实训——基于大数据Hadoop平台的医疗平台项目实战
文章目录
- 医疗平台项目描述
-
- 数据每列的含义
- 数据分析业务需求
- 架构图
- 成果图
- 环境搭建
医疗平台项目描述
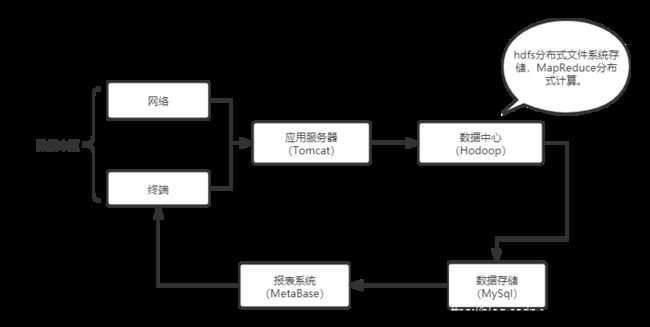
本次项目实训的目的是创建一个基于医疗行业问诊的通用数据分析平台。该平台立足于医疗行业背景,以采集国内医院、诊所和药店的各种病人(患者)的信息、资料和履历为数据源。并通过基于大数据的统计分析手段提炼出当前医疗行业各种运行指标,从中找出国内医疗设施、技术和服务存在的各种问题及不足;从而为完善和规范我国医疗行业制度、提升医疗技术水平提供数据支撑,为保障我国国民身体健康素质提供强有力的保障。本次实训按大数据分析平台的通用流程进行实施,其平台实施过程包括数据收集、分布式存储、分布式计算、数据转换与统计、数据抽取与存储、数据分析与展现等
- 数据收集:将分散到各大医院、诊所和药店的患者数据收集起来推入数据中心,数据中心启用自动化脚本将数据推入分布式存储系统
- 分布式存储:收集的数据分散存储到大数据集群中的各个数据节点上,可通过横向扩展数据节点提升集群的存储容量
- 分布式计算:分析统计业务并结合大数据离线MapReduce算法分离出过滤阶段和统计阶段,并将计算包分发到各个计算节点上完成数据过滤、转换和统计过程
- 数据转换与统计:根据分析业务,在MapReduce框架的调度下执行数据过滤、转换与统计聚合过程并将统计分析结果写回分布式存储系统
- 数据抽取与存储:将统计分析结果通过Job提交方式抽取到关系数据库MySql存储系统中,以供前台提取数据做展现之用
- 数据分析与展现:通过关系数据库SQL语句查询MySql数据库存储系统中的数据,并将其数据推送给报表系统Metabase以生成报表图展现
年龄层次、人口数量、慢性患病率、重症患病率、精准治愈率、地域区间(西南片区、城市)、
政府支出、个人支出、社保参与人数、商业保险参与人数、医保基金收入、来源(医院/诊所/药店)
使用代码编写数据生成器,生成的数据有部分干扰项(便于Mapper处理)、一到两个简单的统计项,便于Reducer处理, 后续的统计分析业务放到Metabase中去处理
数据每列的含义
年龄、性别、身高、体重、出生年份、地区、(是否有)医保、(是否有)商保、(有无)病历、(是否)患病、患病类型(没有、慢性、急性、重症)、(是否)治愈(是、否、无)、治疗费用、个人支出、医保支出、商保支出、来源(医院/诊所/药店)
数据分析业务需求
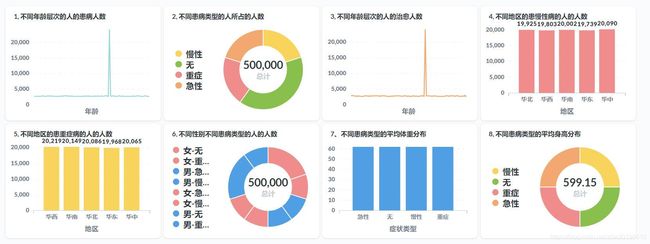
- 不同年龄层次的人的患病人数(曲线图)
- 不同患病类型的人所占的人数(饼图)
- 不同年龄层次的人的治愈人数(曲线图)
- 不同地区的患慢性病的人的人数(柱状图)
- 不同地区的患重症病的人的人数(柱状图)
- 不同性别不同患病类型的人的人数(饼图)
- 不同患病类型的平均体重分布(饼图)
- 不同患病类型的平均身高分布(饼图)
- 不同地区不同患病类型的人的人数(饼图)
- 医疗保险参与人数随年龄层次增长的变化趋势(曲线图)
- 商业保险参与人数随年龄层次增长的变化趋势(曲线图)
- 有病历的人的医疗保险参与人数随年龄层次增长的变化趋势(曲线图)
- 无病历的人的医疗保险参与人数随年龄层次增长的变化趋势(曲线图)
- 个人、医保、商保支出所占比例(饼图)
- 个人支出随年龄层次变化趋势图(曲线图)
- 医保支出随年龄层次变化趋势图(曲线图)
- 商保支出随年龄层次变化趋势图(曲线图)
- 医院、诊所、药店各自总收入汇总(饼图)
- 医院消费额度随不同年龄层次的变化规律(曲线图)
- 诊所消费额度随不同年龄层次的变化规律(曲线图)
- 药店消费额度随不同年龄层次的变化规律(曲线图)
架构图
成果图
环境搭建
Vmware的虚拟网络设置为192.168.162.0
在安装CentOs时看配置好网卡、主机名等
ip为192.168.162.XX,
主机名CC0,CC1,CC2,CC3
集群有四个平行节点
其中,令cc3节点为主节点(名称节点) , cco、cc1、cc2三个节点为次节点(数据节点),我们先安装好CC3的环境,克隆到各个节点
1.查看ip地址
ip a
修改主机的ip为静态地址192.168.162.121
vi /etc/sysconfig/network-scripts/ifcfg-ens32
参考内容如下
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens32
UUID=9ac40fa7-e883-4b2d-93f3-a4c1c81a8c96
DEVICE=ens32
ONBOOT=yes
IPADDR=192.168.162.121
PREFIX=24
GATEWAY=192.168.162.2
DNS1=114.114.114.114
IPV6_PRIVACY=no
wq保存退出,重启网卡
systemctl restart network
2.修改主机名,编辑文件
vi /etc/hostname
也可以使用命令设置主机名
hostnamectl set-hostname CC1
3.安装常用的软件wget、lrzsz、ntp、gcc、unzip、unzip
yum install -y wget lrzsz ntp gcc unzip
启动ntp
service ntpd start
4.下载Hadoop、MySQL、Java、Sqoop、metabase、mysql-connector-java-8.0.25等文件
推荐在Windows下面下载好了tar文件,上传到虚拟机,全部文件如下

hadoop: https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
mysql8.0:https://repo.mysql.com//mysql80-community-release-el7-3.noarch.rpm
jdk: https://download.oracle.com/otn/java/jdk/11.0.11+9/ab2da78f32ed489abb3ff52fd0a02b1c/jdk-11.0.11_linux-x64_bin.tar.gz?AuthParam=1625640177_0e9bf71daf6d9df1b4ca7b2e78896511
5.修改hosts文件
vi etc/hosts
追加以下内容
192.168.162.120 CC0
192.168.162.121 CC1
192.168.162.122 CC2
192.168.162.123 CC3
6.新建Haoop用户,在新建用户之前先查看用户是否存在
grep hadoop /etc/passwd
没有输出表示不存在,则可以添加用户
useradd -md /home/hadoop hadoop
-m是没有就创建,-d是指定路径
设置Hadoop用户密码, 需要在root用户的状态下
passwd hadoop
7.关闭防火墙和selinux
关闭防火墙:
sudo systemctl disable firewalld.service
systemctl stop firewalld
编辑seLinux文件
vi /etc/sysconfig/selinux
修改参数:
SELINUX=disabled
wq保存退出后,执行命令
setenforce 0
8.手动设置时间(安装了ntp,可以不做)
date -s "2021-06-29 15:12:50"
时间持久化
clock -w
9.在根路径下面新建两个文件夹(在保存install上传的文件,安装在software目录下)
mkdir -p / install / software
chmod 777 /install / software
10.安装MySQL、Java、Hadoop
10.1 安装MySQL并设置密码
yum -y install mysql80-community-release-el7-3.noarch.rpm
yum -y install mysql-community-server
systemctl start mysqld.service
systemctl status mysqld.service
grep "password" /var/log/mysqld.log
mysql -uroot -p
输入初始密码,此时不能做任何事情,因为MySQL默认必须修改密码之后才能操作数据库:初始密码在上面倒数第二行grep过滤的结果里面。
注意将new password换成新密码
ALTERUSER 'root'@'localhost' IDENTIFIED BY 'new password';
开启远程登陆
CREATEUSER 'root'@'%' IDENTIFIED BY 'new password';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
flush privileges;
10.2 安装JDK
解压到software目录里面
tar -zxvf jdk-11.0.11_linux-x64_bin.tar.gz -C /software/
切换到software里面的jdk文件
cd /software/jdk-11.0.11/
复制这个路径(使用pwd),后面配置环境需要,编辑配置环境的文件
vi /etc/profile,在末尾追加以下内容(所有需要添加的环境,注意版本号)
JAVA_HOME=/software/jdk-11.0.11
HADOOP_HOME=/software/hadoop-3.3.1
SQOOP_HOME=/software/sqoop-1.4.6
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/lib:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$SQOOP_HOME/bin:
export PATH JAVA_HOME HADOOP_HOME SQOOP_HOME
wq保存退出,使配置项生效
source /etc/profile
10.3 Hadoop安装
切换到Hadoop用户
su -l hadoop
解压Hadoop文件到software文件里面
tar -zxvf hadoop-3.3.1.tar.gz -C /software/
5.3.1修改5个配置文件
在Hadoop-env.sh文件中添加Java的环境
vi /software/hadoop-3.3.1/etc/hadoop/hadoop-env.sh
输入o添加一行,注意jdk版本
export JAVA_HOME=/software/jdk-11.0.11
在core-site.xml文件中修改。
vi /software/hadoop-3.3.1/etc/hadoop/core-site.xml
修改configuration部分的内容
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://CC3:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/software/hadoop/workvalue>
property>
configuration>
在hdfs-site.xml文件中修改
vi /software/hadoop/etc/hadoop/hdfs-site.xml
添加以下内容,其中dfs.replication是将一个分布式存储的文件块复制成多少个副本,下面的value是值
是多少就复制成多少
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
configuration>
在mapred-site.xml文件中修改
vi /software/hadoop/etc/hadoop/mapred-site.xml
分布式计算的名称
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
在yarn-site.xml文件中修改
vi /software/hadoop/etc/hadoop/yarn-site.xml
修改configuration部分的内容
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>CC3value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.application.classpathname>
<value>/software/hadoop-3.3.1/share/hadoop/common/*:/software/hadoop/share/hadoop/hdfs:/software/hadoop-3.3.1/share/hadoop/hdfs/lib/*:/software/hadoop/share/hadoop/hdfs/*:/software/hadoop-3.3.1/share/hadoop/mapreduce/lib/*:/software/hadoop/share/hadoop/yarn:/software/hadoop-3.3.1/share/hadoop/yarn/lib/*:/software/hadoop/share/hadoop/yarn/*value>
property>
configuration>
修改works文件
vi /software/hadoop/etc/hadoop/workers
删除里面的内容,写入下面的三行,这是另外几个主机的节点名
CC0
CC1
CC2
查看Hadoop文件是否属于Hadoop,是就切换到hadoop用户
不是的话就执行下面命令,是的话就不用管
chown -R hadoop:hadoop hadoop-3.3.1
10.4 安装sqoop
解压,设置环境变量(上面已经设置了)
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /software/
添加关系数据库驱动包(这里添加的是MySQL的驱动包)
mv /install/mysql-connector-java-8.0.25.jar /software/sqoop-1.4.6/lib/
5.5 安装metabase
上传metabase文件,使用unzip解压(在root下安装yum install -y unzip)
unzip metabase0.37.2.zip -d /software/
修改Env脚本配置(把最后几行注释),使用H2作为元数据库
vi /software/metabase0.37.2/conf
保存退出之后
cd /software/metabase0.37.2/bin/
执行StartUp脚本
Startup.sh
稍等一会就可以在浏览器中访问了
地址是cc3ip:3000,本文是192.168.162.123:3000
保存快照,复制虚拟机,并命名为CC0、CC1、CC2
启动CC0/1/3,配置好IP和主机名,参照CC3
11.配置CC3免密登录到其他的节点
按照hadoop官网上的文档提示:只需要设置从master节点到其它从节点免密登录即可在master节点上生成公私密钥对
先切换到hadoop用户下
su -l hadoop
生成公私密钥对
ssh-keygen -t rsa -P''
连续三次回车,之后使用下面命令拷贝公钥到每个节点
ssh-copy-id cc0
ssh-copy-id cc1
ssh-copy-id cc2
ssh-copy-id cc3
12.在cc3节点的Hadoop用户下,格式化
hdfs namenode -format
使用echo $?
检查是否成功,$?代表上一个命令执行后的退出状态,0表示成功
echo $?
或者查看是否有work文件夹,有work文件夹,也表示成功了
ls /software/hadoop-3.2.2/
13.启动dfs
start-dfs.sh
查看HDFS分布式系统的整体运行工况
hdfs dfsadmin -report
启动yarn集群
start-yarn.sh
停止顺序刚好相反
14.webPortal端监控
查看HDFS集群状态信息,打开浏览器访问
http://192.168.162.123:9870/
查看Yarn集群状态信息
http://192.168.162.123:8088/
15.在window上面配置maven
解压maven文件,移动到C:\Program Files目录下面,并添加bin到系统环境变量中。编辑C:\Program Files\apache-maven-3.8.1\conf\settings.xml文件
设置仓库存放路径
<localRepository>C:/maven-3.8.1-repolocalRepository>
在C盘中新建一个名为maven-3.8.1-repo的文件夹
16.编写三个Java文件代码
a、驱动类(入口类) 命名通常是XxxDriver
- 带入口方法main的类,
- 校验输入和输出
- 启动一个Job(指定过滤、转换和统计逻辑处理类)
- 整合并启动Job,执行分布式运算,得出最后的统计结果,数据源于分布式文件系统,数据计算完成后的去向也是分布式文件系统
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author zdw
* @description 驱动类, 需求8、不同患病类型的平均身高分布(饼图)的驱动
* 过滤器类输出的键值类型:Text和DoubleWritable
* 最终输出的键值类型:Text和DoubleWritable
*/
public class AvgHeightDriver {
public static void main(String[] args) throws Exception {
// 运行Job时必须要传递输入路径和输出路径
if (args == null || args.length <= 0) {
System.out.println("number of args must more than 2...");
return;
}
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://CC3:9000"), conf, "hadoop");
// 获取需要处理的数据文件路径
Path inputDir = new Path(args[0]);
// 获取数据处理完成之后的输出路径
Path outputDir = new Path(args[1]);
// 输入路径必须要存在
if (!fileSystem.exists(inputDir)) {
System.out.println("input path is not exists");
return;
}
// 输入路径必须是一个目录,不能是一个文件
if (fileSystem.getFileStatus(inputDir).isFile()) {
System.out.println("input path can not be file");
return;
}
// 输出路径必须不存在,如果存在则删除
if (fileSystem.exists(outputDir)) {
// 如果目录存在,就删除,true表示递归删除输出目录
fileSystem.delete(outputDir, true);
}
// 创建Job实例
Job AvgHeightJob = Job.getInstance(conf, "AvgHeight");
// 设置Job运行的入口类
AvgHeightJob.setJarByClass(AvgHeightDriver.class);
// 设置过滤器Mapper和统计类Reducer
AvgHeightJob.setMapperClass(AvgHeightMapper.class);
AvgHeightJob.setReducerClass(AvgHeightReducer.class);
// 设置过滤器类输出的键值类型
AvgHeightJob.setMapOutputKeyClass(Text.class);
AvgHeightJob.setMapOutputValueClass(DoubleWritable.class);
// 设置最终输出的键值类型
AvgHeightJob.setOutputKeyClass(Text.class);
AvgHeightJob.setOutputValueClass(DoubleWritable.class);
// 设置数据输入/输出分布式路径
FileInputFormat.setInputPaths(AvgHeightJob, inputDir);
FileOutputFormat.setOutputPath(AvgHeightJob, outputDir);
// 执行并等待Job完成
boolean flag = AvgHeightJob.waitForCompletion(true);
// 退出JAVA虚拟机进程
System.exit(flag ? 0 : 1);
}
}
b、过滤类(类似于SQL中的where了句),过滤数据的过程就是对数据的清洗过程
- 校验数据是否合法
- 校验数据类型
- 处理条件
- 将清洗的数据推送到统计类
import java.io.IOException;
import java.util.regex.Pattern;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author zdw
* @description 过滤器类, 按患病类型进行聚合统计
*/
public class AvgHeightMapper extends Mapper<LongWritable, Text, Text, DoubleWritable> {
// 输出键值实例
private Text outKey;
private DoubleWritable outValue;
// 处理的源数据中的字段使用制表符分割
private static final Pattern TAB = Pattern.compile("\t");
// 数据块在被读取之前调用一次setup方法
@Override
protected void setup(Mapper<LongWritable, Text, Text, DoubleWritable>.Context context) {
outKey = new Text();
outValue = new DoubleWritable();
}
/**
* 数据块的所有记录读取完成之后调用一次cleanup方法
*/
@Override
protected void cleanup(Mapper<LongWritable, Text, Text, DoubleWritable>.Context context) {
}
/**
* 每读取一行记录调用一次map方法
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
// 转换成JDK字符串
String line = value.toString().trim();
if (line.isEmpty())
return;
String[] fields = TAB.split(line);
if (fields.length != 17)
return;
String diseaseType = fields[10].trim();
int high = Integer.parseInt(fields[2].trim());
outKey.set(diseaseType);
outValue.set(high);
context.write(outKey, outValue);
}
}
c、统计类(相当于sQL语句中的分组、聚合)
- 计算每个组(部门)中的员工人数
- 计算每个组(部)中工资的总和
- 计算每个组(部门)的平均工资
- 将计算结果写出到分布式文件系统
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @author zdw
* @description 统计器类,统计出每种患病类型的人数,以及身高综合
* 需求8、不同患病类型的平均身高分布(饼图)
*/
public class AvgHeightReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable> {
// 输出键值实例
private DoubleWritable outValue;
// 数据块在读取之前调用一次setup方法
@Override
protected void setup(Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context) {
outValue = new DoubleWritable();
}
/**
* 数据块的所有记录读取完成之后调用一次cleanup方法
*/
@Override
protected void cleanup(Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context) {
}
/**
* 每读取一行记录调用一次reduce方法 每条记录包含聚合之后所有值
*/
@Override
protected void reduce(Text Type, Iterable<DoubleWritable> heights,
Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
// 患病类型数量、身高总和
int typeNum = 0, sum = 0;
for (DoubleWritable height : heights) {
typeNum++;
sum += height.get();
}
double avgHeight = 0;
if (typeNum != 0) {
avgHeight = (double) sum / typeNum;
}
// 设置输出值为平均值
outValue.set(avgHeight);
// 将统计结果输出到分布式文件系统
context.write(Type, outValue);
}
}
17.写好之后,打成jar包上传到CC3。当然还要上传数据文件
rz-y
在hadoop中新建src,再建两个目录作为输入输出
上传数据,将数据文件put到Hadoop的src目录中
hdfs dfs-put medical.log /src/input
18.进行分布式运算(MedBigData-1.0-SNAPSHOT.jar和AvgHeightDriver需要根据自己的实际情况改变)
hadoop jarMedBigData-1.0-SNAPSHOT.jar AvgHeightDriver /src/input /src/output
等待执行完成之后,查看output目录
hdfs dfs-ls /src/output
查看输出的内容
hdfs dfs-cat /src/output/part-r-00000
18.启动MySQL,执行建库脚本
DROP TABLE IF EXISTS `eight`;
CREATE TABLE `eight` (
`Type` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`Height` double NOT NULL
) ENGINE = MyISAM AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
查看建库脚本
show create table BigData.eight;
显示字段
desc BigData.salary;
执行sqoop导出数据的命令,注意填写自己的数据库密码,字段,表民
sqoop-export --export-dir '/src/output/part-r-00000' --fields-terminated-by '\t' --lines-terminated-by '\n' --connect 'jdbc:mysql://192.168.162.123:3306/BigData' --username '******' --password '******' --table 'eight' --columns "type,height"
结束,剩下的就是使用metabase进行数据可视化。