【知识图谱】06推理功能(使用Jena+Fuseki)
目录
1、准备工作
2、实现推理
2.1、生成nt文件
2.2、生成TDB数据
2.3、初始化Fuseki环境
2.4、配置FUSEKI文件
2.5、FUSEKI推理机
1、准备工作
jena和fuseki下载链接:
JENA-3.17: http://jena.apache.org/download/index.cgi
FUSEKI-3.16:https://repo1.maven.org/maven2/org/apache/jena/apache-jena-fuseki/3.16.0/
下载文件如下图:
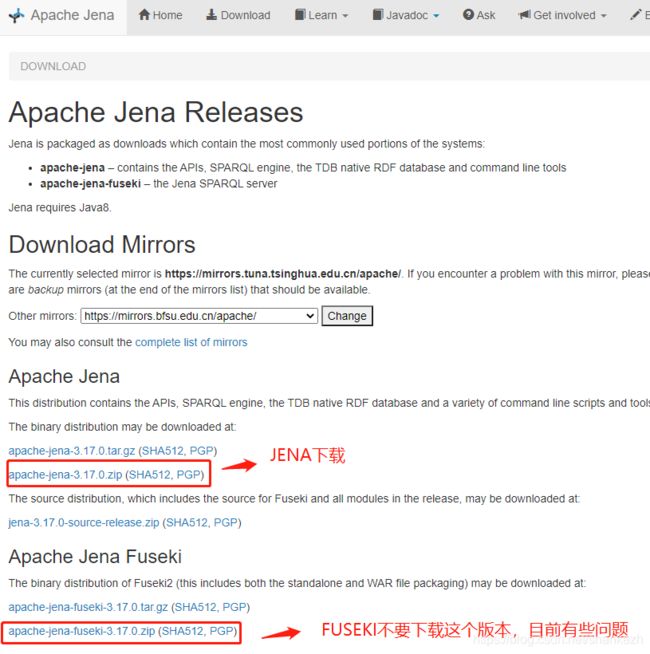
FUSEKI下载这个版本:

当然,你也可以选择你喜欢的版本:https://repo1.maven.org/maven2/org/apache/jena/apache-jena-fuseki/

解压到任意位置,然后配置环境变量:
先建立JENA_HOME变量和FUSEKI_HOME:


再增加环境变量:

环境配置完成。
2、实现推理
2.1、生成nt文件
04节谈到过生成ttl格式的mapping关系文件,现在要利用生成的ttl文件,进一步生成NT(N-TRIPLE)格式的RDF文件,进入到d2rq的目录下,使用如下命令:
dump-rdf.bat -o kg_movie.nt kg_movie_map.ttl在同级目录下,kg_movie.nt就是我们生成的目标文件。
2.2、生成TDB数据
apeach jena使用TDB存储数据,因此我们需要生成TDB数据文件,首先在任意位置建立tdb文件夹,我这里演示建立在jena文件夹中,位置如下:

使用如下命令生成tdb数据文件:
tdbloader.bat --loc="C:\env\apache-jena-3.17.0\tdb" "C:\Program Files\d2rq-0.8.1\kg_movie.nt"其中,tdbloader.bat位于apache-jena文件夹下的bat目录下,配置过环境后可以在任意位置使用命令,--loc参数表示建立的TDB数据库的位置,后面的参数表示为生成的nt文件的路径。
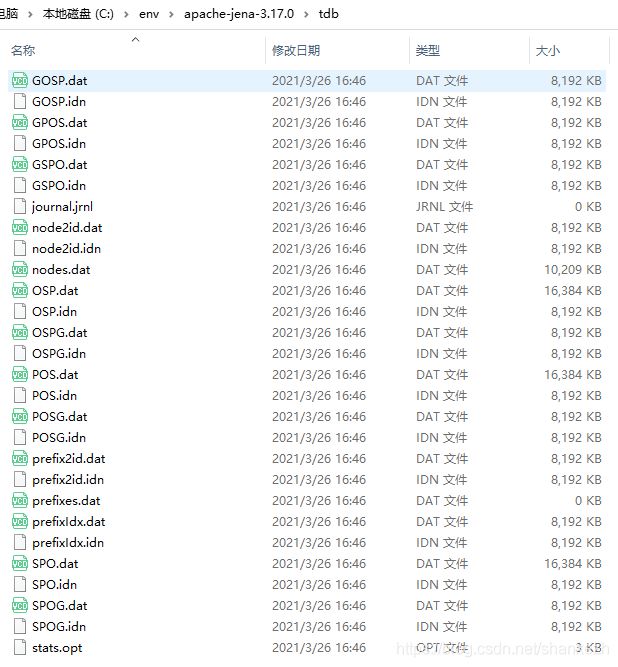
成功后如下图:

tdb目录下出现了对应生成的数据:
2.3、初始化Fuseki环境
这里解释一下为什么不用fuseki-3.17.0版本,我反复搞了一天,在自带的web端中无法显示内容,确认不是配置问题,因此放弃3.17.0版本,无法确定还有什么新问题,毕竟第一步就给折了,总之,先改用3.16.0.
进入之前解压的Fuseki目录下,运行其中的fuseki-server.bat脚本文件进行初始化配置,如下图:

成功后如下图:
此时目录新生成了个run文件夹,表示环境初始化成功:

2.4、配置FUSEKI文件
本系列03节中,曾经有使用过Protege生成过OWL实体文件,这里就要用到了,将其拷贝到生成的上一步生成的run/dabases/目录下,并将后缀从.owl改为.ttl,如下图:
(忽略图中的3.17哈,实际上后来我用的是3.16版本)
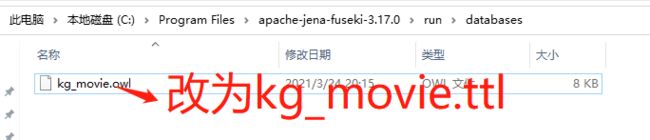
改完如下图:
在 run/configuration/目录下,新建一文件,命名{随意 }.ttl,例如我命名为:kg_movie_conf.ttl:

打开文件,编辑,格式内容如下:
@prefix : .
@prefix tdb: .
@prefix rdf: .
@prefix ja: .
@prefix rdfs: .
@prefix fuseki: .
:service1 a fuseki:Service ;
fuseki:dataset <#dataset> ;
fuseki:name "kg_movie" ;
fuseki:serviceQuery "query" , "sparql" ;
fuseki:serviceReadGraphStore "get" ;
fuseki:serviceReadWriteGraphStore "data" ;
fuseki:serviceUpdate "update" ;
fuseki:serviceUpload "upload" .
<#dataset> rdf:type ja:RDFDataset ;
ja:defaultGraph <#model_inf> ;
.
<#model_inf> rdf:type ja:InfModel ;
ja:baseModel <#baseModel> ;
#ja:reasoner [
# #ja:reasonerURL
# ja:reasonerURL ;
# ja:rulesFrom ;
#] ;
.
<#baseModel> rdf:type ja:UnionModel;
ja:subModel <#ontology>;
ja:rootModel <#tdbGraph>;
.
<#ontology> rdf:type ja:MemoryModel;
ja:content [ja:externalContent ] ;
.
<#tdbGraph> rdf:type tdb:GraphTDB ;
tdb:dataset <#tdbdataset> ;
.
<#tdbdataset> rdf:type tdb:DatasetTDB ;
tdb:location "C:/env/apache-jena-3.17.0/tdb" ;
ja:context [ ja:cxtName "arq:queryTimeout" ; ja:cxtValue "1000" ] ;
. 具体配置修改内容见下图:
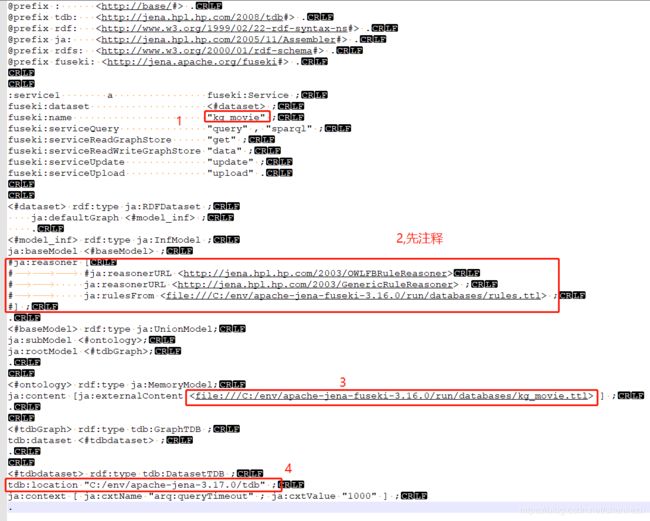
其中:
1、修改成项目数据库名称;
2、配置推理机,其中rules.ttl是我们建立的自定义规则推理机,如果不想用就用#号注释即可,这里先注释掉,待会再用推理机。
3、ontology文件的路径;
4、jena文件夹中建立的tdb文件夹的路径。
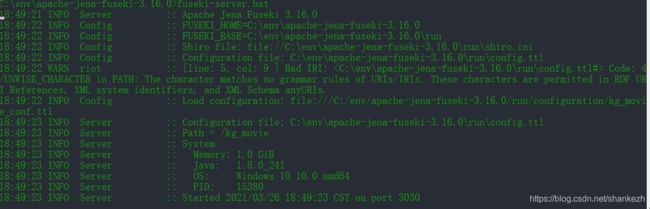
完成,再次启动fuseki-server.bat,ok如下图:
在web端打开localhost:3030:
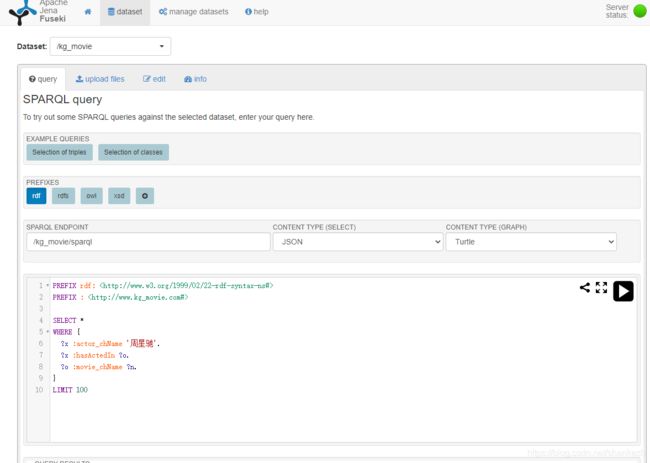
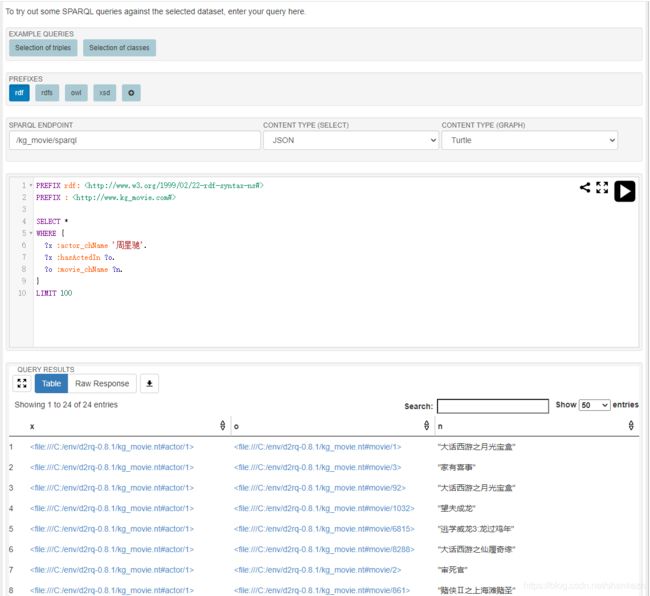
输入我们需要查询的指令,记得引入依赖,这里务必引入kg_movie:
PREFIX rdf:
PREFIX :
SELECT *
WHERE {
?x :actor_chName '周星驰'.
?x :hasActedIn ?o.
?o :movie_chName ?n.
}
LIMIT 100 效果如下图:
2.5、FUSEKI推理机
首先建立规则文件,进入xx目录下,这里创建名称为rules.ttl的文件:

编辑其内容:
@prefix : .
@prefix rdf: .
[ruleComedian: (?p :hasActedIn ?m),(?m :hasGenre ?g),(?g :genre_name '喜剧') -> (?p rdf:type :Comedian)]
[ruleInverse: (?p :hasActedIn ?m) -> (?m :hasActor ?p)] 这里建立了两个规则:
1、喜剧演员:一个演员参演过电影,电影又是喜剧类型,那么他就是喜剧演员,这里的Comedian是我们的推理类型。
2、取反规则:演员参演过,就一定有电影包含某个演员。
编辑kg_movie_conf.ttl文件,将推理机注释打开:
@prefix : .
@prefix tdb: .
@prefix rdf: .
@prefix ja: .
@prefix rdfs: .
@prefix fuseki: .
:service1 a fuseki:Service ;
fuseki:dataset <#dataset> ;
fuseki:name "kg_movie" ;
fuseki:serviceQuery "query" , "sparql" ;
fuseki:serviceReadGraphStore "get" ;
fuseki:serviceReadWriteGraphStore "data" ;
fuseki:serviceUpdate "update" ;
fuseki:serviceUpload "upload" .
<#dataset> rdf:type ja:RDFDataset ;
ja:defaultGraph <#model_inf> ;
.
<#model_inf> rdf:type ja:InfModel ;
ja:baseModel <#baseModel> ;
ja:reasoner [
#ja:reasonerURL
ja:reasonerURL ;
ja:rulesFrom ;
] ;
.
<#baseModel> rdf:type ja:UnionModel;
ja:subModel <#ontology>;
ja:rootModel <#tdbGraph>;
.
<#ontology> rdf:type ja:MemoryModel;
ja:content [ja:externalContent ] ;
.
<#tdbGraph> rdf:type tdb:GraphTDB ;
tdb:dataset <#tdbdataset> ;
.
<#tdbdataset> rdf:type tdb:DatasetTDB ;
tdb:location "C:/env/apache-jena-3.17.0/tdb" ;
ja:context [ ja:cxtName "arq:queryTimeout" ; ja:cxtValue "1000" ] ;
. 
其中,2位置是我们建立的规则文件路径,这里的#号全部删除了,保存文件。
重新运行 fuseki-server.bat,进入web输入推理查询:
查询hasActor如下:
PREFIX rdf:
PREFIX :
SELECT *
WHERE {
?x :movie_chName '家有喜事'.
?x :hasActor ?o.
?o :actor_chName ?n.
}
LIMIT 100 效果:

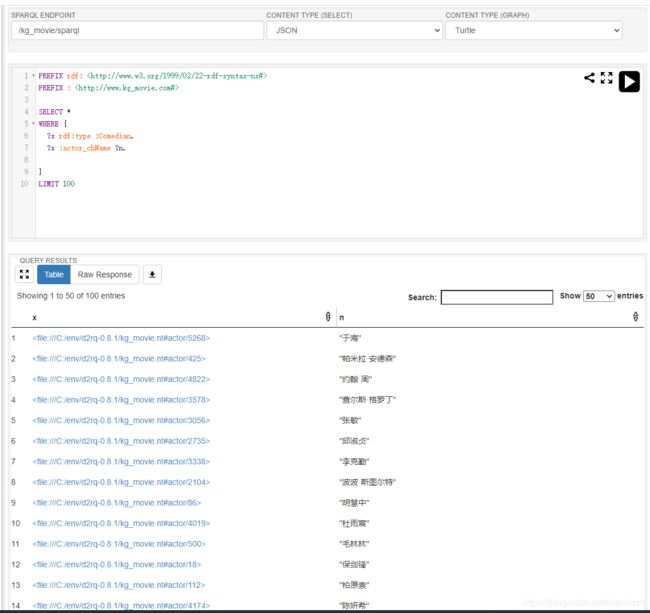
查询喜剧演员:
键入:
PREFIX rdf:
PREFIX :
SELECT *
WHERE {
?x rdf:type :Comedian.
?x :actor_chName ?n.
}
LIMIT 100 效果如下:
完成(这一章还是花了点功夫的,配置那块各种出问题,就差去看fuseki源代码了)。