DAMOYOLO:基于DAMOYOLO训练数据集详细教程
前段时间yolov7的推出引起一篇热潮,接着rmyolo紧跟潮流,后面阿里的达摩院也推出了自己的yolo算法,怎么说呢,damoyolo推出依旧不少天了,现在才写博客,因为damoyolo给我的体验感不是很好。
先看下DAMOYOLO的文章:
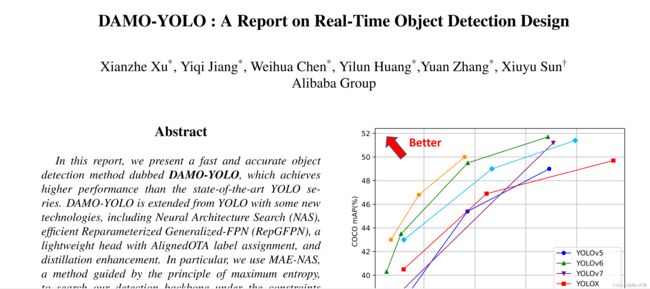
这是DAMOYOLO文章里面速度与map的折线图,从图上看,damoyolo确实很猛
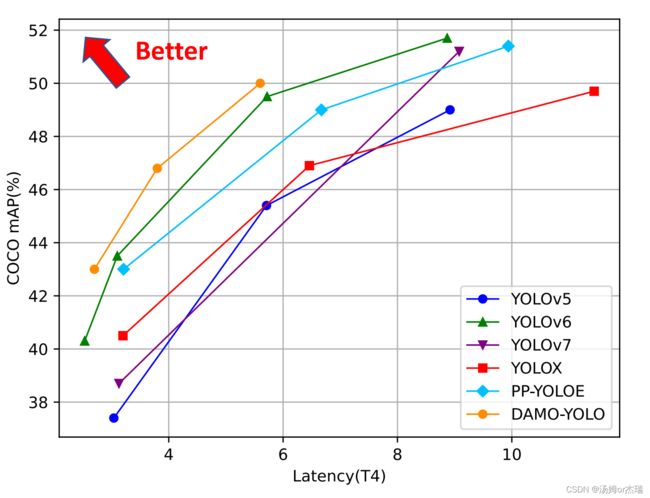
damoyolo的各个模型在COCO上的map.
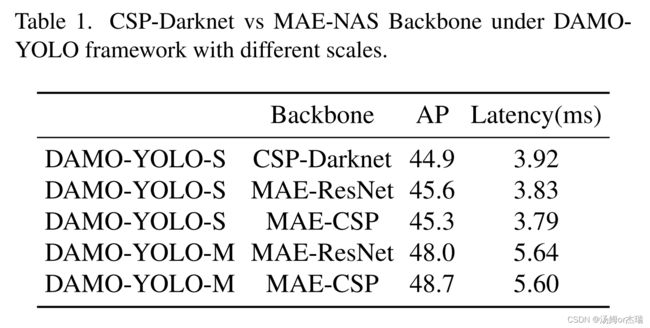
damoyolo的网络结构: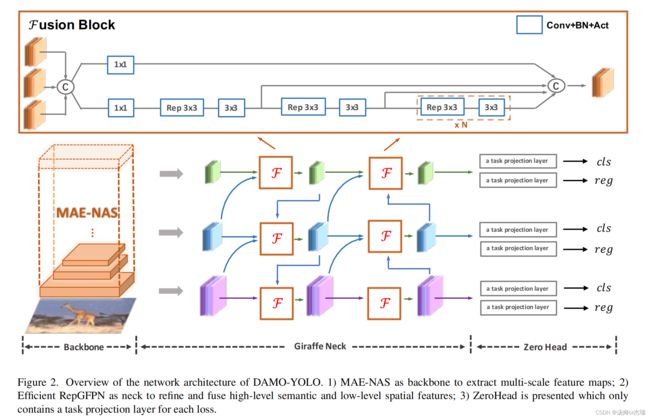
DAMOYOLO的github网址:
https://github.com/tinyvision/DAMO-YOLO下面介绍下如何使用DAMOYOLO训练自己的数据集:
1、YOLO2COCO
damoyolo的数据集格式是coco格式的,v5、v7都是yolo格式的所以我们需要及进行转换。
转换脚本:
import os
import json
import cv2
import random
import time
from PIL import Image
coco_format_save_path='COCO\\val\\' #要生成的标准coco格式标签所在文件夹
yolo_format_classes_path='E:\\YoloV67\\YoloV6_P\\AiTodData\\name.txt' #类别文件,一行一个类
yolo_format_annotation_path='E:\\YoloV67\\YoloV6_P\\AiTodData\\labels\\val\\' #yolo格式标签所在文件夹
img_pathDir='E:\\YoloV67\\YoloV6_P\\AiTodData\\images\\val\\' #图片所在文件夹
with open(yolo_format_classes_path,'r') as fr: #打开并读取类别文件
lines1=fr.readlines()
# print(lines1)
categories=[] #存储类别的列表
for j,label in enumerate(lines1):
label=label.strip()
categories.append({'id':j+1,'name':label,'supercategory':'None'}) #将类别信息添加到categories中
# print(categories)
write_json_context=dict() #写入.json文件的大字典
write_json_context['info']= {'description': '', 'url': '', 'version': '', 'year': 2022, 'contributor': 'xxx', 'date_created': '2022-07-8'}
write_json_context['licenses']=[{'id':1,'name':None,'url':None}]
write_json_context['categories']=categories
write_json_context['images']=[]
write_json_context['annotations']=[]
#接下来的代码主要添加'images'和'annotations'的key值
imageFileList=os.listdir(img_pathDir) #遍历该文件夹下的所有文件,并将所有文件名添加到列表中
for i,imageFile in enumerate(imageFileList):
imagePath = os.path.join(img_pathDir,imageFile) #获取图片的绝对路径
image = Image.open(imagePath) #读取图片,然后获取图片的宽和高
W, H = image.size
img_context={} #使用一个字典存储该图片信息
#img_name=os.path.basename(imagePath) #返回path最后的文件名。如果path以/或\结尾,那么就会返回空值
img_context['file_name']=imageFile
img_context['height']=H
img_context['width']=W
img_context['date_captured']='2022-07-8'
img_context['id']=i #该图片的id
img_context['license']=1
img_context['color_url']=''
img_context['flickr_url']=''
write_json_context['images'].append(img_context) #将该图片信息添加到'image'列表中
if len(imageFile.split('.')) == 2:
txtFile = imageFile.split('.')[0]+'.txt'
else:
print("on")
exit()
# txtFile=imageFile[:5]+'.txt' #获取该图片获取的txt文件
with open(os.path.join(yolo_format_annotation_path,txtFile),'r') as fr:
lines=fr.readlines() #读取txt文件的每一行数据,lines2是一个列表,包含了一个图片的所有标注信息
for j,line in enumerate(lines):
bbox_dict = {} #将每一个bounding box信息存储在该字典中
# line = line.strip().split()
# print(line.strip().split(' '))
class_id,x,y,w,h=line.strip().split(' ') #获取每一个标注框的详细信息
class_id,x, y, w, h = int(class_id), float(x), float(y), float(w), float(h) #将字符串类型转为可计算的int和float类型
xmin=(x-w/2)*W #坐标转换
ymin=(y-h/2)*H
xmax=(x+w/2)*W
ymax=(y+h/2)*H
w=w*W
h=h*H
bbox_dict['id']=i*10000+j #bounding box的坐标信息
bbox_dict['image_id']=i
bbox_dict['category_id']=class_id+1 #注意目标类别要加一
bbox_dict['iscrowd']=0
height,width=abs(ymax-ymin),abs(xmax-xmin)
bbox_dict['area']=height*width
bbox_dict['bbox']=[xmin,ymin,w,h]
bbox_dict['segmentation']=[[xmin,ymin,xmax,ymin,xmax,ymax,xmin,ymax]]
write_json_context['annotations'].append(bbox_dict) #将每一个由字典存储的bounding box信息添加到'annotations'列表中
name = os.path.join(coco_format_save_path,"val"+ '.json')
with open(name,'w') as fw: #将字典信息写入.json文件中
json.dump(write_json_context,fw,indent=2)
最终的数据集格式如下所示:其中annotations为三个json文件(train、val、test),test、train、val为图片文件夹。
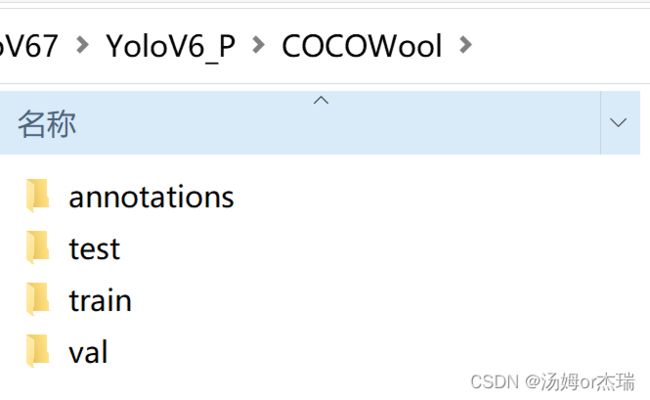
数据集制作完成,接下来配置文件。
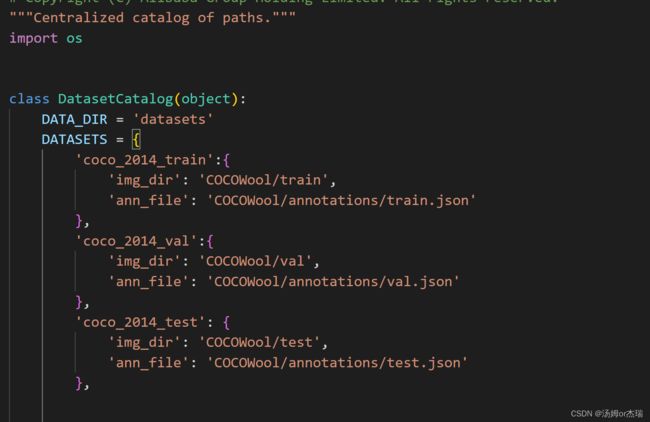
打开damo/config/paths_catalog.py 按照一下进行配置:
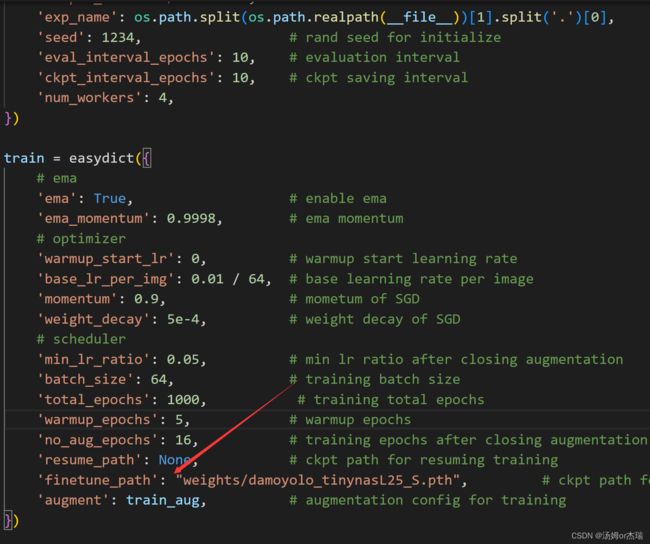
再打开base.py 配置一下预训练模型:我使用的是s预训练模型
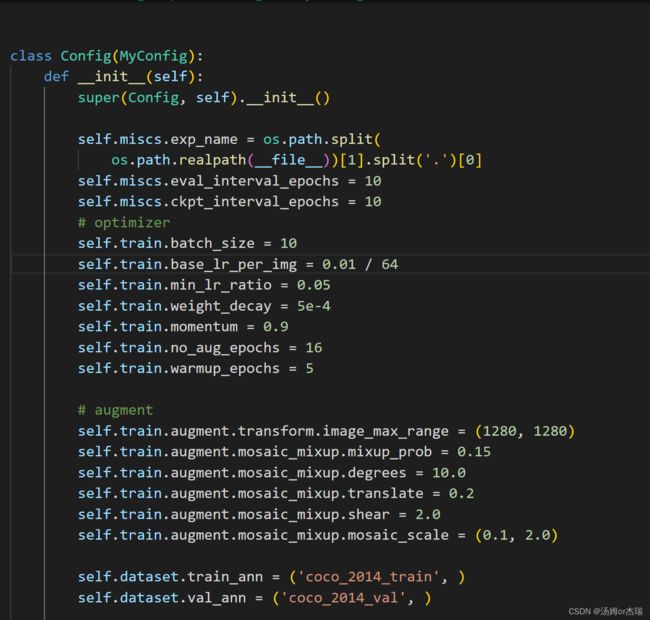
打开config/damoyolo_tinynasL25_S.py 进行参数微调,比如修改输入图像的尺寸,迭代次数。。。。
接下来,,,,大家按照官网创建一个新的虚拟环境,记住版本啥的都要和官网的对应上。(我之前试过用py3.9进行训练的结果卡在了第17轮就不动了)
下面就是damoyolo 的训练过程,,,说实话速度贼慢(s是真的慢,早上10点多开训的,距离此时此刻训练了300轮不到),而且同样的数据集v5表现比他好(收敛速度快)
v5训练:
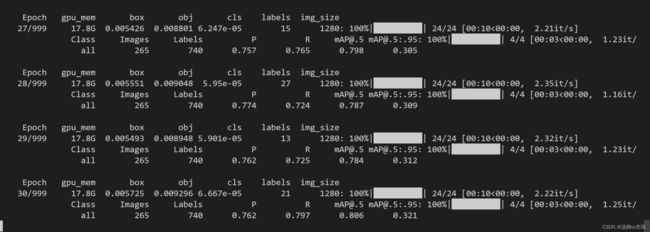
只能这么说damoyolo改动的地方很多,比如repfpn、zerohead、nas..........但是我还是选择v5!!!!!!!!!!!!!!!!