spark-2.4.5编译支持Hadoop-3.3.1和Hive-3.1.2
文章目录
- SPARK源码编译
- 版本要求
-
- 前提准备---Maven安装
- 前提准备---Scala安装
- spark源码编译
- 编译问题
-
- 问题一
- 问题二
- Spark 单机模式启动并测试
- Spark集群配置
-
- 一、spark的安装路径:
- 二、现有系统环境变量:
- 三、查看并关闭防火墙
- 四、系统hosts设置
- 五、spark文件修改
- 六、集群启动:
- 七、集群测试
- Spark整合hive
-
- 1. 拷贝hive中的配置文件到spark中的conf目录下
- 2. 拷贝hive中的mysql驱动jar包到spark中的jars目录下
- 3. 启动服务
- 4. 整合测试
- 5. ThirftServer和beeline的使用测试
- 6.问题集锦
-
- Hadoop错误:
- Spark错误:
- 问题集锦
-
- Hadoop错误:
- Spark错误:
- WEB UI 界面
SPARK源码编译
版本要求
- Spark版本:Spark-2.4.5(15M的那个,只有spark源码)
- Maven版本:Maven-3.5.4
- Scala版本: Scala-2.11.12
- Hadoop版本:Hadoop-3.3.1
- Hive 版本:Hive-3.1.2
前提准备—Maven安装
- 根据Spark官网中Spark源码编译文档可知,最低版本需要Maven 3.5.4以及Java 8 ,最好按照官方得版本进行编译!
Maven环境配置
将路径/root/package/目录下的apache-maven-3.5.4-bin.tar.gz安装包移动到/opt/目录下
mv /root/package/apache-maven-3.5.4-bin.tar.gz /opt/
在/root/opt/目录下解压该文件并更改目录名称为maven-3.5.4
cd /opt/
tar -zxvf apache-maven-3.5.4-bin.tar.gz
mv apache-maven-3.5.4-bin maven-3.5.4
在maven目录下得conf文件夹下配置阿里云镜像
<mirror>
<id>alimavenid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
<mirrorOf>centralmirrorOf>
mirror>
配置maven环境变量
vi /etc/profile
![]()
使环境变量生效
source /etc/profile
检查是否配置成功
mvn -v

前提准备—Scala安装
在spark官网查看Spark2.4.5开发文档查看spark需要得Scala版本
![]()
解压Scala-2.11.12安装包到/opt/目录下并配置系统环境变量
![]()
使得环境变量生效
source /etc/profile
[root@dc6-80-209 ~]# mvn -v
Apache Maven 3.5.4 (1edded0938998edf8bf061f1ceb3cfdeccf443fe; 2018-06-18T02:33:14+08:00)
Maven home: /opt/maven-3.5.4
Java version: 1.8.0_342, vendor: Red Hat, Inc., runtime: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.aarch64/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "4.14.0-115.el7a.0.1.aarch64", arch: "aarch64", family: "unix"
[root@dc6-80-209 ~]# java -version
openjdk version "1.8.0_342"
OpenJDK Runtime Environment (build 1.8.0_342-b07)
OpenJDK 64-Bit Server VM (build 25.342-b07, mixed mode)
[root@dc6-80-209 ~]# scala -version
cat: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.aarch64/release: No such file or directory
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
[root@dc6-80-209 ~]#
spark源码编译
修改make-distribution.sh以跳过检查
vi dev/make-distribution.sh
注释掉一下内容,并在文件末尾添加如下配置:
#VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ 2>/dev/null | grep -v "INFO" | tail -n 1)
#SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ 2>/dev/null\
# | grep -v "INFO"\
# | tail -n 1)
#SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ 2>/dev/null\
# | grep -v "INFO"\
# | tail -n 1)
#SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ 2>/dev/null\
# | grep -v "INFO"\
# | fgrep --count "hive ";\
# # Reset exit status to 0, otherwise the script stops here if the last grep finds nothing\
# # because we use "set -o pipefail"
# echo -n)
# 设置版本信息
VERSION=2.4.5
SCALA_VERSION=2.11.12
SPARK_HADOOP_VERSION=3.3.1
SPARK_HIVE=3.1.2
在根目录执行如下命令:
./dev/make-distribution.sh --name build --tgz -Phadoop-3.3 -Dhadoop.version=3.3.1 -DskipTests -Pyarn -Phive -Phive-thriftserver
命令解释:
--name --tgz :是最后生成的包名,以及采用上面格式打包,比如,编译的是spark-2.4.5,那么最后编译成功后就会在 spark-2.4.5这个目录下生成 spark--bin-build.tgz
-Pyarn: 表示支持yarn
--Phadoop-3.3 :指定hadoop的主版本号
-Dhadoop.version: 指定hadoop的子版本号
-Phive -Phive-thriftserver:开启HDBC和Hive功能。
还可以加上:
-Dscala-2.11 :指定scala版本。
-DskipTests :忽略测试过程。
clean package:clean和package是编译目标。clean执行清理工作,比如清除旧打包痕迹,package用于编译和打包。
编译结果

编译spark-2.4.5编译支持Hadoop-3.3.1和Hive-3.1.2的tgz文件
spark–bin-build.tgz
编译问题
问题一
BUG
[WARNING] The requested profile "hadoop-3.3" could not be activated because it does not exist.
/opt/spark/build/zinc-0.3.15/bin/nailgun: line 50: /opt/spark/build/zinc-0.3.15/bin/ng/linux32/ng: cannot execute binary file
解决方法
在spark根目录下的pom.xml文件中修改Hadoop的版本配置
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<java.version>1.8java.version>
<maven.compiler.source>${java.version}maven.compiler.source>
<maven.compiler.target>${java.version}maven.compiler.target>
<maven.version>3.5.4maven.version>
<sbt.project.name>sparksbt.project.name>
<slf4j.version>1.7.16slf4j.version>
<log4j.version>1.2.17log4j.version>
<hadoop.version>3.3.1hadoop.version>
<protobuf.version>2.5.0protobuf.version>
<yarn.version>${hadoop.version}yarn.version>
<flume.version>1.6.0flume.version>
<zookeeper.version>3.4.6zookeeper.version>
<curator.version>2.6.0curator.version>
<hive.group>org.spark-project.hivehive.group>
<hive.version>1.2.1.spark2hive.version>
<hive.version.short>1.2.1hive.version.short>
<derby.version>10.12.1.1derby.version>
……
properties>
编译成功
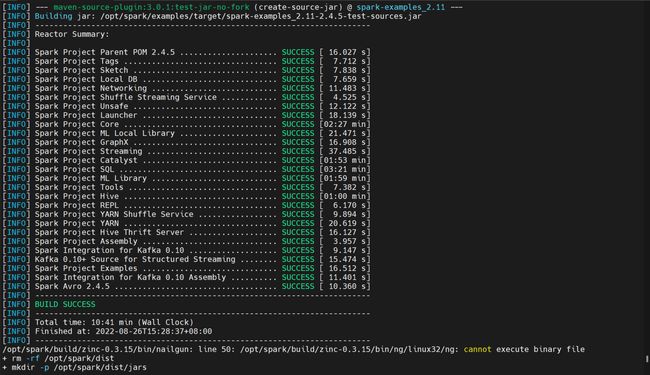
问题二
BUG
在sparkbin目录下启动spark-shell出现如下bug,不能够识别Hadoop的版本

解决办法
查看hive3.1.2源码,根据问题所在 :
在路径 org.apache.hadoop.hive.shims 下找到 ShimLoader抽象类中的getMajorVersion方法
/**
* Return the "major" version of Hadoop currently on the classpath.
* Releases in the 1.x and 2.x series are mapped to the appropriate
* 0.x release series, e.g. 1.x is mapped to "0.20S" and 2.x
* is mapped to "0.23".
*/
public static String getMajorVersion() {
String vers = VersionInfo.getVersion();
String[] parts = vers.split("\\.");
if (parts.length < 2) {
throw new RuntimeException("Illegal Hadoop Version: " + vers +
" (expected A.B.* format)");
}
switch (Integer.parseInt(parts[0])) {
case 2:
case 3:
return HADOOP23VERSIONNAME;
default:
throw new IllegalArgumentException("Unrecognized Hadoop major version number: " + vers);
}
}
在包org.apache.hadoop.util下找到VersionInfo类如下:
public class VersionInfo {
private static final Logger LOG = LoggerFactory.getLogger(VersionInfo.class);
private Properties info = new Properties();
private static VersionInfo COMMON_VERSION_INFO = new VersionInfo("common");
protected VersionInfo(String component) {
String versionInfoFile = component + "-version-info.properties";
InputStream is = null;
try {
is = ThreadUtil.getResourceAsStream(VersionInfo.class.getClassLoader(), versionInfoFile);
this.info.load(is);
} catch (IOException var8) {
LoggerFactory.getLogger(this.getClass()).warn("Could not read '" + versionInfoFile + "', " + var8.toString(), var8);
} finally {
IOUtils.closeStream(is);
}
}
………………
}
发现Hadoop的版本信息是从一个名为 “common-version-info.properties"这个文件中读取的,所以根据网上的说法,在spark的配置文件夹conf下自己添加一个 该文件,命令如下:
touch common-version-info.properties
vi common-version-info.properties
#在该文件中设置如下
version=2.7.6 #版本信息设置成2和3都可以,因为源码中的case 2和case 3 都 return HADOOP23VERSIONNAME
Spark 单机模式启动并测试
在$SPARK_HOME/bin下启动spark-shell
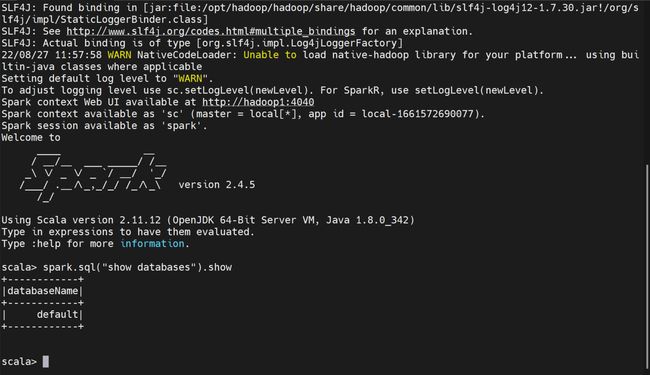
在$SPARK_HOME/bin下启动spark-sql

Spark集群配置
一、spark的安装路径:
/opt/spark
二、现有系统环境变量:
vi /etc/profile
# java
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.aarch64
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# spark
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/hadoop/bin/hadoop classpath)
vi ~/.bashrc
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export HADOOP_HOME=/opt/hadoop/hadoop
三、查看并关闭防火墙
systemctl status firewalld 查看防火墙状态
systemctl stop firewalld 关闭防火墙
四、系统hosts设置
vi /etc/hosts

- Hadoop1对应的主机为 172.36.65.14
- Hadoop2对应的主机为 172.36.65.16
- Hadoop3对应的主机为 172.36.65.15
主节点为Hadoop1 ,从节点分别为Hadoop2、Hadoop3
五、spark文件修改
- spark-env.sh 文件
先切换到$SPARK_HOME/conf目录下,执行如下命令
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
vi /opt/spark/conf/spark-env.sh
在spark-env.sh文件中添加如下内容:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.aarch64
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_POST=7077
export SPARK_WORKER_MEMORY=1G
- slaves文件
在slaves文件中添加如下内容:
# 将原先文件中的localhost注释掉
hadoop2
hadoop3
将spark文件分发到其他从结点上
cd $SPARK_HOME
cd ../
scp -r spark root@hadoop2:/opt/
scp -r spark root@hadoop3:/opt/
分别在hadoop2和hadoop3两台主机上配置spark的系统环境变量
六、集群启动:
在主机Hadoop1上的$SPARK_HOME/sbin目录下执行
start-all.sh
分别在各个主从结点上使用jps命令查看是否启动成功
# 主节点 Hadoop 1 中
[root@dc6-80-235 sbin]# jps
15713 Master
15826 Jps
#从节点 Hadoop 2 中
[root@dc6-80-209 sbin]# jps
8384 Worker
8455 Jps
#从节点 Hadoop 3 中
[root@dc6-80-210 sbin]# jps
1756 Worker
1838 Jps
在spark的ui界面中查看(需关闭master主机的防火墙) url为 “ master结点IP:8080 ”
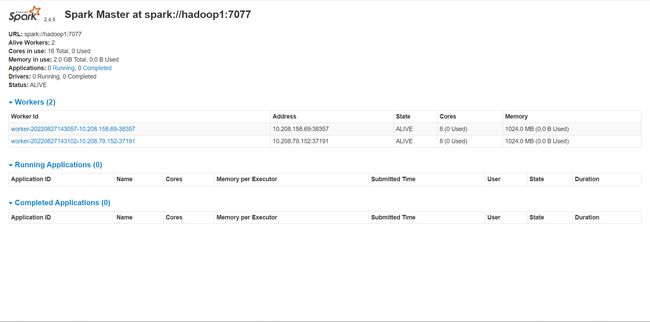
集群可以启动,通过jps查看都正确,但是通过ui界面却只能显示master结点
【解决办法】:
$SPARK_HOME/conf/路径下的spark-env.sh 文件中设置如下:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.342.b07-1.el7_9.aarch64
export SPARK_MASTER_HOST=hadoop1
export SPARK_MASTER_POST=7077
export SPARK_WORKER_MEMORY=1G
七、集群测试
Spark整合hive
1. 拷贝hive中的配置文件到spark中的conf目录下
- 查看hive-site.xml文件中的mysql数据库配置信息
<configuration>
<property>
<name>hive.server2.thrift.client.username>
<value>rootvalue>
<description>Username to use against thrift clientdescription>
property>
<property>
<name>hive.server2.thrift.client.passwordname>
<value>123456value>
<description>Password to use against thrift clientdescription>
property>`
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=truevalue>
<description>JDBC connect string for a JDBC metastoredescription>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.cj.jdbc.Drivervalue>
<description>Driver class name for a JDBC metastoredescription>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>hivevalue>
<description>username to use against metastore databasedescription>
property>
# 添加metastore的url配置(对应hive安装节点,我的为hadoop1节点)
<property>
<name>hive.metastore.urisname>
<value>thrift://hadoop1:9083value>
property>
- 整合需要spark能够读取找到Hive的元数据以及数据存放位置。将hive-site.xml文件拷贝到Spark的conf目录下,同时添加metastore的url配置(对应hive安装节点,我的为hadoop1节点)。
【提醒】
hive.metastore.uris启动metastore服务的端口必须设置为9083,否则将会出错!!!
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
<property>
<name>hive.server2.authenticationname>
<value>NOSASLvalue>
property>
<property>
<name>hive.metastore.localname>
<value>falsevalue>
property>
# 添加metastore的url配置(对应hive安装节点,我的为hadoop1节点)
<property>
<name>hive.metastore.urisname>
<value>thrift://hadoop1:9083value>
property>
- 修改后分发给其他结点
cd $HIVE_HOME/conf
scp -r hive-site.xml root@hadoop2:/opt/spark/conf/
scp -r hive-site.xml root@hadoop3:/opt/spark/conf/
2. 拷贝hive中的mysql驱动jar包到spark中的jars目录下
cd $HIVE_HOME/lib
scp -r mysql-connector-java-8.0.29 /opt/spark/jars/ #复制到本地主机为hadoop1
scp -r mysql-connector-java-8.0.29 root@hadoop2:/opt/spark/jars/ #复制到hadoop2
scp -r mysql-connector-java-8.0.29 root@hadoop3:/opt/spark/jars/ #复制到hadoop2
3. 启动服务
- 启动hadoop集群
使用start-all.sh命令启动集群,(系统环境变量中已经存在 $HADOOP_HOME/sbin的环境)
[root@dc6-80-235 jars]# start-all.sh
Starting namenodes on [localhost]
Last login: Sat Aug 27 15:54:02 CST 2022 on pts/10
localhost: namenode is running as process 24466. Stop it first and ensure /tmp/hadoop-root-namenode.pid file is empty before retry.
Starting datanodes
Last login: Sat Aug 27 16:00:00 CST 2022 on pts/10
localhost: datanode is running as process 24647. Stop it first and ensure /tmp/hadoop-root-datanode.pid file is empty before retry.
Starting secondary namenodes [dc6-80-235.novalocal]
Last login: Sat Aug 27 16:00:01 CST 2022 on pts/10
dc6-80-235.novalocal: secondarynamenode is running as process 24920. Stop it first and ensure /tmp/hadoop-root-secondarynamenode.pid file is empty before retry.
2022-08-27 16:00:20,039 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting resourcemanager
Last login: Sat Aug 27 16:00:07 CST 2022 on pts/10
resourcemanager is running as process 25263. Stop it first and ensure /tmp/hadoop-root-resourcemanager.pid file is empty before retry.
Starting nodemanagers
Last login: Sat Aug 27 16:00:20 CST 2022 on pts/10
localhost: nodemanager is running as process 25442. Stop it first and ensure /tmp/hadoop-root-nodemanager.pid file is empty before retry.
jps检测是否启动成功
[root@dc6-80-235 ~]# jps
1697 NameNode
1882 DataNode
2220 SecondaryNameNode
2573 ResourceManager
3150 Jps
2751 NodeManager
- 在各个结点中查看并启动Mysql服务
#查看mysql的状态
systemctl status mysqld
#启动mysql
systemctl start mysqld
- 启动hive metastore服务
#切换到hive中的bin目录下
cd $HIVE_HOME/bin
#启动metastore服务
hive --service metastore
启动成功的结果如下:

# 使用jps查看
[root@dc6-80-235 ~]# jps
992 RunJar # metastore 进程
1697 NameNode
1882 DataNode
2220 SecondaryNameNode
2573 ResourceManager
3150 Jps
2751 NodeManager
- 启动hive
# 在一个新终端上启动hive
cd $HIVE_HOME/bin
hive
启动结果如下
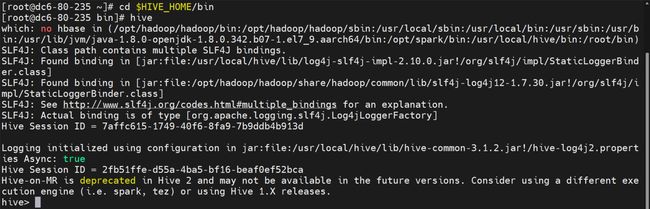
- 启动spark集群服务
# 切换到spark根目录中
cd $SPARK_HOME/sbin
#启动集群服务
[root@dc6-80-235 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-dc6-80-235.novalocal.out
hadoop2: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-dc6-80-209.novalocal.out
hadoop3: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-dc6-80-210.novalocal.out
- 在$SPARK_HOME/bin目录下启动spark-shell
[root@dc6-80-235 ~]# cd $SPARK_HOME/bin
[root@dc6-80-235 bin]# spark-shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/spark/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
22/08/27 17:53:04 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop1:4040
Spark context available as 'sc' (master = local[*], app id = local-1661593991736).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_342)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
- 在$SPARK_HOME/bin目录下启动spark-sql
[root@dc6-80-235 ~]# cd /opt/spark/bin/ # cd 到 $SPARK_HOME目录下
[root@dc6-80-235 bin]# spark-sql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/spark/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
22/08/28 17:21:47 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/08/28 17:21:48 INFO metastore: Trying to connect to metastore with URI thrift://hadoop1:9083
22/08/28 17:21:48 INFO metastore: Connected to metastore.
22/08/28 17:21:49 INFO SessionState: Created local directory: /tmp/ad7756f8-ca79-4693-aa49-fe401bf49adf_resources
22/08/28 17:21:49 INFO SessionState: Created HDFS directory: /tmp/hive/root/ad7756f8-ca79-4693-aa49-fe401bf49adf
22/08/28 17:21:49 INFO SessionState: Created local directory: /tmp/root/ad7756f8-ca79-4693-aa49-fe401bf49adf
22/08/28 17:21:49 INFO SessionState: Created HDFS directory: /tmp/hive/root/ad7756f8-ca79-4693-aa49-fe401bf49adf/_tmp_space.db
22/08/28 17:21:49 INFO SparkContext: Running Spark version 2.4.5
22/08/28 17:21:49 INFO SparkContext: Submitted application: SparkSQL::10.208.140.27
22/08/28 17:21:49 INFO SecurityManager: Changing view acls to: root
22/08/28 17:21:49 INFO SecurityManager: Changing modify acls to: root
22/08/28 17:21:49 INFO SecurityManager: Changing view acls groups to:
22/08/28 17:21:49 INFO SecurityManager: Changing modify acls groups to:
22/08/28 17:21:49 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
22/08/28 17:21:49 INFO Utils: Successfully started service 'sparkDriver' on port 34795.
22/08/28 17:21:49 INFO SparkEnv: Registering MapOutputTracker
22/08/28 17:21:49 INFO SparkEnv: Registering BlockManagerMaster
22/08/28 17:21:49 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
22/08/28 17:21:49 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
22/08/28 17:21:49 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-757d950e-8d54-4ac1-a17d-b7d9f0019ce6
22/08/28 17:21:49 INFO MemoryStore: MemoryStore started with capacity 366.3 MB
22/08/28 17:21:49 INFO SparkEnv: Registering OutputCommitCoordinator
22/08/28 17:21:49 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
22/08/28 17:21:49 INFO Utils: Successfully started service 'SparkUI' on port 4041.
22/08/28 17:21:49 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://hadoop1:4041
22/08/28 17:21:49 INFO Executor: Starting executor ID driver on host localhost
22/08/28 17:21:49 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 37823.
22/08/28 17:21:49 INFO NettyBlockTransferService: Server created on hadoop1:37823
22/08/28 17:21:49 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
22/08/28 17:21:50 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, hadoop1, 37823, None)
22/08/28 17:21:50 INFO BlockManagerMasterEndpoint: Registering block manager hadoop1:37823 with 366.3 MB RAM, BlockManagerId(driver, hadoop1, 37823, None)
22/08/28 17:21:50 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, hadoop1, 37823, None)
22/08/28 17:21:50 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, hadoop1, 37823, None)
22/08/28 17:21:50 INFO SharedState: loading hive config file: file:/opt/spark/conf/hive-site.xml
22/08/28 17:21:50 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('file:/opt/spark/bin/spark-warehouse').
22/08/28 17:21:50 INFO SharedState: Warehouse path is 'file:/opt/spark/bin/spark-warehouse'.
22/08/28 17:21:50 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
22/08/28 17:21:50 INFO HiveUtils: Initializing HiveMetastoreConnection version 1.2.1 using Spark classes.
22/08/28 17:21:50 INFO HiveClientImpl: Warehouse location for Hive client (version 1.2.2) is file:/opt/spark/bin/spark-warehouse
22/08/28 17:21:50 INFO metastore: Mestastore configuration hive.metastore.warehouse.dir changed from /user/hive/warehouse to file:/opt/spark/bin/spark-warehouse
22/08/28 17:21:50 INFO metastore: Trying to connect to metastore with URI thrift://hadoop1:9083
22/08/28 17:21:50 INFO metastore: Connected to metastore.
Spark master: local[*], Application Id: local-1661678509887
22/08/28 17:21:51 INFO SparkSQLCLIDriver: Spark master: local[*], Application Id: local-1661678509887
spark-sql> show databases;
22/08/28 17:22:01 INFO CodeGenerator: Code generated in 180.56121 ms
default
Time taken: 2.216 seconds, Fetched 1 row(s)
22/08/28 17:22:01 INFO SparkSQLCLIDriver: Time taken: 2.216 seconds, Fetched 1 row(s)
4. 整合测试
-
测试数据准备
# 在Linux主机上的/opt/路径下创建测试数据 [root@dc6-80-235 ~]# cd /opt/ [root@dc6-80-235 opt]# touch test.txt [root@dc6-80-235 opt]# ls cloudinit hadoop rh software spark test.txt zookeeper [root@dc6-80-235 opt]# vi test.txt # 在test.txt文件中编写测试数据如下 0001 hadoop 0002 yarn 0003 hbase 0004 hive 0005 spark 0006 mysql 0007 flume -
在打开的hive服务的终端窗口中创建数据库test以及表test并导入数据(数据源为test.txt文件)
# 创建数据库 test hive> create database test; OK Time taken: 11.584 seconds # 查看是否创建成功 hive> show databases; OK default test Time taken: 10.237 seconds, Fetched: 2 row(s) # 选择test数据库 hive> use test; OK Time taken: 10.077 seconds # 创建表test hive> create table if not exists test(userid string,username string) row format delimited fields terminated by ' ' stored as textfile; OK Time taken: 5.674 seconds # 查看是否创建成功 hive> show tables; OK test Time taken: 10.089 seconds, Fetched: 1 row(s) # 从本地文件中导入数据到test表中 hive> load data local inpath "/opt/test.txt" into table test; Loading data to table test.test OK Time taken: 6.653 seconds hive> -
在spark-shell服务的终端窗口中查看数据
scala> spark.sql("show databases").collect(); res1: Array[org.apache.spark.sql.Row] = Array([default]) scala> spark.sql("select * from test.test").show() +------+--------+ |userid|username| +------+--------+ | 0001| hadoop| | 0002| yarn| | 0003| hbase| | 0004| hive| | 0005| spark| | 0006| mysql| | 0007| flume| | | null| +------+--------+ -
在spark-sql服务的终端窗口中查看数据
spark-sql> show databases; default test Time taken: 0.028 seconds, Fetched 2 row(s) 22/08/28 17:38:34 INFO SparkSQLCLIDriver: Time taken: 0.028 seconds, Fetched 2 row(s) spark-sql> use test; Time taken: 0.046 seconds 22/08/28 17:38:44 INFO SparkSQLCLIDriver: Time taken: 0.046 seconds spark-sql> select * from test; 22/08/28 17:38:59 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 479.1 KB, free 365.8 MB) 22/08/28 17:38:59 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 52.3 KB, free 365.8 MB) 22/08/28 17:38:59 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on hadoop1:37823 (size: 52.3 KB, free: 366.2 MB) 22/08/28 17:38:59 INFO SparkContext: Created broadcast 0 from 22/08/28 17:38:59 INFO FileInputFormat: Total input files to process : 1 22/08/28 17:38:59 INFO SparkContext: Starting job: processCmd at CliDriver.java:376 22/08/28 17:38:59 INFO DAGScheduler: Got job 0 (processCmd at CliDriver.java:376) with 1 output partitions 22/08/28 17:38:59 INFO DAGScheduler: Final stage: ResultStage 0 (processCmd at CliDriver.java:376) 22/08/28 17:38:59 INFO DAGScheduler: Parents of final stage: List() 22/08/28 17:38:59 INFO DAGScheduler: Missing parents: List() 22/08/28 17:38:59 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[4] at processCmd at CliDriver.java:376), which has no missing parents 22/08/28 17:38:59 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 8.1 KB, free 365.8 MB) 22/08/28 17:38:59 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 4.4 KB, free 365.8 MB) 22/08/28 17:38:59 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on hadoop1:37823 (size: 4.4 KB, free: 366.2 MB) 22/08/28 17:38:59 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1163 22/08/28 17:38:59 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[4] at processCmd at CliDriver.java:376) (first 15 tasks are for partitions Vector(0)) 22/08/28 17:38:59 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks 22/08/28 17:38:59 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, ANY, 7923 bytes) 22/08/28 17:38:59 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 22/08/28 17:38:59 INFO HadoopRDD: Input split: hdfs://localhost:9000/user/hive/warehouse/test.db/test/test.txt:0+77 22/08/28 17:39:00 INFO ContextCleaner: Cleaned accumulator 2 22/08/28 17:39:00 INFO ContextCleaner: Cleaned accumulator 0 22/08/28 17:39:00 INFO ContextCleaner: Cleaned accumulator 1 22/08/28 17:39:00 INFO ContextCleaner: Cleaned accumulator 3 22/08/28 17:39:00 INFO CodeGenerator: Code generated in 24.82466 ms 22/08/28 17:39:00 INFO LazyStruct: Missing fields! Expected 2 fields but only got 1! Ignoring similar problems. 22/08/28 17:39:00 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1519 bytes result sent to driver 22/08/28 17:39:00 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 276 ms on localhost (executor driver) (1/1) 22/08/28 17:39:00 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 22/08/28 17:39:00 INFO DAGScheduler: ResultStage 0 (processCmd at CliDriver.java:376) finished in 0.349 s 22/08/28 17:39:00 INFO DAGScheduler: Job 0 finished: processCmd at CliDriver.java:376, took 0.415864 s 0001 hadoop 0002 yarn 0003 hbase 0004 hive 0005 spark 0006 mysql 0007 flume NULL Time taken: 1.392 seconds, Fetched 8 row(s) 22/08/28 17:39:00 INFO SparkSQLCLIDriver: Time taken: 1.392 seconds, Fetched 8 row(s) spark-sql> 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 26 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 23 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 19 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 17 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 18 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 21 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 8 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 29 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 6 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 12 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 22 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 27 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 14 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 11 22/08/28 17:51:50 INFO BlockManagerInfo: Removed broadcast_1_piece0 on hadoop1:37823 in memory (size: 4.4 KB, free: 366.2 MB) 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 5 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 13 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 28 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 9 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 4 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 7 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 10 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 25 22/08/28 17:51:50 INFO BlockManagerInfo: Removed broadcast_0_piece0 on hadoop1:37823 in memory (size: 52.3 KB, free: 366.3 MB) 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 24 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 20 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 15 22/08/28 17:51:50 INFO ContextCleaner: Cleaned accumulator 16
5. ThirftServer和beeline的使用测试
-
启动metastore服务
# $HIVE_HOME/bin 路径下 [root@dc6-80-235 bin]# hive --service metastore & [1] 26437 [root@dc6-80-235 bin]# 2022-08-28 18:14:29: Starting Hive Metastore Server SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] # 查看是否启动成功 [root@dc6-80-235 ~]# jps 22736 SparkSubmit 21106 ResourceManager 21285 NodeManager 26437 RunJar # metastore 服务 20726 SecondaryNameNode 22438 SparkSubmit 20359 DataNode 21932 Master 20189 NameNode 26590 Jps -
启动thriftserver服务
# $SPARK_HOME/bin 目录下 [root@dc6-80-235 sbin]# ./start-thriftserver.sh starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /opt/spark/logs/spark-root-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-dc6-80-235.novalocal.out # 查看是否启动成功 [root@dc6-80-235 sbin]# jps 22736 SparkSubmit 21106 ResourceManager 21285 NodeManager 26437 RunJar 20726 SecondaryNameNode 22438 SparkSubmit 20359 DataNode 26904 Jps 21932 Master 20189 NameNode 26765 SparkSubmit # 所启动的thriftserver服务的进程号 [root@dc6-80-235 sbin]# -
通过beeline链接
# 在$SPARK_HOME/bin 路径下 # !connect jdbc:hive2://主机名:端口号 beeline> !connect jdbc:hive2://hadoop1:10000 Connecting to jdbc:hive2://hadoop1:10000 Enter username for jdbc:hive2://hadoop1:10000: hive Enter password for jdbc:hive2://hadoop1:10000: ****** 22/08/28 18:29:27 INFO Utils: Supplied authorities: hadoop1:10000 22/08/28 18:29:27 INFO Utils: Resolved authority: hadoop1:10000 22/08/28 18:29:27 INFO HiveConnection: Will try to open client transport with JDBC Uri: jdbc:hive2://hadoop1:10000 Connected to: Spark SQL (version 2.4.5) Driver: Hive JDBC (version 1.2.1.spark2) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://hadoop1:10000> -
使用sql命令访问hive中的数据
0: jdbc:hive2://hadoop1:10000> show databases; +---------------+--+ | databaseName | +---------------+--+ | default | | test | +---------------+--+ 2 rows selected (0.754 seconds) 0: jdbc:hive2://hadoop1:10000> use test; +---------+--+ | Result | +---------+--+ +---------+--+ No rows selected (0.044 seconds) 0: jdbc:hive2://hadoop1:10000> select * from test.test; +---------+-----------+--+ | userid | username | +---------+-----------+--+ | 0001 | hadoop | | 0002 | yarn | | 0003 | hbase | | 0004 | hive | | 0005 | spark | | 0006 | mysql | | 0007 | flume | | | NULL | +---------+-----------+--+ 8 rows selected (1.663 seconds)
6.问题集锦
Hadoop错误:
- Warning 1:
Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: no hadoop in java.library.path
在/HADOOP_HOME/etc/hadoop/中的hadoop_env.sh头部添加了如下信息:
export HADOOP_COMMON_LIB_NATIVE_DIR="/usr/local/hadoop/lib/native/"
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=/usr/local/hadoop/lib/native/"
- Warning 2:

【解决方案】
使用命令:hdfs dfsadmin -safemode leave 关闭 Hadoop 的安全模式
- Warning 3:
hdfs 页面没有/tmp权限
【解决方案】
hdfs dfs -chmod -R 755 /tmp
Spark错误:
- Warning 1:
Master主机正常,从从节点Worker机器中的$SPARK_HOME/logs目录下发现如下错误,从节点无法与主节点建立连接
Caused by: java.net.NoRouteToHostException: No route to host
【解决方案】
检查并关闭Master结点的防火墙
问题集锦
Hadoop错误:
- Warning 1:
Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: no hadoop in java.library.path
在/HADOOP_HOME/etc/hadoop/中的hadoop_env.sh头部添加了如下信息:
export HADOOP_COMMON_LIB_NATIVE_DIR="/usr/local/hadoop/lib/native/" export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=/usr/local/hadoop/lib/native/"
- Warning 2:
[外链图片转存中…(img-17TInDVf-1661694827124)]
【解决方案】
使用命令:hdfs dfsadmin -safemode leave 关闭 Hadoop 的安全模式
-
Warning 3:
hdfs 页面没有/tmp权限
【解决方案】
hdfs dfs -chmod -R 755 /tmp
Spark错误:
- Warning 1:
Master主机正常,从从节点Worker机器中的$SPARK_HOME/logs目录下发现如下错误,从节点无法与主节点建立连接
Caused by: java.net.NoRouteToHostException: No route to host
【解决方案】
检查并关闭Master结点的防火墙
WEB UI 界面
-
Spark中Master的UI管理界面: http://172.36.65.14:8080/
-
Spark中Spark-shell的UI管理界面: http://172.36.65.14:4040/
-
Hadoop的UI管理界面: http://172.36.65.14:9870/dfshealth.html#tab-overview
(其中172.36.65.14为Master主机IP地址)
【问题反馈】
