Python使用python-snap7实现西门子PLC通讯
Python简介
Python是开源的高级编程语言之一,广泛应用于人工智能、数据分析、爬虫等领域。由于它拥有大量的开源库和标准库,以及简单且贴近自然语言的语法,所以即便是从未接触过编程的人,也能快速上手。2021年10月,Python登顶Tiobe,成为全世界最热门的编程语言之一。
以下摘自百度百科:
Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆 于1990 年代初设计,作为一门叫做ABC语言的替代品。Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
需要注意的是,Python存在2.x版本和3.x版本,本文使用的是3.x的版本。
本文代码已上传至GitHub,项目地址如下:
https://github.com/XMNHCAS/Snap7PythonDemo
Snap7简介
snap7是一个由国外程序员开发的基于以太网与西门子S7系列PLC的通讯的开源库,类似于C#的S7.Net,但是它不单只支持Python,还支持Java、C/C++、C#等语言。
以下是snap7的官网:
http://snap7.sourceforge.net/
官网包含了使用文档、源码、历史版本等说明,可以根据需要自行查阅。
而python-snap7则是snap7的python版本,有单独的文档以及使用说明,只能用于python,以下是官方文档及GitHub链接:
python-snap7官方文档
GitHub
导入python-snap7
首先需要安装python-snap7,打开cmd,输入以下命令,安装python-snap7
pip3 install python-snap7

打开vscode,新建一个py文件,然后在最上面导入snap7
如果不知道如何安装python和使用vscode进行python代码编辑,可以百度一下,此处不赘述如何配置Python开发环境
import snap7创建连接
snap7实现通讯的时候,是将PLC作为服务端,PC以客户端的身份主动连接的,所以最开始的时候,我们应该创建通讯需要使用的客户端
# 创建通讯客户端实例
plcObj = snap7.client.Client()
# 连接至PLC
plcObj.connect('192.168.10.230', 0, 1)如果手头没有PLC,可以参考我写的这篇文章:C#使用S7NetPlus以及PLCSIM Advanced V3.0实现西门子PLC仿真通讯
使用PLCSIM Advanced可以仿真出PLC来进行通讯测试
测试连接功能是否正常:
import snap7
# 创建通讯客户端实例
plcObj = snap7.client.Client()
# 连接至PLC
plcObj.connect('192.168.10.230', 0, 1)
# 打印连接状态
print(f"连接状态:{plcObj.get_connected()}")
# 关闭连接
plcObj.disconnect()
# 打印连接状态
print(f"连接状态:{plcObj.get_connected()}")
![]()
读取数据
python-snap7并未集成像S7.Net那样的读取即刻解析数据的功能,所以无论是读还是写,都是需要进行字节转换的。
以读取DB10的以下的五个变量为例:
打开TIA Protal,创建DB块,编号为10,并添加如下图所示的变量并赋初值,下载到仿真的PLC后打开打开数值监控:
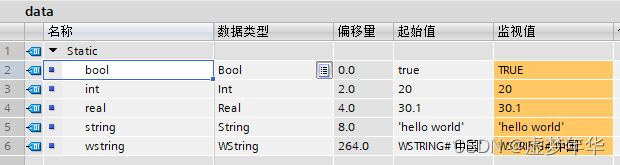
首先我们需要计算需要读取的总字节数,也就是最后一个变量的地址(即偏移量)加上它的数据长度。可以看到,上面的六个变量中,最后一个地址是264,WString为512字节,所以需要读取的总字节数为264+512=776个。
所以第一步,把这776个字节都读取上来:
data = plcObj.db_read(10, 0, 776)其中,plcObj是我们刚刚创建的通讯客户端对象,db_read是它的读取DB块的方法,第一个参数是DB号,第二个是要读取的字节起始的起始地址,第三个参数是要读取的字节总数,用data这个变量来接收这些数据。
当然也可以写成这种形式:
data = plcObj.read_area(snap7.client.Areas.DB, 10, 0, 776)read_area是读取任意区域的方法,通过第一个参数的枚举来区分读取的区域,如input、output、DB等,后面三个参数与db_read一致。
当我们需要的数据以字节的形式读取上来以后,我们就可以进行解析了。
解析数据
这里解析的方法有两种,第一种是使用python自身的数据类型转换的方法进行解析,第二种是使用python-snap7提供的转换方法进行解析。
Python自身函数
首先我们介绍第一种方法,使用python自身的数据类型转换的方法进行解析。
在python中,bool、int两个类型都有一个from_bytes的方法,可以通过这个方法来将字节数组转换为对应的数据。但是需要注意的是,在PLC中,数据是大端存储的,而PC中一般是小端存储,所以在这样进行转换的时候,需要加上byteorder='big',来声明读取上来的字节是大端存储的方式。故前面的bool和int变量都可以以这种方式进行解析:
# 读取bool的值
bool.from_bytes(data[0:1], byteorder='big')
# 读取int的值
int.from_bytes(data[2:4], byteorder='big')其中[ 数字 : 数字 ]是python截取数组的语法,左边的数字是截取的起始索引号,右边的是截取的停止的索引号,需要注意的是,右边的索引是不会被截取的,所以像上面代码的data[ 0 : 1 ],实际上截取的只有data[0],而data[ 2 : 4 ],截取的则是data[2]和data[3]。如果左边的数字不填,则默认从索引0开始截取;而如果右边的数字不填,则默认截取剩余的所有元素。
而对于字符串,python提供了decode方法,可以将字符串的字节数组按照指定的编码格式来转换为字符串。不过PLC中的字符串的头字节是字符串的变量长度和字符串的实际长度,所以需要跳过这些字节来读取实际的数据。string类型是单字节存储的ASCII编码的字符串,所以跳过前两个字节。而wstring类型则是双字节存储的UTF-16BE编码的字符串,所以需要跳过前四个字节。
# 读取string的值
data[10:264].decode(encoding="ascii")
# 读取wstring的值
data[268:].decode(encoding="utf-16be")在python中,float类型没有像bool和int一样的from_bytes方法,这个时候我们就需要使用struct来进行解析。struct是python的模块之一,可以用以解析字节,刚刚说到的bool、int和字符串都可以用它来解析,当然float也是可以的,不过要讲的话东西就会比较多,此次就不深入讲解了。
struct有pack和unpack两个方法,分别用以将数据转换为字节流和将字节流解析为对应的数据,如下所示,即可将real数值转换为python的float类型:
# 读取real的值
struct.unpack('>f', data[4:8])[0]第一个参数是指定需要转换成的数据类型,“f”代表float类型,前面加的“>”代表这个字节数组是大端存储的方式,第二个参数是需要转换的字节流。由于unpack是以元组的形式返回的数据,所以需要加[0]来获取它返回的第一个数据。
接下来运行一下我们的代码,来查看读取结果:
import snap7
import struct
# 创建通讯客户端实例
plcObj = snap7.client.Client()
# 连接至PLC
plcObj.connect('192.168.10.230', 0, 1)
# 读取数据
data = plcObj.db_read(10, 0, 776)
# 关闭连接
plcObj.disconnect()
# python解析
selfBool = bool.from_bytes(data[0:1], byteorder='big')
selfInt = int.from_bytes(data[2:4], byteorder='big')
selfReal = struct.unpack('>f', data[4:8])[0]
selfString = data[10:264].decode(encoding="ascii")
selfWString = data[268:].decode(encoding="utf-16be")
print("python自身函数解析:")
print(
f"bool:{selfBool}; int:{selfInt}; real:{selfReal}; string:{selfString}; wstring:{selfWString}"
) ![]()
对比我们上面的PLC中的数值,基本上是没什么问题的。至于为什么real里的30.1,读上来之后会变成30.100000381469727,是因为计算机中的浮点型的存储规则决定了浮点数在部分情况下只能是个近似值,并非是python的问题,由于误差是比较小,实际应用时一般可以忽略不计。
通过上述方法,我们可以知道python自身就足以解析PLC读取上来的字节,但是这种方法对于部分人来说可能不是那么好理解,使用起来也不是那么简单直观,而且更重要的是,这种方法解析bool值存在一点小问题,毕竟python对二进制的位操作支持得并没有C#那么好。
python-snap7函数
接下来我们来介绍第二种方法,使用python-snap7提供的转换方法进行解析。
首先查看文档,可以看到snap7中有一个util的模块,它提供了多种数据类型的转换方法,可以将从PLC读取上来的字节直接解析为python可识别的数据类型。

首先导入util,这样我们可以少写个snap7,提高代码的简明性。
from snap7 import util根据文档,我们写出以下转换代码:
# Bool的值
util.get_bool(data, 0, 0)
# Int的值
util.get_int(data, 2)
# Real的值
util.get_real(data, 4)
# String的值
util.get_string(data, 8, 256)可以看到,我们在使用snap7的转换方法的时候,只需要把我们读取到的字节数组以及数据的起始索引传进去即可,比起使用python自身的方法会更加简单。
get_bool方法的第三个参数为该字节的第几个bool量,因为一个bool量只需要一个位来表示,而一个字节是包含八个位的,也就是说这个字节可以表示八个bool量,在这里对应的DB10里地址为0.0~0.7的八个bool量,由于我们要读取的是地址0上的第一个bool量,所以第二个参数和第三个参数分别为0,0。
get_string方法的第三个参数为该字符串的最大长度,由于string类型共有256个字节,所以此处填256。
打印一下两种方法的结果:
import snap7
import struct
from snap7 import util
# 创建通讯客户端实例
plcObj = snap7.client.Client()
# 连接至PLC
plcObj.connect('192.168.10.230', 0, 1)
# 读取数据
data = plcObj.db_read(10, 0, 776)
# 关闭连接
plcObj.disconnect()
# python解析
selfBool = bool.from_bytes(data[0:1], byteorder='big')
selfInt = int.from_bytes(data[2:4], byteorder='big')
selfReal = struct.unpack('>f', data[4:8])[0]
selfString = data[10:264].decode(encoding="ascii")
selfWString = data[268:].decode(encoding="utf-16be")
print("python自身函数解析:")
print(
f"bool:{selfBool}; int:{selfInt}; real:{selfReal}; string:{selfString}; wstring:{selfWString}"
)
# snap7解析
snap7Bool = util.get_bool(data, 0, 0)
snap7Int = util.get_int(data, 2)
snap7Real = util.get_real(data, 4)
snap7String = util.get_string(data, 8, 256)
snap7WString = util.get_string(data, 264, 508)
print("snap7函数解析:")
print(
f"bool:{snap7Bool}; int:{selfInt}; real:{snap7Real}; string:{snap7String}; wstring:{snap7WString}"
) 
可以看到,wstring读取出来的结果是乱码,这是因为python-snap7的头字节解析及编码格式问题,所以当我们读取wstring的时候,最好还是用python自己的decode方法
写入数据
与读取数据一样,写入数据也有两种方式,但是区别也仅仅是生成写入数据的字节方式不用。
写入数据可以调用db_write方法,也可以调用write_area,与读取数据一样,前者只能用以写入DB块,后者可以写入任意区域。
plcObj.write_area(snap7.client.Areas.DB,10,0,data)
plcObj.db_write(10,0,data)data是需要写入的数据的字节形式。
Python转换
我们在解析读取数据的时候提到,bool和int有from_bytes,同样的它们也有to_bytes方法,用以将数据转换成对应的字节数组的形式:
# bool的字节
bool.to_bytes(True, 1, 'big')
# int的字节数组(双字节)
int.to_bytes(200, 2, 'big')同样的,字符串类型有解码的decode方法,也有转码的encode方法:
# string的字节数组
str = 'hello python'
str.encode(encoding='ascii')
# wstring的字节数组
str = '中国北京市'
str.encode(encoding='utf-16be')而对于float类型要用的struct,我们解析数据时用到了它的unpack方法,而转换为字节的时候,我们就需要调用它的pack方法:
# float的字节数组
struct.pack(">f", 10.1)所以我们能很轻易地写出写入数据的代码:
import snap7
import struct
# 创建通讯客户端实例
plcObj = snap7.client.Client()
# 连接至PLC
plcObj.connect('192.168.10.230', 0, 1)
# 写入DB10.0 —— bool值
plcObj.write_area(snap7.client.Areas.DB, 10, 0, bool.to_bytes(False, 1, 'big'))
# 写入DB10.2
plcObj.write_area(snap7.client.Areas.DB, 10, 2, int.to_bytes(200, 2, 'big'))
# plcObj.write_area(snap7.client.Areas.DB, 10, 2, struct.pack(">h", 112))
# 写入DB10.4 —— real值
plcObj.write_area(snap7.client.Areas.DB, 10, 4, struct.pack(">f", 10.1))
# 写入DB10.8 —— string值
str = 'hello python'
data = int.to_bytes(254, 1, 'big') + int.to_bytes(len(str), 1, 'big') + str.encode(encoding='ascii')
plcObj.write_area(snap7.client.Areas.DB, 10, 8, data)
# 写入DB10.264 —— wstring值
str = '中国北京市'
data = int.to_bytes(508, 2, 'big') + int.to_bytes(len(str), 2, 'big') + str.encode(encoding='utf-16be')
plcObj.write_area(snap7.client.Areas.DB, 10, 264, data)
# 关闭连接
plcObj.disconnect()运行程序后,回到TIA Protal的监视界面可以看到,数值已经被更改了:

python-snap7转换
python-snap7提供了不同数据类型的转换方法,如下图所示:

所以根据我们这里的五种变量类型,可以写出对应的转换代码:
# bool的字节数组
boolData = bytearray(1)
util.set_bool(boolData, 0, 0, True)
# int的字节数组
intData = bytearray(2)
util.set_int(intData, 0, 100)
# real的字节数组
realData = bytearray(4)
util.set_real(realData, 0, 20.5)
# string的字节数组
str = "hello snap7"
stringData = bytearray(len(str) + 2)
util.set_string(stringData, 0, str, 256)
stringData[0] = 254需要注意,string类型在调用了set_string方法后,首字节的字符最大值依旧是0,可能是python-snap7目前仍然存在的小bug,所以需要手动修改为真实的最大值。
由于目前并没有set_wstring方法,而且set_string方法也不支持wstring,所以wstring依然使用python的decode方法进行写入。
写入代码如下:
import snap7
from snap7 import util
# 创建通讯客户端实例
plcObj = snap7.client.Client()
# 连接至PLC
plcObj.connect('192.168.10.230', 0, 1)
# 写入bool
boolData = bytearray(1)
util.set_bool(boolData, 0, 0, True)
plcObj.db_write(10, 0, boolData)
# 写入int
intData = bytearray(2)
util.set_int(intData, 0, 100)
plcObj.db_write(10, 2, intData)
# 写入real
realData = bytearray(4)
util.set_real(realData, 0, 20.5)
plcObj.db_write(10, 4, realData)
# 写入string
str = "hello snap7"
stringData = bytearray(len(str) + 2)
util.set_string(stringData, 0, str, 256)
stringData[0] = 254
plcObj.db_write(10, 8, stringData)
# 写入wstring
str = '中国广州市'
data = int.to_bytes(508, 2, 'big') + int.to_bytes(len(str), 2, 'big') + str.encode(encoding='utf-16be')
plcObj.db_write(10, 264, data)
plcObj.disconnect()
再打开TIA Protal,可以看到数据已经成功写入。

结尾
本文介绍了怎么使用python实现西门子PLC的通讯,如果会C#的写法的话,可以很明显感觉到python的代码量会比C#少,但是相对的,数据解析也会比C#稍微麻烦一点。不过底层的通讯原理都是一样的,只是具体实现方式不同而已。