数据分析利器Python——Pandas(三、层级索引、分组聚合、透视表)
文章目录
-
- 一、层级索引
- 二、分组聚合
-
- 2.1、介绍
- 2.2、分组操作
- 2.3、自定义分组
- 2.4、自定义聚合
- 三、数据规整
-
- 3.1、透视表
- 3.2、数据合并concat
- 3.3、数据连接merge
- 3.4、数据重构stack,unstack
一、层级索引
它是一个MultiIndex对象
设置多个列索引:set_index([‘a’,‘b’],inplace=True),注意a,b顺序,若不同则有区别
选取子集:
- 外层选取:loc[‘outer_index’]
- 内层选取:loc[‘outer_index’,‘inner_index’]
交换层级顺序:swaplevel()
层级索引排序:sort_index(level=)
二、分组聚合
2.1、介绍
分组:对数据集进行分组 ,然后对每组进行统计分析
聚合:数组产生标量的过程,如mean(),count()等,常用于对分组后的数据进行计算。
分组运算过程:
- 拆分:进行分组的根据
- 应用:每个分组运行的计算规则
- 合并:把每个分组的计算结果合并起来

内置的聚合函数:sum()、mean()、max()、min()、count()
2.2、分组操作
(1) 按单列分组
obj.groupby(‘label’)
(2)多列分组
obj.groupby([‘label’,‘label2’])产生多层DataFrame
(1)groupby()操作后产生GroupBy对象,分为DataFrameGroupBy和SeriesGroupBy
(2)GroupBy对象没有进行实际运算,只是包含分组的中间数据,只有在经过聚合操作后才会产生结果,常用的聚合操作有mean(),max(),size()【每一个分组的大小】,count()
(3)非数值数据不进行分组运算
2.3、自定义分组
方法一:groupby()中传入自定义函数进行分组,操作针对的是索引
# 代码片段举例
def get_score_group(score):
if score<60:
score_group = 'low'
elif score<=80:
score_group='middle'
else:
score_group='high'
data2=data.set_index('Score') # 1、将Score列设置为索引列
data2.groupby(get_score_group).size() # 2、查看每个分组大小
方法二:项目中,可以先人为构造一个分组列,然后进行groupby
data['score_group']=data['Score'].apply(get_score_group)# 对Score列应用get_score_group函数
data.head() # 可以看到多了一列,名为score_group
data.groupby('score_group').size() # 使用groupby函数进行分类
2.4、自定义聚合
使用agg()函数
- 传入包含多个函数的列表,可以同时完成多个聚合操作
- 可通过字典为每个列指定不同的操作方法
- 传入自定义函数
以下两个语句等价
data.groupby('Region').max()
data.groupby('Region').agg(np.max)
(1)传入多个函数的列表
data.('Region')['HappinessScore'].agg([np.max,np.min,np.mean])
'''
运行结果的列名为Region np.max np.min np.mean
'''
(2)通过字典为每个列指定不同的操作方法
data.('Region').agg({'HappinessScore':np.mean,'HappinessRank':np.max})
'''
运行结果列名为Region HappinessRank HappinessScore
'''
(3)传入自定义函数
def max_min_diff(x):# 查看两极分化程度
return x.max()-x.min()
data.groupby('Region')['HappinessRank'].agg(max_min_diff)
三、数据规整
3.1、透视表
计算,汇总和分析数据的强大工具
创建包含名称,学期,成绩,课程四列的表格
df.pivot_table(values,index,columns,aggfunc,margins)
values:透视表中的元素值(根据聚合函数所得)
index:透视表的行索引
columns:透视表的列索引
aggfunc:聚合函数,可以指定多个函数
margins:表示是否对所有数据进行统计,默认为false
3.2、数据合并concat
按照指定轴的方向对多个数据对象进行数据合并
pd.concat(objs,axis)
axis为0则代表按照索引方向进行拼接(纵向),为1代表按照列方向(横向)
objs:多个数据对象,包含DataFrame的列表
注意:默认使用outer join合并
纵向合并:pd.concat([df1,df2],axis=0)
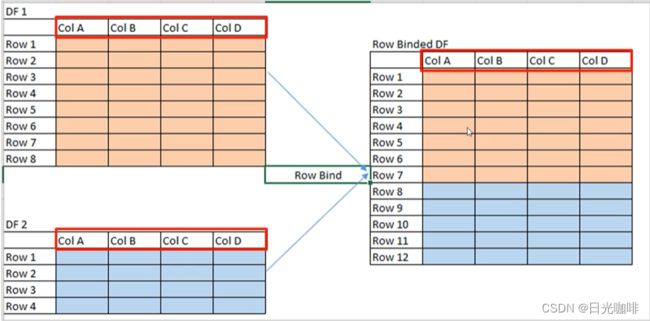
若列名相同,则正常合并,若列名不同,则进行列名的扩展,对应不上的位置为NaN
横向合并:axis=1
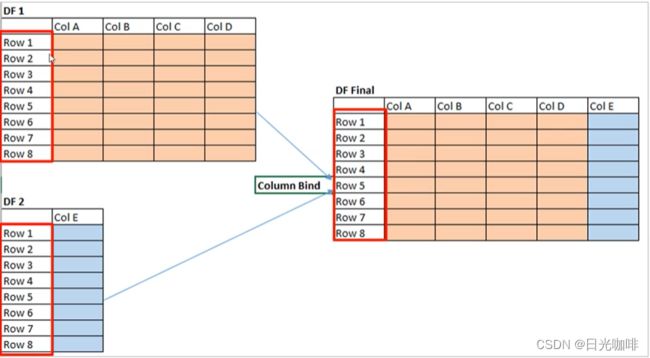
3.3、数据连接merge
merge()
- 根据单个或多个键将不同的DataFrame的行连接起来
- 默认将重叠列的列名作为“外键”进行连接
- 参数how指定连接方式:默认是inner join
outer外连接,结果中的键是并集,left左连接,right右连接 - suffixes,默认为重复列名_x,重复列名_y
- 若在连接时,两个表格没有相同列名,比如同一个人在A表里,它所在的列名是user_id,在B表里它所在的列名叫client_id,此时我们可以在merge函数里,指定left_on=“user_id”,right_on=“client_id”
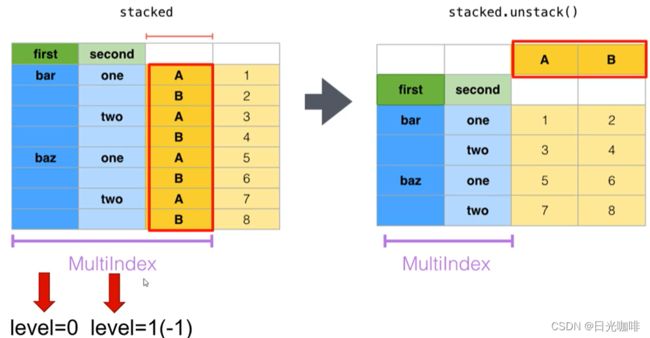
3.4、数据重构stack,unstack
适用于层级索引对象
stack()将数据的列旋转为行,如下图,其实和我们前面的透视表很像,只是这里的重构并没有对数据进行聚合操作
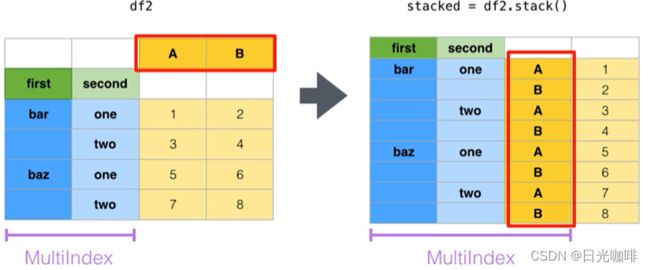
参数level:索引的层级,默认为-1,表示最里面的一层。如上图所示,从左往右是level0,level1…,那么从右往左的第一个就是-1
unstack():将数据的行旋转为列,level参数的规则和stack一样。