动手学深度学习Pytorch Task07
本节课内容目标检测基础、图像风格迁移、图像分类案例1
一、目标检测基础
锚框
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。我们将在后面基于锚框实践目标检测。
import numpy as np
import math
import torch
import os
IMAGE_DIR = '/home/kesci/input/img2083/img/'
print(torch.__version__)
生成多个锚框

def MultiBoxPrior(feature_map, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5]):
"""
# 按照「9.4.1. 生成多个锚框」所讲的实现, anchor表示成(xmin, ymin, xmax, ymax).
https://zh.d2l.ai/chapter_computer-vision/anchor.html
Args:
feature_map: torch tensor, Shape: [N, C, H, W].
sizes: List of sizes (0~1) of generated MultiBoxPriores.
ratios: List of aspect ratios (non-negative) of generated MultiBoxPriores.
Returns:
anchors of shape (1, num_anchors, 4). 由于batch里每个都一样, 所以第一维为1
"""
pairs = [] # pair of (size, sqrt(ration))
# 生成n + m -1个框
for r in ratios:
pairs.append([sizes[0], math.sqrt(r)])
for s in sizes[1:]:
pairs.append([s, math.sqrt(ratios[0])])
pairs = np.array(pairs)
# 生成相对于坐标中心点的框(x,y,x,y)
ss1 = pairs[:, 0] * pairs[:, 1] # size * sqrt(ration)
ss2 = pairs[:, 0] / pairs[:, 1] # size / sqrt(ration)
base_anchors = np.stack([-ss1, -ss2, ss1, ss2], axis=1) / 2
#将坐标点和anchor组合起来生成hw(n+m-1)个框输出
h, w = feature_map.shape[-2:]
shifts_x = np.arange(0, w) / w
shifts_y = np.arange(0, h) / h
shift_x, shift_y = np.meshgrid(shifts_x, shifts_y)
shift_x = shift_x.reshape(-1)
shift_y = shift_y.reshape(-1)
shifts = np.stack((shift_x, shift_y, shift_x, shift_y), axis=1)
anchors = shifts.reshape((-1, 1, 4)) + base_anchors.reshape((1, -1, 4))
return torch.tensor(anchors, dtype=torch.float32).view(1, -1, 4)
我们看到,返回锚框变量y的形状为(1,锚框个数,4)。将锚框变量y的形状变为(图像高,图像宽,以相同像素为中心的锚框个数,4)后,我们就可以通过指定像素位置来获取所有以该像素为中心的锚框了。下面的例子里我们访问以(250,250)为中心的第一个锚框。它有4个元素,分别是锚框左上角的x和y轴坐标和右下角的x和y轴坐标,其中x和y轴的坐标值分别已除以图像的宽和高,因此值域均为0和1之间。
def show_bboxes(axes, bboxes, labels=None, colors=None):
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = d2l.bbox_to_rect(bbox.detach().cpu().numpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'k' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i],
va='center', ha='center', fontsize=6, color=text_color,
bbox=dict(facecolor=color, lw=0))
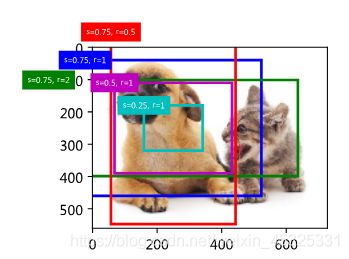
# 展示 250 250像素点的anchor
d2l.set_figsize()
fig = d2l.plt.imshow(img)
bbox_scale = torch.tensor([[w, h, w, h]], dtype=torch.float32)
show_bboxes(fig.axes, boxes[250, 250, :, :] * bbox_scale,
['s=0.75, r=1', 's=0.75, r=2', 's=0.75, r=0.5', 's=0.5, r=1', 's=0.25, r=1'])
交并比
我们刚刚提到某个锚框较好地覆盖了图像中的狗。如果该目标的真实边界框已知,这里的“较好”该如何量化呢?一种直观的方法是衡量锚框和真实边界框之间的相似度。我们知道,Jaccard系数(Jaccard index)可以衡量两个集合的相似度。给定集合A和B ,它们的Jaccard系数即二者交集大小除以二者并集大小:
![]()
实际上,我们可以把边界框内的像素区域看成是像素的集合。如此一来,我们可以用两个边界框的像素集合的Jaccard系数衡量这两个边界框的相似度。当衡量两个边界框的相似度时,我们通常将Jaccard系数称为交并比(Intersection over Union,IoU),即两个边界框相交面积与相并面积之比,如下图所示。交并比的取值范围在0和1之间:0表示两个边界框无重合像素,1表示两个边界框相等。

# 以下函数已保存在d2lzh_pytorch包中方便以后使用
def compute_intersection(set_1, set_2):
"""
计算anchor之间的交集
Args:
set_1: a tensor of dimensions (n1, 4), anchor表示成(xmin, ymin, xmax, ymax)
set_2: a tensor of dimensions (n2, 4), anchor表示成(xmin, ymin, xmax, ymax)
Returns:
intersection of each of the boxes in set 1 with respect to each of the boxes in set 2, shape: (n1, n2)
"""
# PyTorch auto-broadcasts singleton dimensions
lower_bounds = torch.max(set_1[:, :2].unsqueeze(1), set_2[:, :2].unsqueeze(0)) # (n1, n2, 2)
upper_bounds = torch.min(set_1[:, 2:].unsqueeze(1), set_2[:, 2:].unsqueeze(0)) # (n1, n2, 2)
intersection_dims = torch.clamp(upper_bounds - lower_bounds, min=0) # (n1, n2, 2)
return intersection_dims[:, :, 0] * intersection_dims[:, :, 1] # (n1, n2)
def compute_jaccard(set_1, set_2):
"""
计算anchor之间的Jaccard系数(IoU)
Args:
set_1: a tensor of dimensions (n1, 4), anchor表示成(xmin, ymin, xmax, ymax)
set_2: a tensor of dimensions (n2, 4), anchor表示成(xmin, ymin, xmax, ymax)
Returns:
Jaccard Overlap of each of the boxes in set 1 with respect to each of the boxes in set 2, shape: (n1, n2)
"""
# Find intersections
intersection = compute_intersection(set_1, set_2) # (n1, n2)
# Find areas of each box in both sets
areas_set_1 = (set_1[:, 2] - set_1[:, 0]) * (set_1[:, 3] - set_1[:, 1]) # (n1)
areas_set_2 = (set_2[:, 2] - set_2[:, 0]) * (set_2[:, 3] - set_2[:, 1]) # (n2)
# Find the union
# PyTorch auto-broadcasts singleton dimensions
union = areas_set_1.unsqueeze(1) + areas_set_2.unsqueeze(0) - intersection # (n1, n2)
return intersection / union # (n1, n2)
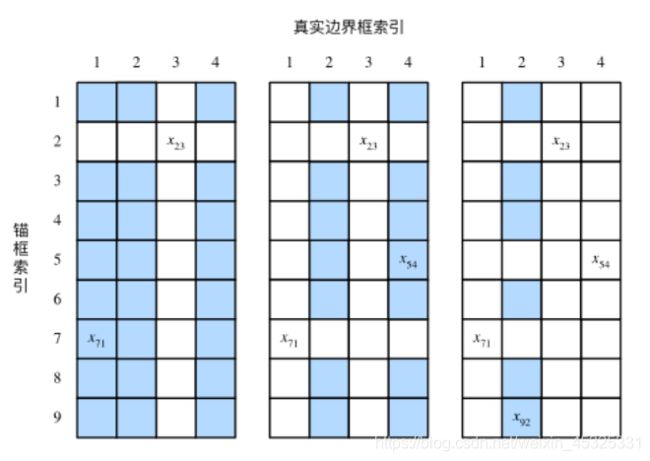
标注训练集的锚框


二、图像风格迁移
样式迁移
样式迁移需要两张输入图像,一张是内容图像,另一张是样式图像,我们将使用神经网络修改内容图像使其在样式上接近样式图像。下图中的内容图像为本书作者在西雅图郊区的雷尼尔山国家公园(Mount Rainier National Park)拍摄的风景照,而样式图像则是一副主题为秋天橡树的油画。最终输出的合成图像在保留了内容图像中物体主体形状的情况下应用了样式图像的油画笔触,同时也让整体颜色更加鲜艳。

方法
下图用一个例子来阐述基于卷积神经网络的样式迁移方法。首先,我们初始化合成图像,例如将其初始化成内容图像。该合成图像是样式迁移过程中唯一需要更新的变量,即样式迁移所需迭代的模型参数。然后,我们选择一个预训练的卷积神经网络来抽取图像的特征,其中的模型参数在训练中无须更新。深度卷积神经网络凭借多个层逐级抽取图像的特征。我们可以选择其中某些层的输出作为内容特征或样式特征。以图9.13为例,这里选取的预训练的神经网络含有3个卷积层,其中第二层输出图像的内容特征,而第一层和第三层的输出被作为图像的样式特征。接下来,我们通过正向传播(实线箭头方向)计算样式迁移的损失函数,并通过反向传播(虚线箭头方向)迭代模型参数,即不断更新合成图像。样式迁移常用的损失函数由3部分组成:内容损失(content loss)使合成图像与内容图像在内容特征上接近,样式损失(style loss)令合成图像与样式图像在样式特征上接近,而总变差损失(total variation loss)则有助于减少合成图像中的噪点。最后,当模型训练结束时,我们输出样式迁移的模型参数,即得到最终的合成图像。

%matplotlib inline
import time
import torch
import torch.nn.functional as F
import torchvision
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import sys
sys.path.append("/home/kesci/input")
import d2len9900 as d2l
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 均已测试
print(device, torch.__version__)
预处理和后处理
rgb_mean = np.array([0.485, 0.456, 0.406])
rgb_std = np.array([0.229, 0.224, 0.225])
def preprocess(PIL_img, image_shape):
process = torchvision.transforms.Compose([
torchvision.transforms.Resize(image_shape),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=rgb_mean, std=rgb_std)])
return process(PIL_img).unsqueeze(dim = 0) # (batch_size, 3, H, W)
def postprocess(img_tensor):
inv_normalize = torchvision.transforms.Normalize(
mean= -rgb_mean / rgb_std,
std= 1/rgb_std)
to_PIL_image = torchvision.transforms.ToPILImage()
return to_PIL_image(inv_normalize(img_tensor[0].cpu()).clamp(0, 1))
抽取特征
!echo $TORCH_HOME # 将会把预训练好的模型下载到此处(没有输出的话默认是.cache/torch)
pretrained_net = torchvision.models.vgg19(pretrained=False)
pretrained_net.load_state_dict(torch.load('/home/kesci/input/vgg193427/vgg19-dcbb9e9d.pth'))
style_layers, content_layers = [0, 5, 10, 19, 28], [25]
net_list = []
for i in range(max(content_layers + style_layers) + 1):
net_list.append(pretrained_net.features[i])
net = torch.nn.Sequential(*net_list)
def extract_features(X, content_layers, style_layers):
contents = []
styles = []
for i in range(len(net)):
X = net[i](X)
if i in style_layers:
styles.append(X)
if i in content_layers:
contents.append(X)
return contents, styles
def get_contents(image_shape, device):
content_X = preprocess(content_img, image_shape).to(device)
contents_Y, _ = extract_features(content_X, content_layers, style_layers)
return content_X, contents_Y
def get_styles(image_shape, device):
style_X = preprocess(style_img, image_shape).to(device)
_, styles_Y = extract_features(style_X, content_layers, style_layers)
return style_X, styles_Y
定义损失函数
内容损失:与线性回归中的损失函数类似,内容损失通过平方误差函数衡量合成图像与内容图像在内容特征上的差异。平方误差函数的两个输入均为extract_features函数计算所得到的内容层的输出。
def content_loss(Y_hat, Y):
return F.mse_loss(Y_hat, Y)
样式损失:样式损失也一样通过平方误差函数衡量合成图像与样式图像在样式上的差异。为了表达样式层输出的样式,我们先通过extract_features函数计算样式层的输出。
def gram(X):
num_channels, n = X.shape[1], X.shape[2] * X.shape[3]
X = X.view(num_channels, n)
return torch.matmul(X, X.t()) / (num_channels * n)
def style_loss(Y_hat, gram_Y):
return F.mse_loss(gram(Y_hat), gram_Y)
总损失:有时候,我们学到的合成图像里面有大量高频噪点,即有特别亮或者特别暗的颗粒像素。一种常用的降噪方法是总变差降噪(total variation denoising)。
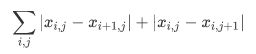
def tv_loss(Y_hat):
return 0.5 * (F.l1_loss(Y_hat[:, :, 1:, :], Y_hat[:, :, :-1, :]) +
F.l1_loss(Y_hat[:, :, :, 1:], Y_hat[:, :, :, :-1]))
损失函数:样式迁移的损失函数即内容损失、样式损失和总变差损失的加权和。通过调节这些权值超参数,我们可以权衡合成图像在保留内容、迁移样式以及降噪三方面的相对重要性。
content_weight, style_weight, tv_weight = 1, 1e3, 10
def compute_loss(X, contents_Y_hat, styles_Y_hat, contents_Y, styles_Y_gram):
# 分别计算内容损失、样式损失和总变差损失
contents_l = [content_loss(Y_hat, Y) * content_weight for Y_hat, Y in zip(
contents_Y_hat, contents_Y)]
styles_l = [style_loss(Y_hat, Y) * style_weight for Y_hat, Y in zip(
styles_Y_hat, styles_Y_gram)]
tv_l = tv_loss(X) * tv_weight
# 对所有损失求和
l = sum(styles_l) + sum(contents_l) + tv_l
return contents_l, styles_l, tv_l, l
创建和初始化合成图像
class GeneratedImage(torch.nn.Module):
def __init__(self, img_shape):
super(GeneratedImage, self).__init__()
self.weight = torch.nn.Parameter(torch.rand(*img_shape))
def forward(self):
return self.weight
def get_inits(X, device, lr, styles_Y):
'''
创建了合成图像的模型实例,并将其初始化为图像X。样式图像在各个样式层的格拉姆矩阵styles_Y_gram将在训练前预先计算好。
'''
gen_img = GeneratedImage(X.shape).to(device)
gen_img.weight.data = X.data
optimizer = torch.optim.Adam(gen_img.parameters(), lr=lr)
styles_Y_gram = [gram(Y) for Y in styles_Y]
return gen_img(), styles_Y_gram, optimizer
训练
def train(X, contents_Y, styles_Y, device, lr, max_epochs, lr_decay_epoch):
print("training on ", device)
X, styles_Y_gram, optimizer = get_inits(X, device, lr, styles_Y)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, lr_decay_epoch, gamma=0.1)
for i in range(max_epochs):
start = time.time()
contents_Y_hat, styles_Y_hat = extract_features(
X, content_layers, style_layers)
contents_l, styles_l, tv_l, l = compute_loss(
X, contents_Y_hat, styles_Y_hat, contents_Y, styles_Y_gram)
optimizer.zero_grad()
l.backward(retain_graph = True)
optimizer.step()
scheduler.step()
if i % 50 == 0 and i != 0:
print('epoch %3d, content loss %.2f, style loss %.2f, '
'TV loss %.2f, %.2f sec'
% (i, sum(contents_l).item(), sum(styles_l).item(), tv_l.item(),
time.time() - start))
return X.detach()
三、图像分类案例1
比较简单,在此略过
注:
以上所有内容均来自伯禹平台动手学深度学习课程