用yolo3训练自己的数据集(包含数据搜集,图片标注,图片批量命名以及如何修改代码)——口罩佩戴以及规范佩戴口罩检验
用yolo3训练自己的数据集——口罩佩戴及规范性佩戴检验
- 前言
- 1. 数据集处理
-
- 1.1 数据搜集(多途径)
- 1.2 自己制作数据集
- 2.图片标注
-
- 2.1 图片批量命名
- 2.2 使用labelimg进行图片标注
-
- 2.2.1 labelimg的安装
- 2.2.2 labelimg的使用
- 3. 训练自己的数据
-
- 3.1 修改代码:
- 3.2 训练
- 3.3 预测
很多小伙伴想要数据集,补上链接,包含佩戴口罩,未佩戴口罩以及不规范佩戴口罩的图片数据及其标签,大约3000张,标签分别为:have_mask,no_mask,incorrect_mask : 口罩数据集
训练权重数据:型训练权重
前言
本文主要阐述如何用yolo3来训练自己的模型,包含数据收集,图片标注,图片批量命名,修改代码等方面,具体yolo3环境配置和代码请参考我的上一篇博文:
本文主要以口罩佩戴和口罩佩戴规范性检测为例来阐述整个过程,下面是效果展示:
话不多说,咱这就进入正题……
1. 数据集处理
1.1 数据搜集(多途径)
其实做深度学习的项目难点在于数据的收集,在这个数据流推动的时代,光有代码没有数据是万万不行的,下面为大家提供几种数据收集的方法:
-
谷歌搜kaggle,这是我目前见过的最全最好用的数据库之一,里面包含各种数据,甚至有很多适合yolo训练(标记过的)数据,但前提是你能科学上网。

-
百度搜 百度ai studio,最近百度也是奋起直追,不论是在数据库,还是类似谷歌colab的飞桨,都逐渐好用起来。其中同样也包含了很多的数据库,大家可以自行查阅。
-
谷歌搜Open Images Dataset V6,里面包含很多图片数据,包含图片标注,图像分割等等,但是要将这里面的数据转化成自己想要的标注形式,需要查阅一定资料,在这里不再赘述。哦对了,科学上网。
-
github,csdn等地球人都知道的搜索路径我就不多说了……
1.2 自己制作数据集
在尝试上面各种方法还没有找到数据集,或者数据集不够完备的情况下,你可以尝试自己制作数据集。说的直观点,就是拍照。还真别笑,只要数据处理做的好,这是一条非常可行的路径。但是拍照也是要讲究技巧的,你得注意以下几点:
- 多类型,多方位,多角度。反正不论是正的,歪的,斜的,反的,远的,近的,高清的,模糊的,有遮挡,无遮挡的,都多来几张。脑洞够大,数据集的训练就会越好。
- 说的专业点,这就是数据增强的一部分。具体数据增强处理csdn上有很多介绍了,不想用代码进行数据增强的小伙伴们,ps也是可以的喔,本人亲测。
2.图片标注
对于图片标注嘛,操作很简单,但也许做项目这部分是最花时间最无脑的浩大工程,还有一个办法(外包),开个玩笑,其实最好的情况就是能直接找到带标注的数据集啦。
在图片标注之前,你最好做一个工作,能节省一些不必要的麻烦,以后修改数据也比较方便,那就是图片批量命名:
2.1 图片批量命名
首先注意一个非常重要的问题就是,yolo训练的数据集图片名字中是不能有空格或者括号这样的,别标注完所有数据之后发现不能用来训练,那可就得改完名字重新标注了,几千张图片这可不是一个小工作。那么请了解以下几点:
- 图片名字可以包含英文字母,下划线,数字。
- 图片所有的格式都必须相同,一般来说为jpg格式。
- 图片批量命名不能使用windows自带的批量命名,因为那样会包含空格等……
所以现在给大家介绍一个软件,用于按照自己的意愿批量命名图片。
Adobel Bridge2020,
Bridge2020
提取码:c653
Adobel Bridge的使用方法请参考我的另一篇博文:
如何使用Adobel Brideg按序批量命名图片
优势会遇见批量修改文件后缀名的情况,可以参考博文批量修改文件名和后缀名
2.2 使用labelimg进行图片标注
2.2.1 labelimg的安装
假如你已经看过了前言里的博文链接,想必已经安装上了pytorch或者tensorflow的环境,那么现在就打开cmder或者cmd,输入activate pytorch或者activate tensorflow,并pip install labelimg,由于我之前装过了,所以显示已完成:
2.2.2 labelimg的使用
1.labelimg的使用:
在使用labelimg之前,大家先创建一个文件夹,用来存放照片以及要标签位置:

其中JPEGImages用来存放你要用于训练的照片,照片最好按序命名,Annotations用于存放标注完的标签。现在,打开cmd,激活环境——activate pytorch,然后输入lambelimg,顺利的话回车就可以打开labelimg了。
- 点击open dir,选择你存放照片的那个文件夹,也是就JPEGImages。

- 点击change save dir,打开你要存放标签的文件夹,也就是Annotations。
- 左手三个手指放在A,W,D上,就像打游戏那样。A,D是用来切换照片的,W是用来显示标注框的,按下W之后,你就可以用鼠标选择要标注的区域。
- 在弹出的小框中输入该区域的标记即可,也就是你想要分类的名字。举个例子,比如这张图片绿色框中是不规范佩戴口罩的照片,那么输入incorrect_mask,然后点击ok,再点击D键切换到下一张图片即可,那么这张图片就标注完成啦,你可以再到你的Annotations文件夹中查看,会发现多出一个标签文件,当然图中这是很多标签了,你只有一个:
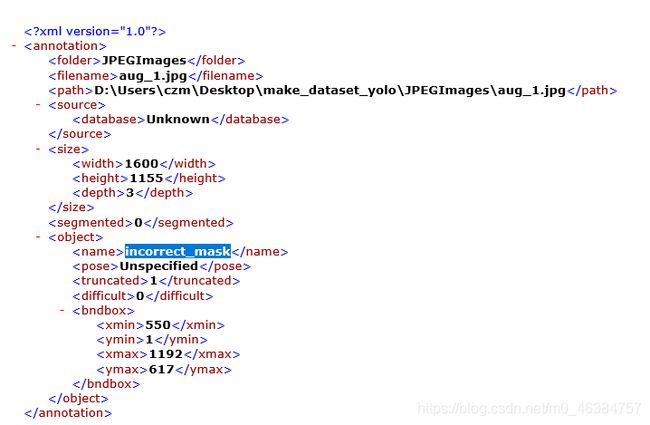
- 点击打开标签文件,其他的你不用看,就看图中标注的的这几个蓝色字母就好,这个就是这张图片的标签,当你把像素点和RGB值传入yolo模型中去,代码会自动匹配这个标签和你框出来的图片,这样代码就知道如何将类似像素点对应标签了。
- labelimg个人总结小技巧:
其实也谈不上什么技巧,就是在大量标注数据后总结出的一点经验。那就是标注图片的时候,如果要标注区域触及图片的最低端,一定要从下往上去框出标记的区域。因为如果从上向下标的话,到最底下的时候那个框框总会发生一些意外,使得你不知道标记的是哪个区域,难以描述,反正等你自己动手就知道了。
3. 训练自己的数据
要训练自己的数据,首先你得有代码,yolo3的环境配置以及代码在我前言中放的那篇博文中可以找到,假设大家已经配置好了环境并下载下来了代码的话,那咱们就开始吧:

3.1 修改代码:
这里给出yolo3的代码主目录,现在介绍几个主要要使用的文件夹以及如何修改代码:
-
img文件夹:用于存放模型训练完成后用于测试的图片。
-
logs文件夹:初始为空,用于存放训练过程中生成的权值文件。
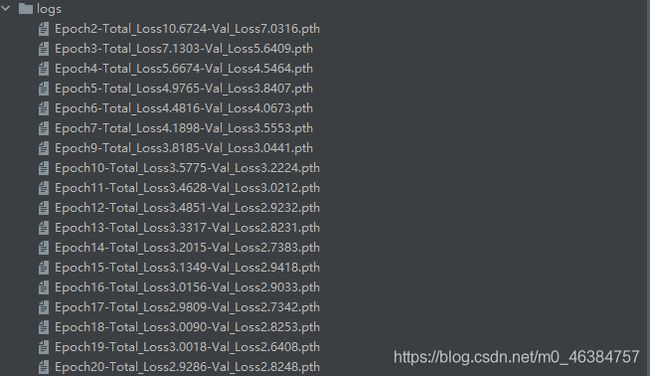
-
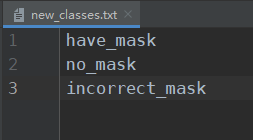
model data文件夹:用于存放这个模型要测试的几个类,比如说要测试口罩的佩戴,未佩戴和不规范佩戴,则在model_data/new_classes.txt中写入:
-
VOCdevkit文件夹:用于存放训练要用的照片数据,标记数据以及将它们相匹配的文件:
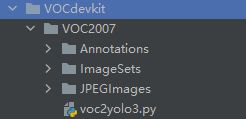
在你标记完数据后,可直接将Annotations和JPEGIamges复制到VOCdevikt文件夹中,之后运行vocyolo3.py文件,修改代码块中的路径,如下图所示:
 运行成功之后你会发现ImageSets/Main中出现几个.txt文件,大家可分别打开看看里面有什么,这样就将标签文件和图片文件对应起来,转换到yolo3可以识别的格式。
运行成功之后你会发现ImageSets/Main中出现几个.txt文件,大家可分别打开看看里面有什么,这样就将标签文件和图片文件对应起来,转换到yolo3可以识别的格式。 -
完成这一步之后,修改主目录中utils/config.py文件的classes参数,你要训练的图片分几类classes就修改为多少;再修改主目录中voc_annotation.py文件的classes参数,将其改为自己要分类的几个选项:

-
现在,运行
voc_annotation.py文件,运行成功后,会发现主目录中多出几个.txt的文件,大家点击打开看看就知道是用来做什么的了。 -
报错提示:报错大家可以看看提示是什么错误,并检查是否每一个地方都按照要求修改了,若报某某图片not found这样的错误,查看你的图片是否和你的标签有对应上,并检查图片格式是否相同,是否都为.jpg格式。
-
predict.py文件:训练完成后用于预测图片测试模型。
-
test.py文件:测试模型。
-
train.py文件:训练yolo3模型。
-
video.py文件:训练模型完成后用于打开摄像头测试。
-
yolo.py文件:yolo3主函数。
3.2 训练
写的有点多,不过大家看完肯定会有帮助的!!!
当之前所有的准备工作都完成之后,就可以开始训练模型了,即运行train.py文件,这里有几个注意事项:
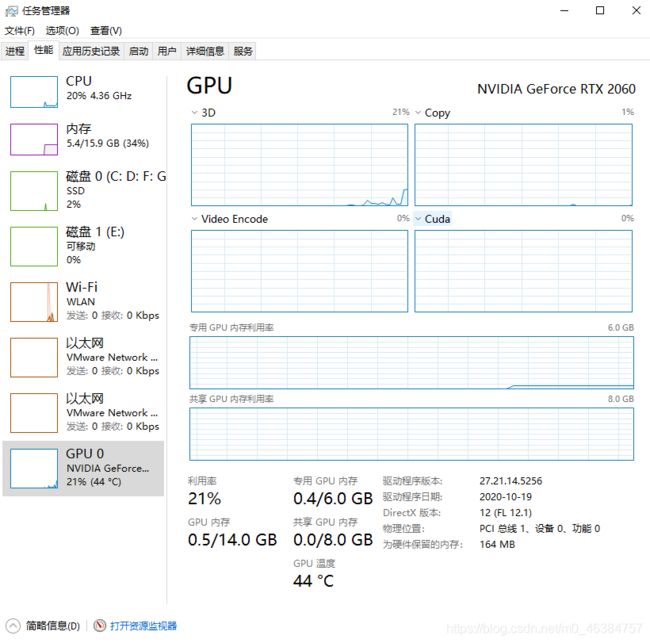
- 如果你的电脑带有gpu的话,因为我推荐下载的cuda是gpu版本,所以直接运行train.py文件即可。你可以同时按下
Ctrl+Alt+Delete键查看电脑运行情况 。假如你的cpu占用率瞬间达到了百分之百利用率,不要慌,这很正常,机子出场时还要烤机呢,说明你的cpu工作的很好,能调用全部功率来训练。只需查看GPU选项的cuda参数或者查看显存即可,我训练时cuda利用率达到了80%左右。
-
假如你的电脑没有GPU的话,也不是不可以训练,将
train.py中的cuda=True设置为cuda=False即可。然后运行train.py文件。不过如果你要训练的数据集过大,并且对电脑风扇不太自信的话, 劝你还是不要用自己的电脑训练了,只要你不想用电脑煮熟一个鸡蛋后电脑自动关机的话……但别担心,cpu一般不会坏,cpu在达到110摄氏度后会自动关机的。那是不是这样就没办法训练了呢?当然不是!这不还能借电脑或者用万能的==colab==嘛,具体colab使用教程请看我写的另一篇博文: -
何时停止训练,每次训练完后都会有一个损失值。一般来说,这个值随着训练次数增加会逐渐减小,当然减小幅度也会随着训练逐渐较小,这很符合常理,我在这里就不用数理逻辑来解释了。当你看到减小的幅度比较小,甚至有增大的情况时,这时候就可以停止训练了,没有必要训练完所有的次数。
3.3 预测
1.假如一切顺利进行,那么相信你能在logs文件夹下面发现有很多权值文件存在了。现在进入到主目录中的model_data文件夹,创建一个文件new_classes.txt,里面写上你要预测的几个类型名字,如:
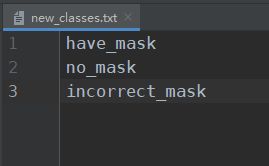
2.完成第一步后,打开主目录中yolo.py,修改model_path和classes_path这两个参数。model_path自然是logs文件夹下权值文件的路径,意思是你要用哪个权值文件进行训练。classes_path自然就是你在model_data中创建的new_classes路径。
3.权值的选择:
权值的选择是很重要的一步,因为它关系到你模型的准确率。最笨的方法当然是一个一个试啦,但其实也是很有效的。网上有很多人说选择最小的损失值的那个权值文件,但其实不然(亲测),因为训练到后面会有过拟合(转载)的现象,一般来说不同模型不同。我训练这个口罩规范性检测模型时在第3~8次的权值会比较好,太早的文件欠拟合,太后的文件过拟合。
4.摄像头的问题:如果你的电脑带有原装的摄像头,是没有任何问题的,直接运行video.py文件即可。如果没有那就买一个外置的吧,外置如果配置的好也是米有问题的,就怕外置的摄像头在电脑里的标号不为0,那么就要修改代码里调用摄像头的那个参数了。