简单速成Pytorch的scatter_函数理解
首先明确,这个函数实现的功能是”放“
怎么个放法呢,看这个函数的参数:
Tensor.scatter_(dim, index, src, reduce=None) → Tensor
- src:将src这个tensor中的值,放到self里(也就是”.“符号前面的那个Tensor)。src不一定要是一个tensor,也可以是一个值。
- dim及index:指示要放的具体位置。
self [index[i][j][k]] [j][k] = src[i][j][k] # if dim == 0
self[i] [index[i][j][k]] [k] = src[i][j][k] # if dim == 1
self[i][j] [index[i][j][k]] = src[i][j][k] # if dim == 2
- reduce则根据官方文档的陈述,这个放,可以是替换(None),或者是加、乘到原先的值上。
reduce (str, optional) – reduction operation to apply, can be either ‘add’ or ‘multiply’.
不好理解哈,首先举个理解性的例子(考虑到什么方法来自pytorch库,大家对以下代码应该非常熟悉)
#代码来源于znxlwm/pytorch-MNIST-CelebA-cGAN-cDCGAN
for x_,y_ in train_loader:
#首先训练D
D.zero_grad()
mini_batch = x_.size()[0] #当输入没有128时,确保后续可执行
y_real_ = torch.ones(mini_batch)
y_fake_ = torch.zeros(mini_batch)
y_label_ = torch.zeros(mini_batch,10) #维度
y_label_.scatter_(1,y_.view(mini_batch,1),1) #y_.view(batch_size,1)返回一个维度为(batch_size,1)但内容和y_一样的tensor
这是一个我今天学习的用c-GAN生成MNIST图片的例子,从数据加载器train_loader中,取出训练集合x_和标签集合y_。常规的梯度清零后,提取本次batch的大小(如果不加这一步,而是直接用之前设定的batch_size,就会出现后续维度不匹配的状况,因为可能有一个batch的大小是64维)。
y_label_ = torch.zeros(mini_batch,10) #维度
y_label_.scatter_(1,y_.view(mini_batch,1),1)
主要关心这两步,第一句初始化了一个全0的tensor,它的大小是(mini_batch,10),含义是batch中每个结果对应了一个one-hot向量。那么我们现在要从y_中获取它的标签,并把真实标签 放入 到这个全0的y_label_中。
也就是使用上面的y_label_.scatter_函数。
- 首先确定其参数dim,很明显,dim=1,因为第一个维度指示的是batch中的某一条数据,第二个维度才指示的是这个数据的label。
- 其次,确定其放入的值是什么,那么此处我们填入1即可,因为当one-hot向量为(0,0,1,0,0,0,0,0,0,0),说明这个数据的真实label为2。
- 最后,我们确定要填充的index,由于数据集中的y_已经有了相应的label,但是数据集中的y_的格式是否符合我们此处index参数的格式?可以看看y_的格式是什么。
↓
tensor([2, 2, 0, 0, 5, 3, 3, 3, 4, 0, 6, 1, 8, 7, 5, 5, 6, 7, 4, 0, 9, 6, 5, 0, 9, 5, 0, 6, 4, 8, 5, 0, 9, 8, 7, 7, 4, 3, 7, 2, 1, 4, 1, 4, 7, 7, 9, 2, 3, 3, 2, 1, 0, 7, 4, 0, 4, 1, 1, 8, 3, 4, 3, 8, 4, 6, 3, 1, 6, 9, 0, 3, 6, 3, 3, 0, 7, 0, 8, 0, 5, 6, 6, 4, 8, 0, 9, 7, 0, 3, 4, 3, 1, 6, 4, 2, 1, 2, 4, 1, 4, 2, 9, 1, 1, 4, 4, 0, 0, 8, 9, 6, 9, 8, 6, 6, 0, 3, 3, 7, 5, 4, 1, 4, 1, 2, 2, 8])
好,这就是y_的输出,每个位置上对应着其真实label
但是这是一个[128]的向量,因此我们用.view()方法,将其扩充至我们需要的维度,可以得到y_.view(mini_batch,1)为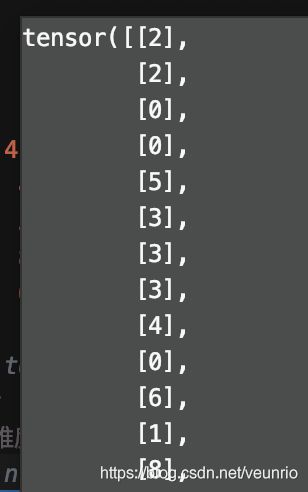
y_label_ = torch.zeros(mini_batch,10)
- 那么和上面这个y_label_的格式一对比,就很明显了,
我们对照官方文档给的公式,确定一下放入位置, 当dim=1时,放入位置为[0][2]、[1][2]、[2][0]…第0维依次递增,我们就获得了一个batch的one-hot标签tensor。
self [index[i][j]] [j]= src[i][j] # if dim == 0
self[i] [index[i][j]] = src[i][j] # if dim == 1
最后举一个数值上的例子
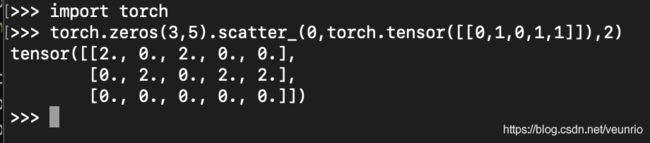 dim=0,因此我们在第0维上进行修改,
dim=0,因此我们在第0维上进行修改,
self [index[i][j]] [j] = src[i][j] # if dim == 0
index = [[0,1,0,1,1]],其shape是torch.Size([1,5])
因此其放入位置对应为
[0][0]
[1][1]
[0][2]
[1][3]
[1][4]
在实际使用的时候要注意维度的对应,例如如果用以下代码
torch.zeros(3,5).scatter_(0,torch.tensor([[1,1,1,1,1,1,1,1]]),1)
看看会出啥事。
就这样,今天成功躲过了leetcode每日一题。