yolo格式数据标签转coco格式
yolo格式数据标签转coco格式
最近在使用Deformable detr时输入数据格式为coco类型的标签,因此根据别人的代码改写了一下,将yolo类型标签转换为coco格式。
总共分为两步:
1. 第一步:将yolo的box标签类型(xMin, yMim, xMax, yMax)转化为coco标签类型(xMin, yMim, xMax, yMax),并保存为txt文件,同时相较于yolo的txt文件,coco的注释文件中还多了一列标签对应的图像名称。
输入参数:
(1) 原始标签路径originLabelsDir:
存放标签的文件夹:

txt文件中的内容
因为我这边只有一类 所以标签就全是0

(2)原始图片路径originImagesDir:
(3) 生成的临时注释txt文件
生成的临时文件中的内容应该如下:
将yolo的标签全部存入一个txt文件中
将yolo格式的标签:classId, xCenter, yCenter, w, h转换为
coco格式:classId, xMin, yMim, xMax, yMax格式
coco的id编号从1开始计算,所以这里classId应该从1开始计算
最终annos.txt中每行为imageName, classId, xMin, yMim, xMax, yMax, 一个bbox对应一行

代码如下
import os
import cv2
import json
from tqdm import tqdm
def yolo2txt(originLabelsDir, originImagesDir, saveTempTxt, img_suffix='png'):
"""
将yolo的标签全部存入一个txt文件中
将yolo格式的标签:classId, xCenter, yCenter, w, h转换为
coco格式:classId, xMin, yMim, xMax, yMax格式
coco的id编号从1开始计算,所以这里classId应该从1开始计算
最终annos.txt中每行为imageName, classId, xMin, yMim, xMax, yMax, 一个bbox对应一行
originLabelsDir: 原始yolo标签路径
originImagesDir: 原始图像路径
ssaveTempTxt: 保存txt路径
)
"""
txtFileList = os.listdir(originLabelsDir)
print(f"image number is {len(txtFileList)}")
with open(saveTempTxt, 'w') as fw:
for txtFile in tqdm(txtFileList, desc="generating COCO format"):
# 读取图像长宽
imagePath = os.path.join(originImagesDir,
txtFile.replace('txt', img_suffix))
assert os.path.exists(imagePath), f"can\'t find this image {imagePath}"
image = cv2.imread(imagePath)
H, W, _ = image.shape
with open(os.path.join(originLabelsDir, txtFile), 'r') as fr:
labelList = fr.readlines()
for label in labelList:
label = label.strip().split()
x = float(label[1])
y = float(label[2])
w = float(label[3])
h = float(label[4])
# convert x,y,w,h to x1,y1,x2,y2
x1 = (x - w / 2) * W
y1 = (y - h / 2) * H
x2 = (x + w / 2) * W
y2 = (y + h / 2) * H
# 为了与coco标签方式对,标签序号从1开始计算
fw.write(txtFile.replace('txt', img_suffix) + ' {} {} {} {} {}\n'.format(int(label[0]) + 1, x1, y1, x2, y2))
if __name__ == "__main__":
# 原始标签路径
originLabelsDir = '/home/taoyang/Documents/datasets/datasets/wheat_panicle_dataset/train/labels'
# 转换后的文件保存路径
saveTempTxt = '/home/taoyang/Documents/datasets/datasets/wheat_panicle_dataset/train/annos_temp.txt'
# 原始标签对应的图片路径
originImagesDir = '/home/taoyang/Documents/datasets/datasets/wheat_panicle_dataset/images/train2017'
yolo2txt(originLabelsDir, originImagesDir, saveTempTxt)
- 第二步:生成json注释文件,并保存。
有三个输入分别为:
原始图像保存的文件夹:originImagesDir
类别txt文件:classtxt
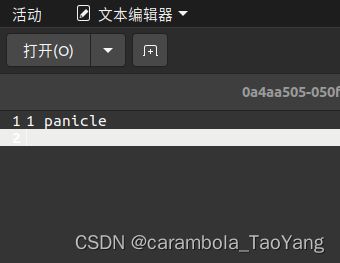
上一步生成的临时注释文件:annostxt
最终生成的注释文件.json保存在与annotxt相同路径下
第二步代码如下:
def yolo2json(originImagesDir, classtxt, annostxt):
# dataset用于保存所有数据的图片信息和标注信息
dataset = {'categories': [], 'annotations': [], 'images': []}
# 打开类别标签
with open(classtxt, 'r') as f:
classes_ori = f.readlines()
classes = [i.strip().split(' ') for i in classes_ori if i.strip() != '']
# 建立类别标签和数字id的对应关系
for i, cls in classes:
dataset['categories'].append({'id': i, 'name': cls})
# 读取images文件夹的图片名称
indexes = os.listdir(originImagesDir)
anno_id = -1
# 读取Bbox信息
with open(annostxt) as tr:
annos = tr.readlines()
# ---------------接着将,以上数据转换为COCO所需要的格式---------------
with tqdm(total=len(indexes)) as pbar:
for k, index in enumerate(indexes):
# 用opencv读取图片,得到图像的宽和高
im = cv2.imread(os.path.join(originImagesDir, index))
assert im.all() != None, f"can\'t find this image {os.path.join(originImagesDir, index)}"
height, width, _ = im.shape
# 添加图像的信息到dataset中
dataset['images'].append({'file_name': index,
'id': k,
'width': width,
'height': height})
del_annos = [] # 保存已经匹配到的注释信息
for anno in annos:
parts = anno.strip().split()
# 如果图像的名称和标记的名称对上,则添加标记
if parts[0] == index:
del_annos.append(anno)
anno_id += 1
# 类别
cls_id = parts[1]
# x_min
x1 = float(parts[2])
# y_min
y1 = float(parts[3])
# x_max
x2 = float(parts[4])
# y_max
y2 = float(parts[5])
width = x2 - x1
height = y2 - y1
assert width > 0 and height > 0, f"width or height of {index}\'s box is not positive"
dataset['annotations'].append({
'area': width * height,
'bbox': [x1, y1, width, height],
'category_id': cls_id, # 根据自己的后续代码决定是否转化为int类型,原来的代码这边是转化成int类
# 型,但是我后面的代码中category_id用的是str类型,导致我一直读不进对应标签的图像
'id': anno_id,
'image_id': k,
'iscrowd': 0,
# 左上角以及右下角坐标
'segmentation': [[x1, y1, x2, y2]]
})
# 删除匹配到的注释
for da in del_annos:
annos.remove(da)
pbar.update(1)
if len(annos) != 0:
print(f"\033[31m can\'t match image for these annotations:\n{annos}\033[0m")
# 保存结果的文件夹, 保存在与annostxt相同文件夹下,命名为annotations.json
savefile = os.path.join(annostxt.rsplit('/', 1)[-2], 'annotations.json')
with open(savefile, 'w', encoding='utf-8') as f:
json.dump(dataset, f, ensure_ascii=False, indent=1)
if __name__ == "__main__":
originImagesDir = '/home/taoyang/Documents/datasets/datasets/wheat_panicle_dataset/images/train2017'
classtxt = '/home/taoyang/Documents/datasets/datasets/wheat_panicle_dataset/train/classes.txt'
annostxt = '/home/taoyang/Documents/datasets/datasets/wheat_panicle_dataset/train/annos_temp.txt'
yolo2json(originImagesDir, classtxt, annostxt)