机器学习中遇到的问题(北极海豹小课堂)
机器学习中遇到的问题
1. Class imbalance in classification problem
表现:一类class的数量远超过另外一种class的数量。正如您在下面的图表下,与90000左右的非欺诈交易相比,欺诈性交易约为400。

2. How to optimize gradient descent in your ML process?
- rescale or normalizae your data
- 以Loss function为y轴,迭代次数为x轴画出图像观察
- 减少learning rate
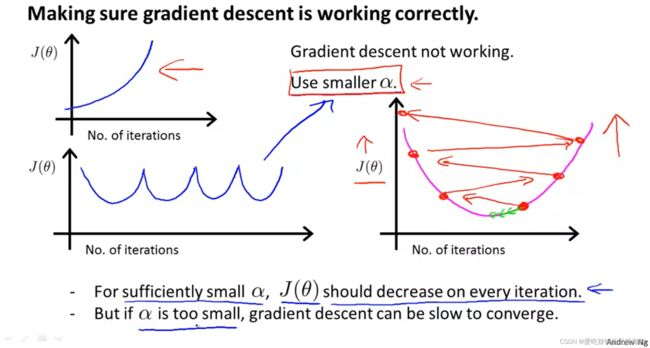
葵花妈妈小课堂:
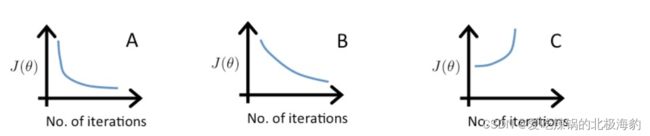
A的learning rate是0.1,B的learning rate是0.01,C的learning rate是1
C中曲线是上升的,说明learning rate过大
A,B都收敛,但是B中收敛的更慢,因此learning rate相较于A是更小的
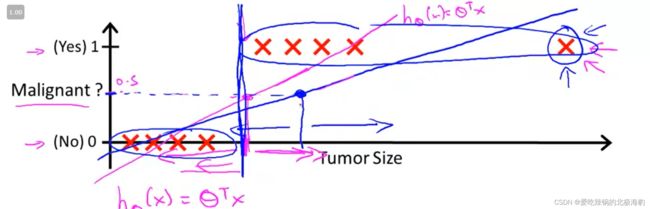
3. 为什么outlier会影响classfication problems
这个图本来使用来说明Linear algorithm并不适用于回归问题
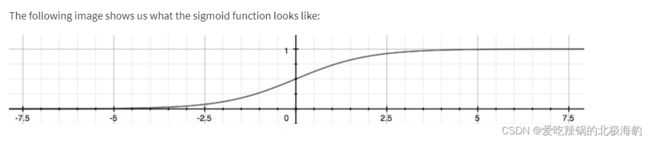
4. What is logistic function(属于sigmoid函数中的一种)
Logistic 函数可以看成是一个“挤压”函数,把一个实数域的输入“挤压”到(0, 1)
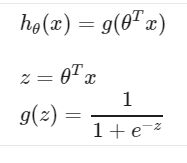

5. The structure of feature engineering.

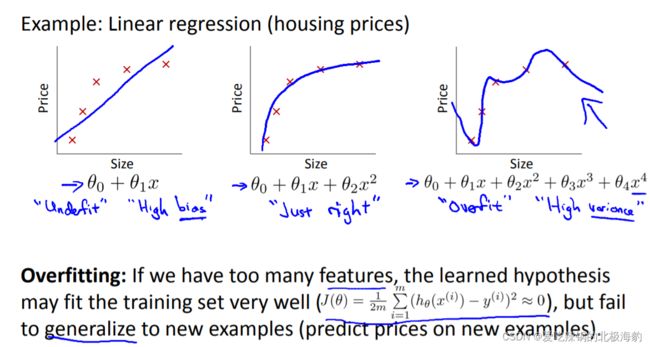
6. Solving the problem of overfitting.
过拟合:经验风险最小化原则很容易导致模型在训练集上错误率很低,但是在未知数据上错误率很高。
过拟合问题往往是由于训练数据少和噪声等原因造成的。


7. AI vs. Machine Learning vs. Deep Learning vs. Neural Networks: What’s the Difference?
最简单来说,可以用一个俄罗斯套娃的结构来描述。

就深度学习(DL)和神经网络之间(ANN)的关系来说
深度学习是有超过3-4个Layers的神经网络。深度学习中的“深度”是指神经网络中的层次。一个由三层组成的神经网络 - 这将包括输入和输出 - 可以被认为是一种深度学习算法。

就ML和DL的区别来说
它们的主要区别在于每种算法如何学习以及每种算法使用多少数据。
DL需要更大量的数据,DL将过程中的大部分特征提取部分自动化,消除了一些所需的人工干预。
AI的概念
人工智能(AI)是最广泛的术语,用于分类模仿人类智能的机器。它用于预测,自动化和优化人类在历史上完成的任务,例如言语和面部识别,决策和翻译。
有着三个主要类别
Artificial Narrow Intelligence (ANI),类似于Siri这样的语音机器人
Artificial General Intelligence (AGI)
Artificial Super Intelligence (ASI)
ANI属于weak人工智能,而AGI,ASI属于强人工智能,例如HBO电视剧《西部世界》里的德洛丽丝
8. What is the Difference Between Test and Validation Datasets?
用于fit model的training dataset 可以进一步分成 training set和validation set,这是training dataset的子集,可以用来获取早期估计的模型的能力。
– Training set: A set of examples used for learning, that is to fit the parameters of the classifier.
– Validation set: The sample of data used to provide an unbiased evaluation of a model fit on the training dataset while tuning model hyperparameters. The evaluation becomes more biased as skill on the validation dataset is incorporated into the model configuration.
– Test set: A set of examples used only to assess the performance of a fully-specified classifier.
Your nortion please:
That the notions of “validation dataset” and “test dataset” may disappear when adopting alternate resampling methods like k-fold cross validation, especially when the resampling methods are nested.
吴恩达的机器学习课程对于这三种dataset的表述:

一些伪代码:
# split data
data = ...
train, validation, test = split(data)
# tune model hyperparameters
parameters = ...
for params in parameters:
model = fit(train, params)
skill = evaluate(model, validation)
# evaluate final model for comparison with other models
model = fit(train)
skill = evaluate(model, test)
9. How to diagnose your model has a high bias or variance according to the learning curve?
Bias是用来衡量模型对于训练数据预测的准确率。
Variance是用来衡量已经被训练过的模型进行预测的准确率。
因此,根据over-fitting的定义,当模型出现low bias,high variance,则判断模型over-fitting.
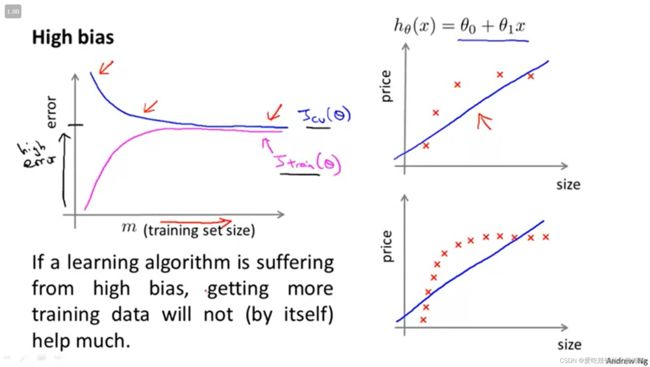
如果模型存在较高的bias,那么cross-validation得分曲线,将会随着数据量的增加,贴近training得分曲线。从下图右侧可以看出,模型存在高bias的情况下,增加数据量是没有用的。
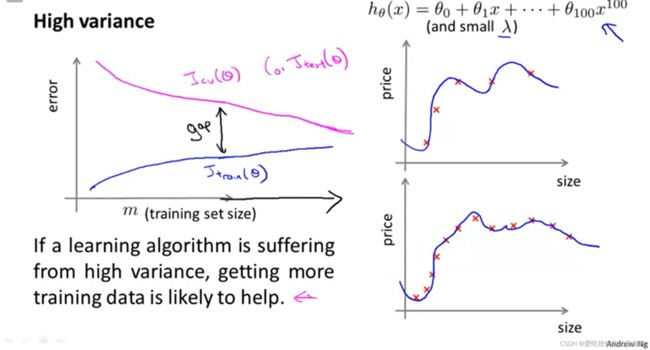
如果模型存在较高的variance,那么cross-validation曲线将会远高于training曲线,但如果增加数据量,那么这两条曲线最后就能贴合,variance也会降低。
10. How will the range of λ influence your model?

11. What can we do to fix high bias or high variance?
- 增加数据量: Fixes high variance
- 减少features,选择其中最主要的(feature selection): Fixes high variance
- 增加features: Fixes high bias
- 增加hypothesis fuction(是一个多项式函数)的degree: Fixes high bias(见下图)
- 减少 λ: Fixes high bias
- 增加 λ: Fixes high variance.
Your notion please:
- hypothesis fuction:hypothesis是监督学习中的一种能够完美的描述目标的function
- λ是Regularization的参数,可见于问题11
hypothesis fuction的度数对model的影响

12. How does the model.score work?
Reference
对于classifiers, accuracy_score 和model.score都是一样的作用,他们俩只是通过不同的方式计算了相同的东西。
对于regressors ,r2_score和model.score都是一样的作用,他们俩只是通过不同的方式计算了确定系数R2(coefficient of determination)。