NLP词性分析,实体分析,句法树构造(依存句法树分析)
NLTK
使用nltk库进行英文文本处理
英文文本分词处理(NLTK)
分词、取出标点符号
由于英语的句子基本上就是由标点符号、空格和词构成,那么只要根据空格和标点符号将词语分割成数组即可,所以相对来说简单很多。
使用nltk中的方法:
word_tokenize 分割单词
sent_tokenize 分割句子
注意: NLTK分词或者分句以后,都会自动形成列表的形式
词性标注
说明: 列表中每个元组第二个元素显示为该词的词性,具体每个词性注释可运行代码”nltk.help.upenn_tagset()“或参看说明文档:NLTK词性标注说明
line是一句完整的话,实际上pos_tag是处理一个词序列,会根据句子来动态判断
import nltk
from nltk.corpus import stopwords
line = 'I love this world which was beloved by all the people here. I have lived here for 20 years'
#分词
words = nltk.word_tokenize(line)
print(words)
#分句
sentences = nltk.sent_tokenize(line)
print(sentences)
#去除标点符号
interpunctuations = [',', '.', ':', ';', '?', '(', ')', '[', ']', '&', '!', '*', '@', '#', '$', '%'] #定义标点符号列表
cutwords = [word for word in words if word not in interpunctuations] #去除标点符号
print(cutwords)
#去除停用词
stops = set(stopwords.words("english"))
cutwords_stop = [word for word in cutwords if word not in stops]
print(cutwords_stop)
#词性标注
pos_tag = nltk.pos_tag(cutwords_stop)
print(pos_tag)
#命名实体识别
ners = nltk.ne_chunk(pos_tag)
print(ners)
#词干提取
#词性还原词性标注表:Penn Treebank P.O.S. Tags (upenn.edu) 宾夕法尼亚大学的词性标注表
import nltk
line = 'i love this world which was beloved by all the people here'
tokens = nltk.word_tokenize(line)
print(tokens)
pos_tag = nltk.pos_tag(tokens)
print(pos_tag)CC 并列连词 NNS 名词复数 UH 感叹词
CD 基数词 NNP 专有名词 VB 动词原型
DT 限定符 NNP 专有名词复数 VBD 动词过去式
EX 存在词 PDT 前置限定词 VBG 动名词或现在分词
FW 外来词 POS 所有格结尾 VBN 动词过去分词
IN 介词或从属连词 PRP 人称代词 VBP 非第三人称单数的现在时
JJ 形容词 PRP$ 所有格代词 VBZ 第三人称单数的现在时
JJR 比较级的形容词 RB 副词 WDT 以wh开头的限定词
JJS 最高级的形容词 RBR 副词比较级 WP 以wh开头的代词
LS 列表项标记 RBS 副词最高级 WP$ 以wh开头的所有格代词
MD 情态动词 RP 小品词 WRB 以wh开头的副词
NN 名词单数 SYM 符号 TO toSpaCy
使用SpaCy库进行英文文本处理, 不仅包含一些基本的文本处理操作、还包含一些预训练的模型以及词向量, 这些基本处理操作可以对我们的数据进行一些预处理,作为神经网络的输入。
SpaCy具有快速的句法分析器,用于标签的卷积神经网络模型,解析和命名实体识别以及与深度学习整合。
#! pip install spacy
import spacy
#! python -m spacy download en_core_web_sm
text = "Life on Earth depends on water."
nlp = spacy.load('en_core_web_sm')
doc = nlp(text)
token = [token.text for token in doc]
#每个token对象有着非常丰富的属性
for token in doc:
print("{0}\t{1}\t{2}\t{3}\t{4}\t{5}\t{6}\t".format(
token.text, #单词
token.idx, #单词起始索引
token.is_punct, #是否为标点
token.lemma_, #单词词干
token.is_space, #是否为空格
token.pos_, #词性标注
token.tag_
))ADJ:形容词,例如大,旧,绿色,难以理解的第一
ADP:位置,例如在,到,在
ADV:副词,例如非常,明天,下来,在那里,那里
AUX:辅助,例如是,已经(完成),将会(要做),应该(要做)
CONJ:连词,例如和,或,但是
CCONJ:协调连词,例如和,或,但是
DET:确定器,例如一个,一个
INTJ:感叹词,例如psst,ouch,bravo,你好
NOUN:名词,例如女孩,猫,树,空气,美女
NUM:数字,例如1,2017,一,七十七,IV,MMXIV
PART:粒子,例如不是
PRON:代词,例如我,你,他,她,我自己,自己,某人
PROPN:专有名词,例如玛丽,约翰,伦敦,北约,HBO
PUNCT:标点符号,例如。,(,),?
SCONJ:从属连词,例如如果,那,那
SYM:符号,例如$,%,§,?,+,?,×,÷,=,:),??
VERB:动词,例如奔跑,奔跑,奔跑,吃,吃,吃
X:其他,例如sfpksdpsxmsa
SPACE:空格,例如nsubj : nominal subject,名词主语
nsubjpass: passive nominal subject,被动的名词主语
dobj : direct object直接宾语
pobj : object of a preposition,介词的宾语Stanford CoreNLP 50来种依存关系(Stanford typed dependencies) - 简书 (jianshu.com)
依存句法树
英文依存句法树
依存句法树并不关注如何生成句子这种宏大的命题。依存句法树关注的是句子中词语之间的语法联系,并且将其约束为树形结构。
依存句法理论
依存语法理论认为词与词之间存在主从关系,这是一种二元不等价的关系。在句子中,如果一个词修饰另一个词,则称修饰词为从属词(dependent),被修饰的词语称为支配词(head),两者之间的语法关系称为依存关系(dependency relation)。

箭头方向由支配词指向从属词(可视化时的习惯)。将一个句子中所有词语依存关系以有向边的形式表示出来,就会得到一棵树,称为依存句法树(dependency parse tree)。例如句子“Wall Street Journal just published an interesting piece on crypto currencies”的依存句法树如图所示。
SpaCy解析依存关系
在Jupyter Notebook中使用spaCy可视化中英文依存句法分析结果 - 知乎 (zhihu.com)
SpaCy能够快速准确地解析句子的依存关系, SpaCy使用head和child来描述依存关系中的连接,识别每个token的依存关系:
- token.text: token的文本
- token.head: 当前token的Parent Token, 从语法关系上来看,每一个Token都只有一个Head
- token.dep_: 依存关系
- token.children: 语法上的直接子节点
- token.ancestors: 语法上的父节点
- _pos: 词性
- _tag: 词性
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp("spaCy uses the terms head and child to describe the words")
for token in doc:
print('{0}({1}) <-- {2} -- {3}({4})'.format(token.text, token.tag_, token.dep_, token.head.text, token.head.tag_))
#依存句法树打印输出
from spacy import displacy
displacy.serve(doc, style='dep')spaCy(NFP) <-- nsubj -- uses(VBZ)
uses(VBZ) <-- ROOT -- uses(VBZ)
the(DT) <-- det -- terms(NNS)
terms(NNS) <-- dobj -- uses(VBZ)
head(VBP) <-- dobj -- uses(VBZ)
and(CC) <-- cc -- head(VBP)
child(NN) <-- conj -- head(VBP)
to(TO) <-- aux -- describe(VB)
describe(VB) <-- xcomp -- uses(VBZ)
the(DT) <-- det -- words(NNS)
words(NNS) <-- dobj -- describe(VB)
先列举一些重要的关系标签:
- root:中心词
- nsubj:名词性主语
- nsubjpass:被动名词性主语
- csubj:名词性主语从句(谓语动词 --> 主语从句主要成分)
- csubjpass:主语从句被动关系(谓语动词(被动)--> 主语从句主要成分)
- dobj:直接宾语(动词 --> 直接宾语)
- pobj:介词的宾语(介词 --> 宾语)
- iobj:间接宾语(动词 --> 间接宾语)
- prep:介词修饰(名词 --> 介词)
- prepc:介词从句修饰
- prob:介词宾语(介词 --> 宾语)
- mark:标记语(从句的主要成分 --> 从句修饰的主体)eq:He says that you like to swim(like --> that)
- aux:助动词(动词 --> 助动词)
- auxpass:过去式助动词(动词 --> 过去式助动词)
- xcomp:开放从句补语(开放从句的补足对象(动词)-->开放从句的动词)eq:Tom likes to eat fish(like --> eat)
- ccomp:被补充说明词-->补语从句主要成分 eq:He says that you like to swim(say --> like)
- acomp:用于动词的形容词补语(动词 --> 形容词)eq:She looks very beautiful.(look -> beautiful)
- pcomp:介词的补语(介词 --> 从句的主要成分)eq:We have no information on whether users are at risk(on --> are)
- cc:连词(第一个并列词 --> 协同关系词)eq:Bill is big and honest(big --> and)
- conj:协同连词(第一个并列词 --> 第二个并列词)eq:Bill is big and honest(big --> honest)
- preconj:(名词短语的前部 --> 连词前面出现的词)eq:Both the boys and the girls are here(boy --> both)
- predet:名词短语的前部-->在限定词前面出现的词 eq: All the boys are here(boys -> all)
- det:限定词(名词短语 --> 限定词)eq:The man is here(man --> the)
- amod:修饰名词短语的形容词修饰语(名词短语 --> 形容词修饰语)eq:Sam eats red meat(meat --> red)
- advmod:副词修饰语(被修饰者 --> 副词)eq:Genetically modified food(modified --> genetically)
- npadvmod:名词短语作为副词修饰(副词修饰的词 --> 名词)eq:The director is 65 years old(old --> years)
- nummod:数词作为修饰(名词 --> 数词)eq:About 200 people came to the party(people --> 200)
- relcl:关系从句修饰(名词短语第一个词 --> 关系动词主要词)eq:I saw the man you love(man --> love)
- poss:所属修饰(拥有者 --> 拥有物品)eq:their offices(their --> offices)
- compound:名词合成修饰(后一个名词 --> 前一个名词) eq:Oil price futures(future -> price)
- parataxis:并列(主要动词 --> 并列句的主要成分)eq:The guy, John said, left early in the morning (left --> said)
- neg:否定词
- punct:标点
- dep:系统无法识别的依赖关系
- discourse:句子的主要部分 --> 语气词、感叹词
StanfordNLP解析依存关系
StanfordNLP是一个斯坦福官方提供的python版本的NLP工具包。这些模块构建在Pytorch之上。如果在支持GPU的计算机上运行此系统,将获得更快的性能。
除了官方提供的python版本外,还有许多其他python版本,例如stanfordcorenlp
import stanfordnlp
stanfordnlp.download('en')
nlp = stanfordnlp.Pipeline()
doc = nlp("He was elected president in 2008.")
doc.sentences[0].print_dependencies()('He', '3', 'nsubj:pass')
('was', '3', 'aux:pass')
('elected', '0', 'root')
('president', '3', 'xcomp')
('in', '6', 'case')
('2008', '3', 'obl')
('.', '3', 'punct')中文依存句法树
Spacy解析依存句法树
import spacy
nlp = spacy.load('zh_core_web_sm')
doc = nlp("小猴子吃了5根香蕉")
for token in doc:
print('{0}({1}) <-- {2} -- {3}({4})'.format(token.text, token.tag_, token.dep_, token.head.text, token.head.tag_))
doc = nlp("依存句法分析作为底层技术,可直接用于提升其他NLP任务的效果。这些任务包括但不限于语义角色标注、语义匹配、事件抽取等。")
sentence_spans = list(doc.sents)
print(len(sentence_spans))
for sentence in sentence_spans:
print(sentence)
for token in doc:
print('{0}({1}) <-- {2} -- {3}({4})'.format(token.text, token.tag_, token.dep_, token.head.text, token.head.tag_))小(JJ) <-- amod -- 猴子(NN)
猴子(NN) <-- nsubj -- 吃(VV)
吃(VV) <-- ROOT -- 吃(VV)
了(AS) <-- aux:asp -- 吃(VV)
5(CD) <-- nummod -- 香蕉(NN)
根(M) <-- mark:clf -- 5(CD)
香蕉(NN) <-- dobj -- 吃(VV)
依存句法分析作为底层技术,可直接用于提升其他NLP任务的效果。
这些任务包括但不限于语义角色标注、语义匹配、事件抽取等。
依存(JJ) <-- amod -- 句法(NN)
句法(NN) <-- nsubj -- 分析(VV)
分析(VV) <-- ROOT -- 分析(VV)
作为(VV) <-- ccomp -- 分析(VV)
底层(NN) <-- compound:nn -- 技术(NN)
技术(NN) <-- dobj -- 作为(VV)
,(PU) <-- punct -- 用于(VV)
可(VV) <-- aux:modal -- 用于(VV)
直接(AD) <-- advmod -- 用于(VV)
用于(VV) <-- conj -- 分析(VV)
提升(VV) <-- ccomp -- 用于(VV)
其他(DT) <-- det -- 任务(NN)
N(NN) <-- compound:nn -- 任务(NN)
L(NN) <-- compound:nn -- 任务(NN)
P(NN) <-- compound:nn -- 任务(NN)
任务(NN) <-- dobj -- 提升(VV)
的(DEC) <-- case -- 任务(NN)
效果(NN) <-- dobj -- 提升(VV)
。(PU) <-- punct -- 分析(VV)
这些(DT) <-- det -- 任务(NN)
任务(NN) <-- nsubj -- 包括(VV)
包括(VV) <-- ROOT -- 包括(VV)
但(AD) <-- advmod -- 限于(VV)
不(AD) <-- neg -- 限于(VV)
限于(VV) <-- ccomp -- 包括(VV)
语义(NN) <-- compound:nn -- 角色(NN)
角色(NN) <-- nsubj -- 标注(VV)
标注(VV) <-- conj -- 抽取(VV)
、(PU) <-- punct -- 抽取(VV)
语义(NN) <-- compound:nn -- 抽取(VV)
匹配(NN) <-- conj -- 抽取(VV)
、(PU) <-- punct -- 抽取(VV)
事件(NN) <-- compound:nn -- 抽取(VV)
抽取(VV) <-- ccomp -- 限于(VV)
等(ETC) <-- etc -- 抽取(VV)
。(PU) <-- punct -- 包括(VV)DDParser解析依存句法树
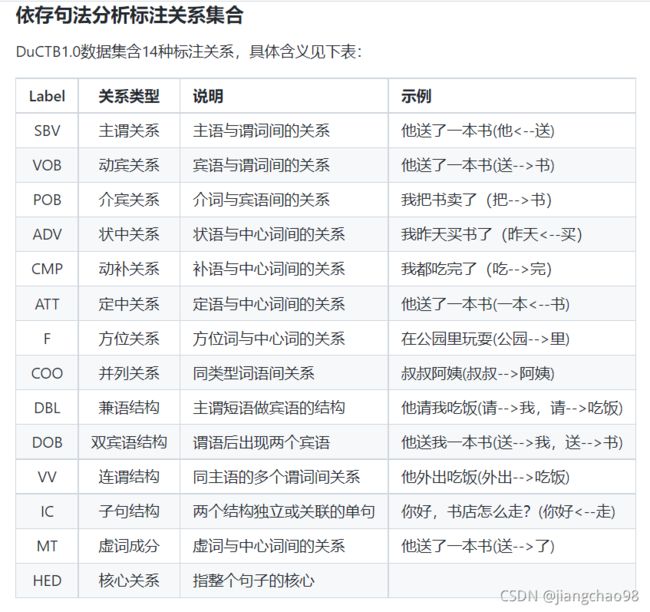
百度中文依存句法分析工具DDParser:baidu/DDParser: 百度开源的依存句法分析系统 (github.com)
百度中文依存句法分析工具DDParser
百度DDParser的依存分析
#未分词方式
from ddparser import DDParser
ddp = DDParser()
#单条句子
ddp.parse("百度是一家高科技公司") #输出
#多条句子
ddp.parse(["百度是一家高科技公司", "他送了一本书"]) #输出
#输出概率和词性标签
ddp = DDParser(prob=True, use_pos=True)
ddp.parse("百度是一家高科技公司") #输出
#buckets=True, 数据集长度不均时处理速度更快
ddp = DDParser(buckets = True)
#使用GPU
ddp = DDParser(use_cuda = True)
#已分词方式
from ddparser import DDParser
ddp = DDParser()
#单条句子
ddp.parse_seg([['他', '送', '了', '一本', '书']])
#输出概率
ddp = DDParser(prob=True)
ddp.parse_seg([['他', '送', '了', '一本', '书']])[{'word': ['百度', '是', '一家', '高科技', '公司'], 'head': [2, 0, 5, 5, 2], 'deprel': ['SBV', 'HED', 'ATT', 'ATT', 'VOB']}]
[{'word': ['百度', '是', '一家', '高科技', '公司'], 'head': [2, 0, 5, 5, 2], 'deprel': ['SBV', 'HED', 'ATT', 'ATT', 'VOB']}, {'word': [' 他', '送', '了', '一本', '书'], 'head': [2, 0, 2, 5, 2], 'deprel': ['SBV', 'HED', 'MT', 'ATT', 'VOB']}]
[{'word': ['百度', '是', '一家', '高科技', '公司'], 'postag': ['ORG', 'v', 'm', 'n', 'n'], 'head': [2, 0, 5, 5, 2], 'deprel': ['SBV', 'HED', 'ATT', 'ATT', 'VOB'], 'prob': [1.0, 1.0, 1.0, 1.0, 1.0]}]
[{'word': ['他', '送', '了', '一本', '书'], 'head': [2, 0, 2, 5, 2], 'deprel': ['SBV', 'HED', 'MT', 'ATT', 'VOB']}]
[{'word': ['他', '送', '了', '一本', '书'], 'head': [2, 0, 2, 5, 2], 'deprel': ['SBV', 'HED', 'MT', 'ATT', 'VOB'], 'prob': [1.0, 1.0, 1.0, 1.0, 1.0]}]| n | 普通名词 | m | 数量词 |
| f | 方位名词 | q | 量词 |
| s | 所处名词 | r | 代词 |
| nz | 其他专名 | p | 介词 |
| nw | 作品名 | c | 连词 |
| v | 普通动词 | u | 助词 |
| vd | 动副词 | xc | 其他虚词 |
| vn | 名动词 | w | 标点符号 |
| a | 形容词 | PER | 人名 |
| ad | 副形词 | LOC | 地名 |
| an | 名形词 | ORG | 机构名 |
| d | 副词 | TIME | 时间 |