可解释机器学习(Explainable/ Interpretable Machine Learning)的原理和应用(李宏毅视频课笔记)
文章目录
- 0 前言
- 1 Introduction of Explainable/ Interpretable ML
-
- 1.1 Why we need Explainable ML?
- 1.2 Interpretable v.s. Powerful
- 2 Local Explanation
-
- 2.1 Introduction of Local Explanation
-
- 2.1.1 Removing Way
- 2.1.2 Modifying Way
- 2.1.3 Limitation of Gradient based Approaches
- 2.2 Attack Interpretation
- 2.3 Help by Saliency Map
- 3 Global Explanation
-
- 3.1 Activation Minimization (review)
- 3.2 "Regularization" from Generator
- 4 Using a model to explain another
-
- 4.1 Using Linear Model
- 4.2 Local Interpretable Model-Agnostic Explanations (LIME)
-
- 4.2.1 Basic Idea of LIME
- 4.2.2 LIME-Image
- 4.3 Using Decision Tree
0 前言
机器学习模型,从简单的LR, Decision Tree到复杂的DNN、CNN、RNN、LSTM等, 整体的趋势是模型越来越复杂,模型的可解释性越来越差。 而我们要求模型不仅可以(分类),还要输出分类的理由是什么(局部),以及某一个分类的判断标准(全局)。本文由整理李宏毅老师视频课笔记和个人理解所得,详细讲述了Explainable/ Interpretable ML的原理及实现方法。有问题欢迎在评论区交流,我会及时回复。
1 Introduction of Explainable/ Interpretable ML
我们期望模型不仅告诉我们结果,还要告诉我们原因。举例来说:

这个原因分为两个层次:
- Local explanation:为什么觉得是一只猫?
- Global explanation:你觉得猫应该长什么样?
1.1 Why we need Explainable ML?
我们不仅需要机器结果的精确度,还需要进行模型诊断。比如有的任务正确率很高,但是实际上什么都没有学到。还比如有需要我们给出理由的应用场景:

一般如果识别结果很不好,我们第一反应就是调参,改模型,但是我们期待未来模型可以自己诊断:

李宏毅老师认为,可解释机器学习的目标并不是完全了解模型到底是怎么工作的,因为实际上即使是人脑现在也是一个黑匣子,但是模型要给出一个不同的人所需要的所关心的解释:

1.2 Interpretable v.s. Powerful
有些模型本来就很容易理解,比如线性模型,但是就没有神经网络那么强。对于深度学习来说虽然可解释性差,但是也要想办法解释:

也有可解释性也很强的模型,比如决策树和对应的随机森林:

决策树也可以变得很复杂,比如层数很高,而且当树很多时候,随机森林也很复杂,很难解释:

2 Local Explanation
2.1 Introduction of Local Explanation
Local explanation的基本精神是给出一个对象x,这个对象可以图片和文本:
Given Object x Components: { x 1 , ⋯ , x n , ⋯ , x N } \begin{aligned} &\text { Given Object } x\\ &\text { Components: }\left\{x_{1}, \cdots, x_{n}, \cdots, x_{N}\right\} \end{aligned} Given Object x Components: {x1,⋯,xn,⋯,xN}
其中的components可能是像素或者单词,这时模型需要给出这些components对于模型最终决策的重要性:

做法是移除或者修改component的值,观察对于决策的影响。对决策改变大的,那么就是重要的component。
2.1.1 Removing Way
将灰色方框在图片上移动,观察输出为正确的label的概率变化,蓝色代表概率低的位置,红色代表概率高的位置。可见对于结果来说,当灰色移动到了关键位置时,输出概率就会下降:
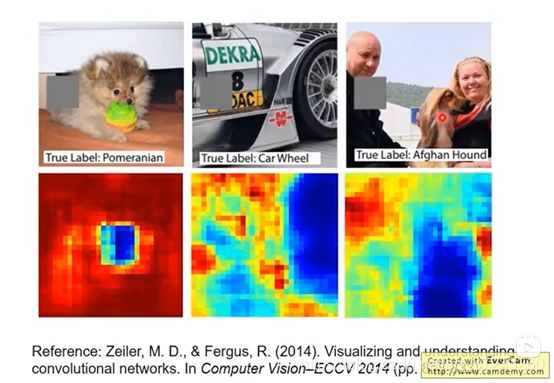 当然这个方框的颜色和大小也是需要调整的参数。
当然这个方框的颜色和大小也是需要调整的参数。
2.1.2 Modifying Way
对于输入的某一个维度的值 x n x_n xn加一个扰动 Δ x \Delta x Δx,然后观察 y k y_k yk输出变化是多少 Δ y \Delta y Δy,可以求 ∣ Δ y Δ x ∣ \left|\frac{\Delta y}{\Delta x}\right| ∣∣∣ΔxΔy∣∣∣,进一步求这个 ∣ ∂ y k ∂ x n ∣ \left|\frac{\partial y_{k}}{\partial x_{n}}\right| ∣∣∣∂xn∂yk∣∣∣偏微分的绝对值,也就是这个 x n x_n xn对 y k y_k yk而言是重要的还是不重要的。

Saliency Map(显著图):图中亮度越大,代表数值越大。也就是说表示了模型是真的获得了狗的信息才判断这是一条狗,而不是根据环境或者其他对象来判断的。
2.1.3 Limitation of Gradient based Approaches
到那时使用偏微分的方法有一定限制,会出现如下图的梯度饱和现象:

大象鼻子长到一定程度之后,那么对模型判断是大象的概率就不会增加了,此时算偏微分就接近0,那么根据上面的方法,会得出“大象鼻子不重要“的结论。
2.2 Attack Interpretation
但是实际上这种解释是可以被攻击的,例如下图的货车,在两种方法的saliency map里都识别出左边的区域重要,但是也可以通过一些几乎不可见的噪声,使得saliency map将云朵识别为重要的区域,但实际上模型的输出还是货车。 也就是输出和解释并不匹配。

2.3 Help by Saliency Map
举一个实际的例子展示saliency map有什么帮助,比如解释数码宝贝和神奇宝贝的差别:

这是两群不同的生物,但普通人很难区别。下载了两种卡通的数据集:

人眼观察的话可能很难分辨出其中的区别,然后李弘毅老师写了一个CNN测试了一下,识别的结果却很好:

所以他想看看对于模型来说怎么识别的,画了两者的saliency map,觉得识别的重点并没有落在生物的本体而是落在生物的边缘上:


究其原因发现,因为Pokemon和Digimon数据集的图片格式是不一样的,机器只需要读背景颜色就能判别了,其实什么都没有学到:

所以这也显示了可解释性学习的必要性。
3 Global Explanation
假设机器看见了猫,那么机器到底认为猫长什么样呢?

3.1 Activation Minimization (review)

先回顾一下,让某一个神经网络的output可以最大化。假设有一个网络可以识别手写数字,那我们现在希望这个网络能输出它认为的典型数字。
怎么做?首先确定哪个一种数字是我们想看的,比如 y i y_i yi位置所对应的数字,现在找要一张图片 x x x,能够使得 y i y_i yi的值最大
但实际我们可能得到 x x x是左边雪花的结果,人眼很难辨识,所以为了好看,需要在后面加一个项 R ( x ) R(x) R(x):

R ( x ) R(x) R(x)可以有不同的定义,这里是用所有的强度加起来,因为实际上的手写图片的多数区域都没有数值,减去强度之后或许会有帮助。
以下这个结果算是很好的,但是已经用了很多调参的技术了:

3.2 “Regularization” from Generator
但是现在我们可以做的更好,现在有一些Generator(生成模型),事先给出一堆图片,就可以教机器产生图片。给机器看一个低维度的向量 z z z,然后经过生成模型,就可以得到图片。
原来的方法是找一张图片,通过使得输出 y y y最大,现在可以在输入图片环境用生成器的结果代替,那么现在变成了找一个 z z z使得 y y y最大了。训练的话也是梯度下降,只需要将这两个网络接起来就可以了。

这样通过在输入端加了一个图片生成器的限制,因为这个生成器总是能输出人类能看懂的图片,那么最终可以使得最好的结果是人类能辨别的。如下图:
 这两个模型实际上是固定的是训练好的,我们只是想看一下结果。因为今天的目标不是训练生成器和分类器。
这两个模型实际上是固定的是训练好的,我们只是想看一下结果。因为今天的目标不是训练生成器和分类器。
4 Using a model to explain another
4.1 Using Linear Model
用一个可以被解释的模型解释另外一个不可以被解释的模型。做法是用一个可解释的模型模仿不可解释的模型,在训练的时候输入相同的样本,让模仿模型的输出接近黑色模型的输出:

4.2 Local Interpretable Model-Agnostic Explanations (LIME)
4.2.1 Basic Idea of LIME
虽然线性模型可解释强,但是性能太差了,很难模仿。但是如果只专注于一部分表现,那还是可以模仿的。比如只模仿一部分区域的行为:

- 假设想要解释黑盒子的输出的某个点。
- 在该点附近采样。
- 用线性的模型拟合neural network在这个区域的行为。
- 最终可以用这个线性模型解释这个区域了。
对于采样区域范围的选择不同,那么最后的结果也会不一样。比如下图如果采样很稀疏的情况:

这个方法只能用在local的explanation上,因为用的线性模型,没办法fit整个模型。
4.2.2 LIME-Image
第一步,给出你想解释的数据
第二步,在附件进行采样,但是这里的采样需要是按照图片分割进行的,将图片分成若干区域,每次随机选取一些区域使用,其他区域则为单色。然后输入到模型中,模型输出一个识别为正确标签“frog”的概率:

第三步,找一个可解释的模型,使得输入图片之后,也能输出同样的结果。
但是实际上如果按每一个像素来输入的话,对于线性模型来说还是需要太多的参数了,所以提出在输入前,将特征进行一些提取:

构造一个M维的向量,M是分割段的个数。以分割的整段为单位来记录,这个段使用了则该维度为1,否则为0。

最终对于线性模型来说就是以下这个式子:
y = w 1 x 1 + ⋯ + w m x m + ⋯ + w M x M x m = { 0 Segment m is deleted & 1 Segment m exists. \begin{aligned} &y=w_{1} x_{1}+\cdots+w_{m} x_{m}+\cdots+w_{M} x_{M} \\ &x_{m}= \begin{cases}0 & \text { Segment } \mathrm{m} \text { is deleted } \\ \& 1 & \text { Segment } \mathrm{m} \text { exists. }\end{cases} \end{aligned} y=w1x1+⋯+wmxm+⋯+wMxMxm={0&1 Segment m is deleted Segment m exists.
此时 w w w的值有三种结果,对应着三种情况:

李宏毅老师做了一个实验,然后将机器判断的依据的段拼接起来之后,有了以下的结果:

4.3 Using Decision Tree
刚才讲的用的线性模型,决策树解释性也很强,可以用决策树 T θ T_\theta Tθ来模拟黑盒子的参数 θ \theta θ:
 当然也不希望决策树过于深,不然也就失去了可解释性,所以定义了一个决策树的复杂度 O ( T θ ) O\left(T_{\theta}\right) O(Tθ),这里可以使用平均深度,目标是复杂度越低越好。
当然也不希望决策树过于深,不然也就失去了可解释性,所以定义了一个决策树的复杂度 O ( T θ ) O\left(T_{\theta}\right) O(Tθ),这里可以使用平均深度,目标是复杂度越低越好。
怎么做呢?假设训练一个特别的网络,这个网络在训练的时候就考虑之后会被决策树分析,训练的参数容易被决策树分析:
 一般的神经网络是就一个损失函数就行,但是我们同时加上一个决策树复杂度函数的正则项,也是越小越好。
一般的神经网络是就一个损失函数就行,但是我们同时加上一个决策树复杂度函数的正则项,也是越小越好。
右边那一项能够做微分吗?实际上不能解。但是有人提出了一个想法,就是又找一个网络,这个网络可以将输入的参数转换成决策树复杂度的值。这样就能解了。