Chapter7 循环神经网络-2
文章目录
- 5、LSTM & GRU
-
- 5.1、长短时记忆网络(Long Short-Term Memory, LSTM)
-
- 5.1.1、相关概念
- 5.1.2、从零开始实现
- 5.1.3、简洁实现
- 5.2、门控循环单元(Gated Recurrent Unit, GRU)
-
- 5.2.1、相关概念
- 5.2.2、模型实现
- 6、深度循环神经网络
- 7、双向循环神经网络(Bi-RNN)
- 8、RNN更多的应用
第一部分地址
5、LSTM & GRU
在实际应用中,上述的标准循环神经网络的优化算法面临一个很大的问题,就是长期依赖问题——由于网络结构的变深使得模型丧失了学习到先前信息的能力。简单来说,标准的循环神经网络实际上虽然有了记忆,但很健忘。当时间步较大或者时间步
当时间步较大或者时间步较小时,循环神经网络的梯度比较容易出现衰减或爆炸。虽然裁剪梯度能够应对梯度爆炸,但无法解决梯度衰减的问题。由于这个原因,循环神经网络在实际中较难捕捉时间序列中时间步距离较大的依赖问题,无法实现长时记忆。那如何解决这个问题?解决RNN中梯度消失方法很多,常用的有:
- 选取更好的激活函数,如ReLU激活函数。ReLU函数的左侧导数为0,右侧导数恒为1,这就避免了“梯度消失”的发生。
- 加入Batch Normalization层,其优点可以包括可以加速收敛、控制过拟合。
- 修改网络的结构,LSTM和GRU可以有效的解决这个问题。
下面LSTM和GRU是如何进行工作的。
5.1、长短时记忆网络(Long Short-Term Memory, LSTM)
5.1.1、相关概念
LSTM中引入了3个门,即输入门(input gate)、遗忘门(forget gate)和输出门(output gate),以及与隐藏状态形状相同的记忆细胞。
LSTM用两个门来控制记忆细胞 C C C的内容,一个是遗忘门,它决定了上一时刻的记忆细胞 C t − 1 C_{t-1} Ct−1有多少保留到当前时刻 C t C_t Ct;另一个是输入门,它决定了当前时刻网络的输入 X t X_t Xt有多少保存到记忆细胞 C t C_t Ct。LSTM用输出门来控制单元状态 C t C_t Ct有多少输出到LSTM的当前输出值 H t H_t Ht。LSTM的循环结构如下图所示:
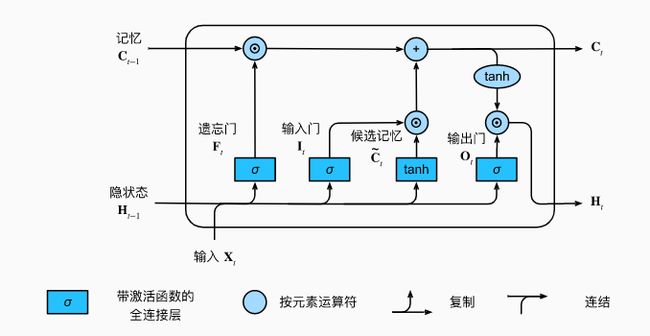
假设隐藏单元特征向量长度为 h h h,给定时间步 t t t的小批量输入 X t ∈ R x × d X_t \in R^{x \times d} Xt∈Rx×d(样本数为n,输入的向量长度为d)和上一时间步隐藏状态 H t − 1 ∈ R n × h H_{t-1} \in R^{n \times h} Ht−1∈Rn×h。时间步t的输入门 I t ∈ R n × h I_t \in R^{n \times h} It∈Rn×h、遗忘门 F t ∈ R n × h F_t \in R^{n \times h} Ft∈Rn×h和输出门 O t ∈ R n × h O_t \in R^{n \times h} Ot∈Rn×h分别计算如下:
I t = σ ( X t W x i + H t − 1 W h i + b i ) F t = σ ( X t W x f + H t − 1 W h f + b f ) O t = σ ( X t W x o + H t − 1 W h o + b o ) I_t = \sigma(X_tW_{xi}+H_{t-1}W_{hi}+b_i)\\ F_t = \sigma(X_tW_{xf}+H_{t-1}W_{hf}+b_f)\\ O_t = \sigma(X_tW_{xo}+H_{t-1}W_{ho}+b_o) It=σ(XtWxi+Ht−1Whi+bi)Ft=σ(XtWxf+Ht−1Whf+bf)Ot=σ(XtWxo+Ht−1Who+bo)
其中的 W x i , W x f , W x o ∈ R d × h W_{xi},W_{xf},W_{xo} \in R^{d \times h} Wxi,Wxf,Wxo∈Rd×h和 W h i , W h f , W h o ∈ R h × h W_{hi},W_{hf},W_{ho} \in R^{h \times h} Whi,Whf,Who∈Rh×h是权重参数, b i , b f , b o ∈ R 1 × h b_i,b_f,b_o \in R^{1 \times h} bi,bf,bo∈R1×h是偏差参数。
时间步t的候选记忆细胞 C ~ t ∈ R n × h \tilde{C}_t \in R^{n \times h} C~t∈Rn×h的计算为:
C ~ t = t a n h ( X t W x c + H t − 1 W h c + b c ) \tilde{C}_t = tanh(X_tW_{xc}+H_{t-1}W_{hc}+b_c) C~t=tanh(XtWxc+Ht−1Whc+bc)
其中 W x c ∈ R d × h W_{xc} \in R^{d \times h} Wxc∈Rd×h和 W h c ∈ R h × h W_{hc} \in R^{h \times h} Whc∈Rh×h是权重参数, b c ∈ R 1 × h b_c\in R^{1 \times h} bc∈R1×h是偏差参数。
当前时间步的记忆细胞 C t ∈ R n × h C_t \in R^{n \times h} Ct∈Rn×h的计算组合了上一时间步记忆细胞和当前时间步候选记忆细胞的信息,并通过遗忘门和输入门进行控制合成:
C t = F t ⨀ C t − 1 + I t ⨀ C ~ t C_t = F_t \bigodot C_{t-1} + I_t \bigodot \tilde{C}_t Ct=Ft⨀Ct−1+It⨀C~t
这个设计可以应对循环神经网络中的梯度衰减问题,并更好地捕捉时间序列中时间步距离较大的依赖关系。
有了当前时间步的记忆细胞后,就可以通过输出门来控制从记忆细胞到隐藏状态 H t ∈ R n × h H_t\in R^{n \times h} Ht∈Rn×h的信息流动:
H t = O t ⨀ t a n h ( C t ) H_t = O_t \bigodot tanh(C_t) Ht=Ot⨀tanh(Ct)
LSTM的完整的计算过程为:
I t = σ ( X t W x i + H t − 1 W h i + b i ) F t = σ ( X t W x f + H t − 1 W h f + b f ) O t = σ ( X t W x o + H t − 1 W h o + b o ) C ~ t = t a n h ( X t W x c + H t − 1 W h c + b c ) C t = F t ⨀ C t − 1 + I t ⨀ C ~ t H t = O t ⨀ t a n h ( C t ) I_t = \sigma(X_tW_{xi}+H_{t-1}W_{hi}+b_i)\\ F_t = \sigma(X_tW_{xf}+H_{t-1}W_{hf}+b_f)\\ O_t = \sigma(X_tW_{xo}+H_{t-1}W_{ho}+b_o)\\ \tilde{C}_t = tanh(X_tW_{xc}+H_{t-1}W_{hc}+b_c)\\ C_t = F_t \bigodot C_{t-1} + I_t \bigodot \tilde{C}_t\\ H_t = O_t \bigodot tanh(C_t) It=σ(XtWxi+Ht−1Whi+bi)Ft=σ(XtWxf+Ht−1Whf+bf)Ot=σ(XtWxo+Ht−1Who+bo)C~t=tanh(XtWxc+Ht−1Whc+bc)Ct=Ft⨀Ct−1+It⨀C~tHt=Ot⨀tanh(Ct)
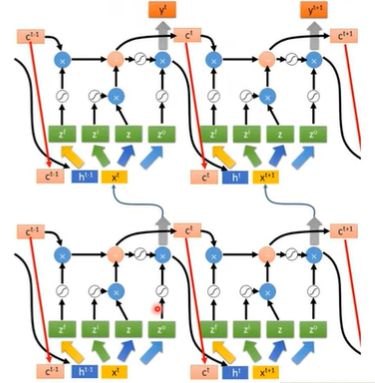
上面介绍的只是一个LSTM单元,而在一个多层的LSTM中,是由许许多多个这样的LSTM单元组成的,它的复杂程度是非常恐怖的,下面是它的一部分的结构图:
5.1.2、从零开始实现
下面从零实现LSTM,与RNN的实现过程一样,也使用The Time Machine数据集,实现导入所使用的包并加载数据集。由于重点为怎么从零实现LSTM的结构以加深对LSTM的理解,因此数据加载以处理的代码就不再过多描述。
import torch
from torch import nn
from d2l import torch as d2l
from torch.nn import functional as F
batch_size, num_steps = 32,35
train_iter, vocab = load_data_time_machine(batch_size,num_steps)
初始化模型参数
对模型中所使用的参数进行初始化,num_hiddens指的是隐藏单元的特征向量的长度。
#初始化模型参数
def get_lstm_param(vocab_size,num_hiddens,device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size = shape, device = device) * 0.01
def three():
return (normal((num_inputs,num_hiddens)),
normal((num_hiddens,num_hiddens)),
torch.zeros(num_hiddens,device = device))
#输入门参数
W_xi,W_hi,b_i = three()
# 遗忘门参数
W_xf, W_hf, b_f = three()
# 输出门参数
W_xo, W_ho, b_o = three()
# 候选记忆单元参数
W_xc, W_hc, b_c = three()
#输出层参数
W_hq = normal((num_hiddens,num_outputs))
b_q = torch.zeros(num_outputs,device = device)
#因为需要计算梯度,将参数的requires_grad属性设置为True
params = [W_xi,W_hi,b_i,W_xf, W_hf, b_f,W_xo, W_ho, b_o,W_xc, W_hc, b_c,W_hq,b_q]
for param in params:
param.requires_grad_(True)
return params
对隐藏单元和记忆单元进行初始化
LSTM在处理第一个时间步的时候,还需要一个初始的隐藏状态和记忆单元,因此需要获得初始的隐藏状态和记忆单元。
#初始状态的隐状态和记忆单元
def init_lstm_state(batch_size,num_hiddens,device):
return (torch.zeros((batch_size,num_hiddens),device = device),
torch.zeros((batch_size,num_hiddens),device = device))
LSTM核心计算过程
模型的计算需要三个门和一个额外的记忆单元。只有隐状态才会传递到输出层,而记忆单元 C t C_t Ct不会直接参与到输出计算中。
#定义lstm单元的计算过程,输入为三个门和一个额外记忆单元,只有隐状态才会传递到输出层,记忆单元不会参与输出计算
def lstm(inputs,state,params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params
(H,C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs,dim=0),(H,C)
对模型的各部分进行整个,得到完整的LSTM
下面将模型参数初始化,初始状态,以及lstm计算过程进行整合,得到一个完整的可以用于模型训练的网络。
#将上述操作进行整合,得到一个完整的LSTM
class LSTMModelScratch:
def __init__(self,vocab_size,num_hiddens,device,get_params,init_state,forward_fn):
self.vocab_size,self.num_hiddens = vocab_size,num_hiddens
self.params = get_params(vocab_size,num_hiddens,device)
self.init_state,self.forward_fn = init_state,forward_fn
def __call__(self,X,state):
X = F.one_hot(X.T,self.vocab_size).type(torch.float32)
return self.forward_fn(X,state,self.params)
def begin_state(self,batch_size,device):
return self.init_state(batch_size,self.num_hiddens,device)
训练和预测
使用定义的LSTM模型,然后使用RNN所使用的模型训练和预测过程对LSTM模型进行训练。
vocab_size,num_hiddens,device = len(vocab),256,try_gpu()
num_epochs,lr = 500,1
model = LSTMModelScratch(len(vocab),num_hiddens,device,get_lstm_param,
init_lstm_state,lstm)
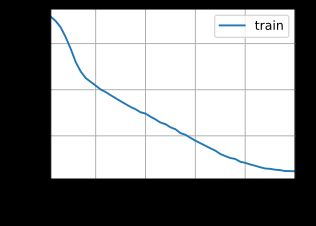
train(model,train_iter,vocab,lr,num_epochs,device)
困惑度 1.2, 24859.8 词元/秒 cuda:0
time traveller for somephing sofiens which there is to not meact
traveller har in the mericcitnemoter procectithe oflicttyen
代码整合
# -*- coding: utf-8 -*-
# @Time : 2022/4/22 17:37
# @Author : tiancn
import collections
import re
import random
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
#1. 数据处理部分
#传入time_machine数据集的下载地址以及哈希校验码
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
#将time_machine数据集加载到文本行的列表中
def read_time_machine():
#下载timemachine.txt文件,并打开文件按行读取内容
with open(d2l.download('time_machine'),'r') as f:
lines = f.readlines()
#re.sub('[^A-Za-z]+',' ',line):使用正则表达式匹配多个连续的非字母,将它们替换为空格
#strip(); 去除字符串两边的空格
#lower():转换字符串中所有大写字符为小写。
return [re.sub('[^A-Za-z]+',' ',line).strip().lower() for line in lines]
#将文本拆分为单词或者字符词元
def tokenize(lines, token = 'word'):
#拆分为单词
if token == 'word':
return [line.split() for line in lines]
#拆分为字符
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:'+token)
#统计词元的频率,返回每个词元及其出现的次数,以一个字典形式返回。
def count_corpus(tokens):
#这里的tokens是一个1D列表或者是2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
#将词元列表展平为一个列表
tokens = [token for line in tokens for token in line]
#该方法用于统计某序列中每个元素出现的次数,以键值对的方式存在字典中。
return collections.Counter(tokens)
#文本词表
class Vocab:
def __init__(self,tokens = None, min_freq = 0, reserved_tokens = None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
#按照单词出现频率排序
counter = count_corpus(tokens)
#counter.items():为一个字典
#lambda x:x[1]:对第二个字段进行排序
#reverse = True:降序
self._token_freqs = sorted(counter.items(),key = lambda x:x[1],reverse = True)
#未知单词的索引为0
#idx_to_token用于保存所有未重复的词元
self.idx_to_token = ['' ] + reserved_tokens
#token_to_idx:是一个字典,保存词元和其对应的索引
self.token_to_idx = {token:idx for idx,token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
#min_freq为最小出现的次数,如果小于这个数,这个单词被抛弃
if freq < min_freq:
break
#如果这个词元未出现在词表中,将其添加进词表
if token not in self.token_to_idx:
self.idx_to_token.append(token)
#因为第一个位置被位置单词占据
self.token_to_idx[token] = len(self.idx_to_token) - 1
#返回词表的长度
def __len__(self):
return len(self.idx_to_token)
#获取要查询词元的索引,支持list,tuple查询多个词元的索引
def __getitem__(self, tokens):
if not isinstance(tokens,(list,tuple)):
#self.unk:如果查询不到返回0
return self.token_to_idx.get(tokens,self.unk)
return [self.__getitem__(token) for token in tokens]
# 根据索引查询词元,支持list,tuple查询多个索引对应的词元
def to_tokens(self,indices):
if not isinstance(indices,(list,tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self):
return 0
@property
def token_freqs(self):
return self._token_freqs
#返回The Time Machine数据集的词元索引别表和词表
def load_corpus_time_machine(max_tokens = -1):
lines = read_time_machine()
tokens = tokenize(lines,'char')
vocab = Vocab(tokens)
#因为The Time Machine数据集中的每个文本行不一定是一个句子或者是一个段落
#所以将所有文本行展平到一个列表中
#保存数据集中每个字符的索引
corpus = [vocab[token] for line in tokens for token in line]
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus,vocab
#2.读取处理好的数据,以便于模型训练
# 使用随机抽样生成一个小批量子序列
def seq_data_iter_random(corpus, batch_size, num_steps):
# 随机偏移量开始对序列进行分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):]
# 减去1,是因为需要考虑标签
# num_subseqs:表示分割的序列的条数
num_subseqs = (len(corpus) - 1) // num_steps
# 长度为num_steps的子序列的起始索引编号
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 在随机抽样的迭代过程中,来自两个相邻的、随机的、小批量的子序列不一定在原始序列上相邻
# 因此将起始索引编号打乱
random.shuffle(initial_indices)
# 返回从pos位置开始的长度为num_steps的序列
def data(pos):
return corpus[pos: pos + num_steps]
# 表示一共有多少个批量
num_batches = num_subseqs // batch_size
# 从0到批量大小×批量的数量遍历,间隔为批量大小,即从循环次数为批量的数量
for i in range(0, batch_size * num_batches, batch_size):
# initial_indices包含子序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
# 按照起始索引获取每一个样本和标签序列。
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
# 返回一个可以用来迭代(for循环)的生成器,因为按照批量大小,返回的数据是多条的
yield torch.tensor(X), torch.tensor(Y)
# 使用相邻采样生成一个小批量子序列
def seq_data_iter_sequential(corpus, batch_size, num_steps):
# 从随机偏移量开始划分序列
offest = random.randint(0, num_steps)
# 获取用于最终训练的序列,因为有偏移量和不能整除,因此对输入的序列进行处理
num_tokens = ((len(corpus) - offest - 1) // batch_size) * batch_size
# 样本序列
Xs = torch.tensor(corpus[offest:offest + num_tokens])
# 标签序列
Ys = torch.tensor(corpus[offest + 1: offest + num_tokens + 1])
# 转为2维数据,行代表不同批次
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
# 为批次的数量
num_batchs = Xs.shape[1] // num_steps
# 循环输出
for i in range(0, num_steps * num_batchs, num_steps):
X = Xs[:, i:i + num_steps]
Y = Ys[:, i:i + num_steps]
yield X, Y
#加载序列数据的迭代器
class SeqDataLoader:
def __init__(self,batch_size,num_steps,use_random_iter,max_tokens):
if use_random_iter:
self.data_iter_fn = seq_data_iter_random
else:
self.data_iter_fn = seq_data_iter_sequential
self.corpus, self.vocab = load_corpus_time_machine(max_tokens)
self.batch_size,self.num_steps = batch_size,num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus,self.batch_size,self.num_steps)
#返回时光机器数据集的迭代器和词表
def load_data_time_machine(batch_size,num_steps,use_random_iter = False,max_tokens = 10000):
data_iter = SeqDataLoader(batch_size,num_steps,use_random_iter,max_tokens)
return data_iter,data_iter.vocab
#3.LSTM神经网络搭建部分
#初始化模型参数
def get_lstm_param(vocab_size,num_hiddens,device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size = shape, device = device) * 0.01
def three():
return (normal((num_inputs,num_hiddens)),
normal((num_hiddens,num_hiddens)),
torch.zeros(num_hiddens,device = device))
#输入门参数
W_xi,W_hi,b_i = three()
# 遗忘门参数
W_xf, W_hf, b_f = three()
# 输出门参数
W_xo, W_ho, b_o = three()
# 候选记忆单元参数
W_xc, W_hc, b_c = three()
#输出层参数
W_hq = normal((num_hiddens,num_outputs))
b_q = torch.zeros(num_outputs,device = device)
#因为需要计算梯度,将参数的requires_grad属性设置为True
params = [W_xi,W_hi,b_i,W_xf, W_hf, b_f,W_xo, W_ho, b_o,W_xc, W_hc, b_c,W_hq,b_q]
for param in params:
param.requires_grad_(True)
return params
#初始状态的隐状态和记忆单元
def init_lstm_state(batch_size,num_hiddens,device):
return (torch.zeros((batch_size,num_hiddens),device = device),
torch.zeros((batch_size,num_hiddens),device = device))
#定义lstm单元的计算过程,输入为三个门和一个额外记忆单元,只有隐状态才会传递到输出层,记忆单元不会参与输出计算
def lstm(inputs,state,params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] = params
(H,C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs,dim=0),(H,C)
#将上述操作进行整合,得到一个完整的LSTM
class LSTMModelScratch:
def __init__(self,vocab_size,num_hiddens,device,get_params,init_state,lstm):
self.vocab_size,self.num_hiddens = vocab_size,num_hiddens
self.params = get_params(vocab_size,num_hiddens,device)
self.init_state,self.lstm = init_state,lstm
def __call__(self,X,state):
X = F.one_hot(X.T,self.vocab_size).type(torch.float32)
return self.lstm(X,state,self.params)
def begin_state(self,batch_size,device):
return self.init_state(batch_size,self.num_hiddens,device)
#使用GPU
#如果存在,则返回gpu(i),否则返回cpu
def try_gpu(i=0):
if torch.cuda.device_count()>=i+1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
#4.预测部分
#在prefix后面生成新字符
def predict(prefix, num_preds, net, vocab, device):
# 获取初始状态
state = net.begin_state(batch_size=1, device=device)
# 保存输出的字符
outputs = [vocab[prefix[0]]]
# 获得当前时间步的输入,为输出列表的最后一个字符
get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))
# 预热期
for y in prefix[1:]:
_, state = net(get_input(), state)
outputs.append(vocab[y])
# 预测num_pred步
for _ in range(num_preds):
y, state = net(get_input(), state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
return ''.join([vocab.idx_to_token[i] for i in outputs])
#5.模型训练部分
#裁剪梯度
def grad_clipping(net,theta):
if isinstance(net,nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
# 自定义优化器
def sgd(params, lr, batch_size):
# 小批量随机梯度下降
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
def train(net, train_iter, vocab, lr, num_epochs, device, use_random_iter=False):
# 交叉熵损失函数
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',
legend=['train'], xlim=[10, num_epochs])
if isinstance(net, nn.Module):
updater = torch.optim.SGD(net.parameters(), lr)
else:
updater = lambda batch_size: sgd(net.params, lr, batch_size)
predict_ = lambda prefix: predict(prefix, 50, net, vocab, device)
for epoch in range(num_epochs):
state, timer = None, d2l.Timer()
# 记录损失之和,词元数量
metric = d2l.Accumulator(2)
for X, Y in train_iter:
# 第一次迭代或者使用随机抽样是初始化state
if state is None or use_random_iter:
state = net.begin_state(batch_size=X.shape[0], device=device)
else:
if isinstance(net, nn.Module) and not isinstance(state, tuple):
state.detach_()
else:
for s in state:
s.detach_()
# 更改标签形状,与输出一样,便于计算损失
y = Y.T.reshape(-1)
X, y = X.to(device), y.to(device)
# 返回输出和状态
y_hat, state = net(X, state)
# 计算损失
l = loss(y_hat, y.long()).mean()
# 针对优化器是pytotch还是自定义有不同的优化方法
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad()
l.backward()
grad_clipping(net, 1)
updater.step()
else:
l.backward()
grad_clipping(net, 1)
updater(batch_size=1)
metric.add(l * y.numel(), y.numel())
# 返回困惑度和平均用时
ppl, speed = math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
if (epoch + 1) % 10 == 0:
print(predict_('time traveller'))
animator.add(epoch + 1, [ppl])
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
#定义参数,训练模型
#6. 获取数据,实例化模型,训练模型并预测
#批量大小,时间步长
batch_size, num_steps = 32,35
#训练轮次,学习率
num_epochs, lr = 500, 1
#隐藏层特征数量
num_hiddens = 512
#返回时光机器数据集的迭代器和词表
#train_iter中已经将样本和标签处理好,并且将数据以索引的形式保存
#vocab为词表,用于将相应的索引转为文本
train_iter,vocab = load_data_time_machine(batch_size, num_steps)
#定义模型
net = LSTMModelScratch(len(vocab),num_hiddens,try_gpu(),get_lstm_param,init_lstm_state,lstm)
#训练模型
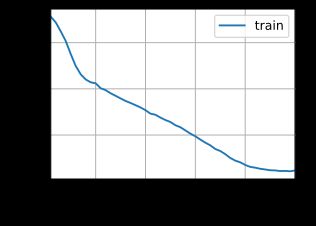
train(net, train_iter, vocab, lr, num_epochs, try_gpu())
困惑度 1.2, 16917.7 词元/秒 cuda:0
#使用训练的模型进行预测
predict('time traveller', 50, net, vocab, try_gpu())
'time traveller for so it will be convenient to speak of himwas e'
5.1.3、简洁实现
下面使用Pytorch中的关于LSTM的相关函数实现LSTM,并使用之前的The Time Machine数据集对模型进行训练。与RNN类型,Pytorch同样有两个函数可以实现LSTM,即torch.nn.LSTM和torch.nn.LSTMCell。它们之间的区别也和torch.nn.RNN和torch.nn.RNNCell是一样的,下面主要介绍torch.nn.LSTM,并使用它搭建一个LSTM模型。
torch.nn.LSTM在Pytorch中的结构为:
torch.nn.LSTM(*args, **kwargs)
它的相关参数与RNN类似有:
input_size:输入x中预期特征数量hidden_size:隐藏层的特征数量num_layers:循环层数。设置num_layers=2意味着将两个LSTM堆叠在一起形成一个堆叠的LSTM,第二个LSTM接受第一个LSTM的输出并计算最终结果。默认为1.bias:如果是False,该层层就不会使用偏置权重,默认是Truebatch_first:如果为True的话,那么输入Tensor的shape应该是(batch,seq,feature),输出也是这样。默认为False,即网络输入为(seq,batch,feature),即序列长度、批次大小、特征维度dropout:如果值非零(参数的取值范围在0-1之间),那么除了最后一层外,其他层的输出都会加上一个dropout层,默认为0bidirectional:如果True,将变成一个双向的LSTM,默认为False。proj_size:如果大于0,将使用LSTM与相应大小的投影。默认值:0。
函数torch.nn.RNN()的输入为输入特征特征、隐藏状态和记忆单元,记为 ( x t , ( h 0 , c 0 ) ) (x_t,(h_0,c_0)) (xt,(h0,c0)),输出包括输出特征、输出隐藏状态和输出记忆单元,记为 ( o u t p u t t , ( h n , c n ) ) (output_t,(h_n,c_n)) (outputt,(hn,cn))。其中输出的output_t为每一时间步隐藏状态的集合,没有经过线性层,因此使用完LSTM后一般还需要使用线性层,而 h n h_n hn和 c n c_n cn为当前时间步的隐藏状态和记忆单元。
输入特征 x t x_t xt的形状为 ( L , N , H i n ) (L,N,H_{in}) (L,N,Hin),分别为序列长度,批量大小,输入尺寸(就是一个词向量的长度,在这里指的是one-hot编码的长度)。而当batch_first=True时,输入的形状为 ( N , L , H i n ) (N,L,H_{in}) (N,L,Hin)。
h_0:张量的形状为 ( D ∗ n u m l a y e r s , N , H o u t ) (D * num_layers,N,H_{out}) (D∗numlayers,N,Hout),如果没有提供该参数,则为0。
c_0:张量的形状为 ( D ∗ n u m l a y e r s , N , H c e l l ) (D * num_layers,N,H_{cell}) (D∗numlayers,N,Hcell),如果没有提供该参数,则为0。
输入特征 o u t p u t t output_t outputt的形状为 ( L , N , D ∗ H o u t ) (L,N,D * H_{out}) (L,N,D∗Hout),分别为序列长度,批量大小,输出尺寸(其中D为是否双向,为1是单向,2为双向)。而当batch_first=True时,输入的形状为 ( N , L D ∗ H o u t ) (N,LD * H_{out}) (N,LD∗Hout)。其中包含每一个时间步LSTM最后一层的输出。
h_n:张量的形状为 ( D ∗ n u m l a y e r s , N , H o u t ) (D * num_layers,N,H_{out}) (D∗numlayers,N,Hout),包含序列中每个元素最终隐状态(即最后一个时间步的隐状态)。
c_n:张量的形状为 ( D ∗ n u m l a y e r s , N , H c e l l ) (D * num_layers,N,H_{cell}) (D∗numlayers,N,Hcell),包含序列中每个元素最终的记忆细胞信息(最后一个时间步的记忆细胞信息)。
下面搭建模型试试吧!
还是老样子,导包,加载数据集。
import torch
from torch import nn
from d2l import torch as d2l
from torch.nn import functional as F
batch_size, num_steps = 32,35
train_iter, vocab = load_data_time_machine(batch_size,num_steps)
下面就使用Pytorch中的torch.nn.LSTM函数搭建模型。
class LSTMModel(nn.Module):
def __init__(self,input_size,num_hiddens,**kwargs):
super(LSTMModel, self).__init__(**kwargs)
self.lstm = nn.LSTM(input_size,num_hiddens)
self.vocab_size = input_size
self.num_hiddens = num_hiddens
# 如果LSTM是双向的,num_directions应该是2,否则应该是1
if not self.lstm.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens,self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2,self.vocab_size)
def forward(self,inputs,state):
X = F.one_hot(inputs.T.long(),self.vocab_size)
X = X.to(torch.float32)
#staet为一个元组,包含了隐藏状态和记忆单元
Y,state = self.lstm(X,state)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# 它的输出形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output,state
def begin_state(self, device, batch_size=1):
# nn.LSTM以元组作为隐状态
return (torch.zeros((self.num_directions * self.lstm.num_layers,
batch_size,self.num_hiddens),device=device),
torch.zeros((self.num_directions * self.lstm.num_layers,
batch_size,self.num_hiddens),device=device))
下面就实例化模型,并使用数据集对模型进行训练。
device = try_gpu()
#实例化模型
net = LSTMModel(input_size=len(vocab),num_hiddens=num_hiddens)
net = net.to(device)
#模型训练
num_epochs,lr = 500,1
train(net,train_iter,vocab,lr,num_epochs,device)
困惑度 1.0, 40644.4 词元/秒 cuda:0
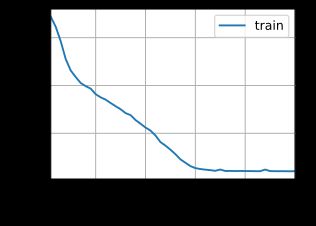
代码整合
# -*- coding: utf-8 -*-
# @Time : 2022/4/22 22:10
# @Author : tiancn
#传入time_machine数据集的下载地址以及哈希校验码
import collections
import re
import random
import numpy
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
#1. 数据处理部分
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
#将time_machine数据集加载到文本行的列表中
def read_time_machine():
#下载timemachine.txt文件,并打开文件按行读取内容
with open(d2l.download('time_machine'),'r') as f:
lines = f.readlines()
#re.sub('[^A-Za-z]+',' ',line):使用正则表达式匹配多个连续的非字母,将它们替换为空格
#strip(); 去除字符串两边的空格
#lower():转换字符串中所有大写字符为小写。
return [re.sub('[^A-Za-z]+',' ',line).strip().lower() for line in lines]
#将文本拆分为单词或者字符词元
def tokenize(lines, token = 'word'):
#拆分为单词
if token == 'word':
return [line.split() for line in lines]
#拆分为字符
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:'+token)
#统计词元的频率,返回每个词元及其出现的次数,以一个字典形式返回。
def count_corpus(tokens):
#这里的tokens是一个1D列表或者是2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
#将词元列表展平为一个列表
tokens = [token for line in tokens for token in line]
#该方法用于统计某序列中每个元素出现的次数,以键值对的方式存在字典中。
return collections.Counter(tokens)
#文本词表
class Vocab:
def __init__(self,tokens = None, min_freq = 0, reserved_tokens = None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
#按照单词出现频率排序
counter = count_corpus(tokens)
#counter.items():为一个字典
#lambda x:x[1]:对第二个字段进行排序
#reverse = True:降序
self._token_freqs = sorted(counter.items(),key = lambda x:x[1],reverse = True)
#未知单词的索引为0
#idx_to_token用于保存所有未重复的词元
self.idx_to_token = ['' ] + reserved_tokens
#token_to_idx:是一个字典,保存词元和其对应的索引
self.token_to_idx = {token:idx for idx,token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
#min_freq为最小出现的次数,如果小于这个数,这个单词被抛弃
if freq < min_freq:
break
#如果这个词元未出现在词表中,将其添加进词表
if token not in self.token_to_idx:
self.idx_to_token.append(token)
#因为第一个位置被位置单词占据
self.token_to_idx[token] = len(self.idx_to_token) - 1
#返回词表的长度
def __len__(self):
return len(self.idx_to_token)
#获取要查询词元的索引,支持list,tuple查询多个词元的索引
def __getitem__(self, tokens):
if not isinstance(tokens,(list,tuple)):
#self.unk:如果查询不到返回0
return self.token_to_idx.get(tokens,self.unk)
return [self.__getitem__(token) for token in tokens]
# 根据索引查询词元,支持list,tuple查询多个索引对应的词元
def to_tokens(self,indices):
if not isinstance(indices,(list,tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self):
return 0
@property
def token_freqs(self):
return self._token_freqs
#返回The Time Machine数据集的词元索引别表和词表
def load_corpus_time_machine(max_tokens = -1):
lines = read_time_machine()
tokens = tokenize(lines,'char')
vocab = Vocab(tokens)
#因为The Time Machine数据集中的每个文本行不一定是一个句子或者是一个段落
#所以将所有文本行展平到一个列表中
#保存数据集中每个字符的索引
corpus = [vocab[token] for line in tokens for token in line]
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus,vocab
#2.读取处理好的数据,以便于模型训练
def seq_data_iter_random(corpus, batch_size, num_steps):
# 随机偏移量开始对序列进行分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):]
# 减去1,是因为需要考虑标签
# num_subseqs:表示分割的序列的条数
num_subseqs = (len(corpus) - 1) // num_steps
# 长度为num_steps的子序列的起始索引编号
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 在随机抽样的迭代过程中,来自两个相邻的、随机的、小批量的子序列不一定在原始序列上相邻
# 因此将起始索引编号打乱
random.shuffle(initial_indices)
# 返回从pos位置开始的长度为num_steps的序列
def data(pos):
return corpus[pos: pos + num_steps]
# 表示一共有多少个批量
num_batches = num_subseqs // batch_size
# 从0到批量大小×批量的数量遍历,间隔为批量大小,即从循环次数为批量的数量
for i in range(0, batch_size * num_batches, batch_size):
# initial_indices包含子序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
# 按照起始索引获取每一个样本和标签序列。
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
# 返回一个可以用来迭代(for循环)的生成器,因为按照批量大小,返回的数据是多条的
yield torch.tensor(X), torch.tensor(Y)
# 使用相邻采样生成一个小批量子序列
def seq_data_iter_sequential(corpus, batch_size, num_steps):
# 从随机偏移量开始划分序列
offest = random.randint(0, num_steps)
# 获取用于最终训练的序列,因为有偏移量和不能整除,因此对输入的序列进行处理
num_tokens = ((len(corpus) - offest - 1) // batch_size) * batch_size
# 样本序列
Xs = torch.tensor(corpus[offest:offest + num_tokens])
# 标签序列
Ys = torch.tensor(corpus[offest + 1: offest + num_tokens + 1])
# 转为2维数据,行代表不同批次
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
# 为批次的数量
num_batchs = Xs.shape[1] // num_steps
# 循环输出
for i in range(0, num_steps * num_batchs, num_steps):
X = Xs[:, i:i + num_steps]
Y = Ys[:, i:i + num_steps]
yield X, Y
#加载序列数据的迭代器
class SeqDataLoader:
def __init__(self,batch_size,num_steps,use_random_iter,max_tokens):
if use_random_iter:
self.data_iter_fn = seq_data_iter_random
else:
self.data_iter_fn = seq_data_iter_sequential
self.corpus, self.vocab = load_corpus_time_machine(max_tokens)
self.batch_size,self.num_steps = batch_size,num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus,self.batch_size,self.num_steps)
#返回时光机器数据集的迭代器和词表
def load_data_time_machine(batch_size,num_steps,use_random_iter = False,max_tokens = 10000):
data_iter = SeqDataLoader(batch_size,num_steps,use_random_iter,max_tokens)
return data_iter,data_iter.vocab
#3.LSTM网络搭建部分
class LSTMModel(nn.Module):
def __init__(self,input_size,num_hiddens,**kwargs):
super(LSTMModel, self).__init__(**kwargs)
self.lstm = nn.LSTM(input_size,num_hiddens)
self.vocab_size = input_size
self.num_hiddens = num_hiddens
# 如果LSTM是双向的,num_directions应该是2,否则应该是1
if not self.lstm.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens,self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2,self.vocab_size)
def forward(self,inputs,state):
X = F.one_hot(inputs.T.long(),self.vocab_size)
X = X.to(torch.float32)
#staet为一个元组,包含了隐藏状态和记忆单元
Y,state = self.lstm(X,state)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# 它的输出形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output,state
def begin_state(self, device, batch_size=1):
# nn.LSTM以元组作为隐状态
return (torch.zeros((self.num_directions * self.lstm.num_layers,
batch_size,self.num_hiddens),device=device),
torch.zeros((self.num_directions * self.lstm.num_layers,
batch_size,self.num_hiddens),device=device))
#使用GPU
#如果存在,则返回gpu(i),否则返回cpu
def try_gpu(i=0):
if torch.cuda.device_count()>=i+1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
#4.预测部分
#在prefix后面生成新字符
def predict(prefix, num_preds, net, vocab, device):
# 获取初始状态
state = net.begin_state(batch_size=1, device=device)
# 保存输出的字符
outputs = [vocab[prefix[0]]]
# 获得当前时间步的输入,为输出列表的最后一个字符
get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))
# 预热期
for y in prefix[1:]:
_, state = net(get_input(), state)
outputs.append(vocab[y])
# 预测num_pred步
for _ in range(num_preds):
y, state = net(get_input(), state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
return ''.join([vocab.idx_to_token[i] for i in outputs])
#5.模型训练部分
#裁剪梯度
def grad_clipping(net,theta):
if isinstance(net,nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
def train(net, train_iter, vocab, lr, num_epochs, device, use_random_iter=False):
# 交叉熵损失函数
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',
legend=['train'], xlim=[10, num_epochs])
updater = torch.optim.SGD(net.parameters(), lr)
predict_ = lambda prefix: predict(prefix, 50, net, vocab, device)
for epoch in range(num_epochs):
state, timer = None, d2l.Timer()
# 记录损失之和,词元数量
metric = d2l.Accumulator(2)
for X, Y in train_iter:
# 第一次迭代或者使用随机抽样是初始化state
if state is None or use_random_iter:
state = net.begin_state(batch_size=X.shape[0], device=device)
else:
if isinstance(net, nn.Module) and not isinstance(state, tuple):
state.detach_()
else:
for s in state:
s.detach_()
# 更改标签形状,与输出一样,便于计算损失
y = Y.T.reshape(-1)
X, y = X.to(device), y.to(device)
# 返回输出和状态
y_hat, state = net(X, state)
# 计算损失
l = loss(y_hat, y.long()).mean()
# 针对优化器是pytotch还是自定义有不同的优化方法
updater.zero_grad()
l.backward()
grad_clipping(net, 1)
updater.step()
metric.add(l * y.numel(), y.numel())
# 返回困惑度和平均用时
ppl, speed = math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
if (epoch + 1) % 10 == 0:
print(predict_('time traveller'))
animator.add(epoch + 1, [ppl])
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
#print(predict_('time traveller'))
#print(predict_('traveller'))
下面训练模型
batch_size, num_steps = 32, 35
# 训练轮次,学习率
num_epochs, lr = 500, 1
# 隐藏层特征数量
num_hiddens = 512
# 返回时光机器数据集的迭代器和词表
# train_iter中已经将样本和标签处理好,并且将数据以索引的形式保存
# vocab为词表,用于将相应的索引转为文本
train_iter, vocab = load_data_time_machine(batch_size, num_steps)
# 定义模型
net = LSTMModel(input_size=len(vocab),num_hiddens=num_hiddens)
net.to(try_gpu())
# 训练模型
train(net,train_iter,vocab,lr,num_epochs,try_gpu())
困惑度 1.1, 38936.0 词元/秒 cuda:0
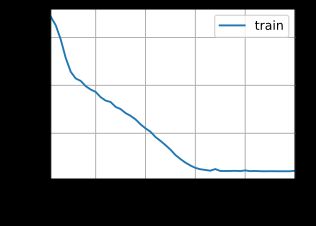
使用训练的模型进行预测
predict('time traveller', 50, net, vocab, try_gpu())
'time traveller for so it will be convenient to speak of himwas e'
5.2、门控循环单元(Gated Recurrent Unit, GRU)
5.2.1、相关概念
上面介绍了LSTM,它有效的克服了传统RNN的一些不足,比较好的解决了梯度消失、长期依赖等问题。但是LSTM也存在一些不足,比如结构比较复杂、计算复杂度比较高等问题。因此后人在LSTM的基础上,有推出其他变种,如GRU。GRU对LSTM做了很多简化,比LSTM少了一个门,因此计算效率更高,占用内存也相对较少。
GRU对LSTM做了两大改动:
- 将输入门、遗忘门、输出门变为两个门:更新门(Update Gate) Z t Z_t Zt和重置门(Reset Gate) R t R_t Rt。
- 将记忆单元和隐藏状态合并为一个隐藏状态: H t H_t Ht
GRU的结构图如下所示:
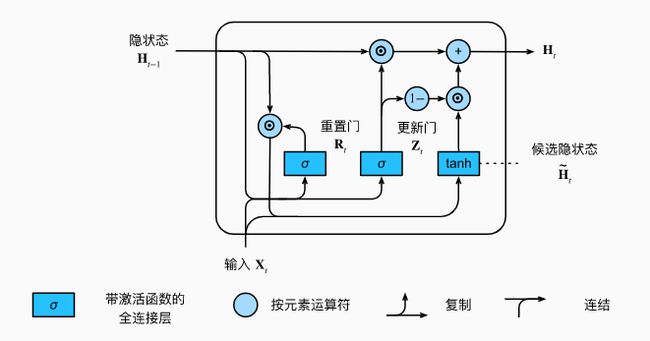
给定时间步t的小批量输入 X t ∈ R n × d X_t\in R^{n \times d} Xt∈Rn×d和上一个时间步的隐藏状态 H t − 1 ∈ R n × h H_{t-1} \in R^{n \times h} Ht−1∈Rn×h。重置门 R t ∈ R n × h R_t \in R^{n \times h} Rt∈Rn×h和更新门 Z t ∈ R n × h Z_t \in R^{n \times h} Zt∈Rn×h的计算为:
R t = σ ( X t W x r + H t − 1 W h r + b r ) Z t = σ ( X t W x z + H t − 1 W h z + b z ) R_t = \sigma(X_tW_{xr}+H_{t-1}W_{hr}+b_r)\\ Z_t = \sigma(X_tW_{xz}+H_{t-1}W_{hz}+b_z) Rt=σ(XtWxr+Ht−1Whr+br)Zt=σ(XtWxz+Ht−1Whz+bz)
其中 W x r , W x z ∈ R d t i m e s h W_{xr},W_{xz} \in R^{d \ times h} Wxr,Wxz∈Rd timesh和 W h r , W h z ∈ R h t i m e s h W_{hr},W_{hz} \in R^{h \ times h} Whr,Whz∈Rh timesh为权重参数, b r , b z ∈ R x t i m e s h b_r,b_z \in R^{x \ times h} br,bz∈Rx timesh是偏差参数。
时间步t的候选隐藏状态的计算为:
H ~ t = t a n h ( X t W x h + ( R t ⨀ H t − 1 ) W h h + b h ) \tilde{H}_t = tanh(X_tW_{xh}+(R_t \bigodot H_{t-1})W_{hh}+b_h) H~t=tanh(XtWxh+(Rt⨀Ht−1)Whh+bh)
其中 W x h ∈ R d × h W_{xh} \in R^{d \times h} Wxh∈Rd×h和 W h h ∈ R h × h W_{hh} \in R^{h \times h} Whh∈Rh×h是权重参数, b n ∈ R 1 × h b_n \in R^{1 \times h} bn∈R1×h是偏差参数。从公式可以看出,重置门控制上一时间步的隐藏状态如何流入当前时间步的候选隐藏状态。重置门可以用来丢弃无关的历史信息。
时间步t的隐藏状态 H t ∈ R n × h H_t \in R^{n\times h} Ht∈Rn×h的计算是使用当前时间步的更新门 Z t Z_t Zt来对上一时间步的隐藏状态 H t − 1 H_{t-1} Ht−1和当前时间步的候选隐藏状态 H ~ t \tilde{H}_t H~t做组合:
H t = Z t ⨀ H t − 1 + ( 1 − Z t ) ⨀ H ~ t H_t = Z_t\bigodot H_{t-1}+(1-Z_t)\bigodot \tilde{H}_t Ht=Zt⨀Ht−1+(1−Zt)⨀H~t
这个设计可以应对循环神经网络中的梯度衰减问题,并更好的捕捉时间序列中时间步距离较大的依赖关系。
在这里的的更新门代替了LSTM的是输入门和遗忘门,这样就可以使输入门和遗忘门进行一个联动。当输入门被打开的时候,遗忘门就会被关闭。这样就可以使用一个门完成了LSTM两个门的功能。
5.2.2、模型实现
在这里只对如何使用上述公式对GRU的计算进行代码实现,详细的代码与上面介绍的LSTM类似。例如数据加载,模型预测,模型训练等部分都与LSTM中从零开始实现一样。这里只介绍不一样的,如初始化模型参数,和模型中GRU计算部分。
import torch
from torch import nn
from d2l import torch as d2l
from torch.nn import functional as F
batch_size, num_steps = 32,35
train_iter, vocab = load_data_time_machine(batch_size,num_steps)
初始化模型参数
从标准差为的高斯分布中提取权重, 并将偏置项设为,超参数num_hiddens定义隐藏单元特征数量,实例化与更新门、重置门、候选隐状态和输出层相关的所有权重和偏置。
def get_gru_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
定义初始化的隐状态
函数返回一个形状为(批量大小,隐藏单元个数)的张量,张量的值全部为零。
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
模型计算过程
为使用上述公式对输入进行处理的过程。
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
对模型的各部分进行整个,得到完整的GRU
下面将模型参数初始化,初始状态,以及gru计算过程进行整合,得到一个完整的可以用于模型训练的网络。
#将上述操作进行整合,得到一个完整的LSTM
class GRUModelScratch:
def __init__(self,vocab_size,num_hiddens,device,get_params,init_state,forward_fn):
self.vocab_size,self.num_hiddens = vocab_size,num_hiddens
self.params = get_params(vocab_size,num_hiddens,device)
self.init_state,self.forward_fn = init_state,forward_fn
def __call__(self,X,state):
X = F.one_hot(X.T,self.vocab_size).type(torch.float32)
return self.forward_fn(X,state,self.params)
def begin_state(self,batch_size,device):
return self.init_state(batch_size,self.num_hiddens,device)
实例化模型
vocab_size,num_hiddens,device = len(vocab),256,try_gpu()
num_epochs,lr = 500,1
model =GRUModelScratch(len(vocab),num_hiddens,device,get_gru_params,
init_gru_state,gru)
train(model,train_iter,vocab,lr,num_epochs,device)
困惑度 1.1, 26344.5 词元/秒 cuda:0
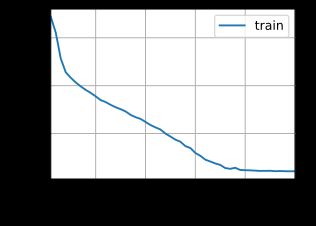
Pytorch中GRU的实现是使用torch.nn.GRU和torch.nn.GRUCell函数,与LSTM使用方法类似,其简介实现与LSTM类似,只需要将函数进行替换。
6、深度循环神经网络
前面介绍的RNN、LSTM、GRU都只有一个单向的隐藏层,而在深度学习中通常会使用含有多个隐藏层的循环神经网络,也称作深度循环神经网络。下图为有L个隐藏层的深度循环神经网络,每个隐藏状态不断传递至当前层的下一时间步和当前时间步的下一层。
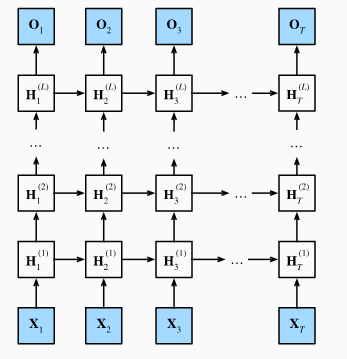
具体来说,在时间步t里,设小批量输入 X t ∈ R n × d X_t \in R^{n \times d} Xt∈Rn×d,第 l l l隐藏层( l = 1 , ⋯ , L l = 1,\cdots ,L l=1,⋯,L)的隐藏状态 H t ( l ) H_t^{(l)} Ht(l),输出层变量为 O t ∈ R n × q O_t \in R^{n \times q} Ot∈Rn×q,且隐藏层的激活函数为 σ \sigma σ,第一层隐藏层的隐藏状态和之前计算一样:
H t ( 1 ) = σ ( X t W x h ( 1 ) + H t − 1 ( 1 ) W h h ( 1 ) + b h ( 1 ) ) H_t^{(1)}=\sigma(X_tW_{xh}^{(1)}+H_{t-1}^{(1)}W_{hh}^{(1)}+b_h^{(1)}) Ht(1)=σ(XtWxh(1)+Ht−1(1)Whh(1)+bh(1))
其中权重 W x h ( 1 ) ∈ R d × h 、 W h h ( 1 ) ∈ R h × h W_{xh}^{(1)}\in R^{d \times h}、W_{hh}^{(1)}\in R^{h \times h} Wxh(1)∈Rd×h、Whh(1)∈Rh×h和偏差 b h ( 1 ) ∈ R 1 × h b_h^{(1)} \in R^{1\times h} bh(1)∈R1×h为第一隐藏层的模型参数。
当 1 < l ≤ L 1 \lt l \le L 1<l≤L时,第 l l l隐藏层的隐藏状态的表达式为:
H t ( l ) = σ ( H t ( l − 1 ) W x h ( l ) + H t − 1 ( l ) W h h ( l ) + b h ( l ) ) H_t^{(l)}=\sigma(H_t^{(l-1)}W_{xh}^{(l)}+H_{t-1}^{(l)}W_{hh}^{(l)}+b_h^{(l)}) Ht(l)=σ(Ht(l−1)Wxh(l)+Ht−1(l)Whh(l)+bh(l))
其中权重 W x h ( l ) ∈ R d × h 、 W h h ( l ) ∈ R h × h W_{xh}^{(l)}\in R^{d \times h}、W_{hh}^{(l)}\in R^{h \times h} Wxh(l)∈Rd×h、Whh(l)∈Rh×h和偏差 b h ( l ) ∈ R 1 × h b_h^{(l)} \in R^{1\times h} bh(l)∈R1×h为第 l l l隐藏层的模型参数。
最终,输出层的输出只需要基于第 L L L隐藏层的隐藏状态:
O t = H t ( L ) W h q + b q O_t = H_t^{(L)}W_{hq}+b_q Ot=Ht(L)Whq+bq
其中权重 W h 1 ∈ R h × q W_{h1} \in R^{h\times q} Wh1∈Rh×q和偏差 b q ∈ R 1 × q b_q\in R^{1 \times q} bq∈R1×q为输出层的模型参数。
同多层感知机一样,隐藏层的层数和隐藏单元的特征向量长度都为超参数。也可以将其应用到LSTM个GRU中,就可以得到深度LSTM和深度GRU。
在Pytorch中,实现也十分简单。在前面介绍的RNN,LSTM,GRU中,在pytorch中都有对应的函数,该函数中都有一个num_layers,我们只需要指定该参数为 L L L,就可以得到一个 L L L层深层循环神经网络。
7、双向循环神经网络(Bi-RNN)
之前介绍的循环神经网络的模型都是当前时间步是由前面的较早时间步的序列决定的,因此它们都将信息通过隐藏状态从前往后传递。但有时候掐面的信息也会由后面的信息决定,因此就需要双向循环神经网络(Bi-RNN)。Bi-RNN同时使用时序数据输入历史及未来数据,时序相反的两个神经网络连接同一输出,输出层可以同时获取历史和未来的信息。下图为双向循环神经网络的结构图。
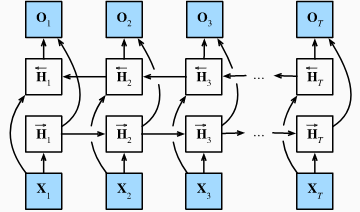
给定时间步 t t t的小批量输入 X t ∈ R n × d X_t \in R^{n \times d} Xt∈Rn×d和隐藏层激活函数为 σ \sigma σ。在双向循环神经网络架构中,设该时间步正向隐藏状态为 H → t ∈ R n × h \overrightarrow {H}_t \in R_{n \times h} Ht∈Rn×h,反向隐藏状态为 H ← t ∈ R n × h \overleftarrow {H}_t \in R_{n \times h} Ht∈Rn×h。正向隐藏状态和反向隐藏状态的计算为:
H → t = σ ( X t W x h ( f ) + H → t − 1 W h h ( f ) + b h ( f ) ) H ← t = σ ( X t W x h ( b ) + H → t − 1 W h h ( b ) + b h ( b ) ) \overrightarrow {H}_t=\sigma(X_tW_{xh}^{(f)}+\overrightarrow {H}_{t-1}W_{hh}^{(f)}+b_h^{(f)}) \\ \overleftarrow {H}_t=\sigma(X_tW_{xh}^{(b)}+\overrightarrow {H}_{t-1}W_{hh}^{(b)}+b_h^{(b)}) Ht=σ(XtWxh(f)+Ht−1Whh(f)+bh(f))Ht=σ(XtWxh(b)+Ht−1Whh(b)+bh(b))
其中权重 W x h ( f ) 、 W h h ( f ) 、 W x h ( b ) 、 W h h ( b ) W_{xh}^{(f)}、W_{hh}^{(f)}、W_{xh}^{(b)}、W_{hh}^{(b)} Wxh(f)、Whh(f)、Wxh(b)、Whh(b)和偏差 b h ( f ) 、 b h ( b ) b_h^{(f)}、b_h^{(b)} bh(f)、bh(b)均为模型参数。
然后连接两个方向的隐藏状态 H → t \overrightarrow {H}_t Ht和 H ← t \overleftarrow {H}_t Ht来得到隐藏状态 H t ∈ R n × 2 h H_t \in R^{n \times 2h} Ht∈Rn×2h,并将其输入到输出层,输出层计算为:
O t = H t W h q + b q O_t = H_tW_{hq}+b_q Ot=HtWhq+bq
其中 W h q W_{hq} Whq和 b q b_q bq为输出层模型参数。
Bi-RNN中的思想也可以用于LSTM和GRU。Bi-RNN的在pytorch中的实现也很简单,只需要修改torch.nn.RNN,torch.nn.LSTM或者torch.nn.GRU等函数中的bidirectional参数为True就好了,具体实现代码只需要将5.1.3节中或者4.5.2节中模型定义中将bidirectional参数为True就好了,其他搭建过程与之前介绍的是一样的。
8、RNN更多的应用
在上面的介绍中,我们所训练的RNN的模型处理的问题是使用当前的单词去预测下一个单词,在形式上来看为多个输入多个输出的问题(训练的时候输入的个数和输出的个数是相同的)。RNN不仅可以处理这种问题,还可以解决更多复杂的问题,RNN的输入和输出可以为多种形式,比如一对一,一对多,多对一,多对多等。下面是这些输入输出形式的结构图:

上图中红色代表输入,蓝色代表输出,有1对1,1对多,多对1,多对多等不同的形式,形式的不同可以完成不同的任务:
- 1->1:输入和输出都为1。没有用到RNN的模型,可以用于图像分类。
- 1->N:输入为1,输出为多个。可以用于输出一张图片,然后给出一段文字描述。
- N->1:输入为多个,输出为1。可以用于文本的情感分析,给定一段文字,判断文字是积极还是消极。
- N->M:输入为多个,输出也为多个,输入和输出个数可以不相等。可以用于机器翻译、语音识别等。
- N->N:输入为多个,输出也为多个,输入和输出个数相等。可以用于视频分类,对视频的每一帧打标签;或者是词性标注,判断文本中的每一个词属于什么词性。