[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第1张图片](http://img.e-com-net.com/image/info8/b7f73bd42a134990a7fae60ab90dd781.jpg)
code link: https://cassiepython.github.io/ clipnerf/
@inproceedings{DBLP:conf/cvpr/WangCH0022,
author = {Can Wang and
Menglei Chai and
Mingming He and
Dongdong Chen and
Jing Liao},
title = {CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields},
booktitle = {{CVPR}},
pages = {3825–3834},
publisher = {{IEEE}},
year = {2022}
}
文章目录
- Overview
-
- What problem is addressed in the paper?
- What is the key to the solution?
- What is the main contribution?
- What can we learn from ablation studies?
- Potential fundamental flaws; how this work can be improved?
- Introduction
- Related works
- Method
-
- 3.1. Conditional NeRF
- 3.2. Disentangled Conditional NeRF
-
- Conditional Shape Deformation.
- Deferred Appearance Conditioning.
- disentangled conditional NeRF
- 3.3. CLIP-Driven Manipulation
- 3.4. Training Strategy
- 3.5. Inverse Manipulation
- Experiments
-
- 4.1. Compared to EditNeRF
- 4.2. Ablation Study
- 4.3. CLIP-Driven Manipulation
- Conclusion
Overview
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第2张图片](http://img.e-com-net.com/image/info8/12b19028430043e18ef80b83c44fbb8e.jpg)
What problem is addressed in the paper?
We present CLIP-NeRF, a multi-modal 3D object manipulation method for neural radiance fields (NeRF). (多模态3D目标操控方法)
What is the key to the solution?
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第3张图片](http://img.e-com-net.com/image/info8/1cbb2a1bf50c45278e06953d33763037.jpg)
By leveraging the joint language-image embedding space of the recent Contrastive Language-Image Pre-Training (CLIP) model, we propose a unified framework that allows manipulating NeRF in a user-friendly way, using either a short text prompt or an exemplar image.
we introduce a disentangled conditional NeRF architecture that allows individual control over both shape and appearance to combine the novel view synthesis capability of NeRF and the controllable manipulation ability of latent representations from generative models
What is the main contribution?
- We present the first text-and-image-driven manipulation method for NeRF, using a unified framework to provide users with flexible control over 3D content using either a text prompt or an exemplar image.
- We design a disentangled conditional NeRF architecture by introducing a shape code to deform the volumetric field and an appearance code to control the emitted colors.
- Our feedforward code mappers enable the fast inference for editing different objects in the same category compared to the optimization-based editing method 。
- We propose an inversion method to infer the shape and appearance codes from a real image, allowing editing the shape and appearance of the existing data.
What can we learn from ablation studies?
- the disentangled design 有效地将shape和appearance的编辑分离开。 并且提升了图像了FID指数。
Potential fundamental flaws; how this work can be improved?
由于潜在空间和预先训练的CLIP的表达能力有限,我们的模型不能处理fine-grained edits 和 out-of-domain edits。这可以通过添加更多不同的训练数据来缓解。
Introduction
Editing NeRF的挑战:
- 由于NERF是针对每个场景优化的隐式函数,因此我们不能使用用于显式表示的直观工具直接编辑形状
- 与单视点信息足以指导编辑[20、44、45]的图像操纵不同,NERF的多视点依赖性使得在没有多视点信息的情况下操纵方式更难控制。
方法概述
利用预训练的CLIP 模型来学习两个code mappers, 用于将CLIP 特征映射到 用于修改形状和外观的code.
具体地,给定一个文本提示或者一个样本图像 作为我们的condition,我们用预训练的CLIP模型提取特征,并将特征提供给 code mappers,由此在潜在空间中产生局部位移以编辑形状和外观code.
我们设计了基于CLIP的损失来加强输入约束和输出渲染之间的CLIP空间一致性,从而支持高分辨率的NERF操作。此外,我们还提出了一种基于优化的方法,通过对真实图像的形状和外观代码进行反向优化来编辑真实图像。
Related works
和普通的NERF相比,普通NERF不能编辑3D模型的内容。
和Editing NeRF相比,我们的方法提供了更大的自由度,并支持全局变形。我们的方法允许交互编辑的快速推理. 我们引入的是直观的方法来编辑NeRF(text prompt or examplar image)
和由CLIP驱动的图像生成和操控方法相比,此前的方法只探索了CLIP的引导能力,我们的方法,将文本和图像的操作统一在了一个模型当中个。
此前方法 仅限于图像处理,因为缺乏3D信息而不能鼓励多视点一致性, 我们的方法将CLIP 和NERF结合起来,允许以试图一致的方式编辑3D模型。
Method
3.1. Conditional NeRF
conditional NeRF servers as a generative model for a particular object category, conditioned on the latent vectors that dedicatedly control shape and appearance.
![]()
其中x是坐标,v是视角方向, z s z_s zs 表示shape code, z a z_a za表示appearance code。 Γ \Gamma Γ 是position encoding 操作, ⊕ \oplus ⊕ 是链接操作。
3.2. Disentangled Conditional NeRF
之前的NERF没有conditional generation ability。 shape和appearance 会相互干预。
we propose our disentangled conditional NeRF architecture to achieve individual control over both shape and appearance by properly disentangling the conditioning mechanism.
Conditional Shape Deformation.
我们设计了一个shape deformation network: τ : ( x , z s ) → △ x \tau: (x,z_s) \rightarrow \bigtriangleup x τ:(x,zs)→△x, △ x \bigtriangleup x △x 是对应位置编码的位移向量,因此,变形的位置编码表示为: Γ ∗ ( p , z s ) = γ ∗ ( p , △ p ) ∣ p ∈ p , △ p ∈ τ ( p , z s ) \Gamma^*(p,z_s) = \gamma^*(p, \bigtriangleup p) | p \in p, \bigtriangleup p \in \tau (p, z_s) Γ∗(p,zs)=γ∗(p,△p)∣p∈p,△p∈τ(p,zs) 被定义为:
![]()
Deferred Appearance Conditioning.
we also defer the appearance conditioning to concatenate the appearance code with the view direction as the input to the radiance prediction network, which allows manipulating the appearance without touching the shape information, i.e., density.
disentangled conditional NeRF
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第4张图片](http://img.e-com-net.com/image/info8/88962a4b8d82482398dff9346f909f89.jpg)
- 形状代码旨在通过变形网络来变形volume field.
- 这种解缠条件NeRF以对抗的方式训练。
- 然后给出一个参考图像或文本提示,CLIP图像或文本编码器为形状和外观映射器提取相应的特征嵌入,分别在潜在空间中倾斜一个局部步骤,用于形状和外观操作。
- 这两个映射器使用CLIP相似损失和我们预先训练的解纠缠条件NeRF来训练。
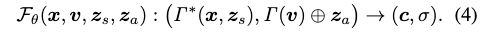
后续简化表达为: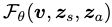 。
。
3.3. CLIP-Driven Manipulation
给定输入文本提示t,和初始的shape 和 appearance code z s ′ , z a ′ z'_s,z_a' zs′,za′, 我们训练一个shape mapper M s M_s Ms 和 appearance mapper M a M_a Ma 来更新code:
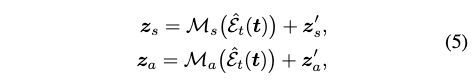
其中 ε t ( ⋅ ) ^ \hat{\varepsilon_t(\cdot)} εt(⋅)^ 表示预训练的CLIP 文本encoder
我们定义了一个cross-modal CLIP distance function D C L I P D_{CLIP} DCLIP(·, ·) 来测量输入文本和渲染图像之间的嵌入相似性:
![]()
其中 ε t ( ⋅ ) ^ \hat{\varepsilon_t(\cdot)} εt(⋅)^ 和 ε i ( ⋅ ) ^ \hat{\varepsilon_i(\cdot)} εi(⋅)^ 分表表示CLIP的文本和图像编码器。<·,·>是余弦相似度算子。
我们的距离还可以扩展到测量两个图像或两个文本提示之间的相似性。因此,我们的框架通过简单地将文本提示替换为上述公式中的示例,自然地支持使用图像示例进行编辑。
我们发现距离对小的物体差异比大的视野变化更敏感。这表明预先训练的CLIP模型能够支持3d感知应用程序的视图一致性表示。
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第5张图片](http://img.e-com-net.com/image/info8/9aebb60d3d844ffbbfbaf81895a9194c.jpg)
图2:虽然相机姿势变化很大,但同一物体的不同视角具有较高的相似性(小距离)。但即使在同一视角下,不同物体的相似度也较低(距离较大)。
3.4. Training Strategy
Our pipeline is trained in two stages:
- we first train the disentangled conditional NeRF including the conditional NeRF generator and the deformation network;
- then we fix the weights of the generator and train the CLIP manipulation parts including both the shape and appearance mappers.
生成对抗损失:
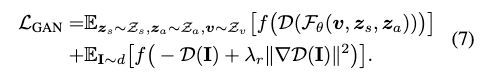
我们从预定义的文本库T中抽取文本提示符t,通过使用公式6, z s 、 z a z_s、z_a zs、za都是随机采样得到的。
我们用下面的损失trian 两个mapper:
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第6张图片](http://img.e-com-net.com/image/info8/d3eafb51d2c3493a97683114a43206b9.jpg)
3.5. Inverse Manipulation
we design an iterative method to alternatively optimize the shape code z s z_s zs, the appearance code z a z_a za, and the camera v.
To be specific, during each iteration, we first optimize vwhile keeping zs and za fixed using the following loss:
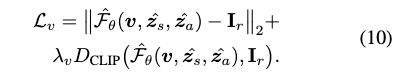
We then update the shape code by minimizing:
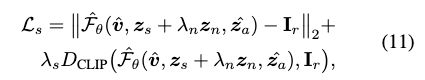
The appearance code is updated in a similar manner:

Experiments
数据集:
- 随机视角渲染
4.1. Compared to EditNeRF
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第7张图片](http://img.e-com-net.com/image/info8/1a34abd4a1f24aa59534afd22e2a97b0.jpg)
EditNeRF is trained using 600 instances with 40 views per instance while ours uses only one view.
Besides, camera pose parameters are required during training of EditNeRF but unknown for us.
EditNeRF要求用户选择目标颜色并在局部区域上绘制粗画 (出现了颜色的不连续,并且生成的颜色和目标颜色不完全一致 )
相比之下,我们允许用户通过提供文本提示来更简单地更改颜色,并且我们的方法产生了更自然的编辑结果。
EditNeRF只能支持局部形状编辑,比如形状部分移除。给定用户的编辑涂鸦,例如,指示删除椅子的腿(在红色矩形中)
与之相比,我们的方法支持较大程度的形状变形,并能很好地推广到未见的视图。
此外,EditNeRF作为一种基于优化的方法,需要花费大量的时间进行优化,而我们的前馈代码映射器可以更快地推断目标形状和外观(表1)。
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第8张图片](http://img.e-com-net.com/image/info8/64c57c8be7a24b469c708acda9f10b5c.jpg)
EditNeRF通过使用标准NeRF光度损失微调条件NeRF来推断形状和外观代码。我们基于优化的反转方法得益于CLIP提供多视图一致性表示的能力
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第9张图片](http://img.e-com-net.com/image/info8/99907229fabc4900b5a9068ea7694de3.jpg)
4.2. Ablation Study
the disentangled design:
在编辑形状时,后者可以改变外观,而我们的保持外观不变。
我们的解纠缠条件NeRF实现了单独的形状控制,因为conditional shape deformation network能够隔离形状条件。
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第10张图片](http://img.e-com-net.com/image/info8/948dd98bc99e4797b3199b62925d147d.jpg)
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第11张图片](http://img.e-com-net.com/image/info8/55cf8541961f4598bab4b2c2aea55c50.jpg)
Inversion:
As discussed in Section 3.3, CLIP has the capability to produce robust poseinvariant features. Therefore, our inversion method introduces a CLIP constraint during optimization and achieves better inversion results thanks to the CLIP prior.
4.3. CLIP-Driven Manipulation
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第12张图片](http://img.e-com-net.com/image/info8/d259a6283e564a788329fa8aaf73f5d7.jpg)
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第13张图片](http://img.e-com-net.com/image/info8/2deb006f19834f98a118e5312406206d.jpg)
Conclusion
-
We present the first text-and-image driven manipulation method for NeRF by designing a unified framework to provide users with flexible control over 3D content using either a text prompt or an exemplar image.
-
We design a disentangled conditional NeRF architecture that allows disentangling shape and appearance while editing an object, and two feedforward code mappers enable fast inference for editing different objects.
-
Further, we proposed an inversion method to infer the shape and appearance codes from a real image, allowing editing the existing data.
limitation:
由于潜在空间和预先训练的CLIP的表达能力有限,我们的模型不能处理fine-grained edits 和 out-of-domain edits。这可以通过添加更多不同的训练数据来缓解。
![[论文解析]CLIP-NeRF: Text-and-Image Driven Manipulation of Neural Radiance Fields_第14张图片](http://img.e-com-net.com/image/info8/b9bd636bf7a14e38a41659383b9d58d4.jpg)