
- 2.4 是否还完贷款
- 3.构建模型并训练
-
- 3.1 朴素贝叶斯
- 3.2 随机森林
- 3.3 逻辑回归
- 4.模型对比
- 五、代码下载地址
一、项目简介
本文主要介绍如何使用python搭建:基于三个经典机器学习算法的个贷违约预测模型。
项目只是用个贷违约预测作为抛砖引玉,其中包含了使用模型进行预测的相关代码。主要功能如下:
- 数据预处理。
- 模型构建及训练,三大模型:朴素贝叶斯、随机森林、逻辑回归。
- 预测违约情况并进行模型评估。
如各位童鞋需要更换训练数据,完全可以根据源码将图像和标注文件更换即可直接运行。
博主也参考过机器学习模型构建的文章,但大多是理论大于方法。很多同学肯定对原理不需要过多了解,只需要搭建出一个预测系统即可。
本文只会告诉你如何快速搭建一个基于个贷违约预测模型并运行,原理的东西可以参考其他博主。
也正是因为我发现网上大多的帖子只是针对原理进行介绍,功能实现的相对很少。
如果您有以上想法,那就找对地方了!
不多废话,直接进入正题!
二、数据集介绍
- 我们将使用个人对个人的借贷网站——借贷俱乐部上面的借贷数据。借贷俱乐部提供关于成功的贷款(被借贷俱乐部和联合贷款人通过的贷款)和失败的贷款(被借贷俱乐部和联合贷款人拒绝的贷款,款项并没有转手)的详尽历史数据。
三、环境安装
本项目开发IDE使用的是:jupyter notebook,大家可以直接csdn搜索安装指南非常多,这里就不再赘述。
因为本项目基于TensorFlow因此需要以下环境:
- pandas
- scikit-learn
- numpy
- matplotlib
四、代码介绍
- 环境安装好后就可以开始愉快的执行代码了。由于代码众多,博客中就不放入最终代码了,有需要的童鞋可以在【代码下载地址】下载所有代码。
1.数据预处理
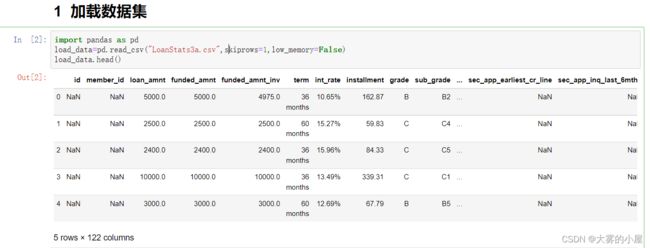
- 首先我们将读入的数据做一些特征选择和数据清洗。
- 字段信息:
- loan_amnt:贷款
- term:账期
- int_rate:国际汇率
- installment:分期付款
- loan_status:贷款状况
- 等等
load_data_clean=load_data[['loan_amnt','funded_amnt','term','int_rate',
'installment','emp_length','dti',
'annual_inc','total_pymnt',
'total_pymnt_inv',
'total_rec_int','loan_status']]
del load_data
#注意输入的变量必须是量化的值,不能是字符串
#数据清洗主要做数据类型的转换,以及处理缺失数据
#采用针对矩阵的元素的函数实现
import re #正则表达式的包
def extract_number(string):
num=re.findall('\d+',str(string))
if len(num)>0:
return int(num[0])
else:
return 0;
load_data_clean.emp_length=load_data_clean.emp_length.apply(extract_number)
load_data_clean.head()
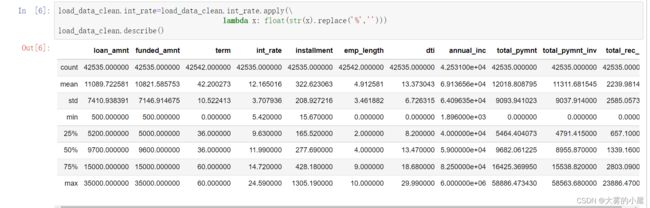
- 处理完后数据情况:
2.数据可视化探索
2.1 各特征可视化

- 可以看到annual_inc特征波动比较大。
2.2 贷款金额的情况

- 可以看到大部分人的贷款金额在:5k-15k这个区间范围内。
2.3 贷款金额与分期付款关系
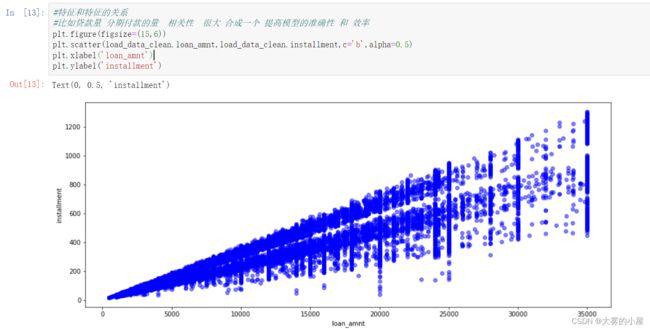
- 这里将:loan_amnt:贷款金额,installment:分期付款金额进行关联分析。
- 可以看到贷款与分期付款 ,相关性较强,我们后续可以考虑将这2个特征合成一个,以提高模型的准确性和效率。
2.4 是否还完贷款

- 可以看到数据中是否足额按时还完贷款所占的比率。
3.构建模型并训练
- 完成上述数据处理后我们构建三个不同的模型进行训练并预测。
3.1 朴素贝叶斯
- 构建模型并训练:
gnb_model=GaussianNB()
gnb_model.fit(X_train,Y_train)
# 训练集
#模型预测可以给出概率的结果
train_probs=gnb_model.predict_proba(X_train)
#返回概率最高的结果
train_predict=gnb_model.predict(X_train)
# 测试集
#模型预测可以给出概率的结果
test_probs=gnb_model.predict_proba(X_test)
#返回概率最高的结果
test_predict=gnb_model.predict(X_test)
- 模型预测得分:

- 这里解释一下,模型得分的情况。可以看到训练集accuracy_score(准确率)得分:0.88。测试集accuracy_score(准确率)得分:0.87。
- 下方Classification report,是2种不同类别的混淆矩阵,分别输出了每个类别的精确率、召回率和F1-score的得分。
- ROC曲线如下:

3.2 随机森林
- 构建模型并训练:
from sklearn import datasets,svm,metrics,model_selection,preprocessing
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# 实例化随机森林
rfc=RandomForestClassifier()
# 调参参数设置
rf_param_grid = {'n_estimators':[100,200,500], 'min_samples_split':[2,3,5,10],
'min_samples_leaf':[4,6,10], 'max_depth':[10,50]}
rf_grid = model_selection.GridSearchCV(rfc, rf_param_grid, cv=5, n_jobs=12, verbose=1, scoring='accuracy')
# 训练模型
rf_grid.fit(X_train, Y_train)
- 模型预测得分:
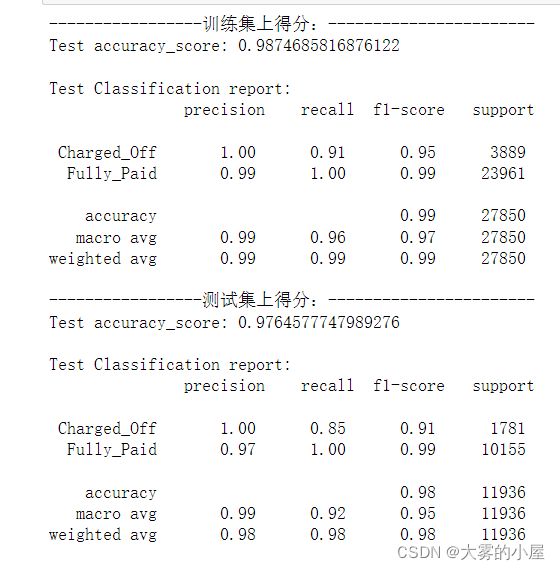
- 同理,随机森林的训练集准确率得分:0.987。测试集准确率得分:0.976
- 上述2个模型的ROC曲线:

3.3 逻辑回归
- 逻辑回归其实是一个分类算法,因此我们也可以用在预测用户是否可能违约上。
- 模型构建及训练:
from sklearn.linear_model import LogisticRegression
#构建模型参数
LGR = LogisticRegression(penalty='l2', multi_class='multinomial',solver="newton-cg",n_jobs=12)
# 训练模型
LGR.fit(X_train, Y_train)
- 模型预测得分:

4.模型对比

- 因为我们知道ROC曲线所占的面积越大,说明模型的效果会越好,根据上图,红色线条的模型效果是最好的,因此:逻辑回归的模型在这个数据集中应用的效果是最佳的。
五、代码下载地址
由于项目代码量和数据集较大,感兴趣的同学可以直接下载代码,使用过程中如遇到任何问题可以在评论区进行评论,我都会一一解答。
代码下载:
- 【代码分享】手把手教你:个人信贷违约预测模型