【数据挖掘】使用支持向量机实现恶意url检测
数据挖掘-使用支持向量机实现恶意url检测
- 一、实验任务:
- 二、实验环境
- 三、项目目录
- 四、实验步骤
-
- 1.写训练脚本 svm.py
-
- 导入需要的包
- 数据清洗的函数
- 训练的函数train():
- 2.写预测脚本 urls_type.py
-
-
- 备注:
-
- 五、参考链接
项目代码见资源【数据挖掘】恶意url检测
一、实验任务:
选择恶意和正常URL链接数据进行研究(特征选择、算法选择),并编写代码构建模型,最终满足如下需求: - 打印出模型的准确率和召回率; - 代码可以根据输入的URL自动判定其安全性;
二、实验环境
AIstudio
(vscode也可以)
python 3.7.4
需要的包在代码中已经列出
三、项目目录
训练
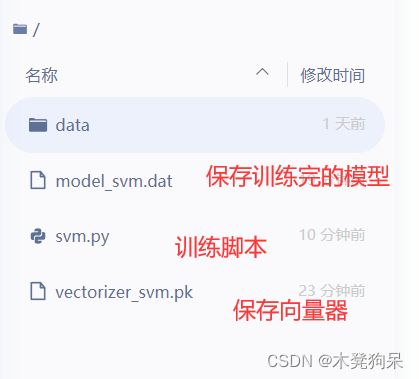
预测

logit是用逻辑回归实现的,经过对比,svm实现的准确率稍微高于logist,因此此处logit无用。

四、实验步骤
1.写训练脚本 svm.py
用支持向量机方法实现
导入需要的包
# coding: utf-8
#!/usr/bin/env python
import pickle
from sklearn import metrics
from sklearn.metrics import classification_report
import pandas as pd
import numpy as np
import random
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
数据清洗的函数
处理特殊符号和词, 通过/ - .分割文本,并且删除一些常见词如com https http
#dataset清洗
def makeTokens(f):
tkns_BySlash = str(f.encode('utf-8')).split('/') # make tokens after splitting by slash
total_Tokens = []
for i in tkns_BySlash:
tokens = str(i).split('-') # make tokens after splitting by dash
tkns_ByDot = []
for j in range(0,len(tokens)):
temp_Tokens = str(tokens[j]).split('.') # make tokens after splitting by dot
tkns_ByDot = tkns_ByDot + temp_Tokens
total_Tokens = total_Tokens + tokens + tkns_ByDot
total_Tokens = list(set(total_Tokens)) #remove redundant tokens
if 'com' in total_Tokens:
total_Tokens.remove('com') # removing .com since it occurs a lot of times and it should not be included in our features
if 'https' in total_Tokens:
total_Tokens.remove('https')
if 'http' in total_Tokens:
total_Tokens.remove('http')
return total_Tokens
训练的函数train():
实验作业中,所给数据集是2个分开的,一个正常的和一个恶意的url 数据集,要分别读取csv,得到2个返回的dataframe,然后合并起来用。

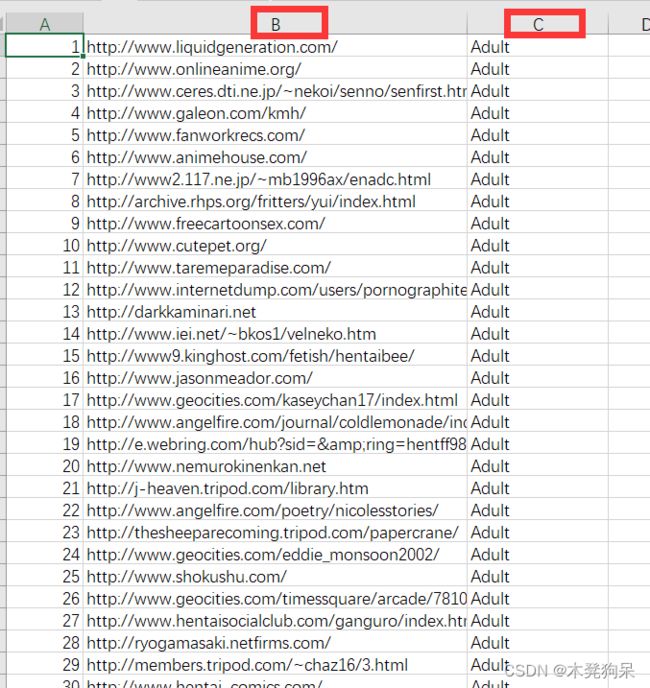
读取csv里的数据:
使用usecols参数,只读取有用的列;
标记dataframe的列名为url和label;
标签为good和bad。
def train():
data0=pd.read_csv("data/data170812/benign-URL-dmoz-datasets.zip",usecols=[1,2],header=None,nrows=650000)
# data0=pd.read_csv("data/data170812/benign-URL-dmoz-datasets.zip",usecols=[1,2],header=None)
data0.columns=["url","label"]
data0["label"]="good"
# print(data0.head())
# data0.head()
# Reading data from csv file
data = pd.read_csv("data/data54433/phishing_verified_online.csv",usecols=[1,6])
data.columns=["url","label"]
data["label"]="bad"
data = pd.concat([data, data0])
print(data.head())
# data.head()
分别取出url列和label列,用于数据处理
# Labels
y = data["label"]
# Features
url_list = data["url"]
urls=[]
urls.append(url_list)
# print(type(urls))
# print(urls[0])
将文本数据转换为数字向量,并且将向量器保存到本地以能重用(必须保证预测脚本中用到的vectorizer和训练时的是同一个)
# Using Tokenizer
vectorizer = TfidfVectorizer(tokenizer=makeTokens,encoding='utf-8')
#不能在这里就保存vectorizer
# Store vectors into X variable as Our XFeatures
X = vectorizer.fit_transform(url_list.values.astype('U'))
with open('vectorizer_svm.pk', 'wb') as fin:
pickle.dump(vectorizer, fin)
#一定要在这里保存vectorizer 才可以
拆分数据集,得到训练集和测试集
# Split into training and testing dataset 80:20 ratio
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
建立逻辑回归模型,进行训练。
# Model Building using logistic regression
logit = LogisticRegression()
logit.fit(X_train, y_train)
保存训练得到的模型
# 保存模型,我们想要导入的是模型本身,所以用“wb”方式写入,即是二进制方式,DT是模型名字
pickle.dump(logit,open("model_svm.dat","wb")) # open("dtr.dat","wb")意思是打开叫"dtr.dat"的文件,操作方式是写入二进制数据
print("保存模型成功\n")
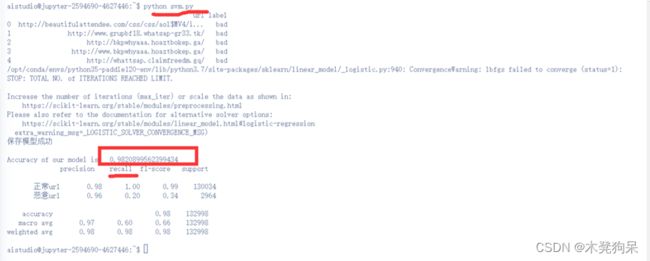
打印准确率及分类报告(包含召回率)
# Accuracy of Our Model
# print("Accuracy of our model is: ",logit.score(X_test, y_test))
print("Accuracy of our model is: ",logit.score(X_test, y_test))
y_predict = logit.predict(X_test)
# print("Recall of our model is: ",logit.recall_score(X_test, y_test))
# 计算准确率和召回率
res = classification_report(y_test,y_predict,labels=["good","bad"],target_names=['正常url','恶意url'])
# precision准确率;recall召回率;综合指标F1-score;support:预测的人数
print(res)
效果如图:
2.写预测脚本 urls_type.py
需要手动输入urls
import pickle
from svm import makeTokens
from sklearn.feature_extraction.text import TfidfVectorizer
if __name__=='__main__':
X_predict=[]
url=input("输入你想预测的url:输入q截止\n")
while url!='q':
X_predict.append(url)
url=input("输入你想预测的url:输入q截止\n")
加载模型和训练完保存的向量器
# 加载模型
# logit = pickle.load(open("model_logit.dat","rb"))
logit = pickle.load(open("model_svm.dat","rb"))
# vectorizer = pickle.load(open("vectorizer_logit.pk","rb"))
vectorizer = pickle.load(open("vectorizer_svm.pk","rb"))
预测并输出结果
X_predict =vectorizer.transform(X_predict)
New_predict = logit.predict(X_predict)
print(New_predict)
效果如图:

备注:
1.如果懒得输入urls,可以直接把urls写入预测脚本来查看效果,资源里有urls_in.py,此处不再赘述。
2.logit命名的文件是用逻辑回归实现的,但是最终没有使用,在调试过程中,存在少部分修改,运行可能有问题。
logit和svm代码大同小异,如果想测试,自己修改且补充完善,注意2个地方:
a.命名,导入包的名、代码中的路径、运行时的命令
b.
logit
# Split into training and testing dataset 80:20 ratio
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Model Building using logistic regression
logit = LogisticRegression()
logit.fit(X_train, y_train)
svm
# Split into training and testing dataset 80:20 ratio
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Model Building using logistic regressio
logit = svm.LinearSVC()
logit.fit(X_train, y_train)
五、参考链接
1.召回率及其他量的含义
2.逻辑回归检测恶意url参考博客
3.参考项目1
4.参考项目2
5.参考项目3
6.参考博客及项目
7.逻辑回归