知识图谱综述
知识图谱概述
-
- 1.摘要
- 2.概述
-
- 2.1 知识图谱
- 2.2 知识图谱设计原则
- 3.知识图谱技术
-
- 3.1 知识获取与处理
-
- 3.1.1 命名实体识别技术
- 3.1.2 关系抽取
- 3.2 知识表示
-
- 3.2.1RDF
- 3.2.2 RDFS/OWL
- 3.2.3 向量Embedding:TranE、TranH、TranR等
- 3.3 知识存储
-
- 3.3.1jena
- 3.3.2 jena java代码
- 3.4 知识计算与应用
-
- 3.4.1 推荐系统
- 3.4.2知识图谱加入推荐系统技术
- 3.4.3知识图谱特征学习
- 参考资料
1.摘要
知识图谱本质上是揭示实体之间关系的语义网络。随着移动互联网的发展,万物互联成为了可能,这种互联所产生的数据也在爆发式地增长,而且这些数据恰好可以作为分析关系的有效原料。机器学习、深度学习的算法大多关注实体的划分与识别,而知识图谱关注实体及实体之间的关系。这让人工智能有了一定的推理能力。
本文大致描述的知识图谱概念、设计原则,以及知识图谱技术:即知识获取与处理、知识建模与存储、知识计算与应用。在应用中,描述了知识图谱如何用于推荐系统,并得到反馈更新。
关键词:知识图谱 实体间关系 知识获取与处理 知识建模与存储 知识计算与应用 推荐系统
2.概述
2.1 知识图谱
知识图谱,由Google在2012年提出,是一种大规模语义网络,包含实体、属性及其之间的各种语义关系,它既是一套人工智能技术体系,也是一种知识组织和表达的模式,同时还是一类大规模的开放知识库。
知识图谱拥有极强的表达能力和建模灵活性,是一种人类可识别且对机器友好的知识表示。
知识图谱的关键技术基础之一是语义网技术发展。2001 年蒂姆·伯纳斯-李(Tim Berners-Lee)等介绍 RDF 知识表示方法、本体论、智能代理等关键内容,奠定了语义网 的基础。随后 W3C 发布 RDF、OWL、SPARQL 等一系列标准来推动语义网落地。2006 年 关联数据(Linded Data)被提出以简化语义网的实现路径,得到广泛应用并深刻地改变了互联网。
知识图谱的另一关键技术基础是大规模知识库的建立。DBpedia、YAGO、Freebase 等大型通用知识图谱主要源自于维基百科;复旦大学的中文通用百科知识图谱 (CN-DBpedia)和中文通用概念知识图谱(CN-Probase)主要从中文百科网站提取信息; ConceptNet、GeoNames、BabelNet、百度知心、搜狗知立方等均以不同知识库为基础。
知识图谱技术可分为知识获取与处理、知识建模与存储、知识计算与应用等 3 个体系。
2.2 知识图谱设计原则
业务原则:一切要从业务逻辑出发,设计时也要想好未来业务可能的变化
效率原则:让知识图谱尽量轻量化,核心在于把知识图谱设计成小而轻的存储载体。
分析原则:不需要把跟关系分析无关的实体放在图谱当中;
冗余原则:有些重复性的信息、高频的信息可以放到传统数据库当中。
3.知识图谱技术
3.1 知识获取与处理
知 识 抽 取 { 命 名 实 体 识 别 技 术 { 基 于 规 则 或 统 计 模 型 基 于 神 经 网 络 的 监 督 学 习 : 神 经 网 络 + 概 率 模 型 + 后 处 理 规 则 关 系 抽 取 { 基 于 模 板 的 方 法 : 基 于 触 发 词 / 字 符 串 、 基 于 依 存 句 法 基 于 监 督 学 习 基 于 半 监 督 学 习 : 远 程 监 督 、 B o o t s t r a p p i n g 知识抽取\begin{cases} 命名实体识别技术\begin{cases} 基于规则或统计模型 \\ 基于神经网络的监督学习:神经网络+概率模型+后处理规则 \end{cases} \\ 关系抽取 \begin{cases} 基于模板的方法:基于触发词/字符串、基于依存句法 \\ 基于监督学习 \\ 基于半监督学习:远程监督、Bootstrapping \end{cases} \end{cases} 知识抽取⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧命名实体识别技术{基于规则或统计模型基于神经网络的监督学习:神经网络+概率模型+后处理规则关系抽取⎩⎪⎨⎪⎧基于模板的方法:基于触发词/字符串、基于依存句法基于监督学习基于半监督学习:远程监督、Bootstrapping
3.1.1 命名实体识别技术
命名实体识别技术主要是抽取的是文本中的原子信息元素。对于结构化数据采用的是图映射(链接数据)、D2R转换(数据库);半结构化数据,采用的是包装器。
(1)命名实体的划分
第一种是以字为单位的标注方案,第二种是以词为单位的标注方案。分词的效果将很大影响以词语为单位的命名实体识别的效果。对于中文而言,命名实体识别任务更常用、更具研究价值和潜力的方法是以字为单位的标注方案。
(2)命名实体的标注
最常用的标准有BIO标注体系和BIOES标注体系。BIO标注体系即将标签分为非命名实体(O),命名实体开头(B),命名实体内部(I)三类。
当出现两个B时,表示上一个B结束。
(3)命名实体的训练/分类:
由于命名实体的非定长、需要联系上下文,最常用、最成功的是采用序列模型。
深度学习方法,经典的是LSTM+CRF。LSTM神经网络,特殊的循环神经网络,能够学习历史的命名实体信息。而CRF能够学习历史的命名实体标注。
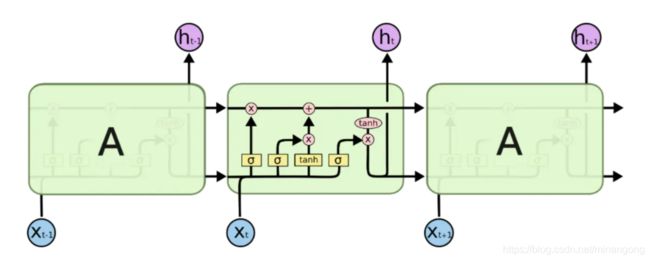

(4)实体统一和指代消解(PageRank算法)
实体统一:即实体名字不同,但指向的是同一个实体
指代消解:识别代词指向的实体。
3.1.2 关系抽取
关系抽取需要需要从文本中提取两个或多个实体之间的语义关系。
(1)基于模板的方法
-
基于触发词/字符串:
通过触发词判断两个实体的关系。例如触发词是儿子,那么左右两个实体关系是父母/儿子的关系。
-
基于依存句法:
通常可以以动词为起点构建规则,对节点上的词性和边上的依存关系进行限定。
- 对句子进行分词、词性标注、命名实体识别、依存分析等处理
- 根据句子依存语法树结构上匹配规则,生成三元组
- 根据扩展规则对三元组进行扩展
- 对三元组实体和触发词进一步处理,抽取出关系
(2)基于监督学习
联合抽取模型:同时抽取实体和其之间的关系
双层的 LSTM-RNN 模型训练分类模型:
- 第一层 LSTM 输入的是词向量、位置特征和词性来识别实体的类型。训练得到的 LSTM 中隐藏层的分布式表达和实体的分类标签信息作为第二层 RNN 模型的输入。
- 第二层的输入实体之间的依存路径,第二层训练对关系的分类。
(3)基于半监督学习
-
远程监督:
知识库与非结构化文本对齐来自动构建大量训练数据,减少模型对人工标注数据的依赖,增强模型跨领域适应能力。
基本假设:若两个实体在知识库中存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系。
具体的步骤:1.从知识库中抽取存在关系的实体对;2.从非结构化文本中抽取含有实体对的句子作为训练样例。
-
Bootstrapping:
基本原理:通过在文本中匹配实体对和表达关系短语模式,寻找和发现新的潜在关系三元组。
具体的步骤:1. 利用少量实例作为初始种子(seed tuples)的集合
2. 利用 pattern 学习方法进行学习,通过不断迭代从非结构化数据中抽取实例
3. 然后从新学到的实例中学习新的 pattern 并扩充 pattern 集合
4. 寻找和发现新的潜在关系三元组
3.2 知识表示
传统的知识图谱表示方法有OWL、RDF、RDFS等本体语言。而随着深度学习的发展与应用,期望用更简单的方式来表示——向量。使用向量可以方面之后的推理等工作。
3.2.1RDF
RDF(Resource Description Framework 资源描述框架)由节点和边组成,节点表示实体/资源、属性,边则表示了实体和实体之间的关系以及实体和属性的关系,其本质是一个数据模型。它提供了一个统一的标准,用于描述实体/资源。RDF形式上表示为SPO三元组(Subjext-Predicate-Object),即一条条知识。
序列化方法:
-
N-Triples:多个三元组表示RDF数据集
其中,第一、三条是实体、属性及其之间的关系,第二条是实体与实体之间的关系
-
Turtle
@prefix person:Turtle可以看作是N-Triples简化后的表示。
-
3.2.2 RDFS/OWL
RDFS还是用来描述RDF数据的。本质上是一些预定义词汇构成的集合,用于对RDF进行类定义、属性定义,是一种轻量化的模式语言。不区分数据属性和对象属性。
@prefix rdfs: .
@prefix rdf: .
@prefix : OWL增加了额外的预定义词汇,区分数据属性和对象属性.具有高效的推理能力
@prefix rdfs: .
@prefix rdf: .
@prefix : .
### owl:Class定义了“人”和“地点”两个类。
:Person rdf:type owl:Class.
:Place rdf:type owl:Class.
### owl:DatatypeProperty定义了数据属性,owl:ObjectProperty定义了对象属性。
:chineseName rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:string .
:hasBirthPlace rdf:type owl:ObjectProperty;
rdfs:domain :Person;
rdfs:range :Place .
:address rdf:type owl:DatatypeProperty;
rdfs:domain :Place;
rdfs:range xsd:string .
3.2.3 向量Embedding:TranE、TranH、TranR等
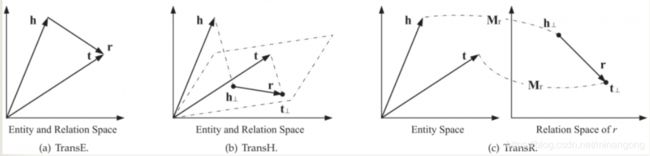
-
TransE:
基于实体和关系的分布式向量表示,利用了词向量的【平移不变现象】。例如:C(king)−C(queen) ≈C(man)−C(woman) .
但不能用于复杂关系上,如一对多关系。(姜文,导演,让子弹飞)、(姜文,导演,一步之遥),可 以得到,让子弹飞≈一步之遥,但实际上这两部电影是不同的实体。
-
TransH:
解决一对多问题
把h和t 投影到一个超平面,得到投影向量h⊥,r⊥,然后关系作为在这两个投影向量之间的平移,对于每一种关系都要训练出一个超平面和与之对应的关系r。
-
TransR:
TransR 认为实体空间和关系空间应该是不同的。实体 h 和 t 映射到关系空间中再做这种平移变换。对于每一个关系有一个与之对应的r和 Mr
3.3 知识存储
知 识 存 储 { 基 于 R D F 的 存 储 : j e n a 、 O r a c l e 12 C + 图 数 据 扩 展 组 件 基 于 图 数 据 库 的 存 储 : N e o 4 j 、 O r i e n t D B 、 J a n u s G r a p h 知识存储\begin{cases} 基于RDF的存储:jena、Oracle\space12C + 图数据扩展组件 \\ 基于图数据库的存储:Neo4j、OrientDB、JanusGraph \end{cases} 知识存储{基于RDF的存储:jena、Oracle 12C+图数据扩展组件基于图数据库的存储:Neo4j、OrientDB、JanusGraph
3.3.1jena
免费开源的支持构建语义网络和数据连接应用的Java框架。
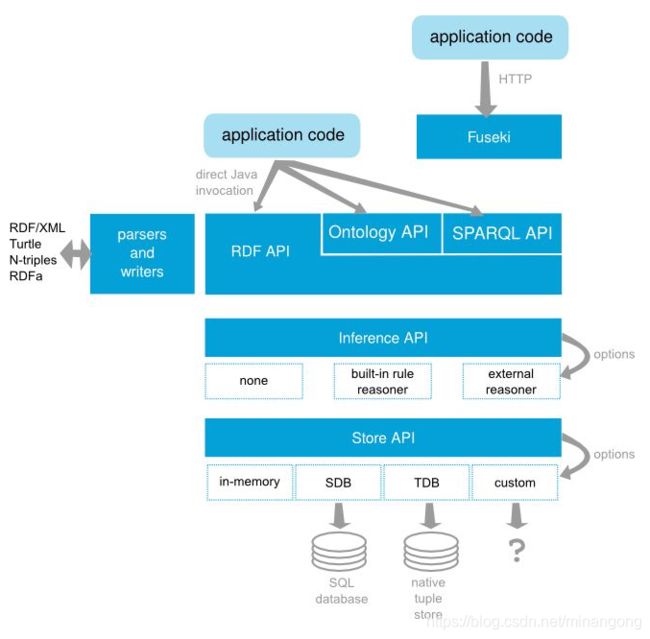
(1)架构
- 最底层的是数据库,包含SQL数据库和原生数据库,其中SDB用来导入SQL数据库, TDB导入RDF三元组。
- 数据库之上的是内建的和外联的推理接口。
- 在往上的是SPARQL查询接口。通过直接使用SPARQL语言或通过REfO等模块转换成SPARQL语言进行查询。
- Fuseki模块,它相当于一个服务器端,操作就是在它提供的端口上进行的。
(2)数据导入:通过Fuseki的手动导入、通过TDB进行导入
/jena-fuseki/tdbloader --loc=/jena-fuseki/data filename
数据导入后启动Fuseki
/jena-fuseki/fuseki-server --loc=/jena-fuseki/data --update /music
(3)查询:通过Fuseki界面查询、使用endpoint接口查询。
3.3.2 jena java代码
// 生成model
Model model = ModelFactory.createDefaultModel();
// 根据知识图谱,添加实体、属性、语义关系
Resource johnSmith = model.createResource(personURI).addProperty(VCARD.FN,fullName).addProperty(VCARD.N,
model.createResource().addProperty(VCARD.Given,givenName).addProperty(VCARD.Family, familyName));
//model导入
InputStream in = FileManager.get().open( inputFileName );
model.read(in, null);
//model导出
model.write(System.out, "RDF/XML-ABBREV");
model.write(System.out, "N-TRIPLES");
//查询
ResIterator iter = model.listResourcesWithProperty(VCARD.FN);
3.4 知识计算与应用
知识计算主要是根据图谱提供的信息得到更多隐含的知识,如通过本体或者规则推理技术可以获取数据中存在的隐含知识;而链接预测则可预测实体间隐含的关系;同时使用社会计算的不同算法在知识网络上计算获取知识图谱上存在的社区,提供知识间关联的路径;通过不一致检测技术发现数据中的噪声和缺陷。
通过基于知识图谱的知识计算可以产生大量的智能应用,如可以提供精确的用户画像,提供领域知识、提供更智能的检索方式,问答。
3.4.1 推荐系统
传统的推荐系统有两个问题:1. 稀疏性,用户与物品的交互信息往往是非常稀疏的。2. 冷启动问题,对于新加入的用户或物品,由于系统没有历史交互信息,无法进行准确的建模和推荐。
解决稀疏性和冷启动问题的一个常见思路是额外引入一些辅助信息作为输入
1. 社交网络:一个用户对某物品感兴趣,他的朋友也可能对该物品感兴趣。
2. 用户/物品属性: 同种属性的用户可能会对同一种物品感兴趣
3. 多媒体信息:图片、视频、音频等
4. 上下文:用户-物品交互的时间、地点等信息
知识图谱:1. 将辅助信息有效地融入推荐算法 2. 从辅助信息中提取有效特征
特性:1.精确性:为物品引入更多语义关系,可以深层次发现用户兴趣
2.多样性:知识图谱提供了不同的关系连接种类,有利于推荐结果的发散。
3.可解释性:根据实体的上下文实体等进行推荐,其语义可知。
3.4.2知识图谱加入推荐系统技术
-
基于特征的推荐的方法:
将用户、物品的属性计为 x x x,该用户和物品之间的交互强度 y ( x ) y(x) y(x)为
y ( x ) : = w 0 + ∑ j = 1 p w j x j + ∑ j = 1 p ∑ j ’ = j + 1 p x j x j ′ ∑ f = 1 k v j , f v j ′ , f ′ y(x):=w0+\sum_{j=1}^{p}{w_jx_j}+\sum_{j=1}^{p}{\sum_{j’=j+1}^{p}{x_jx_{j'}}}\sum_{f=1}^{k}{v_j,fv_{j'},f'} y(x):=w0+∑j=1pwjxj+∑j=1p∑j’=j+1pxjxj′∑f=1kvj,fvj′,f′
p p p个变量的 d d d 阶交叉特征.其中 k k k是分解因子的维度。第一部分是每个输入变量 x j x_j xj的一元交叉,其实就是LR模型。第二部分是输入变量的pairwise的交叉。
它并非专门针对知识图谱设计,因此无法高效地利用知识图谱的全部信息
-
基于路径的推荐方法
将知识图谱视为一个异构信息网络,然后构造物品之间的基于meta-path或meta-graph的特征。这类方法的优点是充分且直观地利用了知识图谱的网络结构,缺点是需要手动设计meta-path或meta-graph
3.4.3知识图谱特征学习
-
依次学习:首先使用知识图谱特征学习得到实体向量和关系向量,然后将这些低维向量引入推荐系统,学习得到用户向量和物品向量
优点:学习模块、推荐系统模块相互独立
缺点:因为相互独立,所以无法做到端对端的训练。
-
联合学习:将知识图谱特征学习和推荐算法的目标函数结合,使用端到端的方法进行联合学习;
优点:推荐系统模块的监督信号可以反馈到知识图谱特征学习中
缺点:训练开销较大
-
交叉学习:将知识图谱特征学习和推荐算法视为两个分离但又相关的任务,使用多任务学习的框架进行交替学习。
实际运用和时间开销,介于依次学习和联合学习之间。
参考资料
[1]钟远薪,夏翠娟. 艺术图像知识图谱构建初探[J].图书馆论坛,2021
[2]肖仰华.知识图谱:概念与技术[M].北京:电子工业出版社, 2020.01.
[3] [为什么需要知识图谱?什么是知识图谱?——KG的前世今生](为什么需要知识图谱?什么是知识图谱?——KG的前世今生 - 知乎 (zhihu.com))
[4] [知识图谱的技术与应用](知识图谱的技术与应用(18版) - 知乎 (zhihu.com))
[5] [知识抽取-实体及关系抽取](知识抽取-实体及关系抽取 - 知乎 (zhihu.com))
[6] [知识抽取与挖掘]((5条消息) [知识图谱]知识抽取与挖掘(I)_盛夏光年-CSDN博客)
[7] [Jena学习笔记(一) RDF](Jena学习笔记(一) RDF - 简书 (jianshu.com))
[8] [知识图谱(二):知识图谱概论(下)]((5条消息) 知识图谱(二):知识图谱概论(下)_yunxiaoMr的博客-CSDN博客)
[9] [推荐算法不够精准?让知识图谱来解决](推荐算法不够精准?让知识图谱来解决 (qq.com))
[10] 如何将知识图谱特征学习应用到推荐系统?