ElasticSearch简介之倒排索引
说起 ElasticSearch,大家的第一反应就是这是一款主要用于搜索的高性能分布式引擎,我们可以使用这个有点重的家伙来完成一个检索功能。当然这是一个普遍的认知,我在这里重复描述也只是为我等小白扫个小盲,大佬可忽略这自嗨。 目前搜索市面上也不仅仅只有 ElasticSearch,抛开 ElasticSearch 这款引擎本身来想一下,我们理想中的搜索引擎是怎么样子的,想必有很多的点吧,也许每个人的见解不同,在这里我阐述一下本人有限脑容量下面的一个对于搜索的理解:
- 第一点搜索必须快吧,这肯定是必须的必呀,要是花了好几分钟才出来,这玩意谁愿意用啊,所以使用搜索引擎的第一个指标就是快速检索出结果。
- 第二点必须准确吧,假如我搜索关键词电脑,结果搜索出来的结果是一些奇奇怪怪的东西,要是在这时候投屏怕不是会陷入社死的尴尬吧。
- 第三点对于我这种比较粗心的人还是需要有一点的容忍度,哪怕输错其中一个字,也可以给出相关的搜索结果。
- 第四点对于大部分人而言,相信大多数人都会希望进行搜索的时候可以有相关的搜索选项提供选择,而不是都是需要自己相办法去思考所有的关键词,毕竟人都是喜欢偷懒的,从某种程度上而言,人们的偷懒促进了现代社会的发展。
说完这几点相信很多的搜索引擎都是奔着这几个目标去的,显而易见 ElasticSearch 满足了上面所有的搜索的基本要求,相信小白(包括我啦)到这里都很想去尝试一下,网上的安装教程和简单 HelloWorld 都是有的,可以自己使用单机版简单的玩耍一下,在这里就不一一赘述了。简单的 Demo 过后是不是很多人都好奇 ElasticSearch 搜索的具体实现方式是怎么实现的,是依靠什么满足上诉第一点的要求,那么开启接下来的里程吧。
倒排索引
抽象模型
众所周知的是 ElastichSearch 使用的是 Lucene 来作为底层的框架来进行一个数据的搜索, Lucene 则是一个高性能的全文检索引擎工具,很多的搜索引擎都是以 Lucene 为工具包,进行二次开发,那么究竟是什么使得 Lucene 这个工具,具有如此的魅力,提到这个就不得不说一下他的一个独特数据结构-倒排索引了。
接下来进入正式环节。在说倒排索引之前,先进行我们正常的思路是如何来对下列的数据进行一个检索的。

普通按照我们正常的思路来进行一个全文的检索,就是使用一个遍历的方式来进行一个关键字的获取,比如我们要检索关键字 keyworld1 时就需要把所有的数据进行检索一编,当然在数据量小的时候这并没有什么影响,反而因为简单处理会速度比较快,没有那么多的性能问题,但是当数据量以百万或者千万级别以上进行的时候就不行了,这个时候遍历一下的速度是我们难以忍受的,如果要花很多的时间好像就没有人愿意进行一个等待了。
为了解决这方面的问题就提出了倒排索引这个比较独特的数据结构,来解决相关的搜索性能问题:那么这种数据结构是怎么样的呢,首先我们给出一个抽象的示意图。
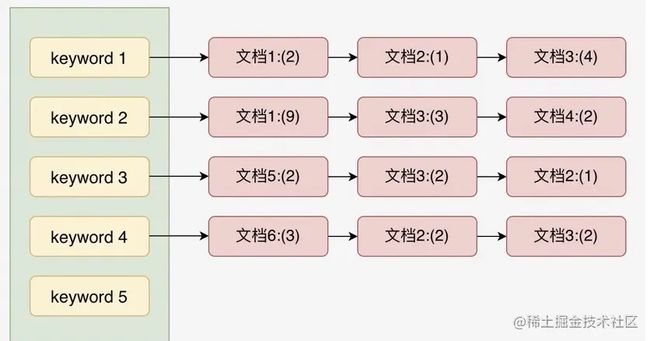
倒排索引对刚进来的文档进行一个索引的构建,把一份文档中所有出现过的关键字放入一个列表中,这个列表被称为单词辞典也就是对应上图的绿色部分,而相对应的文档则是如右侧的红色节点所示,当然,对应的文档不一定是按照列表显示的,也可以选择其他的数据结构比如 B+ 树之类的,当然文档 1 ,这个节点并不是说就存储了相对应的文档,而是存储了这个文档的唯一标志 id ,通过这个 id 可以快速的定位文档的位置。除此之外还要可能红色节点存储了相应的出现的频次,这为后续的给出的排序提供了依据括号表示相应的频次,当然节点里面的数据不一定只有这么一点,肯定还是有很多其他的统计。 那么肯定会有人问如果是模糊搜索是怎么排序,那么肯定是检索绿色的这排,给出相关的文档,排序什么的是按照自己定义的一些规则来进行匹配,后续文章会给出相关性的算法。
大致倒排索引的理论是这样子的,那么就给出相关的例子进行说明一下,以我们之前给出的 HelloWorld 版本进行说明 两个文档的 Json 如下
[
{
"id": "2",
"name": "second Helloworld 2",
"organizer": "wangwu",
"version": "1.0"
},
{
"id": "1",
"name": "ElasticSearch Helloworld",
"organizer": "qingtong",
"version": "1.0"
}
]
复制代码 ElasticSearch 会为了每一个字段建立一个倒排索引,那么我们以 name 这个字段的倒排索引为例:
| 关键词 | 文档 |
|---|---|
| second | (2:1) |
| Helloworld | (2:1),(1:1) |
| 2 | (2:1) |
| ElasticSearch | (1:1) |
进行搜索的时候就按照这个方式先选择搜索项对应的单词列表,在列表中查询相关的值,最后给出相关的文档中的一些内容。其中 2:1 表示文档 id 为 2 的文章该关键词出现一次。
具体实现
当然上述说的都是一个梗概的过程,具体的设计和实现方式肯定不能是这么做的,这也不满足实际的需要。在介绍实现前,先描述几个前置的几个概念。在 ElasticSearch 中并没有关键词这个描述,只是为了在更好的理解所提出的一个说法,对应在 ElasticSearch 中,关键词被称为 Term。所有 Term 的集合被称为 Term Dictionary , Postings list 作为文档的唯一标识的,即文档 id 列表。
按照刚刚的概念进行搜索,显然是需要对 Term 的集合( Term Dictionary )进行一个特定值的获取,可以把 Term Dictionary 作为一个有序数组进行二分查找或者按照 B+ 树搜索的方式进行一个查找,这个时候 Term Dictionary 是不是很像一个索引,可以根据他进行一个查找。
貌似刚刚说的很有道理,但是其实不然, Term Dictionary 想想就应该放在内存中吧,不然放在磁盘中,多次的 IO 就会让他的性能和速度开始无法忍受,但是放在内存中又会出现内存不够用的情况,毕竟 Term Dictionary 是所有单词的集合,这个数量是很大的,为此考虑一下,要不要为这个 Term Dictionary 再加上一个索引结构呢,来加快速度,而且通过一定的手段来降低 Term Dictionary 的空间,提高一个空间使用率,好的,这个时候 Term Index 出现了, Term Index 很显然是一个字典树,并不会包含所有的 Term 项,他会使用一些 Term 的前缀来进行一个索引,这样子就可以通过 Term 快速定位到 Term Dictionary 的某个起始位置,然后再进行快速的查找。上面过程引用网上的一张图片可以描述为

索引优化
Finite State Transducers
既然都使用了一个公共的前缀,那我们能不能利用这个公告的前缀的头来做一些事情呢?好像这个 Term 的数据可以进一步的优化来减少空间哎,反正前缀都在 Term Index 有存储了,这个时候就出现了两个优化的点,一个是按照公共的前缀来按照块来存放,另一个则是把公共部分提出来复用,这就是 Lucene 中用到的 FST 数据结构。
简单的用个列子来说明描述:假设 Term Dictionary 为["regular", "request", "rest", "teacher", "team", "teenage", "tend"],则相应 Index 和 Dictionary 的为

这样子就可以压缩一大部分的空间,可以有效的提高一个空间的利用率了。
Frame of Reference
讲完这个对于 Term Index 和 Term Dictionary 的压缩,考虑一下要不要对文档列表进行一个压缩啊,来提升一下性能 即 Posting list 压缩。毕竟大量的磁盘 IO 耗损的性能可不是开玩笑的,一开始也许有人会问反正存的都是文档 id, 这玩意真的有压缩的必要,即使想压缩又该如何去压缩呢?因为后续要进行查询的时候需要过滤和联合查询,所以这里简单介绍一下,这也是倒排索引中 Posting list 存放的一个方式。他有一种 Frame of Reference 的编码方式来进行一个压缩。
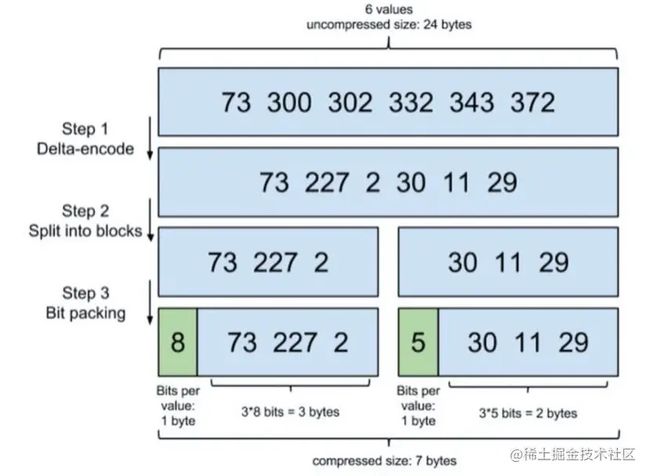
增量编码( Delta-Encode )这种方式进行压缩,所谓的增量编码原先是 [ 73 , 300 , 302 , 332 , 343 , 372 ],那么增量之后就是 [ 73 , 227 , 2 , 30 , 11 , 29 ] ,即后面一个数据对前面一个数据的增量也就是下图中的 step 1 Delta-Encode。
Step 2 就是划分 block 了,如何划分呢?它会把所有的文档分成很多个 block,每个 block 正好包含 256 个文档。下图来自于 ElastichSearch 官方博客中的一个示例(假设每个 block 只有 3 个文件而不是 256 )。
Step 3 计算出存储这个 block 里面所有文档最多需要多少位来保存每个 id,并且把这个位数作为头信息 header 放在每个 block 的前面。
这样可以极大的节省 Posting list 的空间消耗,提高查询性能。
本次因为时间有限就给出 ElasticSearch 学习过程中的一些初步想法,如有错漏之处还请各位大佬指正。