Spark SQL运行流程及性能优化:RBO和CBO
1 Spark SQL运行流程
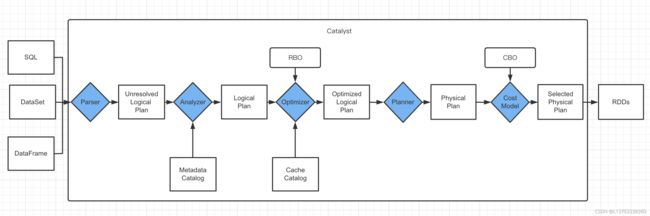
1.1 Spark SQL核心——Catalyst
Spark SQL的核心是Catalyst查询编译器,它将用户程序中的SQL/Dataset/DataFrame经过一系列操作,最终转化为Spark系统中执行的RDD。
1.2 Catalyst组成部分
- Parser :用Antlr将SQL/Dataset/DataFrame转化成一棵未经解析的树,生成 Unresolved Logical Plan
- Analyzer:Analyzer 结合 Catalog 信息对Parser中生成的树进行解析,生成 Resolved Logical Plan
- Optimizer:对解析完的逻辑计划进行树结构的优化,以获得更高的执行效率,生成 Optimized Logical Plan
- 谓词下推(Predicate Pushdown):PushdownPredicate 是最常见的用于减少参与计算的数据量的方法,将过滤操作下推到join之前进行
- 常量合并(Constant Folding):比如, x+(1+2) -> x+3
- 列值裁剪(Column Pruning):对列进行裁减,只留下需要的列
- Planner:Planner将Optimized Logical Plan 转换成多个 Physical Plan
- CostModel:CBO 根据 Cost Model 算出每个 Physical Plan 的代价并选取代价最小的 Physical Plan 作为最终的 Physical Plan
- Spark 以 DAG 的方法执行上述 Physical Plan,在执行 DAG 的过程中,Adaptive Execution 根据运行时信息动态调整执行计划从而提高执行效率
2 SQL优化器——RBO、CBO
SQL语句转化为具体执行计划是由SQL查询编译器决定的,同一个SQL语句可以转化成多种物理执行计划,如何指导编译器选择效率最高的执行计划,这就是优化器的主要作用。传统数据库(例如Oracle)的优化器有两种:
- 基于规则的优化器(Rule-Based Optimization,RBO)
- 基于代价的优化器(Cost-Based Optimization,CBO)。
2.1 RBO(Rule-Based Optimization)
RBO: Rule-Based Optimization也即“基于规则的优化器”,该优化器按照硬编码在数据库中的一系列规则来决定SQL的执行计划。只要按照这个规则去写SQL语句,无论数据表中的内容怎样、数据分布如何,都不会影响到执行计划。
基于规则优化是一种经验式、启发式地优化思路,更多地依靠前辈总结出来的优化规则,简单易行且能够覆盖到大部分优化逻辑,但是对于核心优化算子Join却显得有点力不从心。举个简单的例子,两个表执行Join到底应该使用BroadcastHashJoin 还是SortMergeJoin?当前SparkSQL的方式是通过手工设定参数来确定,如果一个表的数据量小于这个值就使用BroadcastHashJoin,但是这种方案显得很不优雅,很不灵活。基于代价优化(CBO)就是为了解决这类问题,它会针对每个Join评估当前两张表使用每种Join策略的代价,根据代价估算确定一种代价最小的方案 。
2.2 CBO(Cost-Based Optimization)
CBO: Cost-Based Optimization也即“基于代价的优化器”,该优化器通过根据优化规则对关系表达式进行转换,生成多个执行计划,然后CBO会通过根据统计信息(Statistics)和代价模型(Cost Model)计算各种可能“执行计划”的“代价”,即COST,从中选用COST最低的执行方案,作为实际运行方案。CBO依赖数据库对象的统计信息,统计信息的准确与否会影响CBO做出最优的选择。
CBO 原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理执行计划。其核心在于评估一个给定的物理执行计划的代价。物理执行计划是一个树状结构,其代价等于每个执行节点的代价总合。
每个执行节点的代价分为两个部分:
- 该执行节点对数据集的影响,或者说该节点输出数据集的大小与分布
- 该执行节点操作算子的代价
要计算每个执行节点的代价,CBO需要解决两个问题:
- 如何获取原始数据集的统计信息
- 如何根据输入数据集估算特定算子的输出数据集
2.3 join重排
2.3.1 join重排介绍
基于代价的优化器(Cost Based Optimizer,CBO)已经包含了Join重排的优化规则,join重排通过影响中间结果、具体join算法,从而影响join的执行效率
- Join的顺序影响中间结果的数据量,决定了Join的执行效率
- 假如A,B,C的数据量各自是1000条记录,如果A ⋈ C的数据量是1条记录,A ⋈ B是100条记录,显然A ⋈ B ⋈ C的效率低于A ⋈ C ⋈ B,因为前者的中间结果是100条记录,而后者是1条
- Join的顺序影响具体Join算法的效率,决定了Join的执行效率
- 比如Hash Join算法,它提前把右边表的数据建立一张哈希表,循环获取左边表的记录查表做Join。假设建立哈希表的代价很大,且随数据量线性递增,那么我们总希望更小的数据集在右边。假设A表是1000条记录,B表是10条记录,那么A ⋈ B优于B ⋈ A
2.3.2 join重排难点
- 穷举和验证最优方案的算法复杂度是指数级的(NP hard问题)
- 获取某个Join的中间结果数据量的代价很大。我们不得不实际执行一遍Join才能获知中间结果数据量,每个Join都可能花费数小时甚至数天。
2.3.3 join重排算法
- 动态规划:总能找到最优方案,但是复杂度是最高的
- 启发式算法:复杂度最低,只能找到次优解
- 贪婪算法:贪婪算法的好处是,它每次选择的一个Join都是可以实际执行的,因此我们很容易计算cost
- GOO算法:算法的复杂度比贪婪算法高,cost估计从实体的输入改为抽象的Join,难度更大,但是它的优势在于支持稠密树
- KBZ算法:KBZ或IIKBZ是在cost function满足ASI(adjacent sequence interchange)条件下理论最优的启发式算法
- 随机算法:效果是上面两种算法的折中
- Random Walk算法
- 模拟退火算法
- 基因算法
2.3.4 join重排总结
Join重排是一个较激进的优化规则,考虑到CBO无法完美估计数据量,打开这个规则可能会产生worst plan。
2.3 RBO和CBO比较
| RBO | CBO | |
| 实现 | RBO使用一组规则来确定如何执行查询 | 为每个SQL语句提供最便宜的执行计划 |
| 应用 | 几乎所有都支持 | Mysql 、Oracle、SQL Server、Spark sql、Hive、Presto |
| 难度 | 实现容易,时间换空间 | 实现困难,空间换时间 |
参考
Spark SQL 内部原理 RBO Catalyst Rule-based optimization | 技术世界 | spark,sql,RBO,基于规则的优化,大数据,集群,消息系统,郭俊 Jason,spark 优化,大数据架构,技术世界,spark sql
Spark SQL 性能优化再进一步 CBO 基于代价的优化 | 技术世界 | CBO,基于代价的优化,spark,sql,CBO,大数据,集群,消息系统,郭俊 Jason,spark 优化,大数据架构,技术世界,spark sqlSpark SQL 内部原理 RBO Catalyst Rule-based optimization | 技术世界 | spark,sql,RBO,基于规则的优化,大数据,集群,消息系统,郭俊 Jason,spark 优化,大数据架构,技术世界,spark sql
SQL优化器原理 - Join重排-阿里云开发者社区
Spark源码--逻辑计划优化之表达式简化_wusuopuBUPT的专栏-CSDN博客
SQL优化器-RBO与CBO分别是什么 - JasonCeng - 博客园