我凭什么相信你?面向可解释的机器学习:What, why, what for and how?
我凭什么相信你?面向可解释的机器学习:What, why, what for and how?
- 1. 引言
-
- 1.1 可解释性
- 1.2 公平性
- 1.3 隐私性
- 1.4 鲁棒性
- 2. 什么是可解释性?为什么需要可解释性?可解释的目的是什么?(What, why and what for?)
-
- 2.1 什么是可解释性?(what)
- 2.2 为什么需要可解释性?(why)
- 2.3 可解释的目的是什么?(what for)
- 3. 如何实现可解释性?
-
- 3.1 置换特征重要性(Permutation Feature Importance)
- 3.2 LIME
- 3.3 SHAP
- 4. 感想和展望
本文摘自我的知乎原文,全文约14000字,建议阅读时长35分钟。
在第一章中,本文将介绍机器学习的可信性(Trustworthiness),包含可解释性(Explainability)、公平性(Fairness)、隐私性(Privacy)和鲁棒性(Robustness)。其中可解释性是最重要的,因为它在一定程度上可以促进后三者。因此,本文重点关注机器学习的可解释性。
在第二章中,本文将详细阐述什么是可解释性(what),为什么需要可解释性(why),以及可解释的目的是什么(what for)。
在第三章中,本文将介绍三种代表性的实现可解释性的方法(how),包括置换特征重要性、LIME和SHAP。
在最后一章,本文将展望可信/可解释机器学习领域。
1. 引言
近年来随着深度学习技术的快速发展,我们可以看到机器学习系统已经渗透在我们生活的各个方面:
- 图像识别:手机上的人脸解锁、支付宝的人脸支付等都已经非常成熟。
- 产品推荐:机器学习模型通过分析我们的历史交易行为,为我们推荐可能会心仪的产品。
- 自动/无人驾驶:百度、京东、特斯拉等互联网公司都有涉足,其中京东自研的无人车可以实现快递、外卖等货物的配送。
- 自然语言处理:各种翻译软件本质上都是基于神经网络强大的学习能力;我们在微信上可以通过输入一段语音将它转成文字。
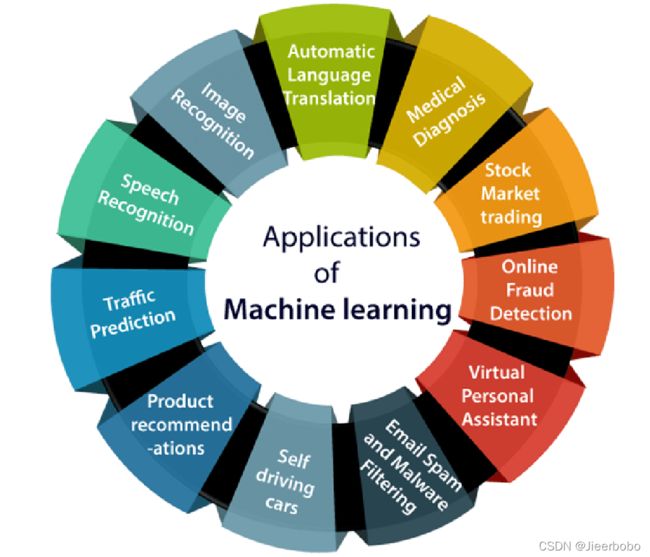
通过这些例子,我们可能会感叹于机器学习技术的强大,因为它确确实实在改变着我们的生活。但同时,我们也会有疑问,机器学习模型真的是无所不能的吗?更具体一点,它们真的足够可信吗?想要回答这个问题,我们首先要知道在可信机器学习领域,什么组成了可信性。
可信性包含了很多方面:可解释性、公平性、隐私性、鲁棒性、准确率、可审计性等等[1]。
本文主要关注前四个方面,因为它们相对来说是更加重要的。
1.1 可解释性
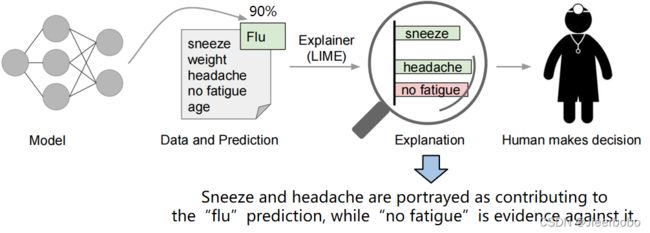
我们考虑一个辅助医生预测流感的机器学习模型(如下图),当我们把病人的数据输入到模型中,它会输出一个结果,它告诉医生这个病人得流感了,因为输出的概率是90%,医生可能并不会相信,因为模型只给了一个硬生生的数字,但如果这个模型给出判断理由,即这个病人打喷嚏和头疼的症状促使模型把他预测成得流感,那医生可能会选择相信这个模型,因为模型的判断是有理有据的,并且符合他的经验。因此可解释性能够提升我们对机器学习模型的理解能力和接受程度。然而不幸的是,尽管现在大多数深度神经网络在各类竞赛上刷新准确率,它对于我们人类来说仍然是一个黑盒子,这在一定程度上也限制了它在实际中的应用。
1.2 公平性
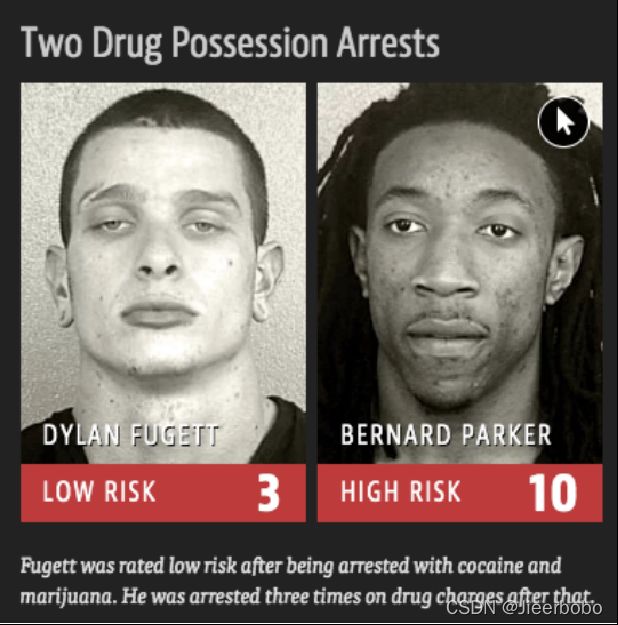
机器学习模型是数据驱动的,也就是我们给模型足够多的数据,模型能给我们拟合出一个非常理想的决策边界,但在这个过程中模型可能会学习到一些具有偏见的内容,从而输出违反伦理道德的决策。一个典型的案例是ProPublica组织[2]发现美国法院所使用的软件存在非常严重的歧视问题,具体来说,黑人被告远比白人被告更有可能被错误地判定为具有较高的累犯风险,而白人被告比黑人被告更有可能被错误地标记为低风险。因此,关注机器学习模型的公平性问题也是必不可少的。
1.3 隐私性
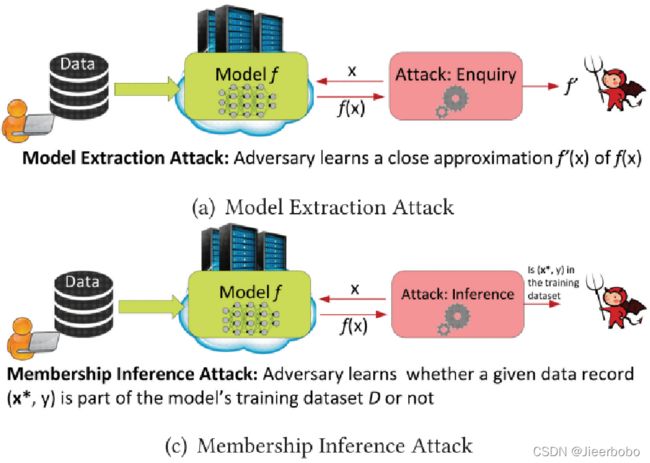
机器学习的隐私问题是被广泛关注和研究的,并且已经有相应的法律规定,比如中华人民共和国网络安全法第42条规定“网络运营者不得泄露、篡改、毁损其收集的个人信息;未经被收集者同意,不得向他人提供个人信息”。现在有用安全多方计算来保护数据隐私,联邦学习的提出的初心之一也是保护数据隐私。尽管有各种保护方法提出,攻击手段也同样更加先进了。比如联邦学习刚提出没多久,17年的SP[3](安全领域的四大顶会之一)就在该场景下,通过只获取用户上传给服务端的参数就推理出某条数据是否属于某用户的数据集,这种攻击手段叫作成员推理攻击。其次还有模型提取攻击,即敌手可以推理出整个模型的架构。**因此机器学习模型仍然很容易泄露自己的架构和训练数据,从而泄露用户隐私,导致用户不敢信任模型。**下图[4]展示的是模型提取攻击和成员推理攻击。
1.4 鲁棒性
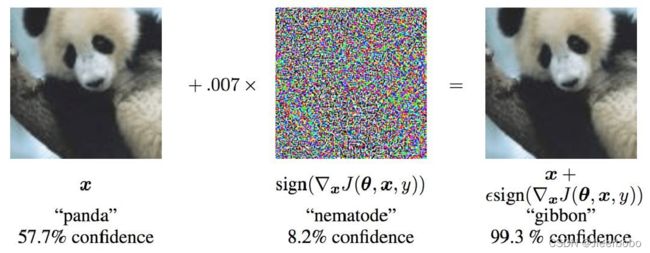
破坏机器学习模型的鲁棒性,最典型的例子就是对抗攻击,我们可以通过向图片里添加一个很小的噪声,就能使模型把大熊猫认成长臂猿。此外,把图片进行一个细微的转动,模型就能把秃鹰认成猩猩。因此尽管深度神经网络在众多领域获得了前所未有的成就,它依然很容易被欺骗,并且这样的欺骗在我们看来是不可思议的。

我们回过头来再看一下这个问题,机器学习模型真的足够可信嘛?我想答案应该很明显,Absolutely not!其实可信性是如今机器学习在实际应用中面临的主要障碍之一。现在有很多的法律法规都在关注机器学习的可信性,比如GDPR定义了解释权,就是说机器学习模型需要对其输出给出相应的解释,不然我们有权利不使用它。
- National Academies Workshop
- Promoting the Use of Trustworthy Artificial Intelligence in the Federal Government
- EU Ethics Guidelines for Trustworthy Artificial Intelligent
- FEAT Principles
- The European Union General Data protection Regulation (GDPR)
我们可以看到可信性在机器学习领域受到越来越多的重视,刚才我从四个方面来讲解了可信性,其中我觉得可解释性是最重要的,因为可解释性可以增强公平性、隐私性和鲁棒性。具体来说,可解释性能够让我们了解一个模型它到底在做什么,它依靠什么来做出决策的,这样我们就能避免它学到有偏见的内容,从而保证公平性。同时,我们也能够知道它为什么会被对抗样本所欺骗,从而提升鲁棒性。此外,通过可解释性工具,我们可以知道什么特征对模型来说是重要的,并对它们进行重点保护,从而保证了隐私性。因此,本文重点关注机器学习的可解释性。
2. 什么是可解释性?为什么需要可解释性?可解释的目的是什么?(What, why and what for?)
2.1 什么是可解释性?(what)
可解释性它是一个比较主观的概念,并且它在不同的领域应该会有不同的含义,因此研究人员对其定义还未达成共识。在人工智能领域,我引用了2020年发在information fusion上的综述里的定义[5]。
“Given an audience, an explainable AI is one that produces details or reasons to make its functioning clear or easy to understand.”
给定一个受众,可解释的人工智能是指能够提供细节或理由,使其功能清晰或易于理解的人工智能。
这里为什么要强调给定一个受众呢,因为对于不同人来说,用来解释的细节和原因是不一样的。比如我要向大家讲解比特币,如果受众是网络空间安全专业的学生,那么我可能会讲底层的区块链技术;那如果受众是我奶奶,我可能就需要编一个小故事,用比喻的手段来跟她讲解。其实可解释性跟信任有点相似,都是仁者见仁,智者见智的。
2.2 为什么需要可解释性?(why)
***本章节参考台湾大学李宏毅老师的可解释机器学习的课程,非常推荐!![6]
- 正确的答案 ≠ 智能:一个本质原因是就算机器学习如今能够在各个领域大展身手,得到正确的答案,但这并不代表它足够聪明,足够智能。举一个例子,过去有一匹马很聪明,所以大家叫他神马汉斯,那这个神马汉斯可以做什么事情呢?它可以做数学题。举例来说,你问它根号9等于多少,它就会用自己的马蹄去跺3下地板,然后停下来代表它已经计算出答案,然后旁边的人就会欢呼。底下这张图展示的就是神马汉斯,然后周围一堆人看它解数学题。后来有人就很怀疑,为什么汉斯可以解数学题呢,它只是一匹马。后来有人发现说,只要没有人围观的时候,汉斯就会答不出数学题。没有人看它的时候,你问它数学题,它就会不断地敲打马蹄,不知道什么时候停下来。所以它其实只是侦测到旁边人类微妙的情感变化,知道它什么时候要停下跺马蹄,它就可以有胡萝卜吃,它并不是真的学会做数学题。今天我们看到的种种人工智能的应用,有没有可能跟神马汉斯是一样的状况?

- 利用可解释可以改善机器学习模型:今天在使用深度学习技术的时候,往往状况是这个样子的。如下图[7],某个人说:“这个就是你的机器学习系统吗?”另一个人说:“是啊,我就是把数据丢进行,里面有很多矩阵的相乘,接下来就会跑出我的结果。”“如果结果不符合预期的话,怎么办呢?”“那就把这堆线性代数打乱一下,看看结果会不会变好。”没有做过深度学习的人可能会大吃一惊,就会觉得哇这样怎么可以呢。但实际上,今天我们要改进深度学习模型,我们通常需要去调一下参数,去试不同的架构,看看它work不work,我们其实根本不知道自己在做什么。但我们期待,也许未来当我们知道深度学习模型它为什么会有bug,为什么会不work,也许我们会有更好的方法,更有效率的方法来改进我们的模型。

- 在安全系数很高的场景中,需要绝对可信的决策:在一些安全系数很高的场景,我们需要绝对可信的决策。比如自动驾驶汽车,汽车的每一次刹车和加速,我们都需要知道它为什么会做出这样的决策,不然就可能有生命危险。
- 人类的好奇心和学习能力[8]:这一点体现在人文方面。举个例子,当我们在使用电脑的时候,对于大多数人来说,我们并不需要理解电脑是如何工作的,但突然有一天它蓝屏了,死机了,我们会好奇它为什么会出现这样的状况。所以人类的好奇心和学习能力也驱动着我们需要可解释性。
2.3 可解释的目的是什么?(what for)
可解释机器学习的终极目标是什么?在这里,我非常赞同李宏毅老师的一个观点。
“很多人对可解释机器学习有个误解,他们觉得一个好的解释就是要告诉我们整个模型在做什么,我们要了解模型的一切。但是你想想这件事情真的有必要吗?我们今天说深度神经网络是一个黑盒子,所以我们不能相信它。但你想想看,世界上有那么多黑盒子正在我们的身边,**人脑不也是黑盒子吗?我们其实也并不完全知道人脑的运作原理,但是我们可以相信另一个人做出的决定。**那么问题来了,人脑是一个黑盒子,你可以相信人脑做出的决定,为什么对于同样是黑盒子的深度神经网络,你没有办法相信呢?我觉得对于人而言,也许有一种东西能不能让我们放心,能不能让我们接受,理由是非常重要的。”
以下是一个跟机器学习完全无关的心理学实验,这个实验跟打印机有关。在哈佛大学的图书馆里,打印机前面会排很长的队,这个时候如果有一个人跟他前面的人说:“拜托,请让我先印,我就印5页而已。”结果是有百分之60的人会接受。如果我们把刚才的话稍微改一下,变成“能不能让我先印,因为我赶时间”。他是不是真的赶时间,没有人知道,但是当你有一个理由所以你要先印的时候,大家的接受程度变成了94%。更神奇的事情是,就算你的理由稍微改一下,比如有人说:“能让我先打印吗,因为我需要先印。”光是这个样子,大家的接受程度也有93%。
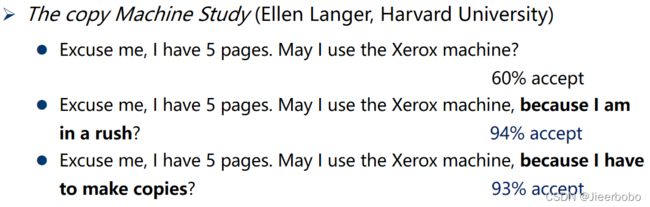
所以神奇的是人就是需要一个理由,你为什么需要先印?只要你讲出一个理由,就算你的理由是“因为我需要先印”,大家也会接受。所以会不会可解释机器学习也是同样的道理,我们只需要机器给我们一个理由告诉我们它为什么这样做,我们可能就会接受。所以什么是一个好的解释?一个好的解释就是人能接受的解释,人就是需要一个理由能让我们舒适。
Make people (your customers, your boss, yourself) comfortable.
让人们(你的客户、你的老板和你自己)感到舒适。 ——李宏毅
其实我们追踪一下现有的可解释性机器学习的论文,我们可以发现研究者在设计那些技术的时候,那些思想其实跟李老师的观点是很接近的。
3. 如何实现可解释性?
本节将介绍三种可解释性方法,包括置换特征重要性、LIME和SHAP。除此之外,我将会实现这三种方法并在一个新的数据集上进行分析。
3.1 置换特征重要性(Permutation Feature Importance)
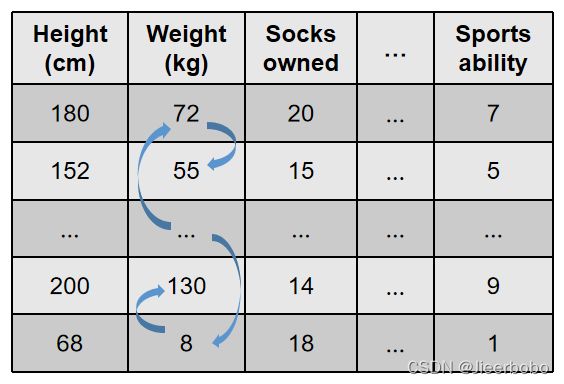
置换特征重要性是首先由这篇文章[9]提出的用在随机森林模型上,19年的这篇文章[10]把它变得一般化了,可以用在任何一个模型上。它的思想很简单,通过置换某个特征后,计算模型预测误差的变化程度来衡量该特征的重要性。举个例子,如下图所示,我用前面这些特征来预测一个人的运动能力,我们改变体重的数据,比如随机交换里面的数据,然后发现模型的预测误差明显增加了,那这说明体重这个特征很重要。相反,如果模型的预测误差几乎没有变化,那说明体重这个特征不重要。
3.1.1 数据集+代码实现+实验结果
数据集[11]:
- 预测葡萄牙的两所高中的学生的成绩
- 395个样本+15个特征
import pandas as pd
df = pd.read_csv('student-mat.csv', delimiter=';')
# drop columns that are less related to the target based on my judgement
cols_to_drop = ['school', 'age', 'address', 'Medu', 'Fedu', 'Mjob', 'Fjob', 'reason', 'guardian', 'famsup',
'romantic', 'goout', 'Dalc', 'Walc', 'health', 'G1', 'G2']
# at the same time, rename the columns so that they are understandable
df = df.drop(columns=cols_to_drop).rename(columns={'famsize': 'family_size', 'Pstatus': 'parent_cohab_status',
'traveltime': 'travel_time_school', 'studytime': 'study_time',
'failures': 'past_failures', 'schoolsup': 'extra_support',
'paid': 'extra_paid_classes', 'activities': 'extra_curricular',
'nursery': 'nursery_school', 'higher': 'want_higher_edu',
'internet': 'internet_access', 'famrel': 'family_relationships',
'freetime': 'free_time', 'absences': 'number_absences',
'G3': 'score'})
# convert categorical variables into dummy variables
df = pd.get_dummies(df, drop_first=True)
df_features = df.drop(columns='score')
df_features.info()

- travel_time_school:从学校到家的时间;study_time:每周学习时间;past_failures:过去课程不及格次数;family_relationships:家庭关系质量;free_time:放学后的休息时间;number_absences:翘课的次数;sex_M:性别为男性(1是男性,0是女性)等等,其余的解释可以直接去UCI官网查看。
置换特征重要性的代码实现[12]+实验结果:我用的jupyter notebook,底下代码里的每一小段就是jupyter里的一个小模块。
# machine learning model
import xgboost as xgb
model = xgb.XGBRegressor(n_estimators=500, max_depth=20, learning_rate=0.1, subsample=0.8, random_state=33)
model.fit(df_features, df['score'])
# using permutation_importance
from sklearn.inspection import permutation_importance
scoring = ['r2', 'neg_mean_squared_error']
perm_importance = permutation_importance(model, df_features, df['score'], scoring=scoring, n_repeats=5, random_state=33)
# plot a figure
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
perm_importance_r2 = pd.DataFrame(
data={'importance': perm_importance['r2']['importances_mean']}, index=df_features.columns
)
perm_importance_r2.sort_values(by='importance', ascending=False).plot(kind='barh', figsize=(5, 3.75))
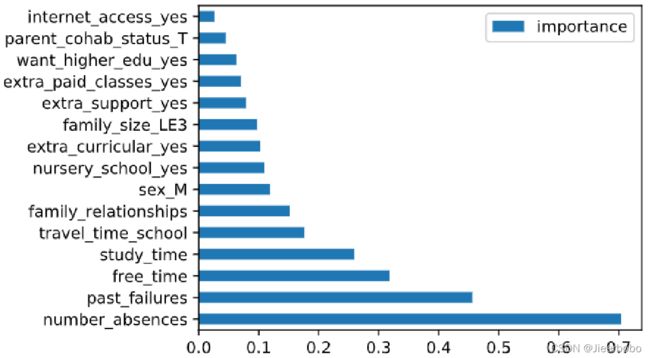
结果如上图所示,我们可以看到对学生成绩影响最大的特征是旷课的次数(number_absences),其次是过去课程不及格的次数(past_failures),再是放学后的休息时间(free_time)。这个结果确实也是比符合我的预期的,但这里有一个问题,即我们只知道这三个特征对成绩影响很大,但它具体是起到正反馈还是负反馈的作用,这张图并不能体现出来,因此置换特征重要性它不能展示特征值是如何影响最终结果的。
3.1.2 优缺点:
- 简单且高效的(相比于后两种方法)。
- 当特征之间是有关联的,置换特征重要性可能会因为不切实际的数据而产生偏差。比如刚才的示例,身高和体重并非完全无关的,我们通过置换体重的值,可能会出现一个人高2米,但体重只有8千克,这就不符合现实生活的逻辑。
- 不能显示特征值对最终结果的正负关系。
3.2 LIME
LIME[13]这篇文章是16年发表在数据挖掘和数据库领域的顶会KDD上,如今的引用量已经达到了8000多,是影响力非常大的一篇文章。这篇文章的作者认为一个好的解释器需要有以下几个特征:
- 可解释性(Interpretable):它要求我们所使用的可解释模型是人类易于理解的,比如一颗小的决策树是很好理解的,一个不懂机器学习的人也知道这颗树在做什么,但这个模型它的准确率是不够高的,那我们要提升准确率,通常我们会采用一片决策树,这个时候,模型就变得不可解释了。我们可以看到作者这里对可解释的想法跟我前面所说的让人感到舒服是一致的,都是以人为核心。
- 与模型无关的(Model-agnostic):一个好的解释器是希望能够解释任何模型的,即使是底下这个极其复杂的深度神经网络,也能够解释。
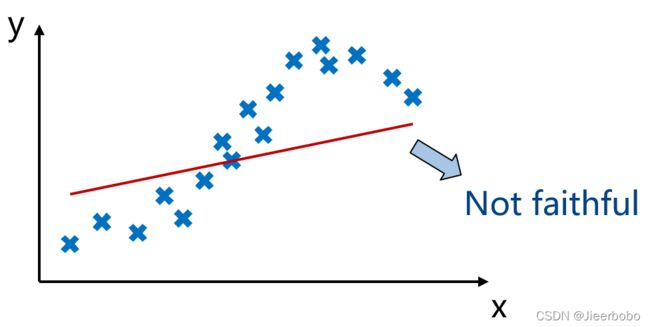
- 可信赖的(Faithful):解释器需要描述模型到底在做什么,比如说底下的叉是实际的数据分布,那么我用红线去拟合就是不可信赖的,因为它没有理解模型真正在做什么。
我们现在再来看一下LIME指的是什么:
Local Interpretable Model-agnostic Explanations
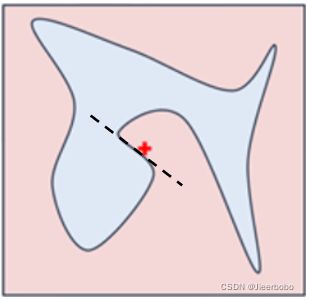
后面三个词语我都解释过了,现在就剩这个Local还没解释。这里的local指的是局部保真,这也是本文设计的核心思想。我们通常不可能去用一个简单的模型来全局近似一个复杂的黑盒模型,因为如果能这样,我们直接用简单的模型就好了。但是我们可以在局部用一个简单的模型来进行拟合。举个例子,在底下这个图中,红色和蓝色分别代表不同的类别,这条曲线是决策边界,我们是不可能用一个线性模型来达到这样的决策边界的,但是在局部,我们是可以精准地实现的。这就是LIME最核心的思想,保证在局部范围内,解释是可信的。
主要过程[14][15]:首先选择一个需要解释的样本x,然后对它进行扰动,就是找到它周围的样本,然后对这些样本进行预测,一些样本就变成蓝色的,一些样本就变成红色的,然后再根据这些样本与需要解释的样本的距离进行加权,最后其实就是用这些样本点去训练一个局部的线性模型。

我再用一个图来展示一下整个过程,这里参考了《LIME:我可以解释任何一个分类模型的预测结果》[16](写得很好的一篇文章)。如下图,最左边一串是需要解释的原始样本,给它进行编码(比如是01串),然后再对这个01串进行扰动得到一堆新的样本,这些新的01串样本作为解释器的训练数据,会输出一个output’,对这些新的01串样本进行解码,然后输入到原始模型中,也会得到一个output,然后就根据这两个output来构造损失函数并进行优化。这就是LIME的大致过程,其核心思想就是全局模型太难拟合了,我们就把目光聚焦在局部来进行模型的简化。

3.2.1 LIME的代码实现+实验结果
***文本分类和图像分类的代码,可以参考LIME作者的github[17]
首先是文本分类,这是一个判断一段文本是无神论还是基督教的分类器,准确率能达到92.09%。这是需要被解释的样本,我们发现这段文本有60%的可能性是无神论,40%的可能性是基督教,然后我们用LIME来对它进行解释,发现这个分类器判断基督教是因为文本里出现god这个词,这是符合预期的。然而它判断无神论不是根据邮件的内容而是邮件的抬头,这里颜色越深表示这些词对它的判断结果越重要,这样的判断逻辑显然是不正确的。如果我们没有LIME,我们可能会被这个分类器的高准确率所欺骗,有了LIME,我们会发现这个分类器似乎真的跟神马汉斯一样,不知道在做什么。

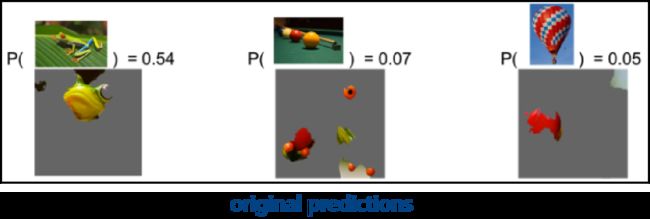
第二个例子是图像分类,我们可以看到原始图片有54%的概率被识别为树蛙,那模型为什么做出这样的决策呢?因为这张图片里的嘴巴这个特征和树蛙非常相似。这张图片还有7%的概率被识别为台球,尽管这看起来很荒谬,但我们通过LIME的解释,发现是因为树蛙的脚和眼睛跟台球很像,所以会有一定的概率被识别为台球。同样地,它还可能被识别为热气球,是因为这颗心脏有点像热气球的外表皮。当模型给出我这样的解释的时候,我的内心还是感到很舒适的,因为它的每个决策与我的思维是相符的,所以我会选择信任这个模型。
最后一个例子是刚才的学生成绩预测。我用LIME对一个人的成绩进行了解释,这个人的成绩是5分,对这个成绩起到积极影响的,也就是加分项,是他过去课程不及格的次数(past_failures)为0次,而对这个成绩起到消极影响的是他翘课的次数(number_absences)为12次,并且他的性别是女生(在这个数据集里,女生的成绩普遍低于男生),最后是因为他周末特别爱玩(这里5分是最爱玩,他得了4分)。这样的解释大体上也是符合我的预期的,但是我结合上一个方法的结果,发现了一个问题。就是特征的重要程度是不一致的。我们看到在LIME里,past_failures、extra_support_yes和travel_time_school是最重要的三个特征,而在置换特征重要性里,number_absences、past_failures和free_time是最重要的三个特征。我分析LIME是只保证了局部准确率,因为它的特点是local faithful,而在全局上它并不准确。也就是说如果我们要判断某一个人他因为什么原因得了低分,那用LIME是合适的,而如果是判断对于整个数据集来说,哪个特征对学生成绩的影响最大,置换特征重要性更加准确。
***数据集的代码在置换特征重要性中已经介绍过了
import lime
import lime.lime_tabular
import numpy as np
data=np.array(df_features)
explainer = lime.lime_tabular.LimeTabularExplainer(data, mode="regression", feature_names=df_features.columns)
############## visualizations #############
exp = explainer.explain_instance(data[79], model.predict, num_features=6)
exp.show_in_notebook(show_table=True)

3.2.2 优缺点:
- 适用于表格数据、文本和图像的方法。
- 解释的不稳定性,重复采样后的解释结果可能不同。
- 如何正确定义邻域(即采样/扰动的范围)是一个重要且未解决的问题。
3.3 SHAP
***这里推荐两个视频,需要去看[19][20]。
下面我介绍最后一种可解释性方法SHAP[18],这篇文章发表在17年人工智能的顶会NIPS上。SHAP是基于博弈论里的一个概念Shapley值[21]。这个Shapley值要解决的问题就是我们有一个联盟C,合作去创造了价值V,我们该如何度量每一个成员的贡献。通俗一点讲,就是我们几个人组队去参加比赛,最后得到1万元奖金,我们该怎么衡量每个人在这次比赛中的贡献来瓜分这1万元。比如说我们想度量成员1的贡献度,那我们就先把它从联盟中剔除,看看最终价值的变化,我们发现这块紫色的部分就是成员1对于234联盟的边际贡献。
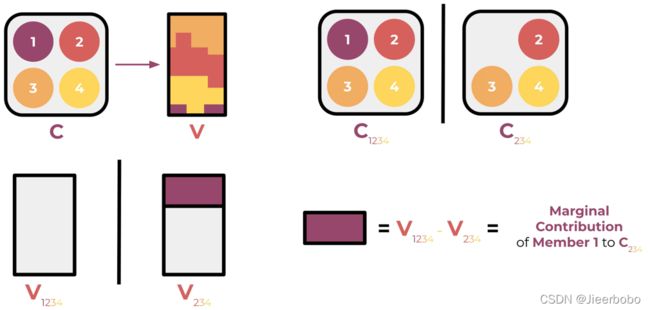
如果我们累加成员1在所有联盟里的边际贡献,即考虑每一个联盟都剔除成员1后的价值变化,那么对于成员1的平均边际贡献就是fai1,相应地,也能计算出其他成员的平均边际贡献fai2,fai3和fai4 。这些值就是Shapley值,代表着每个成员的贡献程度。
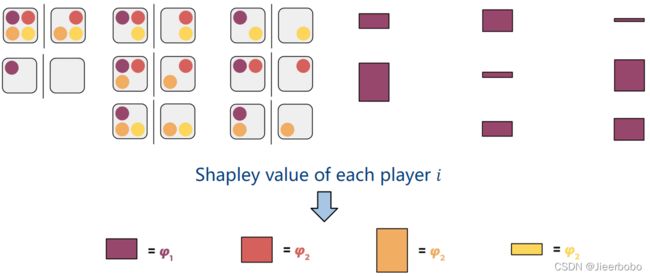
所以要解决上面这个问题(如何度量每一个成员的贡献?),一个公平的方法就是计算shapley值,底下是Shapley值计算的形式化表达。最令人惊喜的是,Shapley值是唯一满足有效性(efficiency)、对称性(symmetry)、虚拟性(dummy)和可加性(additivity)的方法,这四个性质具体是什么含义,大家有兴趣的可以自己去搜一下[22]。讲完了Shapley值,接下来我们要考虑的是如何把它应用在机器学习中。
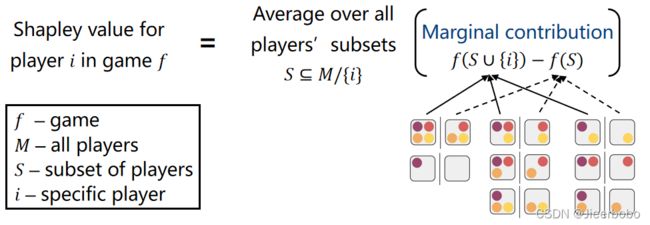
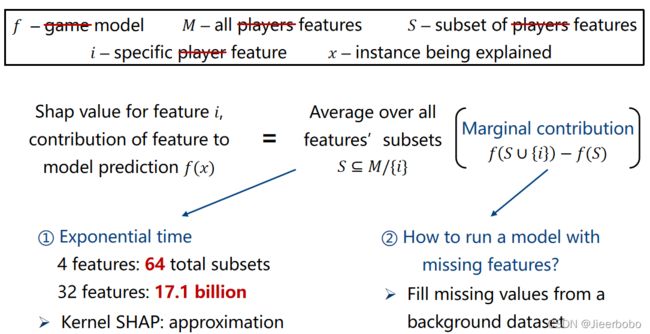
在博弈论中,我们度量的是每个player对结果的贡献度,而在机器学习中,我们要度量的是每个特征对结果的贡献度。我们把刚才公式里所有的player都改成feature,并把刚才的game改为model就可以了。但是这里会遇到两个挑战,第一个是特征联盟是呈指数增长的,刚才1个成员就涉及2的4次方,16个联盟,然后总共有4个成员,就是64个联盟,同样地,在这里4个特征我们需要计算64个联盟,而当特征增加到32个的时候,将要计算171亿个联盟,这显然会导致效率很低。这也是Shapley值的一个致命缺点,就是在99.9%的实际问题中,只有近似计算的方法才是可行的。第二个挑战是由于机器学习模型的输入在设计时就固定好维度了,如何将缺少特征值的输入丢到模型中运行?那这里采取的是填充的办法,可以根据经验填充,也可以随机填充,当然这也会导致不符合现实的数据产生。因此,SHAP的本质思想是把博弈论中的Shapley值迁移到机器学习领域,然后解决了两个挑战。
3.3.1 SHAP的代码实现+实验结果
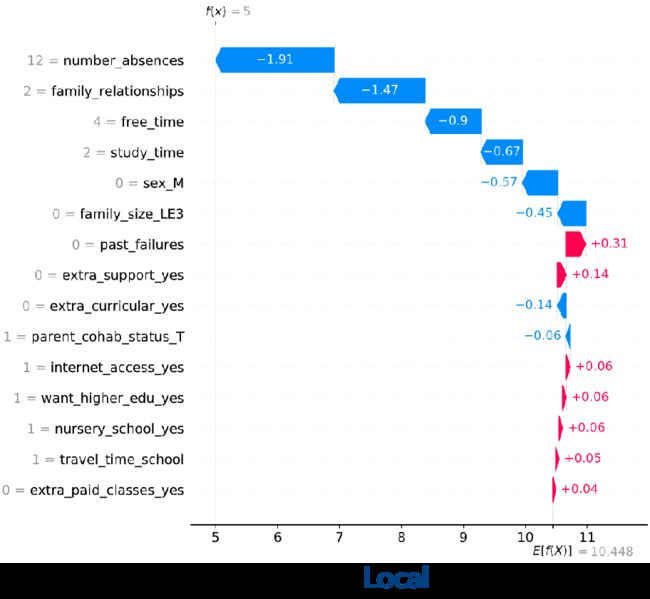
同样,我在预测学生成绩数据集上进行分析,下图是单个样本的解释,里面有两条线,E[f(x)]表示所有学生的平均成绩10.448分,f(x)表示需要被解释的学生的成绩5分。这个图的左边是学生的特征值,SHAP的解释和前面两种方法不一样,它从平均值出发,分析各个特征的影响程度。这些红色的箭头代表这些特征对该学生的成绩起到了加分的作用,而蓝色的箭头则起到了减分作用。比如放学后的休息时间(free_time)是4(5是满分,代表休息时间很长),这会导致成绩降低,家庭关系不和睦也会导致成绩降低,最重要的是旷课了12次,进一步降低了成绩。所以SHAP的解释图给人一种推动的感觉,就是部分因素积极地推动,部分因素消极地推动。
# Generate the Tree explainer and SHAP values
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(df_features)
expected_value = explainer.expected_value
shap.plots._waterfall.waterfall_legacy(expected_value, shap_values[79], features=df_features.loc[79,:], feature_names=df_features.columns, max_display=15, show=True)
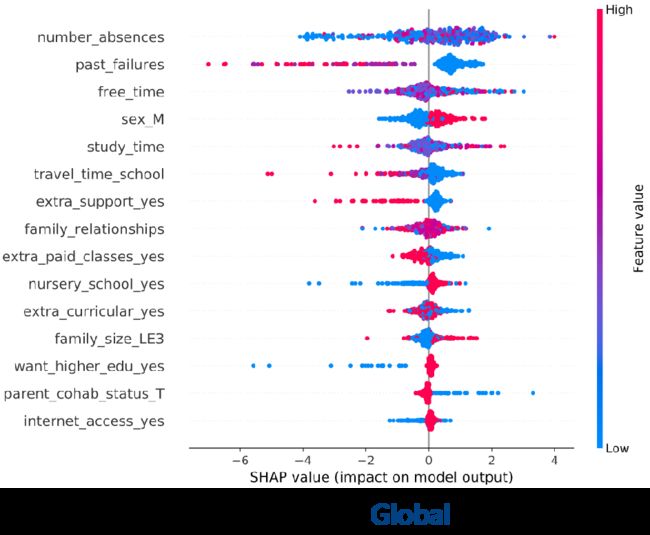
底下这张图也很有意思,是SHAP特有的。这张图是这样看的,从蓝到红表示特征值从低到高,比如蓝表示旷课0次,红表示旷课10几次。横坐标表示SHAP值,负的就是起到降低成绩的作用,正的就是起到提升成绩的作用。然后每个特征里面都有小圆点,表示的是每一个样本,即每个学生。我举几个例子来解释一下,比如这个past_failures,表示过去课程不及格的次数,蓝色表示不及格次数很少,红色表示不及格次数很多,我们发现蓝色的点所对应的SHAP值全是正的,红色的全是负的,也就是说,旷课次数少能促进成绩的提高,旷课次数多则相反。这也是符合预期的。再比如want_higher_edu_yes,红色表示想要获得更高的教育,蓝色表示不想要,图意为你不想获得更高的教育会使成绩降低,而想要获得更高的教育会提升成绩,但影响没那么大,因为红点都在0附近。最后再讲一个,internet_access_yes,你能上网则对成绩有积极影响,而不能上网大概率会降低成绩,但也不一定,因为有几个蓝点对应的SHAP值是正的。这是SHAP的实验结果,它通常可以让我们更加全面地去解释和分析模型的决策。
shap.summary_plot(shap_values, df_features,title="SHAP summary plot")
3.3.2 优缺点:
- 良好的数学性质和扎实的理论基础。
- KernelSHAP计算速度很慢,且忽略了特征相关性。
4. 感想和展望
- Less is More 大道至简:前面讲的三种方法一篇发在CCF A类顶刊上,另外两篇发在CCF A类顶会上,都是特别好的论文,我看了他们的论文后的第一个感想就是大道至简,他们的核心思想都非常简单,但他们在论文里会对这些思想用数学理论或方法进行验证。此外他们的方法都是general的,也就是对于任何机器学习模型都适用,因为他们只关注模型的输入和输出,我想这也是他们受欢迎的原因之一吧。
- 如何量化机器学习模型的可信性仍是一个开放问题:2020年的一篇文章[23]做了一个很好的尝试,他把模型的可信度描述为客观存在的信任以及情感上的信任,其中情感上的信任是由用户在看完那些用可解释性工具生成的解释后进行评估的,客观存在的信任是由模型的鲁棒性、透明性、准确率以及复杂度进行度量的。
- **我们是否能用解释器来检测或者构造对抗样本?**我的想法是既然机器面对两张人类看来是一样的图片会分类错,那肯定是因为机器在这两张图片上的关注特征是不同的。现在已经有文章把可解释性用在对抗攻击的研究上[24]。
- 如何去欺骗解释器(LIME和SHAP等等)?
参考文献
- https://web.stanford.edu/class/cs329t/
- https://www.propublica.org/article/how-we-analyzed-the-compas-recidivism-algorithm
- R. Shokri, et al., “Membership inference attacks against machine learning models,” In proceedings of S&P, 2017.
- B. Liu, et al., “When machine learning meets privacy: A survey and outlook,” ACM Computing Surveys (CSUR), 2021.
- A.B. Arrieta, et al., “Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI,” Information fusion, 2020.
- https://speech.ee.ntu.edu.tw/~hylee/ml/2022-spring.php
- https://www.explainxkcd.com/wiki/index.php/1838:_Machine_Learning
- C. Molnar, “Interpretable Machine Learning: A Guide for Making Black Box Models Explainable,”, 2022. http://christophm.github.io/interpretable-ml-book/
- L. Breiman, “Random forests,” Machine learning, 2001.
- A. Fisher, et al., “All models are wrong, but many are useful: Learning a variable’s importance by studying an entire class of prediction models simultaneously,” Journal of Machine Learning Research, 2019.
- https://archive.ics.uci.edu/ml/datasets/student+performance#
- https://www.justintodata.com/explainable-machine-learning-with-python/#explainable-ml-method-1-permutation-feature-importance
- M.T. Ribeiro, et al., “Why should i trust you? Explaining the predictions of any classifier,” In Proceedings of the 22nd ACM SIGKDD, 2016.
- https://blog.csdn.net/iqdutao/article/details/108397239
- https://blog.csdn.net/weixin_42347070/article/details/106076360
- https://zhuanlan.zhihu.com/p/385351557
- https://github.com/marcotcr/lime
- S.M. Lundberg and Su-In Lee, “A unified approach to interpreting model predictions,” In Proceedings of NeurIPS, 2017.
- https://www.youtube.com/watch?v=VB9uV-x0gtg&t=176s
- https://www.youtube.com/watch?v=0yXtdkIL3Xk&t=458s
- L.S. Shapley, “A value for n-person games,” Contributions to Theory Games, 1953.
- https://blog.csdn.net/zhangyi0626/article/details/122741464
- Li, Chen, et al., “Trustworthy Deep Learning in 6G-Enabled Mass Autonomy: From Concept to Quality-of-Trust Key Performance Indicators,” IEEE Vehicular Technology Magazine, 2020.
- G. Fidel, et al., “When explainability meets adversarial learning: Detecting adversarial examples using SHAP signatures,” In 2020 international joint conference on neural networks (IJCNN), 2020.