PySpark | SparkSQL函数 | SparkSQL运行流程
文章目录
-
- 一、SparkSQL函数定义
-
- 1. SparkSQL 定义UDF函数
-
- 1.1 UDF函数的创建
- 1.2 注册返回值是数组类型的UDF
- 1.3 注册返回是字典类型的UDF对象
- 1.4 通过RDD代码模拟UDAF效果
- 2. SparkSQL 使用窗口函数
- 3. 总结
- 二、SparkSQL的运行流程
-
- 1. SparkRDD的执行流程回顾
- 2. SparkSQL的自动优化
- 3. Catalyst优化器
- 4. SparkSQL的执行流程
- 三、SparkSQL整合Hive
-
- 1. 原理
- 2. 配置
- 3. 代码中集成
- 四、分布式SQL引擎配置
-
- 1. 概念
- 2. 配置
- 3. 客户端工具连接
- 4. 代码JDBC连接
传送门:
- 视频地址:黑马程序员Spark全套视频教程
- 1.PySpark基础入门(一)
- 2.PySpark基础入门(二)
- 3.PySpark核心编程(一)
- 4.PySpark核心编程(二)
- 5.PySaprk——SparkSQL学习(一)
- 6.PySaprk——SparkSQL学习(二)
- 7.Spark综合案例——零售业务统计分析
- 8. Spark3新特性及核心概念(背)
一、SparkSQL函数定义
1. SparkSQL 定义UDF函数
1.1 UDF函数的创建
无论Hive还是SparkSQL分析处理数据时,往往需要使用函数,SparkSQL模块本身自带很多实现公共功能的函数,在pyspark.sql.functions中。SparkSQL与Hive一样支持定义函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛。回顾Hive中自定义函数有三种类型:
- 第一种:UDF (User-Defined-Function)函数
一对一的关系,输入一个值经过函数以后输出一个值;
在Hive中继承UDF类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法; - 第二种:UDAF (User-Defined Aggregation Function)聚合函数
多对一的关系,输入多个值输出一个值,通常与groupBy联合使用; - 第三种:UDTF (User-Defined Table-Generating Functions)函数
—对多的关系,输入一个值输出多个值(一行变为多行);
用户自定义生成函数,有点像flatMap
在SparkSQL中,目前仅仅支持UDF函数和UDAF函数。目前Python仅支持UDF。SparkSQL定义UDF函数有两种方式:
方式一:sparksession.udf.register()
注册的UDF可以用于DSL和SQL。返回值用于DSL风格,传参内给的名字用于SQL风格。
方式1语法:
udf对象 = sparksession.udf.register(参数1,参数2,参数3)
参数1:UDF名称,可用于SQL风格
参数2:被注册成UDF的方法名
参数3:声明UDF的返回值类型
udf对象: 返回值对象,是一个UDF对象,可用于DSL风格
#!usr/bin/env python
# -*- coding:utf-8 -*-
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0.构建SparkSession执行环境入口对象
spark = SparkSession.builder. \
appName('test'). \
master('local[*]'). \
config("spark.sql.shuffle.partitions", 2). \
getOrCreate()
sc = spark.sparkContext
# 构建RDD
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7]).map(lambda x: [x])
df = rdd.toDF(['num'])
# TODO 1:方式1:sparksession.udf.register(),DSL和SQL风格均可以使用
# UDF的处理函数
def num_ride_10(num):
return num * 10
# 参数1:注册的UDF名称,这UDF名称可以用于SQL风格
# 参数2:UDF的处理逻辑,是一个单独的方法
# 参数3:UDF的返回值类型
# 注意:UDF注册时候,会声明返回值类型,并且UDF的真实返回值一定要和声明的返回值一致
# 返回值对象:这是一个UDF对象,既可以用于DSL语法
# 当前这种方式定义的UDF,可以通过参数1的名称用于SQL风格,通过返回值对象用于DSL风格
udf2 = spark.udf.register('udf1', num_ride_10, IntegerType())
# SQL风格中使用
# selectExpr以SELECT的表达式执行,
# select方法,接受普通的字符串字段名,或者返回值是Column对象的计算
df.selectExpr('udf1(num)').show()
# DSL风格中使用
# 返回值UDF对象,如果作为方法使用,传入的参数一定是Column对象。
df.select(udf2(df['num'])).show()
+---------+
|udf1(num)|
+---------+
| 10|
| 20|
| 30|
| 40|
| 50|
| 60|
| 70|
+---------+
+---------+
|udf1(num)|
+---------+
| 10|
| 20|
| 30|
| 40|
| 50|
| 60|
| 70|
+---------+
方式二:pyspark.sql.functions.udf
仅能用于DSL风格
方式2语法:
udf对象 = F.udf(参数1, 参数2)
参数1:被注册成UDF的方法名
参数2:声明UDF的返回值类型
udf对象: 返回值对象,是一个UDF对象,可用于DSL风格
#!usr/bin/env python
# -*- coding:utf-8 -*-
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0.构建SparkSession执行环境入口对象
spark = SparkSession.builder. \
appName('test'). \
master('local[*]'). \
config("spark.sql.shuffle.partitions", 2). \
getOrCreate()
sc = spark.sparkContext
# 构建RDD
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7]).map(lambda x: [x])
df = rdd.toDF(['num'])
def num_ride_10(num):
return num * 10
# TODO 2 :方式2注册:pyspark.sql.functions.udf,仅能用于SQL风格
udf3 = F.udf(num_ride_10, IntegerType())
df.select(udf3(df['num'])).show()
+----------------+
|num_ride_10(num)|
+----------------+
| 10|
| 20|
| 30|
| 40|
| 50|
| 60|
| 70|
+----------------+
使用UDF两种方式的注册均可以。唯一需要注意的就是:返回值类型—定要有合适的类型来声明。
- 返回int可以用IntergerType
- 返回值小数,可以用FolatType或者DoubleType
- 返回数组list可用ArrayType描述
- 返回字典可用StructType描述
这些Spark内置的数据类型均存储在:
pyspark.sql.types包中。
1.2 注册返回值是数组类型的UDF
注册一个ArrayType(数字\list)类型的返回值UDF。
注意:数组或者list类型,可以使用spark的 ArrayType来描述即可。
注意:声明ArrayType要类似这样: ArrayType(StringType( ) ),在ArrayType中传入数组内的数据类型
# coding:utf8
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions", 2).\
getOrCreate()
sc = spark.sparkContext
# 构建一个RDD
rdd = sc.parallelize([["hadoop spark flink"], ["hadoop flink java"]])
df = rdd.toDF(["line"])
# 注册UDF, UDF的执行函数定义
def split_line(data):
return data.split(" ") # 返回值是一个Array对象
# TODO1 方式1 构建UDF
udf2 = spark.udf.register("udf1", split_line, ArrayType(StringType()))
# DLS风格
df.select(udf2(df['line'])).show()
# SQL风格
df.createTempView("lines")
spark.sql("SELECT udf1(line) FROM lines").show(truncate=False)
# TODO 2 方式2的形式构建UDF
udf3 = F.udf(split_line, ArrayType(StringType()))
df.select(udf3(df['line'])).show(truncate=False)
+--------------------+
| udf1(line)|
+--------------------+
|[hadoop, spark, f...|
|[hadoop, flink, j...|
+--------------------+
+----------------------+
|udf1(line) |
+----------------------+
|[hadoop, spark, flink]|
|[hadoop, flink, java] |
+----------------------+
+----------------------+
|split_line(line) |
+----------------------+
|[hadoop, spark, flink]|
|[hadoop, flink, java] |
+----------------------+
1.3 注册返回是字典类型的UDF对象
注册一个字典类型的返回值的UDF。
注意: 字典类型返回值, 可以用StructType来进行描述。
StructType是一个普通的Spark支持的结构化类型,只是可以用在:
- DF中用于描述Schema
- UDF中用于描述返回值是字典的数据
# coding:utf8
import string
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions", 2).\
getOrCreate()
sc = spark.sparkContext
# 假设 有三个数字 1 2 3 我们传入数字 ,返回数字所在序号对应的 字母 然后和数字结合形成dict返回
# 比如传入1 我们返回 {"num":1, "letters": "a"}
rdd = sc.parallelize([[1], [2], [3]])
df = rdd.toDF(["num"])
# 注册UDF
def process(data):
return {"num": data, "letters": string.ascii_letters[data]}
"""
UDF的返回值是字典的话, 需要用StructType来接收
"""
udf1 = spark.udf.register("udf1", process, StructType().add("num", IntegerType(), nullable=True).\
add("letters", StringType(), nullable=True))
df.selectExpr("udf1(num)").show(truncate=False)
df.select(udf1(df['num'])).show(truncate=False)
+---------+
|udf1(num)|
+---------+
|{1, b} |
|{2, c} |
|{3, d} |
+---------+
+---------+
|udf1(num)|
+---------+
|{1, b} |
|{2, c} |
|{3, d} |
+---------+
1.4 通过RDD代码模拟UDAF效果
# coding:utf8
import string
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder. \
appName("test"). \
master("local[*]"). \
config("spark.sql.shuffle.partitions", 2). \
getOrCreate()
sc = spark.sparkContext
rdd = sc.parallelize([1, 2, 3, 4, 5], 3)
df = rdd.map(lambda x: [x]).toDF(['num'])
# 折中的方式 就是使用RDD的mapPartitions 算子来完成聚合操作
# 如果用mapPartitions API 完成UDAF聚合, 一定要单分区
single_partition_rdd = df.rdd.repartition(1)
def process(iter):
sum = 0
for row in iter:
sum += row['num']
return [sum] # 一定要嵌套list, 因为mapPartitions方法要求的返回值是list对象
print(single_partition_rdd.mapPartitions(process).collect())
[15]
2. SparkSQL 使用窗口函数
- 介绍
开窗函数的引入是为了既显示聚集前的数据,又显示聚集后的数据。即在每一行的最后一列添加聚合函数的结果。开窗用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。 - 聚合函数和开窗函数
聚合函数是将多行变成一行,count、avg等。开窗函数是将一行变成多行;
聚合函数如果要显示其他的列必须将列加入到group by中,开窗函数可以不使用group by,直接将所有信息显示出来 - 开窗函数分类
- 聚合开窗函数
聚合函数(列)OVER(选项),这里的选项可以是 PARTITION BY 子句,但不可以是 ORDER BY 子句。 - 排序开窗函数
排序函数(列)OVER(选项),这里的选项可以是 ORDER BY 子句,也可以是OVER(PARTITION BY子句 ORDER BY子句),但不可以是 PARTITION BY 子句。 - 分区类型NTILE的窗口函数
- 聚合开窗函数
实战:
# coding:utf8
import string
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder. \
appName("test"). \
master("local[*]"). \
config("spark.sql.shuffle.partitions", 2). \
getOrCreate()
sc = spark.sparkContext
rdd = sc.parallelize([
("张一", "class1", 99),
("张二", "class2", 35),
("张三", "class3", 57),
("张四", "class4", 12),
("张五", "class5", 99),
("张六", "class1", 90),
("张七", "class2", 91),
("张八", "class3", 33),
("张九", "class4", 55),
("张十", "class5", 66),
("张十一", "class1", 11),
("张十二", "class2", 33),
("张十三", "class3", 36),
("张十四", "class4", 79),
("张十五", "class5", 90),
("张十六", "class1", 90),
("张十七", "class2", 90),
("张十八", "class3", 11),
("张十九", "class4", 11),
("张二十", "class5", 3),
])
schema = StructType().add('name', StringType()). \
add('class', StringType()). \
add('score', IntegerType())
# rdd转dataframe
df = rdd.toDF(schema=schema)
df.createTempView('stu')
# TODO 1: 聚合窗口函数演示
spark.sql("""
SELECT * ,AVG(score) OVER() AS avg_score FROM stu
""").show()
# TODO 2:排序相关的窗口函数计算
spark.sql("""
SELECT * ,ROW_NUMBER() OVER(ORDER BY score DESC) AS row_number_rank,
DENSE_RANK() OVER(PARTITION BY class ORDER BY score DESC) AS dense_rank,
RANK() OVER(ORDER BY score) AS rank
FROM stu
""").show()
# TODO 3:NTILE窗口函数_分区类型函数
spark.sql("""
SELECT * , NTILE(6) OVER(ORDER BY score DESC)
FROM stu
""").show()
+------+------+-----+---------+
| name| class|score|avg_score|
+------+------+-----+---------+
| 张一|class1| 99| 54.55|
| 张二|class2| 35| 54.55|
| 张三|class3| 57| 54.55|
| 张四|class4| 12| 54.55|
| 张五|class5| 99| 54.55|
| 张六|class1| 90| 54.55|
| 张七|class2| 91| 54.55|
| 张八|class3| 33| 54.55|
| 张九|class4| 55| 54.55|
| 张十|class5| 66| 54.55|
|张十一|class1| 11| 54.55|
|张十二|class2| 33| 54.55|
|张十三|class3| 36| 54.55|
|张十四|class4| 79| 54.55|
|张十五|class5| 90| 54.55|
|张十六|class1| 90| 54.55|
|张十七|class2| 90| 54.55|
|张十八|class3| 11| 54.55|
|张十九|class4| 11| 54.55|
|张二十|class5| 3| 54.55|
+------+------+-----+---------+
+------+------+-----+---------------+----------+----+
| name| class|score|row_number_rank|dense_rank|rank|
+------+------+-----+---------------+----------+----+
| 张一|class1| 99| 1| 1| 19|
| 张六|class1| 90| 4| 2| 14|
|张十六|class1| 90| 6| 2| 14|
|张十一|class1| 11| 17| 3| 2|
| 张七|class2| 91| 3| 1| 18|
|张十七|class2| 90| 7| 2| 14|
| 张二|class2| 35| 13| 3| 8|
|张十二|class2| 33| 15| 4| 6|
| 张三|class3| 57| 10| 1| 11|
|张十三|class3| 36| 12| 2| 9|
| 张八|class3| 33| 14| 3| 6|
|张十八|class3| 11| 18| 4| 2|
|张十四|class4| 79| 8| 1| 13|
| 张九|class4| 55| 11| 2| 10|
| 张四|class4| 12| 16| 3| 5|
|张十九|class4| 11| 19| 4| 2|
| 张五|class5| 99| 2| 1| 19|
|张十五|class5| 90| 5| 2| 14|
| 张十|class5| 66| 9| 3| 12|
|张二十|class5| 3| 20| 4| 1|
+------+------+-----+---------------+----------+----+
+------+------+-----+-----------------------------------------------------------------------------------------------+
| name| class|score|ntile(6) OVER (ORDER BY score DESC NULLS LAST ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)|
+------+------+-----+-----------------------------------------------------------------------------------------------+
| 张一|class1| 99| 1|
| 张五|class5| 99| 1|
| 张七|class2| 91| 1|
| 张六|class1| 90| 1|
|张十五|class5| 90| 2|
|张十六|class1| 90| 2|
|张十七|class2| 90| 2|
|张十四|class4| 79| 2|
| 张十|class5| 66| 3|
| 张三|class3| 57| 3|
| 张九|class4| 55| 3|
|张十三|class3| 36| 4|
| 张二|class2| 35| 4|
| 张八|class3| 33| 4|
|张十二|class2| 33| 5|
| 张四|class4| 12| 5|
|张十一|class1| 11| 5|
|张十八|class3| 11| 6|
|张十九|class4| 11| 6|
|张二十|class5| 3| 6|
+------+------+-----+-----------------------------------------------------------------------------------------------+
3. 总结
- SparkSQL支持UDF和UDAF定义,但在Python中,暂时只能定义UDF
- UDF定义支持2种方式;
1:使用SparkSession对象构建——sparksession.udf.register()。
2: 使用functions包中提供的UDF API构建。
要注意, 方式1可用DSL和SQL风格,方式2 仅可用于DSL风格 - SparkSQL支持窗口函数使用,常用SQL中的窗口函数均支持,如聚合窗口\排序窗口\NTILE分组窗口等
二、SparkSQL的运行流程
1. SparkRDD的执行流程回顾
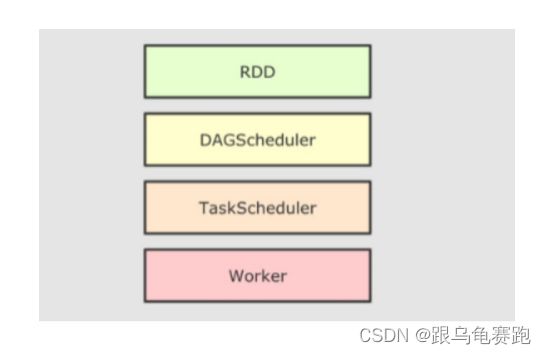
RDD的简易执行流程为:
代码 -> DAG调度器逻辑任务 -> Task调度器任务分配和管理监控 -> Worker干活
2. SparkSQL的自动优化
RDD的运行会完全按照开发者的代码执行, 如果开发者水平有限,RDD的执行效率也会受到影响。而SparkSQL会对写完的代码,执行“自动优化”, 以提升代码运行效率,避免开发者水平影响到代码执行效率。
这是因为RDD内含数据类型不限格式和结构。DataFrame是100%二维表结构,可以被针对。SparkSQL的自动优化,依赖于Catalyst优化器。
3. Catalyst优化器
为了解决过多依赖Hive的问题, SparkSQL使用了一个新的SQL优化器替代Hive 中的优化器,这个优化器就是Catalyst,整个SparkSQL的架构大致如下:

- API层简单来说就是Spark会通过一些API接受SQL语句
- 收到SQL语句以后,将其交给Catalyst,Catalyst负责解析SQL,生成执行计划等
- Catalyst的输出应该是 RDD的执行计划
- 最终交由集群运行
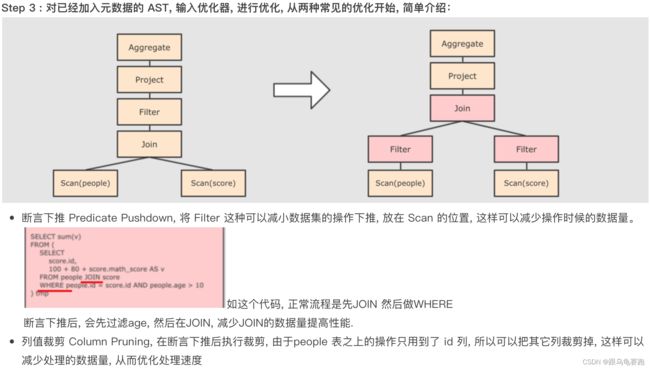
Catalyst优化器具体流程:


SparkSQL与parquet搭配很好用,因为parquet相比于csv、json是列式存储格式,非常适合列值裁剪。在读的时候就可以裁剪。
补充:SQL常见的执行顺序
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
- LIMIT
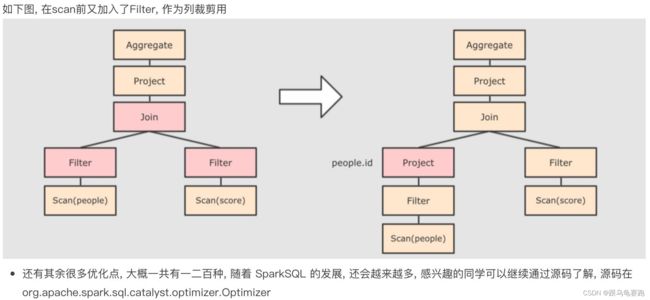
优化器总结:大方面的优化有两点
- 谓词下推(Predicate Pushdown)\断言下推:将逻辑判断提前到前面,以减少shuffle阶段的数据量。(行过滤,提前执行where)
- 列值裁剪(Column Pruning):将加载的列进行裁剪,尽量减少被处理数据的宽度(列过滤,提前规划select的字段数量)
4. SparkSQL的执行流程


三、SparkSQL整合Hive
1. 原理
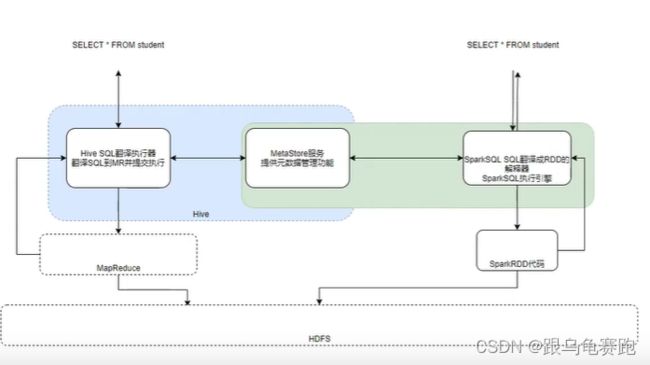
对于Hive来说,就两东西:
- SQL优化翻译器(执行引擎),翻译SQL到MapReduce并提交到YARN执行
- MetaStore元数据管理中心
对于Spark来说,自身是一个执行引擎,但是Spark自己没有元数据管理功能。
解决方案:
Spark提供执行引擎能力,Hive的MetaStore提供元数据管理功能。让Spark和Metastore连接起来,那么,Spark On Hive 就有了:
- 引擎: spark
- 元数据管理: metastore
总结:Spark On Hive 就是把Hive的MetaStore服务拿过来给Spark做元数据管理用而已。
2. 配置
根据原理,就是Spark能够连接上Hive的MetaStore就可以了。所以:
- MetaStore需要存在并开机
- Spark知道MetaStore在哪里(IP端口号)
步骤1:在spark的conf目录中,创建hive-site.xml,内容如下:

步骤2:将mysql的驱动jar包放入spark的jars目录
因为要连接元数据,会有部分功能连接到mysql库,需要mysql驱动包
步骤3:确保Hive配置了MetaStore相关的服务,检查hive配置文件目录内的: hive-site.xml,确保有如下配置:

步骤4:启动hive的MetaStore服务
[root@node1 hive]# nohup bin/hive --service metastore 2>&1 >> /export/server/hive/metastore.log &
[1] 13700
[root@node1 hive]# nohup: 忽略输入重定向错误到标准输出端
3. 代码中集成

# coding:utf8
import string
import time
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions", 2).\
config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse").\
config("hive.metastore.uris", "thrift://node1:9083").\
enableHiveSupport().\
getOrCreate()
sc = spark.sparkContext
spark.sql("SELECT * FROM student").show()
+---+--------+
| id| name|
+---+--------+
| 1|zhangsan|
| 2| wangwu|
+---+--------+
四、分布式SQL引擎配置
1. 概念
Spark中有一个服务叫做: ThriftServer服务,可以启动并监听在10000端口。这个服务对外提供功能,我们可以用数据库工具或者代码连接上来直接写SQL即可操作spark。

当使用ThrftServer后,相当于是一个持续性的Spark On Hive集成模式。它提供10000端口,持续对外提供服务,外部可以通过这个端口连接上来,写SQL,让Spark运行。
2. 配置

[root@node1 spark]# sbin/start-thriftserver.sh --hiveconf hive.server2.thrift.port=10000 --hiveconf hive.server2.thrift.bind.host=node1 --master local[*]
starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /export/server/spark/logs/spark-root-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-node1.itcast.cn.out
[root@node1 spark]# netstat -anp|grep 10000
tcp6 0 0 192.168.88.161:10000 :::* LISTEN 16374/java
这是Spark提供的10000端口,ThriftServer,底层是翻译成RDD运行的。
3. 客户端工具连接
通过这些客户端工具就连接上Spark,就可以将Spark当成数据库来使用。底层的功能由spark-sql翻译成RDD来运行。这样即保证了效率——分布式sql的执行,又保证了操作的方便。

4. 代码JDBC连接
# coding:utf8
from pyhive import hive
if __name__ == '__main__':
# 获取到Hive(Spark ThriftServer的链接)
conn = hive.Connection(host="node1", port=10000, username="root")
# 获取一个游标对象
cursor = conn.cursor()
# 执行SQL
cursor.execute("SELECT * FROM student")
# 通过fetchall API 获得返回值
result = cursor.fetchall()
print(result)
[(1, 'zhangsan'), (2, 'wangwu')]