代码详解:在Pytorch和Python中实现神经风格迁移
全文共5146字,预计学习时长10分钟
风格迁移是计算机视觉的一个激动人心的子领域,目的是将一幅图像的风格迁移到另一幅图像上,称为内容图像。这项技术支持结合不同图像的内容和风格合成新图像。在这个子领域已经取得了一些进展,但最显著的初步工作(神经类型迁移)是Gatys等人在2015年完成的。以下是应用这种技术的效果图。

从左到右为:内容图像、风格图像、生成的图像
这个方法相当直观,本文是在pytorch和python中实现神经风格迁移的简单指南,并预先解释了这个方法。
Github完整代码:https://github.com/ksivaman/Transfer-image-styling

理解风格和内容
神经风格迁移涉及到将一个图像的风格迁移到另一个图像的内容上。它们分别是什么?
内容就是图像的组成部分。可能是风景、海滩环境、花园里的猫、动物园里的长颈鹿等等……在典型的图像分类网络中,基本上是图像的标签。内容是图像组成的高级表征。
图像风格涉及更复杂的细节:笔触、颜色对比、整体纹理等等……
假设图像的内容是一只狗,不同人画这个“内容”的方式不一样,也就是说狗的模样会不尽相同。这种差异形成了图像风格。你的笔画可能会更粗更有活力,而我的笔画可能会更细更钝。
这些定义有助于理解目的,但实际上,实现该算法需要更精确的定义。可以使用下面概述的标准图像分类网络获得这些定量定义。
卷积神经网络(CNN)是图像分类的常用方法。为了进行分类,CNN将图像作为输入,并应用一组卷积滤波器、最大池化和非线性激活来给出更密集的输入图像表示。
更全面的CNNs指南:https://towardsdatascience.com/convolutional-neural-networks-from-the-ground-up-c67bb41454e1
卷积网络丢失了大量的输入图像信息(尤其是池化层)。丢失的信息主要与图像风格有关,因为在处理图像分类任务时,风格是无用的信息。默认情况下,分类渠道(CNNs)非常擅长表示图像的内容。密集的输出表示是特征映射的术语,从CNNs中获得的完全连接的层保留了输入图像的大部分内容,但丢失了许多风格。这是因为CNNs的任务是对自然与图像内容有关的图像进行分类,而不是对图像风格进行分类。因此,图像内容可以直接定义为任何经过预处理的图像分类网络得到的最后一个卷积特征图的输出。
本文中将使用最初的预训练过VGG19网络。因此,图像内容表征将是VGG19网络中最后一个卷积层(block 5, layer 4)的输出。目标图像——即最终想要实现的图像,将从内容图像开始,迭代地进行修改以将我们的风格图像中的风格合并到目标图像上。但是,在继续进行修改时,会保留图像的内容表征。我们会通过将一个损失函数最小化来实现这些,该函数表示两个图像的内容损失、内容图像和目标图像。这种内容损失可以简单地理解为两个图像内容表示的均方误差(MSE)损失(VGG19特征映射上文提到的输出)。
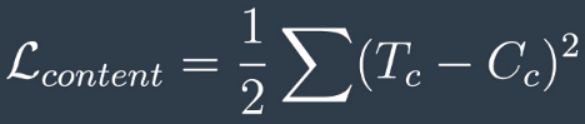
在内容损失方面, T_subC是目标图像内容特征图, C_subC是内容图像内容特征图,L_sub(content)表示两者的MSE。该术语除以2只是为了得到较低的数值。
图像风格在定量表征上稍微复杂一些,因为网络本身并不保存这种风格信息。但是,正如对内容图像所做的那样,将提出一个风格表征,并在迭代迁移期间最小化风格图像和目标图像之间的风格损失。
通过使用不同向量(该向量是卷积特征映射的一部分)的输出的相关性风格来获取风格表征。此处是指对于不同的风格,不同图层的不同特征映射的特征向量会以不同的方式关联。这种相关性将代表图像风格,即不同的笔触、调色板和纹理。从数学角度,通过将特征图与自身的转置相乘得到特定特征图的这种相关性。这是直观的理解,因为这个乘法将给出原始特征映射输出中的每个向量集之间的相关值。得到的结果矩阵称为gram矩阵。综合考虑VGG19中5个卷积层的所有gram矩阵,得到图像的整体风格。风格损失与内容损失类似,被定义为目标图像的gram矩阵和对应的风格图像的gram矩阵的MSE。但是,这一次有5个特征映射,即5个gram矩阵,即5个风格损失而不是1个(内容)。因此,整体风格损失被看作是内容损失的线性组合。
生成这些用于风格比较的gram矩阵的主要目的是比较具有不同内容的不同特征映射之间的关系,以查看特征映射的风格是否相似。
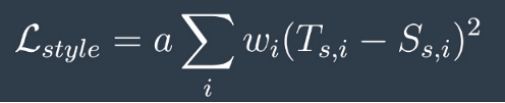
风格损失,w_-sub i对应于5克矩阵损失中每个权重,t_-sub(s,i)代表目标图像风格特征映射,s_-sub(s,i)代表风格图像风格特征映射,a是指定风格和内容损失的相对重要性的权重超参数,L_Sub(Style)是整体加权MSE。
我们现在所拥有的总损失等于风格损失加上内容损失。利用这个损失作为目标函数,可以开始优化目标图像(初始化为内容图像)使用标准的反向传播和梯度下降。这就是神经风格迁移所需要的一切!

实现方案
第一步:涵盖所有必要的库
from PIL import Image from io import BytesIO import matplotlib import matplotlib.pyplot as plt import numpy as np import time import torch import torch.optim as optim import requests from torchvision import transforms, models
第二步:因为将不会对网络进行训练,在Pytorch中初始化预训练的VGG19模型并冻结所有模型参数,如果NVIDIA GPUs可用,移动模型到cuda。
vgg = models.vgg19(pretrained=True).features
# freeze VGG params to avoid chanhe
for param in vgg.parameters():
param.requires_grad_(False)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
vgg.to(device)
第三步:定义一个函数以从VGG19网络中提取特征。图层字典中的图层名称是PyTorch预培训的VGG19模型中的预定义名称。
def get_features(image, model, layers=None):
""" Run an image forward through a model and get the features for
a set of layers. Default layers are for VGGNet matching Gatys
et al (2016)
"""
## Need the layers for the content and style representations of an
image
if layers is None:
layers = {'0': 'conv1_1',
'5': 'conv2_1',
'10': 'conv3_1',
'19': 'conv4_1',
'21': 'conv4_2', ## content representation
'28': 'conv5_1'}
features = {}
x = image
# model._modules is a dictionary holding each module in the model
for name, layer in model._modules.items():
x = layer(x)
if name in layers:
features[layers[name]] = x
return features
第四步:给定特征映射作为张量,定义一个函数来计算gram矩阵。
def gram_matrix(tensor):
# get the batch_size, depth, height, and width of the Tensor
_, d, h, w = tensor.size()
# reshape so we're multiplying the features for each channel
tensor = tensor.view(d, h * w)
# calculate the gram matrix
gram = torch.mm(tensor, tensor.t())
return gram
第五步:获取风格和内容图像的特征,获取风格损失的gram矩阵,将目标图像初始化为风格图像,从5 个gram矩阵的MSE中为损失的线性组合设置风格权重,为两个损失的相对重要性设置内容权重和风格权重(上面的风格损失图像中为“a”),选择用于反向传播的优化器,并设置迭代和修改目标图像的步骤数。
# get content and style features only once before training
content_features = get_features(content, vgg)
style_features = get_features(style, vgg)
# calculate the gram matrices for each layer of our style
representation
style_grams = {layer: gram_matrix(style_features[layer]) for layer in
style_features}
#initialize the target image as the content image
target = content.clone().requires_grad_(True).to(device)
style_weights = {'conv1_1': 1.,
'conv2_1': 0.75,
'conv3_1': 0.2,
'conv4_1': 0.2,
'conv5_1': 0.2}
content_weight = 1
style_weight = 1e6
# iteration hyperparameters
optimizer = optim.Adam([target], lr=0.003)
steps = 2000 # decide how many iterations to update your image (5000)
第六步:在保持最小损失的同时,迭代修改目标图像。减少“操作步骤”的次数。
for ii in range(1, steps+1):
# get the features from your target image
target_features = get_features(target, vgg)
# the content loss
content_loss = torch.mean((target_features['conv4_2'] -
content_features['conv4_2'])**2)
# the style loss
# initialize the style loss to 0
style_loss = 0
# then add to it for each layer's gram matrix loss
for layer in style_weights:
# get the "target" style representation for the layer
target_feature = target_features[layer]
target_gram = gram_matrix(target_feature)
_, d, h, w = target_feature.shape
# get the "style" style representation
style_gram = style_grams[layer]
# the style loss for one layer, weighted appropriately
layer_style_loss = style_weights[layer] *
torch.mean((target_gram - style_gram)**2)
# add to the style loss
style_loss += layer_style_loss / (d * h * w)
# calculate the *total* loss
total_loss = content_weight * content_loss + style_weight *
style_loss
# update your target image
optimizer.zero_grad()
total_loss.backward()
optimizer.step()

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”

(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)