spark 运行自带样例SparkPi、spark-examples报错
本人太蠢,命太差,基本把运行样例中所有的坑都踩了,大家根据下面的多种报错信息自行参考
报错时我使用的环境如下:
- windows10中运行,非linux虚拟机
- 使用微软的Terminal软件进入powershell环境
- scala 2.12.10
- spark-3.1.1-bin-hadoop3.2
- 没有单独安装hadoop环境
- java 8
注意一:该spark-3.1.1-bin-hadoop3.2在centos 7、树莓派4b+官方32位系统均可正常运行样例SparkPi,但唯独在window10中频繁报错
注意二:大家首先要确保自己的路径没有问题,spark-shell和spark-submit都是在bin目录下,而样例sparkPi是在examples目录下,所以要先返回到上级目录再进入examples目录中
注意三:还是路径问题。一定要确保SparkPi的样例名称是当前版本下的spark对应的名称。不同的spark版本有不同的sparkPi名称。名称一定要完全符合。
参考我的:

注意四:还是路径问题。一定要全英文路径。不论是spark还是hadoop(如果你安装了的话)等,为了确保不是路径问题引起的,所有环境路径均设为纯英文。
注意五:下文中的报错信息是循序渐进的,每次报错都会修改设置 甚至 是增加环境配置
报错1:
运行的命令
在spark-shell环境中执行:
不论是./spark-submit:
./spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.10.1.jar 10
![]()
还是直接spark-submit:
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.10.1.jar 10
![]()
都不能执行
错误原因
- 不能在spark-shell环境中运行,直接在terminal(linux)、cmd(win10)、powershell(win10)中执行即可
- jar包名称也有问题,对于
spark-3.1.1-bin-hadoop3.2来说,应该是spark-examples_2.12-3.1.1.jar
报错2:
运行的命令
在powershell中执行以下命令:
./spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.0.0.jar 10
报错信息
WARN Shell: Did not find winutils.exe: {}
java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset
Error: Failed to load class org.apache.spark.examples.SparkPi.
原因
jar包名称错误
改之
报错3
运行命令
./spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.1.1.jar 10
报错信息:
图片丢失了,不过你应该会找到,spark在提示你缺少hadoop环境等信息
原因
缺少hadoop环境
注:没错,就是这么神奇。明明下载的是带有hadoop的spark-3.1.1-bin-hadoop3.2,但就是告诉你缺少hadoop,windows用户没人权啊。同样的就是这个文件spark-3.1.1-bin-hadoop3.2,在没有单独安装hadoop环境中的centos 7中就能完美运行。
大家先不用再去下载一个不带有hadoop的spark,就现在的spark-3.1.1-bin-hadoop3.2即可,先看我下文
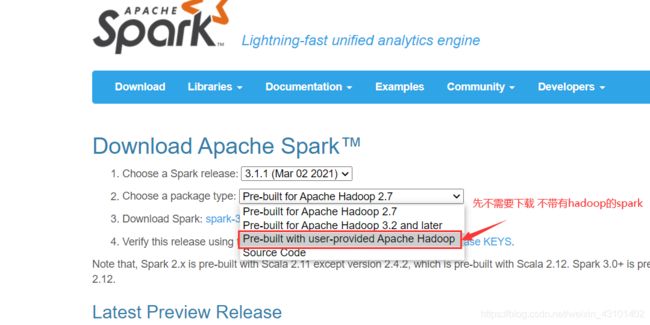
安装hadoop环境
下载
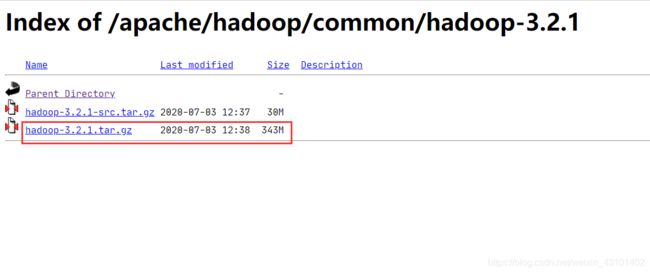
下载、解压缩hadoop,注意下载的版本要和自己的spark匹配,spark3.1.1需要hadoop3.2,所以我下载了hadoop3.2.1,为什么不是3.2.2呢?看我后文 报错4
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
解压缩
下载完成后,你若是直接解压hadoop-3.2.1.tar,可能会提示你缺少一些权限,有两、三个文件无法解压
所以你需要用管理员身份来解压
对于7zip来说,我没找到如何以管理员身份解压,所以我直接把7zip整个软件设为管理员身份启动

这样再次解压hadoop-3.2.1.tar即可
环境变量
其一:
HADOOP_HOME:你的解压目录(解压目录)
其二:
在path中添加:
PATH:你的解压目录\bin
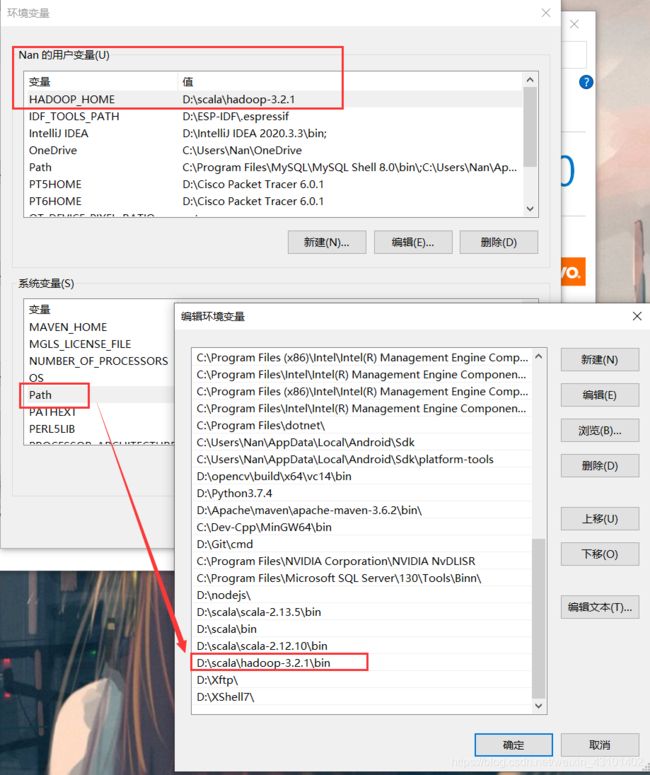
最好重启电脑,使得环境变量能生效
报错4:
运行的命令
运行以下命令:
./spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.1.1.jar 10
报错信息
21/04/15 10:48:19 WARN Shell: Did not find winutils.exe: {}
java.io.FileNotFoundException: Could not locate Hadoop executable: D:\scala\hadoop-3.2.2\bin\winutils.exe -see https://wiki.apache.org/hadoop/WindowsProblems
尽管是个warn,但就是它引起的
原因
hadoop中的bin目录里,缺少winutils.exe
下载链接https://github.com/cdarlint/winutils
在2021年4月25日及之前,是没有与3.2.2相匹配的版本的,这就是之前为什么要下载hadoop3.2.1的原因
选自己的对应的版本:

把这两个都下载下来:
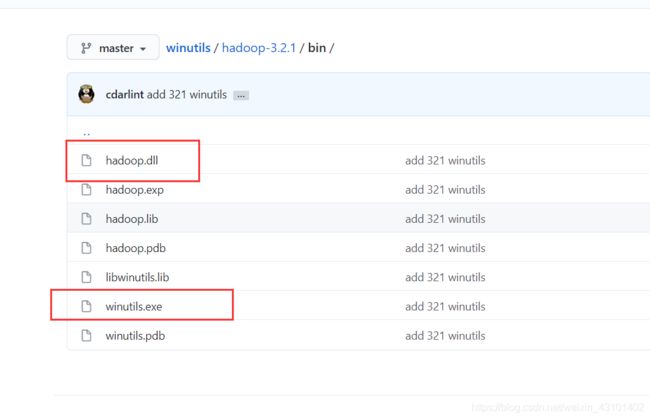
放在hadoop下的bin中:
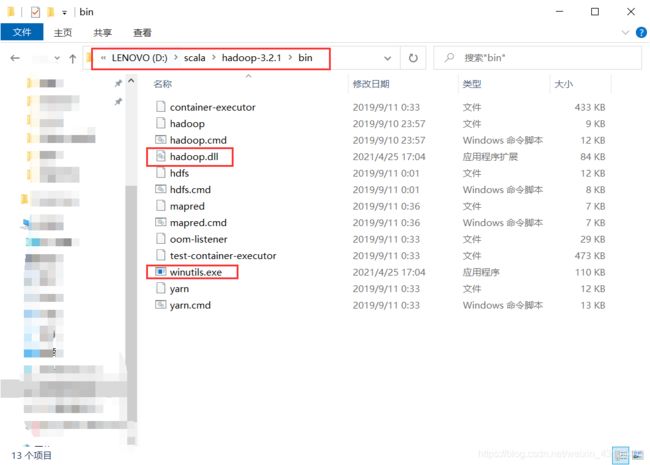
同时,把dll文件放在这里:
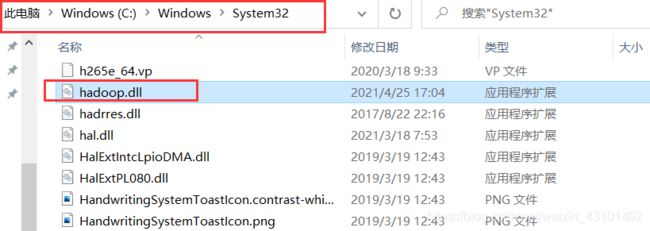
大功告成
在powershell中,再次执行:
./spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.1.1.jar 10

样例SparkPi输出结果在众多INFO中:
终于ok了
注:这个pi的值是通过样例算出来的,所以和标准Pi值有差异,而且你的运行结果可能也和我的不一样
我基本上把能踩的坑都踩了,仅供大家参考
要是对大家有用,就施舍个赞吧,我折腾了两天,太难了